文本分类入门:特征选择算法之开方检验、信息增益;特征选择与特征权重计算的区别
来源:互联网 发布:淘宝卖家手淘旺信入口 编辑:程序博客网 时间:2024/05/02 04:31
文本分类入门(十)特征选择算法之开方检验:http://www.blogjava.net/zhenandaci/archive/2008/08/31/225966.html
文本分类入门(十一)特征选择方法之信息增益:http://www.blogjava.net/zhenandaci/archive/2016/08/11/261701.html
文本分类入门(番外篇)特征选择与特征权重计算的区别:http://www.blogjava.net/zhenandaci/archive/2009/04/19/266388.html
文本分类入门(十)特征选择算法之开方检验:http://www.blogjava.net/zhenandaci/archive/2008/08/31/225966.html
前文提到过,除了分类算法以外,为分类文本作处理的特征提取算法也对最终效果有巨大影响,而特征提取算法又分为特征选择和特征抽取两大类,其中特征选择算法有互信息,文档频率,信息增益,开方检验等等十数种,这次先介绍特征选择算法中效果比较好的开方检验方法。
大家应该还记得,开方检验其实是数理统计中一种常用的检验两个变量独立性的方法。(什么?你是文史类专业的学生,没有学过数理统计?那你做什么文本分类?在这捣什么乱?)
开方检验最基本的思想就是通过观察实际值与理论值的偏差来确定理论的正确与否。具体做的时候常常先假设两个变量确实是独立的(行话就叫做“原假设”),然后观察实际值(也可以叫做观察值)与理论值(这个理论值是指“如果两者确实独立”的情况下应该有的值)的偏差程度,如果偏差足够小,我们就认为误差是很自然的样本误差,是测量手段不够精确导致或者偶然发生的,两者确确实实是独立的,此时就接受原假设;如果偏差大到一定程度,使得这样的误差不太可能是偶然产生或者测量不精确所致,我们就认为两者实际上是相关的,即否定原假设,而接受备择假设。
那么用什么来衡量偏差程度呢?假设理论值为E(这也是数学期望的符号哦),实际值为x,如果仅仅使用所有样本的观察值与理论值的差值x-E之和

来衡量,单个的观察值还好说,当有多个观察值x1,x2,x3的时候,很可能x1-E,x2-E,x3-E的值有正有负,因而互相抵消,使得最终的结果看上好像偏差为0,但实际上每个都有偏差,而且都还不小!此时很直接的想法便是使用方差代替均值,这样就解决了正负抵消的问题,即使用
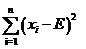
这时又引来了新的问题,对于500的均值来说,相差5其实是很小的(相差1%),而对20的均值来说,5相当于25%的差异,这是使用方差也无法体现的。因此应该考虑改进上面的式子,让均值的大小不影响我们对差异程度的判断
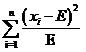 式(1)
式(1)
上面这个式子已经相当好了。实际上这个式子就是开方检验使用的差值衡量公式。当提供了数个样本的观察值x1,x2,……xi ,……xn之后,代入到式(1)中就可以求得开方值,用这个值与事先设定的阈值比较,如果大于阈值(即偏差很大),就认为原假设不成立,反之则认为原假设成立。
在文本分类问题的特征选择阶段,我们主要关心一个词t(一个随机变量)与一个类别c(另一个随机变量)之间是否相互独立?如果独立,就可以说词t对类别c完全没有表征作用,即我们根本无法根据t出现与否来判断一篇文档是否属于c这个分类。但与最普通的开方检验不同,我们不需要设定阈值,因为很难说词t和类别c关联到什么程度才算是有表征作用,我们只想借用这个方法来选出一些最最相关的即可。
此时我们仍然需要明白对特征选择来说原假设是什么,因为计算出的开方值越大,说明对原假设的偏离越大,我们越倾向于认为原假设的反面情况是正确的。我们能不能把原假设定为“词t与类别c相关“?原则上说当然可以,这也是一个健全的民主主义社会赋予每个公民的权利(笑),但此时你会发现根本不知道此时的理论值该是多少!你会把自己绕进死胡同。所以我们一般都使用”词t与类别c不相关“来做原假设。选择的过程也变成了为每个词计算它与类别c的开方值,从大到小排个序(此时开方值越大越相关),取前k个就可以(k值可以根据自己的需要选,这也是一个健全的民主主义社会赋予每个公民的权利)。
好,原理有了,该来个例子说说到底怎么算了。
比如说现在有N篇文档,其中有M篇是关于体育的,我们想考察一个词“篮球”与类别“体育”之间的相关性(任谁都看得出来两者很相关,但很遗憾,我们是智慧生物,计算机不是,它一点也看不出来,想让它认识到这一点,只能让它算算看)。我们有四个观察值可以使用:
1. 包含“篮球”且属于“体育”类别的文档数,命名为A
2. 包含“篮球”但不属于“体育”类别的文档数,命名为B
3. 不包含“篮球”但却属于“体育”类别的文档数,命名为C
4. 既不包含“篮球”也不属于“体育”类别的文档数,命名为D
用下面的表格更清晰:
特征选择
1.属于“体育”
2.不属于“体育”
总 计
1.包含“篮球”
A
B
A+B
2.不包含“篮球”
C
D
C+D
总 数
A+C
B+D
N
如果有些特点你没看出来,那我说一说,首先,A+B+C+D=N(这,这不废话嘛)。其次,A+C的意思其实就是说“属于体育类的文章数量”,因此,它就等于M,同时,B+D就等于N-M。
好,那么理论值是什么呢?以包含“篮球”且属于“体育”类别的文档数为例。如果原假设是成立的,即“篮球”和体育类文章没什么关联性,那么在所有的文章中,“篮球”这个词都应该是等概率出现,而不管文章是不是体育类的。这个概率具体是多少,我们并不知道,但他应该体现在观察结果中(就好比抛硬币的概率是二分之一,可以通过观察多次抛的结果来大致确定),因此我们可以说这个概率接近
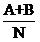
(因为A+B是包含“篮球”的文章数,除以总文档数就是“篮球”出现的概率,当然,这里认为在一篇文章中出现即可,而不管出现了几次)而属于体育类的文章数为A+C,在这些个文档中,应该有
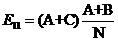
篇包含“篮球”这个词(数量乘以概率嘛)。
但实际有多少呢?考考你(读者:切,当然是A啦,表格里写着嘛……)。
此时对这种情况的差值就得出了(套用式(1)的公式),应该是

同样,我们还可以计算剩下三种情况的差值D12,D21,D22,聪明的读者一定能自己算出来(读者:切,明明是自己懒得写了……)。有了所有观察值的差值,就可以计算“篮球”与“体育”类文章的开方值
把D11,D12,D21,D22的值分别代入并化简,可以得到
词t与类别c的开方值更一般的形式可以写成
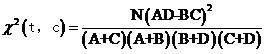 式(2)
式(2)
接下来我们就可以计算其他词如“排球”,“产品”,“银行”等等与体育类别的开方值,然后根据大小来排序,选择我们需要的最大的数个词汇作为特征项就可以了。
实际上式(2)还可以进一步化简,注意如果给定了一个文档集合(例如我们的训练集)和一个类别,则N,M,N-M(即A+C和B+D)对同一类别文档中的所有词来说都是一样的,而我们只关心一堆词对某个类别的开方值的大小顺序,而并不关心具体的值,因此把它们从式(2)中去掉是完全可以的,故实际计算的时候我们都使用
![]() 式(3)
式(3)
好啦,并不高深对不对?
针对英文纯文本的实验结果表明:作为特征选择方法时,开方检验和信息增益的效果最佳(相同的分类算法,使用不同的特征选择算法来得到比较结果);文档频率方法的性能同前两者大体相当,术语强度方法性能一般;互信息方法的性能最差(文献[17])。
但开方检验也并非就十全十美了。回头想想A和B的值是怎么得出来的,它统计文档中是否出现词t,却不管t在该文档中出现了几次,这会使得他对低频词有所偏袒(因为它夸大了低频词的作用)。甚至会出现有些情况,一个词在一类文章的每篇文档中都只出现了一次,其开方值却大过了在该类文章99%的文档中出现了10次的词,其实后面的词才是更具代表性的,但只因为它出现的文档数比前面的词少了“1”,特征选择的时候就可能筛掉后面的词而保留了前者。这就是开方检验著名的“低频词缺陷“。因此开方检验也经常同其他因素如词频综合考虑来扬长避短。
好啦,关于开方检验先说这么多,有机会还将介绍其他的特征选择算法。
附:给精通统计学的同学多说几句,式(1)实际上是对连续型的随机变量的差值计算公式,而我们这里统计的“文档数量“显然是离散的数值(全是整数),因此真正在统计学中计算的时候,是有修正过程的,但这种修正仍然是只影响具体的开方值,而不影响大小的顺序,故文本分类中不做这种修正。
文本分类入门(十一)特征选择方法之信息增益:http://www.blogjava.net/zhenandaci/archive/2016/08/11/261701.html
前文提到过,除了开方检验(CHI)以外,信息增益(IG,Information Gain)也是很有效的特征选择方法。但凡是特征选择,总是在将特征的重要程度量化之后再进行选择,而如何量化特征的重要性,就成了各种方法间最大的不同。开方检验中使用特征与类别间的关联性来进行这个量化,关联性越强,特征得分越高,该特征越应该被保留。
在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。
因此先回忆一下信息论中有关信息量(就是“熵”)的定义。说有这么一个变量X,它可能的取值有n多种,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:

意思就是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大(因此我一直觉得我们的政策法规信息量非常大,因为它变化很多,基本朝令夕改,笑)。
对分类系统来说,类别C是变量,它可能的取值是C1,C2,……,Cn,而每一个类别出现的概率是P(C1),P(C2),……,P(Cn),因此n就是类别的总数。此时分类系统的熵就可以表示为:
![clip_image002[4]](http://www.blogjava.net/images/blogjava_net/zhenandaci/WindowsLiveWriter/7fce385fe28b_D158/clip_image002%5B4%5D_thumb.gif "clip_image002[4]")
有同学说不好理解呀,这样想就好了,文本分类系统的作用就是输出一个表示文本属于哪个类别的值,而这个值可能是C1,C2,……,Cn,因此这个值所携带的信息量就是上式中的这么多。
信息增益是针对一个一个的特征而言的,就是看一个特征t,系统有它和没它的时候信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即增益。系统含有特征t的时候信息量很好计算,就是刚才的式子,它表示的是包含所有特征时系统的信息量。
问题是当系统不包含t时,信息量如何计算?我们换个角度想问题,把系统要做的事情想象成这样:说教室里有很多座位,学生们每次上课进来的时候可以随便坐,因而变化是很大的(无数种可能的座次情况);但是现在有一个座位,看黑板很清楚,听老师讲也很清楚,于是校长的小舅子的姐姐的女儿托关系(真辗转啊),把这个座位定下来了,每次只能给她坐,别人不行,此时情况怎样?对于座次的可能情况来说,我们很容易看出以下两种情况是等价的:(1)教室里没有这个座位;(2)教室里虽然有这个座位,但其他人不能坐(因为反正它也不能参与到变化中来,它是不变的)。
对应到我们的系统中,就是下面的等价:(1)系统不包含特征t;(2)系统虽然包含特征t,但是t已经固定了,不能变化。
我们计算分类系统不包含特征t的时候,就使用情况(2)来代替,就是计算当一个特征t不能变化时,系统的信息量是多少。这个信息量其实也有专门的名称,就叫做“条件熵”,条件嘛,自然就是指“t已经固定“这个条件。
但是问题接踵而至,例如一个特征X,它可能的取值有n多种(x1,x2,……,xn),当计算条件熵而需要把它固定的时候,要把它固定在哪一个值上呢?答案是每一种可能都要固定一下,计算n个值,然后取均值才是条件熵。而取均值也不是简单的加一加然后除以n,而是要用每个值出现的概率来算平均(简单理解,就是一个值出现的可能性比较大,固定在它上面时算出来的信息量占的比重就要多一些)。
因此有这样两个条件熵的表达式:
![]()
这是指特征X被固定为值xi时的条件熵,
![]()
这是指特征X被固定时的条件熵,注意与上式在意义上的区别。从刚才计算均值的讨论可以看出来,第二个式子与第一个式子的关系就是:

具体到我们文本分类系统中的特征t,t有几个可能的值呢?注意t是指一个固定的特征,比如他就是指关键词“经济”或者“体育”,当我们说特征“经济”可能的取值时,实际上只有两个,“经济”要么出现,要么不出现。一般的,t的取值只有t(代表t出现)和![]() (代表t不出现),注意系统包含t但t 不出现与系统根本不包含t可是两回事。
(代表t不出现),注意系统包含t但t 不出现与系统根本不包含t可是两回事。
因此固定t时系统的条件熵就有了,为了区别t出现时的符号与特征t本身的符号,我们用T代表特征,而用t代表T出现,那么:

与刚才的式子对照一下,含义很清楚对吧,P(t)就是T出现的概率,![]() 就是T不出现的概率。这个式子可以进一步展开,其中的
就是T不出现的概率。这个式子可以进一步展开,其中的

另一半就可以展开为:

因此特征T给系统带来的信息增益就可以写成系统原本的熵与固定特征T后的条件熵之差:

公式中的东西看上去很多,其实也都很好计算。比如P(Ci),表示类别Ci出现的概率,其实只要用1除以类别总数就得到了(这是说你平等的看待每个类别而忽略它们的大小时这样算,如果考虑了大小就要把大小的影响加进去)。再比如P(t),就是特征T出现的概率,只要用出现过T的文档数除以总文档数就可以了,再比如P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的文档数除以出现了T的文档数就可以了。
从以上讨论中可以看出,信息增益也是考虑了特征出现和不出现两种情况,与开方检验一样,是比较全面的,因而效果不错。但信息增益最大的问题还在于它只能考察特征对整个系统的贡献,而不能具体到某个类别上,这就使得它只适合用来做所谓“全局”的特征选择(指所有的类都使用相同的特征集合),而无法做“本地”的特征选择(每个类别有自己的特征集合,因为有的词,对这个类别很有区分度,对另一个类别则无足轻重)。
看看,导出的过程其实很简单,没有什么神秘的对不对。可有的学术论文里就喜欢把这种本来很直白的东西写得很晦涩,仿佛只有读者看不懂才是作者的真正成功。
咱们是新一代的学者,咱们没有知识不怕被别人看出来,咱们有知识也不怕教给别人。所以咱都把事情说简单点,说明白点,大家好,才是真的好。
文本分类入门(番外篇)特征选择与特征权重计算的区别:http://www.blogjava.net/zhenandaci/archive/2009/04/19/266388.html
在文本分类的过程中,特征(也可以简单的理解为“词”)从人类能够理解的形式转换为计算机能够理解的形式时,实际上经过了两步骤的量化——特征选择阶段的重要程度量化和将具体文本转化为向量时的特征权重量化。初次接触文本分类的人很容易混淆这两个步骤使用的方法和各自的目的,因而我经常听到读者有类似“如何使用TFIDF做特征选择”或者“卡方检验量化权重后每篇文章都一样”等等困惑。文本分类本质上也是一个模式识别的问题,因此我想借用一个更直观的例子来说说特征选择和权重量化到底各自是什么东西,当然,一旦解释清楚,你马上就会觉得文本分类这东西实在白痴,实在没什么技术含量,你也就不会再继续看我的技术博客,不过我不担心,因为你已经踏上了更光明的道路(笑),我高兴还来不及。
想想通过指纹来识别一个人的身份,只看一个人的指纹,当然说不出他姓甚名谁,识别的过程实际上是比对的过程,要与已有的指纹库比较,找出相同的,或者说相似到一定程度的那一个。
首要的问题是,人的指纹太复杂,包含太多的位置和几何形状,要完全重现一个人的指纹,存储和计算都是大麻烦。因此第一步总是一个特征选择的问题,我们把全人类的指纹都统计一下,看看哪几个位置能够最好的区分不同的人。显然不同的位置效果很不一样,在有的位置上,我的指纹是是什么形状,其他人也大都是这个形状,这个位置就不具有区分度,或者说不具有表征性,或者说,对分类问题来说,它的重要程度低。这样的位置我们就倾向于在识别的时候根本不看它,不考虑它。
那怎么看谁重要谁不重要呢?这就依赖于具体的选择方法如何来量化重要程度,对卡方检验和信息增益这类方法来说,量化以后的得分越大的特征就越重要(也就是说,有可能有些方法,是得分越小的越重要)。
比如说你看10个位置,他们的重要程度分别是:
1 2 3 4 5 6 7 8 9 10
(20,5,10,20,30,15,4,3,7, 3)
显然第1,第3,4,5,6个位置比其他位置更重要,而相对的,第1个位置又比第3个位置更重要。
识别时,我们只在那些重要的位置上采样。当今的指纹识别系统,大都只用到人指纹的5个位置(惊讶么?只要5个位置的信息就可以区分60亿人),这5个位置就是经过特征选择过程而得以保留的系统特征集合。假设这个就是刚才的例子,那么该集合应该是:
(第1个位置,第3个位置,第4个位置,第5个位置,第6个位置)
当然,具体的第3个位置是指纹中的哪个位置你自己总得清楚。
确定了这5个位置之后,就可以把一个人的指纹映射到这个只有5个维度的空间中,我们就把他在5个位置上的几何形状分别转换成一个具体的值,这就是特征权重的计算。依据什么来转换,就是你选择的特征权重量化方法,在文本分类中,最常用的就是TFIDF。
我想一定是“权重“这个词误导了所有人,让大家以为TFIDF计算出的值代表的是特征的重要程度,其实完全不是。例如我们有一位男同学,他的指纹向量是:
(10,3,4,20,5)
你注意到他第1个位置的得分(10)比第3个位置的得分(3)高,那么能说第1个位置比第3个位置重要么?如果再有一位女同学,她的指纹向量是:
(10,20,4,20,5)
看看,第1个位置得分(10)又比第3个位置(20)低了,那这两个位置到底哪个更重要呢?答案是第1个位置更重要,但这不是在特征权重计算这一步体现出来的,而是在我们特征选择的时候就确定了,第1个位置比第3个位置更重要。
因此要记住,通过TFIDF计算一个特征的权重时,该权重体现出的根本不是特征的重要程度!
那它代表什么?再看看两位同学的指纹,放到一起:
(10, 3,4,20,5)
(10,20,4,20,5)
在第三个位置上女同学的权重高于男同学,这不代表该女同学在指纹的这个位置上更“优秀“(毕竟,指纹还有什么优秀不优秀的分别么,笑),也不代表她的这个位置比男同学的这个位置更重要,3和20这两个得分,仅仅代表他们的”不同“。
在文本分类中也是如此,比如我们的系统特征集合只有两个词:
(经济,发展)
这两个词是使用卡方检验(特征选择)选出来的,有一篇文章的向量形式是
(2,5)
另一篇
(3,4)
这两个向量形式就是用TFIDF算出来的,很容易看出两篇文章不是同一篇,为什么?因为他们的特征权重根本不一样,所以说权重代表的是差别,而不是优劣。想想你说“经济这个词在第二篇文章中得分高,因此它在第二篇文章中比在第一篇文章中更重要“,这句话代表什么意义呢?你自己都不知道吧(笑)。
所以,当再说起使用TFIDF来计算特征权重时,最好把“权重“这个字眼忘掉,我们就把它说成计算得分好了(甚至”得分“也不太好,因为人总会不自觉的认为,得分高的就更重要),或者就仅仅说成是量化。
如此,你就再也不会拿TFIDF去做特征选择了。
小Tips:为什么有的论文里确实使用了TFIDF作特征选择呢?
严格说来并不是不可以,而且严格说来只要有一种方法能够从一堆特征中挑出少数的一些,它就可以叫做一种特征选择方法,就连“随机选取一部分“都算是一种,而且效果并没有差到惊人的地步哦!还是可以分对一大半的哦!所以有的人就用TFIDF的得分来把特征排排序,取得分最大的几个进入系统特征集合,效果也还行(毕竟,连随机选取效果也都还行),怎么说呢,他们愿意这么干就这么干吧。就像咱国家非得实行户口制度,这个制度说不出任何道理,也不见他带来任何好处,但不也没影响二十一世纪成为中国的世纪么,呵呵。
- 文本分类入门:特征选择算法之开方检验、信息增益;特征选择与特征权重计算的区别
- 文本分类入门特征选择算法之开方检验
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- [教程] 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门(番外篇)特征选择与特征权重计算的区别
- 文本分类入门-特征选择方法之信息增益
- 文本分类入门-特征选择方法之信息增益
- 文本分类入门(十)特征选择算法之开方检验
- 文本分类入门(十)特征选择算法之开方检验
- YII -- 基础 工具 扩展
- php函数记录
- 移植Qt_for_ARM出错小结
- request.getRealPath("/");
- Laravel -- 基础
- 文本分类入门:特征选择算法之开方检验、信息增益;特征选择与特征权重计算的区别
- 二叉树层次遍历
- 一起写RPC框架(十三)RPC服务提供端四--服务的降级
- 设计模式1
- jquery操作iframe的方法:父页面和子页面相互操作的方法
- Android面向对象的六大设计原则
- 使用redis缓存数据
- SVN merge between two branches - “path not found”
- windows2003 server 定时自动重启的设置


