UTF-8 Everywhere
来源:互联网 发布:英雄联盟js打野天赋 编辑:程序博客网 时间:2024/05/22 16:47
前言,一篇比较好的介绍UTF-8的文章,这篇文章的目的是推广和支持UTF-8编码
Purpose of this document (本文的目的)
This document contains special characters. Without proper rendering support, you may see question marks, boxes, or other symbols.Our goal is to promote usage and support of the UTF-8 encoding and to convince that it should be the default choice of encoding for storing text strings in memory or on disk, for communication and all other uses. We believe that our approach improves performance, reduces complexity of software and helps prevent many Unicode-related bugs. We suggest that other encodings of Unicode (or text, in general) belong to rare edge-cases of optimization and should be avoided by mainstream users.
In particular, we believe that the very popular UTF-16 encoding (often mistakenly referred to as ‘widechar’ or simply ‘Unicode’ in the Windows world) has no place in library APIs except for specialized text processing libraries, e.g. ICU.
【作者显然不支持UTF-16,尽管微软做了UTF-16,作者还是认为,即使是windows应用,仍然应该采用UTF-8】
This document also recommends choosing UTF-8 for internal string representation in Windows applications, despite the fact that this standard is less popular there, both due to historical reasons and the lack of native UTF-8 support by the API. We believe that, even on this platform, the following arguments outweigh the lack of native support. Also, we recommend forgetting forever what ‘ANSI codepages’ are and what they were used for. It is in the user’s bill of rights to mix any number of languages in any text string.
Across the industry, many localization-related 【这里指和国家语言代码相关的一些软件】bugs have been blamed on programmers’ lack of knowledge in Unicode. We, however, believe that for an application that is not supposed to specialize in text, the infrastructure can and should make it possible for the program to be unaware of encoding issues.【举例】 For instance, a file copy utility shouldnot be written differently to support non-English file names. In this manifesto, we will also explain what a programmer should be doing if they do not want to dive into all complexities of Unicode and do not really care about what’s inside the string.
Furthermore, we would like to suggest that counting or otherwise iterating over Unicode code points should not be seen as a particularly important task in text processing scenarios. Many developers mistakenly see code points as a kind of a successor to ASCII characters. This lead to software design decisions such as Python’s string O(1) code point access. The truth, however, is that Unicode is inherently more complicated and there is no universal definition of such thing as Unicode character. We see no particular reason to favor Unicode code points over Unicode grapheme clusters, code units or perhaps even words in a language for that. On the other hand, seeing UTF-8 code units (bytes) as a basic unit of text seems particularly useful for many tasks, such as parsing commonly used textual data formats. This is due to a particular feature of this encoding. Graphemes, code units, code points and other relevant Unicode terms are explained in Section 5. Operations on encoded text strings are discussed in Section 7.
Background
In 1988, Joseph D. Becker published the first Unicode draft proposal. At the basis of his design was the naïve assumption that 16 bits per character would suffice. In 1991, the first version of the Unicode standard was published, with code points limited to 16 bits. In the following years many systems have added support for Unicode and switched to the UCS-2 encoding. It was especially attractive for new technologies, such as the Qt framework (1992), Windows NT 3.1 (1993) and Java (1995).
However, it was soon discovered that 16 bits per character will not do for Unicode. In 1996, the UTF-16 encoding was created so existing systems would be able to work with non-16-bit characters. This effectively nullified the rationale behind choosing 16-bit encoding in the first place, namely being a fixed-width encoding. Currently Unicode spans over 109449 characters, about 74500 of them being CJK ideographs.

Microsoft has often mistakenly used ‘Unicode’ and ‘widechar’ as synonyms for both ‘UCS-2’ and ‘UTF-16’. Furthermore, since UTF-8 cannot be set as the encoding for narrow string WinAPI, one must compile his code with UNICODE define. Windows C++ programmers are educated that Unicode must be done with ‘widechars’ (Or worse—the compiler setting-dependent TCHARs, which allow programmer to opt-out from supporting all Unicode code points). As a result of this mess, many Windows programmers are now quite confused about what is the right thing to do about text.
At the same time, in the Linux and the Web worlds, there is a silent agreement that UTF-8 is the best encoding to use for Unicode. Even though it provides shorter representation for English and therefore to computer languages (such as C++, HTML, XML, etc) over any other text, it is seldom less efficient than UTF-16 for commonly used character sets.
The facts
- In both UTF-8 and UTF-16 encodings, code points may take up to 4 bytes.
- UTF-8 is endianness independent. UTF-16 comes in two flavors: UTF-16LE and UTF-16BE (for the two different byte orders, respectively). Here we name them collectively as UTF-16.
- Widechar is 2 bytes in size on some platforms, 4 on others.
- UTF-8 and UTF-32 result the same order when sorted lexicographically. UTF-16 does not.
- UTF-8 favors efficiency for English letters and other ASCII characters (one byte per character) while UTF-16 favors several Asian character sets (2 bytes instead of 3 in UTF-8). This is what made UTF-8 the favorite choice in the Web world, where English HTML/XML tags are intermixed with any-language text. Cyrillic, Hebrew and several other popular Unicode blocks are 2 bytes both in UTF-16 and UTF-8.
- UTF-16 is often misused as a fixed-width encoding, even by the Windows package programs themselves: in plain Windows edit control (until Vista), it takes two backspaces to delete a character which takes 4 bytes in UTF-16. On Windows 7, the console displays such characters as two invalid characters, regardless of the font being used.
- Many third-party libraries for Windows do not support Unicode: they accept narrow string parameters and pass them to the ANSI API. Sometimes, even for file names. In the general case, it is impossible to work around this, as a string may not be representable completely in any ANSI code page (if it contains characters from a mix of Unicode blocks). What is normally done by Windows programmers for file names is getting an 8.3 path to the file (if it already exists) and feeding it into such a library. It is not possible if the library is supposed to create a non-existing file. It is not possible if the path is very long and the 8.3 form is longer than
MAX_PATH. It is not possible if short-name generation is disabled in OS settings. - In C++, there is no way to return Unicode from
std::exception::what()other than using UTF-8. There is no way to support Unicode forlocaleconvother than using UTF-8. - UTF-16 remains popular today, even outside the Windows world. Qt, Java, C#, Python (prior to the CPython v3.3 reference implementation, see below) and the ICU—they all use UTF-16 for internal string representation.
Opaque data argument
Let’s go back to the file copy utility. In the UNIX world, narrow strings are considered UTF-8 by default almost everywhere. Because of that, the author of the file copy utility would not need to care about Unicode. Once tested on ASCII strings for file name arguments, it would work correctly for file names in any language, as arguments are treated as cookies. The code of the file copy utility would not need to change at all to support foreign languages. fopen() would accept Unicode seamlessly, and so wouldargv.
Now let’s see how to do this on Microsoft Windows, a UTF-16 based architecture. To make a file copy utility that can accept file names in a mix of several different Unicode blocks (languages) here requires advanced trickery. First, the application must be compiled as Unicode-aware. In this case, it cannot havemain() function with standard-C parameters. It will then accept UTF-16 encoded argv. To convert a Windows program written with narrow text in mind to support Unicode, one has to refactor deep and to take care of each and every string variable.
The standard library shipped with MSVC is poorly implemented with respect to Unicode support. It forwards narrow-string parameters directly to the OS ANSI API. There is no way to override this. Changing std::locale does not work. It’s impossible to open a file with a Unicode name on MSVC using standard features of C++. The standard way to open a file is:
std::fstream fout("abc.txt");The proper way to get around is by using Microsoft’s own hack that accepts wide-string parameter, which is a non-standard extension.
On Windows, the HKLM\SYSTEM\CurrentControlSet\Control\Nls\CodePage\ACP registry key enables receiving non-ASCII characters, but only from a single ANSI codepage. An unimplemented value of 65001 would probably resolve the cookie issue, on Windows. If Microsoft implements support of thisACP value, this will help wider adoption of UTF-8 on Windows platform.
For Windows programmers and multi-platform library vendors, we further discuss our approach to handling text strings and refactoring programs for better Unicode support in the How to do text on Windows section.
Glyphs, graphemes and other Unicode species
Here is an excerpt of the definitions regarding characters, code points, code units and grapheme clusters according to the Unicode Standard with our comments. You are encouraged to refer to the relevant sections of the standard for a more detailed description.
Приве́т नमस्ते שָׁלוֹם
How many characters do you see?
- Code point
- Any numerical value in the Unicode codespace.[§3.4, D10] For instance: U+3243F.
- Code unit
- The minimal bit combination that can represent a unit of encoded text.[§3.9, D77] For example, UTF-8, UTF-16 and UTF-32 use 8-bit, 16-bit and 32-bit code units respectively. The above code point will be encoded as four code units ‘
f0 b2 90 bf’ in UTF-8, two code units ‘d889 dc3f’ in UTF-16 and as a single code unit ‘0003243f’ in UTF-32. Note that these are just sequences ofgroups of bits; how they are stored on an octet-oriented media depends on the endianness of the particular encoding. When storing the above UTF-16 code units, they will be converted to ‘d8 89 dc 3f’ in UTF-16BE and to ‘89 d8 3f dc’ in UTF-16LE. - Abstract character
A unit of information used for the organization, control, or representation of textual data.[§3.4, D7]The standard further says in §3.1:
For the Unicode Standard, [...] the repertoire is inherently open. Because Unicode is a universal encoding, any abstract character that could ever be encoded is a potential candidate to be encoded, regardless of whether the character is currently known.
The definition is indeed abstract. Whatever one can think of as a character—is an abstract character. For example,
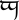 tengwar letter ungwe is an abstract character, although it is not yet representable in Unicode.
tengwar letter ungwe is an abstract character, although it is not yet representable in Unicode.- Encoded character
- Coded character
A mapping between a code point and an abstract character.[§3.4, D11] For example, U+1F428 is a coded character which represents the abstract character
0 0- UTF-8 Everywhere
- eBay Architecture(8)–Async Everywhere
- UTF-16, UTF-8
- UTF-16 UTF-8
- Everywhere politics
- Beauty everywhere
- QT Everywhere
- Transitions-Everywhere
- UTF-8、UTF-16、UTF-32
- Unicode,UTF-8,UTF-16,UTF-32
- unicode,utf-8,utf-16,utf-32
- UTF-8
- UTF-8
- UTF-8
- utf-8
- UTF-8
- UTF-8
- UTF-8
- 人脸检测——Compact CascadeCNN
- ul 无序列表、ol 有序列表、dl 定义列表
- 在fastjson中使用SimplePropertyPreFilter忽略指定属性
- PyConChina2016 北京站即将召开
- 开发一个完整的iOS直播app必须技能
- UTF-8 Everywhere
- HTTP请求响应过程 与HTTPS区别
- HTML基本简介
- iOS:学习视频看这里就够了(定期更新)
- linux原始套接字-发送ARP报文
- 安卓UI设计辅助软件
- FCKeditor2.2+ASP.NET2.0不完全攻略
- 首届全国智能制造(中国制造2025)创新创业大赛在京启动
- Netty线程模型详解


