15-Entities and Encodings
来源:互联网 发布:学术讲座海报 大数据 编辑:程序博客网 时间:2024/06/07 02:44
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
15.1 Messages Are Crates, Entities Are Cargo
- If HTTP messages are the crates of the Internet shipping system, then HTTP entities are the cargo of the messages. Figure 15-1.
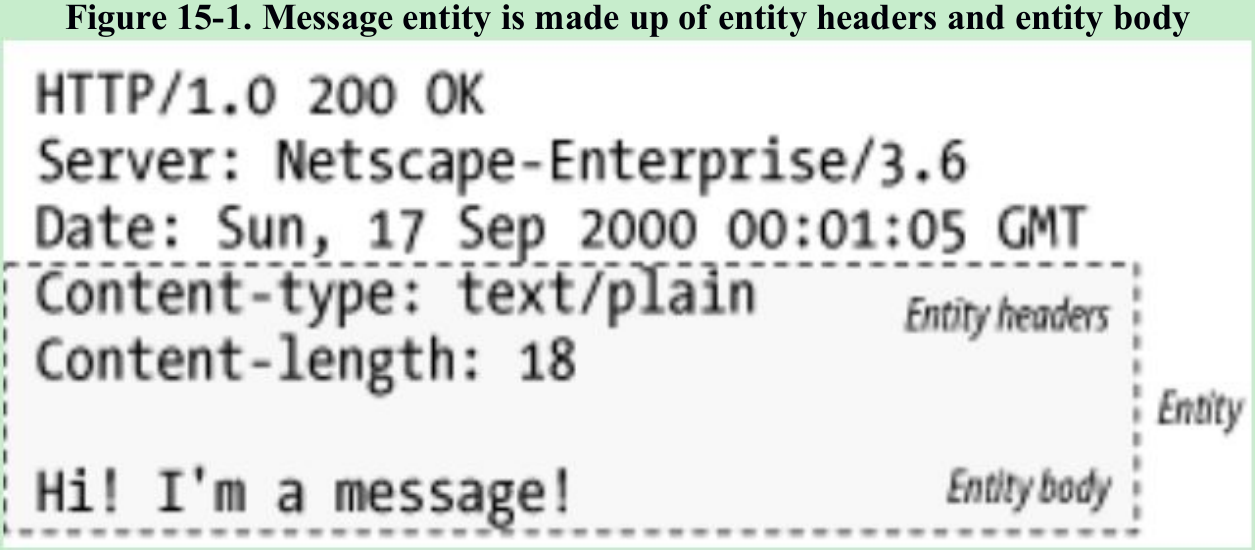
- The entity headers indicate a plain-text document(Content-Type: text/plain) that is 18 characters long(Content-Length: 18). A blank line(CRLF) separates the header fields from the start of the body.
- HTTP entity headers(Chapter 3) describe the contents of an HTTP message. HTTP/1.1 defines 10 primary entity header fields:
- Content-Type: The kind of object carried by the entity.
- Content-Length: The length or size of the message being sent.
- Content-Language: The human language that best matches the object being sent.
- Content-Encoding: Any transformation(compression, etc.) performed on the object data.
- Content-Location: An alternate location for the object at the time of the request.
- Content-Range: If this is a partial entity, this header defines which pieces of the whole are included.
- Content-MD5: A checksum of the contents of the entity body.
- Last-Modified: The date on which this content was created or modified at the server.
- Expires: The date and time at which this entity data will become stale.
- Allow: What request methods are legal on this resource; e.g., GET and HEAD.
- ETag: A unique validator for this particular instance(Section 15.7) of the document.
- Cache-Control: Directives on how this document can be cached.
- The Cache-Control header and the ETag header are not defined formally as an entity header.
15.1.1 Entity Bodies
- The entity body contains the raw cargo. Any descriptive information is contained in the headers.
If there is a Content-Encoding header, the content has been encoded by the content-encoding algorithm, and the first byte of the entity is the first byte of the encoded(e.g., compressed) cargo. - The raw content begins immediately after the blank CRLF line that marks the end of the header fields.

- Figure 15-2. The hexadecimal values show the contents of the message:
- In a, the entity body begins at byte number 65, right after the end-of-headers CRLF. The entity body contains the ASCII characters for “Hi! I’m a message.”
- In b, the entity body begins at byte number 67. The entity body contains the binary contents of the GIF image. GIF files begin with 6-byte version signature, a 16-bit width, and a 16-bit height.
15.2 Content-Length: The Entity’s Size
- The Content-Length header indicates the size of the entity body in bytes. It is mandatory for messages with entity bodies, unless the message is transported using chunked encoding. Content-Length is needed to detect premature message truncation when servers crash and to properly segment messages that share a persistent connection.
15.2.1 Detecting Truncation
- Message truncation is severe for caching proxy servers. If a cache receives a truncated message and doesn’t recognize the truncation, it may store the defective content and serve it many times. Caching proxy servers do not cache HTTP bodies that don’t have an explicit Content-Length header to reduce the risk of caching truncated messages.
15.2.2 Incorrect Content-Length
- HTTP/1.1 user agents officially are supposed to notify the user when an invalid length is received and detected.
15.2.3 Content-Length and Persistent Connections
- If the response comes across a persistent connection, another HTTP response can immediately follow the current response. The Content-Length header lets the client know where one message ends and the next begins. Because the connection is persistent, the client cannot use
connection closeto identify the message’s end. - Section 15.6: when you use chunked encoding, you can use persistent connections without having a Content-Length header. Chunked encoding sends the data in a series of chunks, each with a specified size. Even if the server does not know the size of the entire entity at the time the headers are generated(often because the entity is being generated dynamically), the server can use chunked encoding to transmit pieces of well-defined size.
15.2.4 Content Encoding
- HTTP lets you encode the contents of an entity body. If the body has been content-encoded, the Content-Length header specifies the length in bytes of the encoded body, not the length of the original, un-encoded body.
- None of the headers described in the HTTP/1.1 specification can be used to send the length of the original, unencoded body, which makes it difficult for clients to verify the integrity of their unencoding processes.
15.2.5 Rules for Determining Entity Body Length
- The following rules describe how to determine the length and end of an entity body in different circumstances. The rules should be applied in order; the first match applies.
- If this HTTP message type is not allowed to have a body, ignore the Content-Length header for body calculations. Messages that forbid entity bodies must terminate at the first empty line after the headers, regardless of which entity header fields are present.
Example: The HEAD method requests that a server send the headers(including Content-Length header), but no body. - If a message contains a Transfer-Encoding header(not the default HTTP “identity” encoding), the entity will be terminated by a pattern called a “zero-byte chunk,” unless the message is terminated first by closing the connection.
- If a message has a Content-Length header and the message type allows entity bodies, the Content-Length value contains the body length, unless there is a non-identity Transfer-Encoding header. If a message is received with both a Content-Length header field and a non-identity Transfer-Encoding header field, you must ignore the Content-Length because the transfer encoding will change the way entity bodies are represented and transferred.
- If the message uses the “multipart/byteranges” media type and the entity length is not specified in the Content-Length header, each part of the multipart message will specify its own size. This multipart type is the only entity body type that self-delimits its own size, so this media type must not be sent unless the sender knows the recipient can parse it.
- If none of the above rules match, the entity ends when the connection closes. In practice, only servers can use connection close to indicate the end of a message. Clients can’t close the connection to signal the end of client messages, because that would leave no way for the server to send back a response. The client could do a half close of its output connection, but many server applications interpret a half close as the client disconnecting from the server.
- To be compatible with HTTP/1.0 applications, any HTTP/1.1 request that has an entity body must include a valid Content-Length header field unless the server is known to be HTTP/1.1-compliant. The HTTP/1.1 specification indicates that if a request contains a body and no Content-Length, the server should send a 400 Bad Request response if it cannot determine the length of the message, or a 411 Length Required response if it wants to insist on receiving a valid Content-Length.
- If this HTTP message type is not allowed to have a body, ignore the Content-Length header for body calculations. Messages that forbid entity bodies must terminate at the first empty line after the headers, regardless of which entity header fields are present.
15.3 Entity Digests
- To detect modification of entity body data, the sender can generate a checksum of the data when the initial entity is generated, and the receiver can check the checksum to catch any unintended entity modification.
- The Content-MD5 header is used by servers to send the result of running the MD5 algorithm on the entity body. Only the server where the response originates may compute and send the Content-MD5 header, intermediate proxies and caches may not modify or add the header.
- The Content-MD5 header contains the MD5 of the content after all content encodings have been applied to the entity body and before any transfer encodings have been applied to it. Clients seeking to verify the integrity of the message must first decode the transfer encodings, then compute the MD5 of the resulting unencoded entity body.
15.4 Media Type and Charset
- The Content-Type header field describes the MIME type of the entity body(for HEAD request, it shows the type that would have been sent if it was a GET request). The MIME type is a standardized name that describes the underlying type of media carried as cargo. Client applications use the MIME type to decipher and process the content.
- The Content-Type values are standardized MIME types. MIME types consist of a primary media type(e.g., text, image, audio), followed by a slash, followed by a subtype that further specifies the media type. Table 15-1. More in Appendix D.

- The Content-Type header specifies the media type of the original entity body. If the entity has gone through content encoding, the Content-Type header will still specify the entity body type before the encoding.
15.4.1 Character Encodings for Text Media
- The Content-Type header supports optional parameters to further specify the content type. The “charset” parameter specifies the mechanism to convert bits from the entity into characters in a text file:
Content-Type: text/html; charset=iso-8859-4
15.4.2 Multipart Media Types
- MIME “multipart” email messages contain multiple messages stuck together and sent as a single, complex message. Each component is self-contained, with its own set of headers describing its content; the different components are concatenated together and delimited by a string.
- HTTP supports multipart bodies that are typically sent in two situations: in fill-in form submissions and in range responses carrying pieces of a document.
15.4.3 Multipart Form Submissions
- When an HTTP fill-in form is submitted, variable-length text fields and uploaded objects are sent as separate parts of a multipart body, allowing forms to be filled out with values of different types and lengths. E.g., you may fill out a form that asks for your name and a description with your nickname and a small photo.
- HTTP sends such requests with a
Content-Type: multipart/form-dataheader or aContent-Type: multipart/mixedheader and a multipart body:
Content-Type: multipart/form-data;boundary=[delimiter]where the boundary specifies the delimiter string between the different parts of the body.
- The following example illustrates multipart/form-data encoding. Suppose we have this form:
<FORM action="http://server.com/cgi/handle" enctype="multipart/form-data" method="post"><P>What is your name? <INPUT type="text" name="submit-name"><BR>What files are you sending? <INPUT type="file"name="files"><BR><INPUT type="submit" value="Send"> <INPUT type="reset"></FORM>- If the user enters “Sally” in the text-input field and selects the text file “essayfile.txt,” the user agent might send back the following data:
Content-Type: multipart/form-data; boundary=AaB03x--AaB03xContent-Disposition: form-data; name="submit-name"Sally--AaB03xContent-Disposition: form-data; name="files";filename="essayfile.txt"Content-Type: text/plain...contents of essayfile.txt...--AaB03x--- If the user selected a second(image) file, “imagefile.gif,” the user agent might construct the parts as follows:
Content-Type: multipart/form-data; boundary=AaB03x--AaB03xContent-Disposition: form-data; name="submit-name"Sally--AaB03xContent-Disposition: form-data; name="files"Content-Type: multipart/mixed; boundary=BbC04y--BbC04yContent-Disposition: file; filename="essayfile.txt"Content-Type: text/plain...contents of essayfile.txt...--BbC04yContent-Disposition: file; filename="imagefile.gif"Content-Type: image/gifContent-Transfer-Encoding: binary...contents of imagefile.gif...--BbC04y----AaB03x--15.4.4 Multipart Range Responses
- HTTP responses to range requests also can be multipart. Such responses come with a
Content-Type: multipart/byterangesheader and a multipart body with the different ranges. Here is an example of a multipart response to a request for different ranges of a document:
HTTP/1.0 206 Partial contentServer: Microsoft-IIS/5.0Date: Sun, 10 Dec 2000 19:11:20 GMTContent-Location: http://www.joes-hardware.com/gettysburg.txtContent-Type: multipart/x-byteranges; boundary=--[delimiter]--Last-Modified: Sat, 09 Dec 2000 00:38:47 GMT--[delimiter]--Content-Type: text/plainContent-Range: bytes 0-174/1441Fourscore and seven years ago our fathers brough forth on thiscontinenta new nation, conceived in liberty and dedicated to theproposition thatall men are created equal.--[delimiter]--Content-Type: text/plainContent-Range: bytes 552-761/1441But in a larger sense, we can not dedicate, we can notconsecrate,we can not hallow this ground. The brave men, living and deadwhostruggled here have consecrated it far above our poor power toaddor detract.--[delimiter]--Content-Type: text/plainContent-Range: bytes 1344-1441/1441and that government of the people, by the people, for thepeople shallnot perish from the earth.--[delimiter]--15.5 Content Encoding
- HTTP applications can encode content before sending it. E.g., a server might compress a large HTML document before sending it. Once the content is content-encoded, the encoded data is sent to the receiver in the entity body as usual.
15.5.1 The Content-Encoding Process
- The content-encoding process is:
- A web server generates an original response message with original Content-Type and Content-Length headers.
- A content-encoding server(perhaps the origin server or a downstream proxy) creates an encoded message that has the same Content-Type but may a different Content-Length. The content-encoding server adds a Content-Encoding header to the encoded message, so that a receiving application can decode it.
- A receiving program gets the encoded message, decodes it, and obtains the original.
Figure 15-3.

15.5.2 Content-Encoding Types
- HTTP defines some standard content-encoding types and allows for additional encodings to be added as extension encodings. Encodings are standardized through the IANA, which assigns a unique token to each content-encoding algorithm. The Content-Encoding header uses these standardized token values to describe the algorithm used in the encoding. Table 15-2.

15.5.3 Accept-Encoding Headers
- To prevent servers from using encodings that the client doesn’t support, the client passes a list of supported content encodings in the Accept-Encoding request header. If the HTTP request does not contain an Accept-Encoding header, a server can assume that the client will accept any encoding(equivalent to passing Accept-Encoding: *). Figure 15-4.

- The Accept-Encoding field contains a comma-separated list of supported encodings.
- Clients can indicate preferred encodings by attaching Q(quality) values that range from 0.0(the client does not want the associated encoding) to 1.0(the preferred encoding).
- “*” means “anything else.” Example:
Accept-Encoding: compress, gzipAccept-Encoding:Accept-Encoding: *Accept-Encoding: compress;q=0.5, gzip;q=1.0Accept-Encoding: gzip;q=1.0, identity; q=0.5, *;q=0- The identity encoding token can be present only in the Accept-Encoding header and is used by clients to specify relative preference over other content-encoding algorithms.
15.6 Transfer Encoding and Chunked Encoding
- Content encodings are reversible transformations that applied to the body of the message. They are tightly associated with the details of the particular content format.
- Transfer encodings are also reversible transformations performed on the entity body, but they are independent of the format of the content. You apply a transfer encoding to a message to change the way message data is transferred across the network (Figure 15-5).

15.6.1 Safe Transport
- Transfer encodings exist in other protocols to provide safe transport of messages across a network. The concept of safe transport has a different focus for HTTP, where the transport infrastructure is standardized and more forgiving. In HTTP, there are a few reasons why transporting message bodies can cause trouble. Two of these are:
- Unknown size
Some gateway applications and content encoders are unable to determine the final size of a message body without generating the content first. So, these servers would like to start sending the data before the size is known. Because HTTP requires the Content-Length header to precede the data, some servers apply a transfer encoding to send the data with a special terminating footer that indicates the end of data. - Security
You can use a transfer encoding to scramble the message content before sending it across a shared transport network. Because of the popularity of transport layer security schemes like SSL, transfer-encoding security isn’t very common.
- Unknown size
15.6.2 Transfer-Encoding Headers
- There are two defined headers to describe and control transfer encoding:
- Transfer-Encoding: Tells the receiver what encoding has been performed on the message in order for it to be safely transported.
- TE: Used in the request header to tell the server what extension transfer encodings are okay to use.
- In the following example, the request uses the TE header to tell the server that it accepts the chunked encoding(which it must if it’s an HTTP 1.1 application) and is willing to accept trailers on the end of chunk-encoded messages:
GET /new_products.html HTTP/1.1Host: www.joes-hardware.comUser-Agent: Mozilla/4.61 [en] (WinNT; I)TE: trailers, chunked...- The response includes a Transfer-Encoding header to tell the receiver that the message has been transfer-encoded with the chunked encoding:
HTTP/1.1 200 OKTransfer-Encoding: chunkedServer: Apache/3.0...- After this initial header, the structure of the message will change.
- All transfer-encoding values are case-insensitive. HTTP/1.1 uses transfer-encoding values in the TE header field and in the Transfer-Encoding header field. The latest HTTP specification defines only one transfer encoding, chunked encoding.
- The TE header, like the Accept-Encoding header, can have Q values to describe preferred forms of transfer encoding. The HTTP/1.1 specification forbids the association of a Q value of 0.0 to chunked encoding.
15.6.3 Chunked Encoding
- Chunked encoding breaks messages into chunks of known size. Each chunk is sent one after another, eliminating the need for the size of the full message to be known before it is sent.
- Chunked encoding is a form of transfer encoding and therefore is an attribute of the message, not the body. Multipart encoding is an attribute of the body and is completely separate from chunked encoding.
15.6.3.1 Chunking and persistent connections
- When the connection between the client and server is not persistent, clients do not need to know the size of the body they are reading since they expect to read the body until the server closes the connection.
- With persistent connections, the size of the body must be known and sent in the Content-Length header before the body can be written. When content is dynamically created at a server, it may not be possible to know the length of the body before sending it.
- Chunked encoding provides a solution for this dilemma by allowing servers to send the body in chunks, specifying only the size of each chunk. As the body is dynamically generated, a server can buffer up a portion of it, send its size and the chunk, and then repeat the process until the full body has been sent. The server can signal the end of the body with a chunk of size 0 and still keep the connection open and ready for the next response.

- Figure 15-6. It begins with an initial HTTP response header block, followed by a stream of chunks. Each chunk contains a length value and the data for that chunk. The length value is in hexadecimal form and is separated from the chunk data with a CRLF. The size of the chunk data is measured in bytes and includes neither the CRLF sequence between the length value and the data nor the CRLF sequence at the end of the chunk. The last chunk has a length of zero, which signifies “end of body.”
- A client can send chunked data to a server. Because the client does not know beforehand whether the server accepts chunked encoding(servers do not send TE headers in responses to clients), it must be prepared for the server to reject the chunked request with a 411 Length Required response.
15.6.3.2 Trailers in chunked messages
- A trailer can be added to a chunked message if the client’s TE header indicates that it accepts trailers, or if the trailer is added by the server that created the original response and the contents of the trailer are optional meta-data that it is not necessary for the client to understand and use(it is okay for the client to ignore and discard the contents of the trailer).
- The trailer can contain additional header fields whose values might not have been known at the start of the message. An example is the Content-MD5 header. The message headers contain a Trailer header listing the headers that will follow the chunked message. The last chunk is followed by the headers listed in the Trailer header.
- Any of the HTTP headers can be sent as trailers, except for the Transfer-Encoding, Trailer, and Content-Length headers.
15.6.4 Combining Content and Transfer Encodings
- Content encoding and transfer encoding can be used simultaneously. Figure 15-7 illustrates how a sender can compress an HTML file using a content encoding and send the data chunked using a transfer encoding. The process to “reconstruct” the body is reversed on the receiver.

15.6.5 Transfer-Encoding Rules
- When a transfer encoding is applied to a message body, some rules must be followed:
- The set of transfer encodings must include “chunked.” The only exception is if the message is terminated by closing the connection.
- When the chunked transfer encoding is used, it is required to be the last transfer encoding applied to the message body.
- The chunked transfer encoding must not be applied to a message body more than once.
- These rules allow the recipient to determine the transfer length of the message.
15.7 Time-Varying Instances
- The same URL can point to different versions of an object over time. Think of the web page as being an object and its different versions as being different instances of the object(Figure 15-8). The client in the figure requests the same resource(URL) multiple times, but it gets different instances of the resource as it changes over time.

- The HTTP protocol specifies operations for a class of requests and responses, called instance manipulations, that operate on instances of an object. The two main methods are range requests and delta encoding. Both methods require clients to be able to identify the exact copy of the resource that they have(if any) and request new instances conditionally.
15.8 Validators and Freshness
- The client does not initially have a copy of the resource, so it sends a request to the server asking for it. The server responds with Version 1 of the resource. The client can now cache this copy with a limited time.
- Once the client no longer consider its copy valid, it must request a fresh copy from the server. If the document has not changed at the server, the client does not need to receive it and it can continue to use its cached copy.
- This special request, called a conditional request, requires that the client tell the server which version it currently has, using a validator, and ask for a copy to be sent only if its current copy is no longer valid.
15.8.1 Freshness
- Servers can offer clients information about how long clients can cache their content and consider it fresh by using one of two headers: Expires and Cache-Control.
- The Expires header specifies the date and time at which the document expires and it can no longer be considered fresh.
Syntax:Expires: Sun Mar 18 23:59:59 GMT 2001
For a client and server to use the Expires header correctly, their clocks must be synchronized. This is hard because neither may run a clock synchronization protocol. So, defines expiration using relative time is more useful. - The Cache-Control header specifies the maximum age for a document in seconds that is the total amount of time since the document left the server. It can be used by both servers and clients to describe freshness using more directives than just specifying an age or expiration time. Table 15-3.

15.8.2 Conditionals and Validators
- When a cache’s copy is requested, and it is no longer fresh, the cache needs to make sure it has a fresh copy. The cache can fetch the current copy from the origin server, but in many cases, the document on the server is still the same as the stale copy in the cache.
- Figure 15-8b: the cached copy have expired, but the server content still is the same as the cache content. If a cache always fetches a server’s document, even if it’s the same as the expired cache copy, the cache wastes network bandwidth, places unnecessary load on the cache and server.
- Fix: HTTP provides a way for clients to request a copy only if the resource has changed by using conditional requests. Conditional requests are normal HTTP request messages that are performed only if a particular condition is true. A cache might send the following conditional GET message to a server, asking it to send the file /announce.html only if the file has been modified since June 29, 2002(the date the cached document was last changed by the author):
GET /announce.html HTTP/1.0If-Modified-Since: Sat, 29 Jun 2002, 14:30:00 GMT- Conditional requests are implemented by conditional headers that start with “If-“. A conditional header allows a method to execute only if the condition is true. If the condition is not true, the server sends an HTTP error code back.
- Each conditional works on a particular validator that is an attribute of the document instance that is tested. The If-Modified-Since conditional header tests the last-modified date, so the last-modified date is the validator. The If-None-Match conditional header tests the ETag value of a document. Last-Modified and ETag are the two primary validators used by HTTP. Table 15-4.

- HTTP groups validators into two classes: weak validators and strong validators: weak validators may not always uniquely identify an instance of a resource, strong validators must.
Example of weak validator is the size of the object in bytes: the resource content might change even if the size remains the same. A checksum of the contents of the resource(such as MD5) is a strong validator; it changes when the document changes. - The last-modified time is considered a weak validator because it specifies that time to an accuracy of at most one second. Because a resource can change multiple times in a second, and because servers can serve thousands of requests per second, the last-modified date might not always reflect changes.
- The ETag header is considered a strong validator because the server can place a distinct value in the ETag header every time a value changes. Version numbers and digest checksum are good candidates for the ETag header, but they can contain any arbitrary text. ETag headers are flexible; they take arbitrary text values(“tags”), and can be used to devise a variety of client and server validation strategies.
- Clients and servers may want to adopt a looser version of entity-tag validation. E.g., a server may want to make changes to a large, popular cached document without triggering a mass transfer when caches revalidate. In this case, the server advertise a weak entity tag by prefixing the tag with “W/”. A weak entity tag should change only when the associated entity changes in a semantically significant way. A strong entity tag must change whenever the associated entity value changes in any way.
- The following example shows how a client might revalidate with a server using a weak entity tag. The server would return a body only if the content changed in a meaningful way from Version 4.0 of the document:
GET /announce.html HTTP/1.1If-None-Match: W/"v4.0"- Summary:
- When clients access the same resource more than once, they first need to determine whether their current copy still is fresh.
- If it is not, they must get the latest version from the server.
- To avoid receiving an identical copy, clients can send conditional requests to the server, specifying validators that uniquely identify their current copies.
- Servers will send a copy of the resource only if it is different from the client’s copy.
15.9 Range Requests
- HTTP allows clients to request part or a range of a document.
- Suppose you were three-fourths of the way through downloading xxx, and a network interrupted your connection. With range requests, an HTTP client can resume downloading an entity by asking for the range or part of the entity it failed to get (provided that the object did not change at the origin server between the time the client first requested it and its subsequent range request).
GET /bigfile.html HTTP/1.1Host: www.joes-hardware.comRange: bytes=4000-User-Agent: Mozilla/4.61 [en] (WinNT; I)...- The client is requesting the remainder of the document after the first 4,000 bytes. The end bytes do not have to be specified because the size of the document may not be known to the requester.
- The Range header can be used to request multiple ranges(the ranges can be specified in any order and may overlap).
- Servers can advertise to clients that they accept ranges by including the header Accept-Ranges in their responses. The value of this header is the unit of measure in bytes.
HTTP/1.1 200 OKDate: Fri, 05 Nov 1999 22:35:15 GMTServer: Apache/1.2.4Accept-Ranges: bytes...- Figure 15-9 shows an example of a set of HTTP transactions involving ranges.
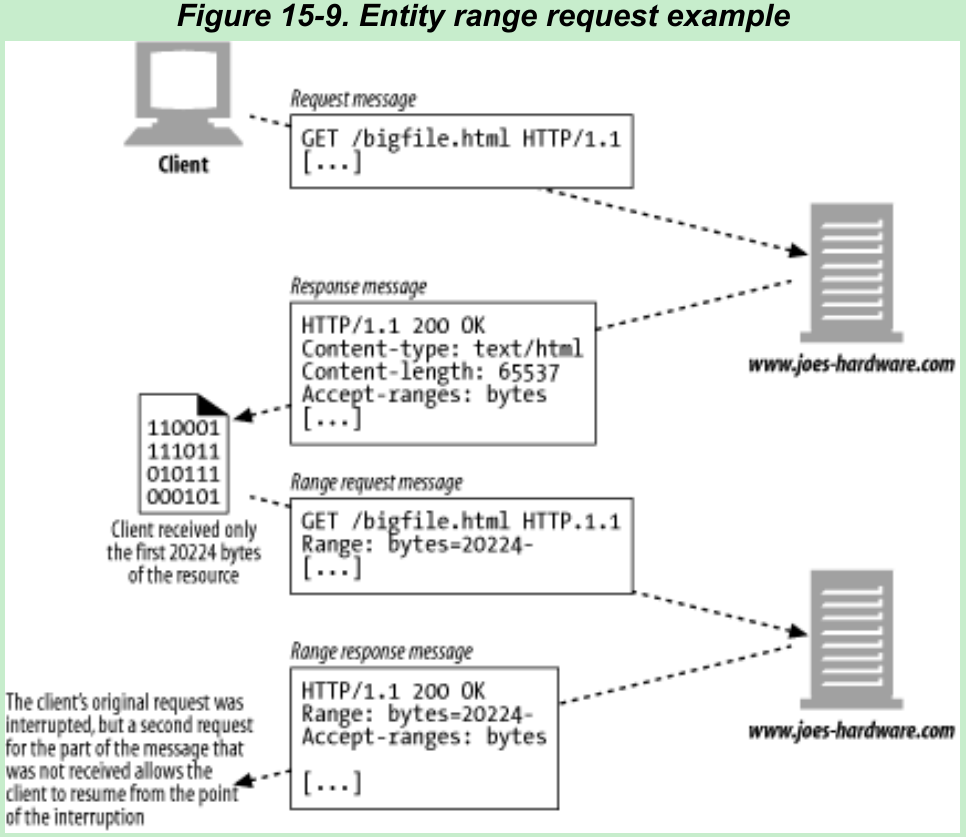
- Range headers are used extensively by peer-to-peer file-sharing client software to download different parts of multimedia files simultaneously from different peers.
- Range requests are a class of instance manipulations because they are exchanges between a client and a server for an instance of an object. A client’s range request makes sense only if the client and server have the same version of a document.
15.10 Delta Encoding
- If a client has an expired copy of a page, it requests the latest instance of the page. If the server has a newer instance of the page, it will send it to the client, and it will send the full new instance of the page even if only a small portion of the page actually has changed.
- The client would get the page faster if the server only sent the changes to the client’s copy of the page. Delta encoding is an extension to the HTTP protocol that optimizes transfers by communicating changes instead of entire objects. Delta encoding is a type of instance manipulation because it relies on clients and servers exchanging information about particular instances of an object.

- Figure 15-10 illustrates the mechanism of requesting, generating, receiving, and applying a delta-encoded document.
- The client has to tell the server which version of the page it has, that it is willing to accept a delta from the latest version of page, and which algorithms it knows for applying those deltas to its current version.
- The server has to check if it has the client’s version of the page and how to compute deltas from the latest version and the client’s version(there are several algorithms for computing the difference between two objects). It then has to compute the delta, send it to the client, let the client know that it’s sending a delta, and specify the new identifier for the latest version of the page(because this is the version that the client will end up with after it applies the delta to its old version).
- The client uses the unique identifier for its version of the page(sent by the server in its previous response to the client in the ETag header) in an If-None-Match header. This is the client’s way of telling the server, “if the latest version of the page you have does not have this same ETag, send me the latest version of the page.” Just the If-None-Match header would cause the server to send the client the full latest version of the page(if it was different from the client’s version).
- The client can tell the server that it is willing to accept a delta of the page by sending an A-IM(Accept-Instance-Manipulation) header. In the A-IM header, the client specifies the algorithms it knows how to apply in order to generate the latest version of a page given an old version and a delta. The server sends back the following: a special response code(226 IM Used) telling the client that it is sending it an instance manipulation of the requested object, not the full object itself; an IM(short for Instance-Manipulation) header, which specifies the algorithm used to compute the delta; the new ETag header; and a Delta-Base header, which specifies the ETag of the document used as the base for computing the delta(ideally, the same as the ETag in the client’s If-None-Match request!). The headers used in delta encoding are summarized in Table 15-5.

15.10.1 Instance Manipulations, Delta Generators, and Delta Appliers
- Clients can specify the types of instance manipulation they accept using the A-IM header. Servers specify the type of instance manipulation used in the IM header. Table 15-6 lists some of the IANA registered types of instance manipulations.

- A “delta generator” at the server, as in Figure 15-10, takes the base document and the latest instance of the document and computes the delta between the two using the algorithm specified by the client in the A-IM header.
- At the client side, a “delta applier” takes the delta and applies it to the base document to generate the latest instance of the document. E.g., if the algorithm used to generate the delta is the Unix diff -e command, the client can apply the delta using the functionality of the Unix ed text editor, because
diff -e <file1> <file2>
generates the set of ed commands that will convert into . - In the example in Figure 15-10, 5c says delete line 5 in the base document, and chisels.. says add “chisels.”. The Unix diff -e algorithm does a line-by-line comparison of files.
- This is okay for text files but breaks down for binary files. The vcdiff algorithm works even for non-text files and generally producing smaller deltas than diff -e.
- The delta encoding specification defines the format of the A-IM and IM headers in detail. Suffice it to say that multiple instance manipulations can be specified in these headers(along with corresponding quality values). Documents can go through multiple instance manipulations before being returned to clients, in order to maximize compression. E.g., deltas generated by the vcdiff algorithm may in turn be compressed using the gzip algorithm. The server response would then contain the header IM: vcdiff, gzip. The client would first gunzip the content, then apply the results of the delta to its base page in order to generate the final document.
- Delta encoding can reduce transfer times, but it can be tricky to implement. Imagine a page that changes frequently and is accessed by many different people. A server supporting delta encoding must keep all the different copies of that page as it changes over time, in order to figure out what’s changed between any requesting client’s copy and the latest copy.(If the document changes frequently, as different clients request the document, they will get different instances of the document. When they make subsequent requests to the server, they will be requesting changes between their instance of the document and the latest instance of the document. To be able to send them just the changes, the server must keep copies of all the previous instances that the clients have.) In exchange for reduced latency in serving documents, servers need to increase disk space to keep old instances of documents around. The extra disk space necessary to do so may quickly negate the benefits from the smaller transfer amounts.
15.11 For More Information
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
0 0
- 15-Entities and Encodings
- Charsets and encodings
- Description of graph6 and sparse6 encodings
- Chapter 8 Accessing the Entities and View Entities
- Entities and Entities's Relation Extraction of ACE 2005
- Extraction of Entities and Relations调研
- Entities, Bundles,Fields and Field instance
- Returning multiple entities and Alias injection names
- unicode Entities for Symbols and Greek Letters
- Introducing Character Sets and Encodings(字符集与编码介绍)
- Ruby 1.9 Encodings: A Primer and the Solution for Rails
- incompatible character encodings: UTF-8 and ASCII-8BIT
- LINQ to SQL and Disconnected Entities Follow-up
- ISO 8859-1 Characters as Named and Numeric HTML Entities
- Create stored procedure and integrate it into linq to entities
- ADO.Net Linq to SQL and Linq to Entities Note
- Character Encodings
- Type Encodings
- Makefile中指示符“include”、“-include”和“sinclude”的区别
- js/jquery判断浏览器类型的方法小结
- 第十二章 Boolean()
- 未完成
- Eclipse- Dynamic Web Module 3.0 requires Java 1.6 错误
- 15-Entities and Encodings
- oracle sql 按日,周,月,年统计
- HDU 2492 PingPong (树状数组)
- 第十三章 使用原始值:字符串、数字和布尔值
- Java代码片段留存
- Java设计模式--适配器(Adapter)模式
- 求1234四个数能组成多少互不相同且不重复的三位数
- 第十四章 null
- svn中 更新,提交,与资源库同步分别会有什么效果


