深入浅出的理解Android网络请求框架
来源:互联网 发布:mac视频电脑怎么截图 编辑:程序博客网 时间:2024/05/22 15:40
以前在写网络请求的时候,我们经常干的一件事情就是首先开启一个线程,然后创建一个Handler将网络请求的操作放到一个线程中去执行。因为大家都知道网络请求是一个耗时的操作,不能放在主线程中去执行,但是我们发现我们用框架去处理网络请求的时候,代码量确实非常的少同时还不用写那些繁琐的Handler去处理数据,只需要一个回调接口就可以处理我们的一些业务逻辑就可以了。现在就来分析一下这其中的来龙去脉,因为我平时用的比较多的请求框架是 async-http,这里我就对这个框架进行分析一下: https://github.com/loopj/android-async-http
根据它官方的例子,我们介绍一下它最基本的大概的用法:
AsyncHttpClient httpClient = new AsyncHttpClient(); httpClient.get("http://www.baidu.com", new AsyncHttpResponseHandler() { @Override public void onSuccess(int code, Header[] headers, byte[] responseBody) { //请求成功的回调处理 } @Override public void onFailure(int code, Header[] headers, byte[] responseBody, Throwable error){ //请求失败的回调处理 } });我们平时在使用网络请求框架的时候见到最多的形式就是这种模式,一个回调接口,然后一个请求的url地址,在福州一些的话,可能会有一些什么请求头之类的等等,而且为什么人家就不需要使用繁琐的Handler呢?而且还可以在回调方法中更新UI界面的。下面就进入代码中看看。
1. 首先创建一个AsyncHttpClient对象
public AsyncHttpClient() { this(false, 80, 443);}public AsyncHttpClient(int httpPort) { this(false, httpPort, 443);}public AsyncHttpClient(int httpPort, int httpsPort) { this(false, httpPort, httpsPort);}public AsyncHttpClient(boolean fixNoHttpResponseException, int httpPort, int httpsPort) { this(getDefaultSchemeRegistry(fixNoHttpResponseException, httpPort, httpsPort));}public AsyncHttpClient(SchemeRegistry schemeRegistry) { BasicHttpParams httpParams = new BasicHttpParams(); ConnManagerParams.setTimeout(httpParams, connectTimeout); ConnManagerParams.setMaxConnectionsPerRoute(httpParams, new ConnPerRouteBean(maxConnections)); ConnManagerParams.setMaxTotalConnections(httpParams, DEFAULT_MAX_CONNECTIONS); HttpConnectionParams.setSoTimeout(httpParams, responseTimeout); HttpConnectionParams.setConnectionTimeout(httpParams, connectTimeout); HttpConnectionParams.setTcpNoDelay(httpParams, true); HttpConnectionParams.setSocketBufferSize(httpParams, DEFAULT_SOCKET_BUFFER_SIZE); HttpProtocolParams.setVersion(httpParams, HttpVersion.HTTP_1_1); ClientConnectionManager cm = createConnectionManager(schemeRegistry, httpParams); threadPool = getDefaultThreadPool(); requestMap = Collections.synchronizedMap(new WeakHashMap<Context, List<RequestHandle>>()); clientHeaderMap = new HashMap<String, String>(); httpContext = new SyncBasicHttpContext(new BasicHttpContext()); httpClient = new DefaultHttpClient(cm, httpParams); httpClient.addRequestInterceptor(new HttpRequestInterceptor() { @Override public void process(HttpRequest request, HttpContext context) { ...... } }); httpClient.addResponseInterceptor(new HttpResponseInterceptor() { @Override public void process(HttpResponse response, HttpContext context) { ...... } }); httpClient.addRequestInterceptor(new HttpRequestInterceptor() { @Override public void process(final HttpRequest request, final HttpContext context) { ...... } }, 0); httpClient.setHttpRequestRetryHandler(new RetryHandler(DEFAULT_MAX_RETRIES, DEFAULT_RETRY_SLEEP_TIME_MILLIS));}构造方法中主要做了以下的事情:
1、四个构造方法分别对http和https的端口设定,同时也对http和https注册Scheme
2、创建httpclient、httpContext对象,同时设置httpclient的读取数据超时的时间、连接超时的时间、http协议的版本号、socket缓存大小
3、对httpclient设置重试次数以及重试的时间间隔,同时为HttpClient添加Request 拦截器以及Response 拦截器,创建Cached ThreadPool线程池.
4、对httpclient设置重试的处理方式 setHttpRequestRetryHandler(),我们这里自定义了一个重试处理的类RetryHandler;
2.接下来就是为get 方法请求网络做准备工作
public RequestHandle get(String url, RequestParams params, ResponseHandlerInterface responseHandler) { return get(null, url, params, responseHandler);}/** * Perform a HTTP GET request and track the Android Context which initiated the request. * * @param context the Android Context which initiated the request. * @param url the URL to send the request to. * @param params additional GET parameters to send with the request. * @param responseHandler the response handler instance that should handle the response. * @return RequestHandle of future request process */public RequestHandle get(Context context, String url, RequestParams params, ResponseHandlerInterface responseHandler) { return sendRequest(httpClient, httpContext, new HttpGet(getUrlWithQueryString(isUrlEncodingEnabled, url, params)), null, responseHandler, context);}1、首先是将请求的参数进行拆分然后转化成一个字符串
2、将url进行decode,然后按照指定的规则再将请求参数拼接到url的后面
public static String getUrlWithQueryString(boolean shouldEncodeUrl, String url, RequestParams params) { if (url == null) return null; if (shouldEncodeUrl) {//这里默认是需要开启 url encode 功能的。 try { String decodedURL = URLDecoder.decode(url, "UTF-8"); URL _url = new URL(decodedURL); URI _uri = new URI(_url.getProtocol(), _url.getUserInfo(), _url.getHost(), _url.getPort(), _url.getPath(), _url.getQuery(), _url.getRef()); url = _uri.toASCIIString(); } catch (Exception ex) { log.e(LOG_TAG, "getUrlWithQueryString encoding URL", ex); } } if (params != null) { //首先我们之前设置的请求进行分解,然后将这些请求信息拼接成一个字符串。 String paramString = params.getParamString().trim(); //我们都知道平时浏览器中的请求地址后面是url + ? + params,这里也这么处理的 如果有 ? 存在的话表示之前就跟有请求参数了,如果还没有问题,就添加问号并且添加请求参数 if (!paramString.equals("") && !paramString.equals("?")) { url += url.contains("?") ? "&" : "?"; url += paramString; } } return url;}3.正式的请求网络操作
protected RequestHandle sendRequest(DefaultHttpClient client, HttpContext httpContext, HttpUriRequest uriRequest, String contentType, ResponseHandlerInterface responseHandler, Context context) { //1、首先一上来就对uriRequest, responseHandler参数为空检查 ...... //2、然后接着就是判断Content-Type类型,设置到请求头中去 if (contentType != null) { if (uriRequest instanceof HttpEntityEnclosingRequestBase && ((HttpEntityEnclosingRequestBase) uriRequest).getEntity() != null && uriRequest.containsHeader(HEADER_CONTENT_TYPE)) { log.w(LOG_TAG, "Passed contentType will be ignored because HttpEntity sets content type"); } else { uriRequest.setHeader(HEADER_CONTENT_TYPE, contentType); } } //3、接着就是将请求参数和请求的url地址保存到responseHandler responseHandler.setRequestHeaders(uriRequest.getAllHeaders()); responseHandler.setRequestURI(uriRequest.getURI()); 4、接着就是创建一个请求任务了,也就是HttpRequest. AsyncHttpRequest request = newAsyncHttpRequest(client, httpContext, uriRequest, contentType, responseHandler, context); 5、然后将任务扔到之前创建的中的线程池中去执行. threadPool.submit(request); RequestHandle requestHandle = new RequestHandle(request); ....... return requestHandle;}通过上面的代码中,我们还是非常的懵懂的不清楚具体的请求网络是在哪里,我们知道了 AsyncHttpRequest 任务是在线程池中在执行了,那么我们就有一点是非常的肯定的认为该类基本上是实现了Runnable接口的,所以请求的操作肯定是在 AsyncHttpRequest 中处理的。
@Overridepublic void run() { //首先是检查是否是取消 if (isCancelled()) { return; } ...... //这里这个 responseHandler 只是一个回调接口,别被这个给迷惑了 responseHandler.sendStartMessage(); try { makeRequestWithRetries(); } catch (IOException e) { if (!isCancelled()) { //这里是处理请求失败的回调结果 responseHandler.sendFailureMessage(0, null, null, e); } else { AsyncHttpClient.log.e("AsyncHttpRequest", "makeRequestWithRetries returned error", e); } } //执行完毕之后的回调接口 responseHandler.sendFinishMessage(); ......}private void makeRequestWithRetries() throws IOException { boolean retry = true; IOException cause = null; HttpRequestRetryHandler retryHandler = client.getHttpRequestRetryHandler(); try { while (retry) { try { makeRequest(); return; } catch (UnknownHostException e) { // switching between WI-FI and mobile data networks can cause a retry which then results in an UnknownHostException // while the WI-FI is initialising. The retry logic will be invoked here, if this is NOT the first retry // (to assist in genuine cases of unknown host) which seems better than outright failure cause = new IOException("UnknownHostException exception: " + e.getMessage(), e); retry = (executionCount > 0) && retryHandler.retryRequest(e, ++executionCount, context); } catch (NullPointerException e) { // there's a bug in HttpClient 4.0.x that on some occasions causes // DefaultRequestExecutor to throw an NPE, see // https://code.google.com/p/android/issues/detail?id=5255 cause = new IOException("NPE in HttpClient: " + e.getMessage()); retry = retryHandler.retryRequest(cause, ++executionCount, context); } catch (IOException e) { if (isCancelled()) { // Eating exception, as the request was cancelled return; } cause = e; retry = retryHandler.retryRequest(cause, ++executionCount, context); } if (retry) { responseHandler.sendRetryMessage(executionCount); } } } catch (Exception e) { // catch anything else to ensure failure message is propagated AsyncHttpClient.log.e("AsyncHttpRequest", "Unhandled exception origin cause", e); cause = new IOException("Unhandled exception: " + e.getMessage(), cause); } // cleaned up to throw IOException throw (cause);}从上面的代码中我们可以看出只要makeRequest函数不抛出异常的话就直接返回也就不走循环了,要是在请求的过程中出现了问题的话,那么捕获异常并且检查重试的次数,要是次数达到了指定的重试的次数之后就跳出整个循环,并且抛出一个异常让调用者去处理就可以了。接下来我们来看看人家是如何处理重试的问题的,当然这个重试的问题我也可以自己利用一个循环去处理的,但是既然Httpclient已经提供了解决方案给我们,我也就可以直接继承人家的方案就可以了。
class RetryHandler implements HttpRequestRetryHandler {private final static HashSet<Class<?>> exceptionWhitelist = new HashSet<Class<?>>();private final static HashSet<Class<?>> exceptionBlacklist = new HashSet<Class<?>>();static { // Retry if the server dropped connection on us exceptionWhitelist.add(NoHttpResponseException.class); // retry-this, since it may happens as part of a Wi-Fi to 3G failover exceptionWhitelist.add(UnknownHostException.class); // retry-this, since it may happens as part of a Wi-Fi to 3G failover exceptionWhitelist.add(SocketException.class); // never retry timeouts exceptionBlacklist.add(InterruptedIOException.class); // never retry SSL handshake failures exceptionBlacklist.add(SSLException.class);}private final int maxRetries;private final int retrySleepTimeMS;public RetryHandler(int maxRetries, int retrySleepTimeMS) { this.maxRetries = maxRetries; this.retrySleepTimeMS = retrySleepTimeMS;}.....@Overridepublic boolean retryRequest(IOException exception, int executionCount, HttpContext context) { boolean retry = true; if (executionCount > maxRetries) { // Do not retry if over max retry count retry = false; } else if (isInList(exceptionWhitelist, exception)) { // immediately retry if error is whitelisted retry = true; } else if (isInList(exceptionBlacklist, exception)) { // immediately cancel retry if the error is blacklisted retry = false; } else if (!sent) { // for most other errors, retry only if request hasn't been fully sent yet retry = true; } ...... if (retry) { SystemClock.sleep(retrySleepTimeMS); } else { exception.printStackTrace(); } return retry;}protected boolean isInList(HashSet<Class<?>> list, Throwable error) { for (Class<?> aList : list) { if (aList.isInstance(error)) { return true; } } return false;}}
首先在构造方法中就有了两个set集合用于存放哪些白名单异常和黑名单异常,所谓的白名单的异常是指一些网络切换时出现的问题,服务器端的异常,这个时候出现异常的话我们就需要重试请求;所谓的黑名单异常就是比如说https的验证出现了问题了,还有就是中断异常,这个时候出现这个异常的时候我们就不需要进行重试了,因为你重试也没用处的,会一直的失败,还不如节省时间。我们在调用 retryRequest()方法的时候,会传入一个异常对象,还有就是次数,然后就是httpContext,传入的次数主要是用于跟我们之前设置的的最大重试次数比较。然后传入的异常看看该异常是否是白名单还是黑名单的来决定是否重试的,最后我们还看到了一个重试的间隔时间,SystemClock.sleep() 函数最后其实还是调用的Thread.sleep(),只是对这个进行了封装一下而已。
在研究完重试机制之后我们接着刚才的网络请求来看看,因为我们只看到了处理开始的消息和结束的消息,但是我们并没有看到真正的网络请求的信息。
private void makeRequest() throws IOException { ...... // Fixes #115 if (request.getURI().getScheme() == null) { // subclass of IOException so processed in the caller throw new MalformedURLException("No valid URI scheme was provided"); } if (responseHandler instanceof RangeFileAsyncHttpResponseHandler) { ((RangeFileAsyncHttpResponseHandler) responseHandler).updateRequestHeaders(request); } HttpResponse response = client.execute(request, context); ...... // The response is ready, handle it. responseHandler.sendResponseMessage(response); ..... // Carry out post-processing for this response. responseHandler.onPostProcessResponse(responseHandler, response);}从上面的代码中是不是可以很简单的看出 client.execute()才是真正的执行网络请求的,然后拿到HttpResponse,紧接着就用接口回调函数将该接口扔出去了,然后实现ResponseHandlerInterface 接口的类去处理接口了,然后我们再回到我们我们最开始的例子中,我们在请求网络的时候是传入了AsyncHttpResponseHandler 类型的。下面我们就来看看这个类做了什么处理的。
private Handler handler;public abstract class AsyncHttpResponseHandler implements ResponseHandlerInterface { public AsyncHttpResponseHandler() { this(null); } public AsyncHttpResponseHandler(Looper looper) { // Do not use the pool's thread to fire callbacks by default. this(looper == null ? Looper.myLooper() : looper, false); } private AsyncHttpResponseHandler(Looper looper, boolean usePoolThread) { if (!usePoolThread) { this.looper = looper; // Create a handler on current thread to submit tasks this.handler = new ResponderHandler(this, looper); } else { // If pool thread is to be used, there's no point in keeping a reference // to the looper and handler. this.looper = null; this.handler = null; } this.usePoolThread = usePoolThread; }}从上面的构造方法中,我们发现这个类基本上是非常的简单的,因为 AsyncHttpResponseHandler 是在主线程中创建的,因此Looper.myLooper()也是MainLooper的,所以我们知道这里的Handler是在主线程中定义的。下面我们来看看之前请求完网络的之后,然后就调用了接口的回调结果:sendResponseMessage(),所以我们就寻找一下类中的这个方法。
@Overridepublic void sendResponseMessage(HttpResponse response) throws IOException { // do not process if request has been cancelled if (!Thread.currentThread().isInterrupted()) { StatusLine status = response.getStatusLine(); byte[] responseBody; responseBody = getResponseData(response.getEntity()); // additional cancellation check as getResponseData() can take non-zero time to process if (!Thread.currentThread().isInterrupted()) { if (status.getStatusCode() >= 300) { sendFailureMessage(status.getStatusCode(), response.getAllHeaders(), responseBody, new HttpResponseException(status.getStatusCode(), status.getReasonPhrase())); } else { sendSuccessMessage(status.getStatusCode(), response.getAllHeaders(), responseBody); } } }}/** * Returns byte array of response HttpEntity contents * * @param entity can be null * @return response entity body or null * @throws java.io.IOException if reading entity or creating byte array failed */byte[] getResponseData(HttpEntity entity) throws IOException { byte[] responseBody = null; if (entity != null) { InputStream instream = entity.getContent(); if (instream != null) { long contentLength = entity.getContentLength(); /** *获取字节流的长度,如果字节流的长度大于整数的最大值的话就直接抛出异常, *对于一般的网络数据的话没有这么大的,除非是下载的,作者在这里就直接做了处理 */ if (contentLength > Integer.MAX_VALUE) { throw new IllegalArgumentException("HTTP entity too large to be buffered in memory"); } int buffersize = (contentLength <= 0) ? BUFFER_SIZE : (int) contentLength; try { ByteArrayBuffer buffer = new ByteArrayBuffer(buffersize); try { byte[] tmp = new byte[BUFFER_SIZE]; long count = 0; int l; // do not send messages if request has been cancelled while ((l = instream.read(tmp)) != -1 && !Thread.currentThread().isInterrupted()) { count += l; buffer.append(tmp, 0, l); sendProgressMessage(count, (contentLength <= 0 ? 1 : contentLength)); } } finally { AsyncHttpClient.silentCloseInputStream(instream); AsyncHttpClient.endEntityViaReflection(entity); } responseBody = buffer.toByteArray(); } catch (OutOfMemoryError e) { System.gc(); throw new IOException("File too large to fit into available memory"); } } } return responseBody;}这里就比较简单了也就是我们平时所说的对于一个字节输入流的处理了,只不过是坐着这里利用了ByteArrayBuffer,中间利用了一个字节数组作为过渡,这样子就可以大大的提高读取的速度,最后在转换成一个字节数组返回出去,回到sendResponseMessage 方法中我们对statusCode进行判断,如果返回的状态码 >= 300的话那么我们就可以断定这个请求是失败的了,具体的问题大家去看看http协议就清楚了;接下来看看发送消息函数是如何处理的。
final public void sendSuccessMessage(int statusCode, Header[] headers, byte[] responseBytes) { sendMessage(obtainMessage(SUCCESS_MESSAGE, new Object[]{statusCode, headers, responseBytes}));}protected Message obtainMessage(int responseMessageId, Object responseMessageData) { return Message.obtain(handler, responseMessageId, responseMessageData);}protected void sendMessage(Message msg) { if (getUseSynchronousMode() || handler == null) { handleMessage(msg); } else if (!Thread.currentThread().isInterrupted()) { // do not send messages if request has been cancelled Utils.asserts(handler != null, "handler should not be null!"); handler.sendMessage(msg); }}protected void handleMessage(Message message) { Object[] response; try { switch (message.what) { case SUCCESS_MESSAGE: response = (Object[]) message.obj; if (response != null && response.length >= 3) { onSuccess((Integer) response[0], (Header[]) response[1], (byte[]) response[2]); } else { log.e(LOG_TAG, "SUCCESS_MESSAGE didn't got enough params"); } break; case FAILURE_MESSAGE: response = (Object[]) message.obj; if (response != null && response.length >= 4) { onFailure((Integer) response[0], (Header[]) response[1], (byte[]) response[2], (Throwable) response[3]); } else { log.e(LOG_TAG, "FAILURE_MESSAGE didn't got enough params"); } break; case START_MESSAGE: onStart(); break; case FINISH_MESSAGE: onFinish(); break; case PROGRESS_MESSAGE: response = (Object[]) message.obj; if (response != null && response.length >= 2) { try { onProgress((Long) response[0], (Long) response[1]); } catch (Throwable t) { log.e(LOG_TAG, "custom onProgress contains an error", t); } } else { log.e(LOG_TAG, "PROGRESS_MESSAGE didn't got enough params"); } break; case RETRY_MESSAGE: response = (Object[]) message.obj; if (response != null && response.length == 1) { onRetry((Integer) response[0]); } else { log.e(LOG_TAG, "RETRY_MESSAGE didn't get enough params"); } break; case CANCEL_MESSAGE: onCancel(); break; } } catch (Throwable error) { onUserException(error); }}从这里我们就可以一目了然的看到了原来所有的讨论都是这样子的,首先封装一个Message消息体,然后消息中包装了了一个Object数组,将我们刚才获取到的信息全部放到数组中的,最后使用handler.sendMessage()发出去,然后这些都是我们平时的一些很平常的代码了,最后在调用抽象方法 onSuccess() 方法了。这个就是我们例子中的重写onSuccess 方法,并且能在这个方法中更新UI界面的原因,现在我们知道了为什么第三方的框架为啥可以在回调接口中进行 UI 更新了吧:其实人家最后还是用了Handler去处理主线程与子线程的这种数据交互,只是人家内部把这个Handler封装起来了,然后处理消息之后,通过抽象方法或者是接口将最后的结果回调出来,让实现类去处理具体的业务逻辑了。
总结
最后我画一张图来简单的描述一下网络请求的一个基本原理,用一个非常生动的工厂的例子来说明一下。 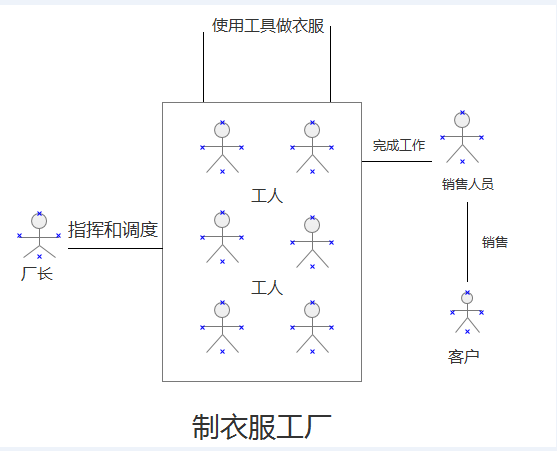
根据上面的图我们来做一个比喻:
- 线程池 ————————> 厂长
- 工人 —————————> 任务(实现Runnable接口的任务)
- 制衣服的工具 ——-———> 比作网络请求的基本工具(也就是代码中 HttpClient等等一系列吧)
- 客户 —————————> 比作 主线程中的要做的事情
- 销售人员 ———————> 比作 Handler 也就是传达事情的信使
- 工程师 ————————> 比作 老板,这个时候我们就协调好各个的环节,同时我们还要告诉使用工具的一些细节,毕竟工具太高级了嘛,所以需要告诉工人如何正确的使用工具才能更快更好的制好衣服的嘛。
我们编码的过程的其实也就是一个高级的搬砖的活,我们要协调各个部门的关系,同时我们还要教工人们如何正确的使用工具,该如何配置工具(网络请求的最基本的工具 httpClient或者是HttpUrlConnection)的哪些参数,同时还要把握各个制衣服和销售衣服的各个环节。厂长就好比线程池一样来管理工人(任务),将工人最大的做事的空间发挥出来,比如说看到某个工人空闲而且有任务来的时候,这个时候厂长就开始分配任务给工人了;当工人们将衣服做完之后(也就是任务结束之后)我们就需要一个专门的人去将这个衣服销售出去,这个销售的过程又有专门的人去做了,我们肯定不能让工人去卖衣服的,因为这个是不安全的,万一哪个工厂来挖墙脚了就不好了,所以这里的销售人员就相当于是(Handler)来分发最后的结果的,与外界打交道的。
Ps:其实市面上的大多数的框架基本上的原理就是这样子的,只是有些人的指挥能力(编程能力)比较强,对于制衣服的工具(httpclient)了解的比较透彻,这样子就可以教工人更好的调试制衣服的工具。因为善于协调各个部门的工作关系以及善于给工人洗脑嘛(也制代码写的好),所以最后做出来的衣服的质量和数量就比别人更厉害的,同样的每个人都是一个小老板,你也可以自己慢慢的尝试的去管理一个工厂(写一个自己的框架),虽然前期的产出的质量和数量不怎么好,但是后面你慢慢看多了别人的经验(代码)之后,你也慢慢的更会总结经验了。这里我就用一个最浅显的比喻来描述了一下网络请求的框架。
- 深入浅出的理解Android网络请求框架
- 深入浅出的理解框架
- Android网络请求框架
- Android 网络请求 框架
- Android网络请求框架Volley的使用
- android网络请求Volley框架的使用
- Android网络请求框架的使用okhttp
- Android网络框架xUtils的Http网络数据请求操作
- 【Android框架】深入浅出理解DiskLruCache(上)
- 【Android框架】深入浅出理解DiskLruCache(下)
- Android简易网络请求框架
- Android网络请求框架 Volley
- Android网络请求框架--AsyncHttpClient
- 轻量级Android网络请求框架
- Android网络请求框架Volley
- Android主流网络请求框架
- android中的网络请求框架
- Android主流网络请求框架
- 【CSS】CSS中alt属性和title属性用法
- 【C++】日期类
- Git之SSH公钥与私钥
- 计算机视觉领域的一些牛人博客,超有实力的研究机构web主页(转)
- 优先队列的数组实现(有序)
- 深入浅出的理解Android网络请求框架
- PHP爬虫最全总结1
- LZ认为好的文章和地址,外人勿看
- memecached 网络模型分析
- php浅析memcache和memcached模块比较以及安装方法
- HDU 1280 前m大的数(优先队列+栈)
- Linux Bash Shell入门教程
- 仿微信 Fragment 动态加载
- CSS3 animation实现点点点loading动画


