MongoDB复制集原理
来源:互联网 发布:迅雷无法访问网络 编辑:程序博客网 时间:2024/06/06 15:03
MongoDB的单实例模式下,一个mongod进程为一个实例,一个实例中包含若干db,每个db包含若干张表。
MongoDB通过一张特殊的表local.oplog.rs存储oplog,该表的特点是:固定大小,满了会删除最旧记录插入新记录,而且只支持append操作,因此可以理解为一个持久化的ring-buffer。oplog是MongoDB复制集的核心功能点。
MongoDB复制集是指MongoDB实例通过复制并应用其他实例的oplog达到数据冗余的技术。
常用的复制集构成一般有下图两种方式 (注意,可以使用mongoshell 手工指定复制源,但mongdb不保证这个指定是持久的,下文会讲到在某些情况下,MongoDB会自动进行复制源切换)。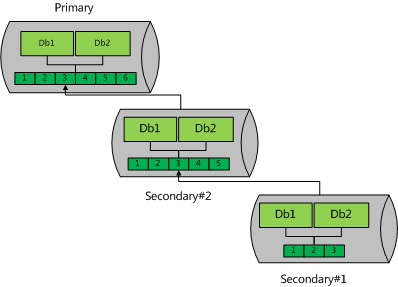
MongoDB的复制集技术并不少见,很类似mysql的异步复制模式,这种模式主要有几个技术点:
新节点加入,正常同步前的初始化
Primary节点挂掉后,剩余的Secondary节点如何提供服务
- 如何保证主节点挂掉后数据不丢失/主节点挂掉后丢失数据的处理
MongoDB作为一个成熟的数据库产品,较好的解决了上述问题,一个完整的复制集包含如下几点功能:
数据同步
1.1 initial-sync
1.2steady-sync
1.3异常数据回滚MongoDB集群心跳与选举
一.数据同步
initial_sync
当一个节点刚加入集群时,它需要初始化数据使得 自身与集群中其它节点的数据量差距尽量少,这个过程称为initial-sync。
一个initial-sync 包括六步(阅读rs_initialSync.cpp:_initialSync函数的逻辑)
- 删除本地除local库以外的所有db
- 选取一个源节点,将源节点中的所有db导入到本地(注意,此处只导入数据,不导入索引)
- 将2)开始执行到执行结束中源产生的oplog 应用到本地
- 将3)开始执行到执行结束中源产生的oplog 应用到本地
- 从源将所有table的索引在本地重建(导入索引)
- 将5)开始执行到执行结束中源产生的oplog 应用到本地
当第6)步结束后,源和本地的差距足够小,MongoDB进入Secondary(从节点)状态。
第2)步要拷贝所有数据,因此一般第2)步消耗时间最长,第3)与第4)步是一个连续逼近的过程,MongoDB这里做了两次
是因为第2)步一般耗时太长,导致第3)步数据量变多,间接受到影响。然而这么做并不是必须的,rs_initialSync.cpp:384 开始的TODO建议使用SyncTail的方式将数据一次性读回来(SyncTail以及TailableCursor的行为与原理如果不熟悉请看官方文档

steady-sync
当节点初始化完成后,会进入steady-sync状态,顾名思义,正常情况下,这是一个稳定静默运行于后台的,从复制源不断同步新oplog的过程。该过程一般会出现这两种问题:
- 复制源写入过快(或者相对的,本地写入速度过慢),复制源的oplog覆盖了 本地用于同步源oplog而维持在源的游标。
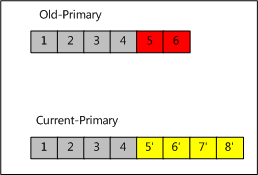
- 本节点在宕机之前是Primary,在重启后本地oplog有和当前Primary不一致的Oplog。
这两种情况分别如下图所示: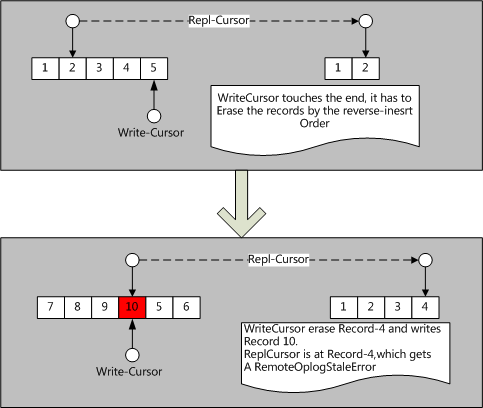
这两种情况在bgsync.cpp:_produce函数中,虽然这两种情况很不一样,但是最终都会进入bgsync.cpp:_rollback函数处理,
对于第二种情况,处理过程在rs_rollback.cpp中,具体步骤为:
维持本地与远程的两个反向游标,以线性的时间复杂度找到LCA(最近公共祖先,上conflict.png中为Record4)
该过程与经典的两个有序链表找公共节点的过程类似,具体实现在roll_back_local_operations.cpp:syncRollBackLocalOperations中,读者可以自行思考这一过程如何以线性时间复杂度实现。针对本地每个冲突的oplog,枚举该oplog的类型,推断出回滚该oplog需要的逆操作并记录,如下:
2.1: create_table -> drop_table
2.2: drop_table -> 重新同步该表
2.3: drop_index -> 重新同步并构建索引
2.4: drop_db -> 放弃rollback,改由用户手工init_resync
2.5: apply_ops -> 针对apply_ops 中的每一条子oplog,递归执行 2)这一过程
2.6: create_index -> drop_index
2.7: 普通文档的CUD操作 -> 从Primary重新读取真实值并替换。相关函数为:rs_rollback.cpp:refetch针对2)中分析出的每条oplog的处理方式,执行处理,相关函数为 rs_rollback.cpp:syncFixUp,此处操作主要是对步骤2)的实践,实际处理过程相当繁琐。
- truncate掉本地冲突的oplog。
上面我们说到,对于本地失速(stale)的情况,也是走_rollback 流程统一处理的,对于失速,走_rollback时会在找LCA这步失败,之后会尝试更换复制源,方法为:从当前存活的所有secondary和primary节点中找一个使自己“不处于失速”的节点。
这里有必要解释一下,oplog是一个有限大小的ring-buffer, 失速的唯一判断条件为:本地维护在复制源的游标被复制源的写覆盖(想象一下你和同学同时开始绕着操场跑步,当你被同学超过一圈时,你和同学相遇了)。因此如果某些节点的oplog设置的比较大,绕完一圈的时间就更长,利用这样的节点作为复制源,失速的可能性会更小。
对MongoDB的集群数据同步的描述暂告段落。我们利用一张流程图来做总结: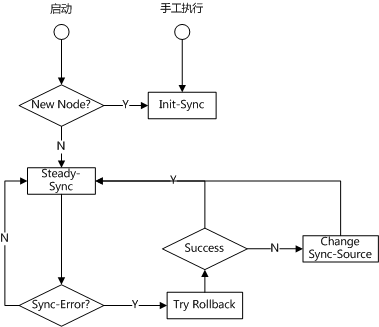
steady-sync的线程模型与Oplog指令乱序加速
与steady-sync相关的代码有 bgsync.cpp, sync_tail.cpp。上面我们介绍过,steady-sync过程从复制源读取新产生的oplog,并应用到本地,这样的过程脱不离是一个producer-consumer模型。由于oplog需要保证顺序性,producer只能单线程实现。
对于consumer端,是否有并发提速机制呢?
首先,不相干的文档之间无需保证oplog apply的顺序,因此可以对oplog 按照objid 哈希分组。每一组内必须保证严格的写入顺序性。
572 void fillWriterVectors(OperationContext* txn,573 MultiApplier::Operations* ops,574 std::vector<MultiApplier::OperationPtrs>* writerVectors) {581 for (auto&& op : *ops) {582 StringMapTraits::HashedKey hashedNs(op.ns);583 uint32_t hash = hashedNs.hash();584585 // For doc locking engines, include the _id of the document in the hash so we get586 // parallelism even if all writes are to a single collection. We can't do this for capped587 // collections because the order of inserts is a guaranteed property, unlike for normal588 // collections.589 if (supportsDocLocking && op.isCrudOpType() && !isCapped(txn, hashedNs)) {590 BSONElement id = op.getIdElement();591 const size_t idHash = BSONElement::Hasher()(id);592 MurmurHash3_x86_32(&idHash, sizeof(idHash), hash, &hash);593 }601 auto& writer = (*writerVectors)[hash % numWriters];602 if (writer.empty())603 writer.reserve(8); // skip a few growth rounds.604 writer.push_back(&op);605 }606 }其次对于command命令,会对表或者库有全局性的影响,因此command命令必须在当前的consumer完成工作之后单独处理,而且在处理command oplog时,不能有其他命令同时执行。这里可以类比SMP体系结构下的
cpu-memory-barrior。899 // Check for ops that must be processed one at a time.900 if (entry.raw.isEmpty() || // sentinel that network queue is drained.901 (entry.opType[0] == 'c') || // commands.902 // Index builds are achieved through the use of an insert op, not a command op.903 // The following line is the same as what the insert code uses to detect an index build.904 (!entry.ns.empty() && nsToCollectionSubstring(entry.ns) == "system.indexes")) {905 if (ops->getCount() == 1) {906 // apply commands one-at-a-time907 _networkQueue->consume(txn);908 } else {909 // This op must be processed alone, but we already had ops in the queue so we can't910 // include it in this batch. Since we didn't call consume(), we'll see this again next911 // time and process it alone.912 ops->pop_back();913 }从库和主库的oplog 顺序必须完全一致,因此不管1、2步写入用户数据的顺序如何,oplog的必须保证顺序性。对于mmap引擎的capped-collection,只能以顺序插入来保证,因此对oplog的插入是单线程进行的。对于wiredtiger引擎的capped-collection,可以在ts(时间戳字段)上加上索引,从而保证读取的顺序与插入的顺序无关。
517 // Only doc-locking engines support parallel writes to the oplog because they are required to518 // ensure that oplog entries are ordered correctly, even if inserted out-of-order. Additionally,519 // there would be no way to take advantage of multiple threads if a storage engine doesn't520 // support document locking.521 if (!enoughToMultiThread ||522 !txn->getServiceContext()->getGlobalStorageEngine()->supportsDocLocking()) {523524 threadPool->schedule(makeOplogWriterForRange(0, ops.size()));525 return false;526 }
steady-sync 的类依赖与线程模型总结如下图: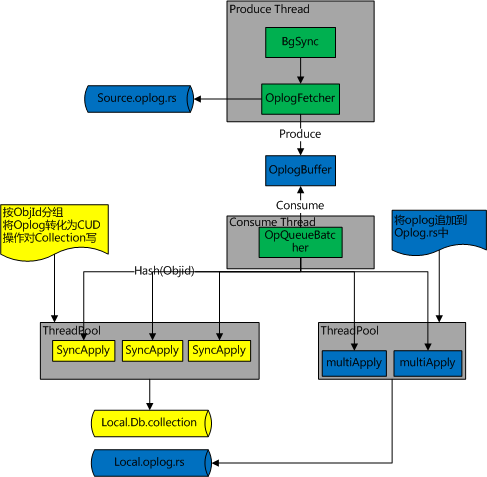
二.MongoDB心跳与选举机制
MongoDB的主节点选举由心跳触发。一个复制集N个节点中的任意两个节点维持心跳,每个节点维护其他N-1个节点的状态(该状态仅是该节点的POV,比如因为网络分区,在同一时刻A观察C处于down状态,B观察C处于seconary状态)
以任意一个节点的POV,在每一次心跳后会企图将主节点降级(step down primary)(topology_coordinator_impl.cpp:_updatePrimaryFromHBData),主节点降级的理由如下:
- 心跳检测到有其他primary节点的优先级高于当前主节点,则尝试将主节点降级(stepDown) 为
Secondary, primary值的动态变更提供给了运维一个可以热变更主节点的方式 - 本节点若是主节点,但是无法ping通集群中超过半数的节点(majority原则),则将自身降级为Secondary
选举主节点
Secondary节点检测到当前集群没有存活的主节点,则尝试将自身选举为Primary。主节点选举是一个二阶段过程+多数派协议。
第一阶段
以自身POV,检测自身是否有被选举的资格:
- 能ping通集群的过半数节点
- priority必须大于0
- 不能是arbitor节点
如果检测通过,向集群中所有存活节点发送FreshnessCheck(询问其他节点关于“我”是否有被选举的资格)
同僚仲裁
选举第一阶段中,某节点收到其他节点的选举请求后,会执行更严格的同僚仲裁
- 集群中有其他节点的primary比发起者高
- 不能是arbitor节点
- primary必须大于0
- 以冲裁者的POV,发起者的oplog 必须是集群存活节点中oplog最新的(可以有相等的情况,大家都是最新的)
第二阶段
发起者向集群中存活节点发送Elect请求,仲裁者收到请求的节点会执行一系列合法性检查,如果检查通过,则仲裁者给发起者投一票,并获得30秒钟“选举锁”,选举锁的作用是:在持有锁的时间内不得给其他发起者投票。
发起者如果或者超过半数的投票,则选举通过,自身成为Primary节点。获得低于半数选票的原因,除了常见的网络问题外,相同优先级的节点同时通过第一阶段的同僚仲裁并进入第二阶段也是一个原因。因此,当选票不足时,会sleep[0,1]秒内的随机时间,之后再次尝试选举。
- MongoDB复制集原理
- MongoDB复制集原理
- MongoDB复制集原理
- MongoDB原理:复制集状态同步机制
- MongoDB复制原理
- MongoDB实战-复制(副本集的复制原理)
- ttlsa教程系列之mongodb——(五)mongodb架构-复制原理&复制集
- MongoDB之复制集(一)原理篇
- mongodb复制集搭建
- 搭建mongodb复制集
- Mongodb复制集
- mongodb复制集搭建
- mongodb 复制集
- MongoDb复制-副本集
- MongoDb(3)-复制集
- mongodb 复制集
- Mongodb复制集
- mongodb复制-副本集
- 小菜鸟起跑-对模仿《谷歌电子市场》项目前两天的总结(二)
- php的增删改
- 摩拜单车/OFO/市政公交车的技术背景分析
- lombok安装入门
- 体验事件对象
- MongoDB复制集原理
- Matlab Robotic Toolbox V9.10工具箱(六):puma560 动力学建模与仿真
- CoreLocation定位服务
- Linux下USB驱动详解(HOST)
- TextureAtlas 使用注意
- Vim简明教程【CoolShell】
- php去除前后空格
- 能看懂的Pandas教程
- 更改TabBar的字体颜色


