hadoop---hdfs
来源:互联网 发布:中超球员籍贯数据库 编辑:程序博客网 时间:2024/06/05 17:39
hdfs
hdfs概念
block
类似于unix文件系统,hdfs也有block的概念,默认是128MB,但是和unix文件系统不同的是,1个1MB的文件,不会占用一个block的全部大小,仍然只占用1MB空间。
block的用途:
- 一个大文件会被分割为多个block,这样一个大文件如果在单机存储不下,可以分割成小的block分若干台机器存储
- 每个block大小相同,存储管理会简单许多,可以很方便的估算出还剩多少磁盘空间,还能继续存储多少block等
- 每个block会额外复制2份,同一个机架一份,不同机架一份,用于冗余备份和容灾
Namenode和Datanode
Namenode:
- HDFS文件系统中的文件目录树,以及文件的数据块索引,即每个文件对应的数据块列表。目录树、元数据和数据块的索引信息会持久化到物理存储中,实现是保存在命名空间的镜像fsimage和编辑日志edits中。
- 数据块和数据节点的对应关系,即某一块数据块保存在哪些数据节点的信息。存储在内存中,由NameNode启动后DataNode主动上报它所存储的数据块,动态建立对应关系。
Datanode:
- 客户端(client)或者元数据信息(namenode)可以向数据节点请求写入或者读出数据块。
- 其周期性的向元数据节点回报其存储的数据块信息。
secondary namenode:
- 从元数据节点并不是元数据节点出现问题时候的备用节点,它和元数据节点负责不同的事情。
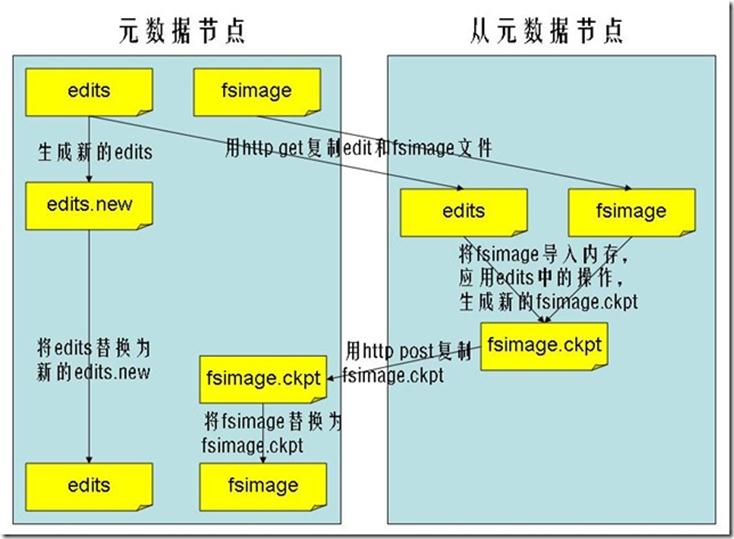
- 其主要功能就是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。合并过程见下图所示。
- 合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。
Namenode的ha
hadoop2.x方案,两个namenode,active-standby模式
- 共享存储,保存edit log,当主namenode挂掉,备份namenode变为active,从共享存储中读取edit log,构建namespace image,并读入内存。共享内存选择(NFS/QJM)
- datanode将file-block-datanode映射关系同时发给上述两个namenode
- client必须能以用户没有感知的情况下,在主备namenode之间切换
参考:http://blog.csdn.net/anzhsoft/article/details/23279027
0 0
- Hadoop HDFS
- hadoop hdfs
- hadoop hdfs
- hadoop hdfs
- Hadoop-HDFS
- Hadoop HDFS
- Hadoop - HDFS
- hadoop HDFS
- Hadoop-hdfs
- hadoop---hdfs
- Hadoop-HDFS
- Hadoop-HDFS
- Hadoop-HDFS
- Hadoop HDFS
- Hadoop--HDFS
- Hadoop ---- HDFS
- Hadoop(HDFS)
- Hadoop HDFS (2) HDFS概念
- ubuntu下安装cryptography报错 error: command 'x86_64-linux-gnu-gcc' failed with exit status 1
- Windows Server系统安全配置
- 外包项目合作流程
- SVM的详细推导
- BaseAdapter(和SimpleAdapter)的使用
- hadoop---hdfs
- Word2Vec源码详细解析(上)
- unity-PoolManager 预制件管理插件
- C语言calloc()函数:分配内存空间并初始化
- 前向神经网络算法原理
- visual studio(vs) 如何快速查找接口的实现类
- Noip2015 D2T1 跳石头
- 关于4个位置的仿二进制解析
- 关于多文件下多图片路径的生成


