shell
来源:互联网 发布:python map数据结构 编辑:程序博客网 时间:2024/06/06 07:17
讲解一
1.概念
位置参数(position parameter)
运行脚本前(调用函数前),shell 传递给脚本的参数。
2. 原理
bash 脚本的位置参数的传递可以做如下理解:
1. shell将用户输入的命令行 分别赋值给 1, 2, 3, 4, 5....N
2. 然后将最后一个参数的名称 N 赋值给 #
例如: ./script.sh pa1 pa2 pa3 pa4 pa5
1="pa1"; 2="pa2"; 3="pa3" ; 4="pa4"; 5="pa5" && #=5 # 一个间接引用
3. 应用:
echo "$1" # 打印 pa1
echo "$2" # 打印 pa2
echo "$#" # 打印的是最后一个参数的序号, 即位置参数的个数 5
echo "$(eval echo "/$$#")" # 打印的是最后一个参数的值
echo "${!#}" # 打印的是最后一个参数的值
echo "$@" # 打印所有位置参数,IFS为间隔符号
echo "$*" # 打印所有位置参数,无间隔符号
函数参数传递:函数的值传递,全部都是 字符串的传递,而且是值传递。
例如:将一个数组名作为参数传递给一个函数时,函数里面使用该参数时,则认为其只是一个字符串。
e.g:
#!/bin/bash
declare -a arr
func(){
#$1[0]="first element of array" # error! command not found
arr[0]="first element of array" # right
}
func arr
tips: 将一个文本文件的内容赋值给一个变量
这个比较牛: str=$(<file) #<file == 0<file
我写的:read str < <(echo file| tr "/n" " ")
讲解二
linux中shell变量$#,$@,$0,$1,$2的含义解释:
变量说明:
$$
Shell本身的PID(ProcessID)
$!
Shell最后运行的后台Process的PID
$?
最后运行的命令的结束代码(返回值)
$-
使用Set命令设定的Flag一览
$*
所有参数列表。如"$*"用「"」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。
$@
所有参数列表。如"$@"用「"」括起来的情况、以"$1" "$2" … "$n" 的形式输出所有参数。
$#
添加到Shell的参数个数
$0
Shell本身的文件名
$1~$n
添加到Shell的各参数值。$1是第1参数、$2是第2参数…。
我们先写一个简单的脚本,执行以后再解释各个变量的意义
# touch variable
# vi variable
脚本内容如下:
#!/bin/sh
echo "number:$#"
echo "scname:$0"
echo "first :$1"
echo "second:$2"
echo "argume:$@"
保存退出
赋予脚本执行权限
# chmod +x variable
执行脚本
# ./variable aa bb
number:2
scname:./variable
first: aa
second:bb
argume:aa bb
通过显示结果可以看到:
$# 是传给脚本的参数个数
$0 是脚本本身的名字
$1是传递给该shell脚本的第一个参数
$2是传递给该shell脚本的第二个参数
$@ 是传给脚本的所有参数的列表
魔术数字
编辑锁定理由编辑
- 参考资料
Linux命令替换
Linux命令替换和重定向有些相似,但区别在于命令替换是将一个命令的输出作为另外一个Linux命令的参数。常用命令格式为: command1 `command2` 其中,command2的输出将作为command1的参数。需要注意的是这里的`符号,被它括起来的内容将作为Linux命令执行,执行后的结果作为command1的参数。例如: $ cd `pwd`
该命令将pwd命令列出的目录作为cd命令的参数,结果仍然是停留在当前目录下
登录shell和非登录shell
(2012-09-25 14:00:03)ftp服务器
默认
计算机
无法使用
用户登录
it
分类: linux事实上还有很多特殊符号可用来分隔单个的命令:分号(;)、管道(|)、&、逻辑AND (&&),还有逻辑OR (||)。对于每一个读取的管道,Shell都回将命令分割,为管道设置I/O,并且对每一个命令依次执行下面的操作:
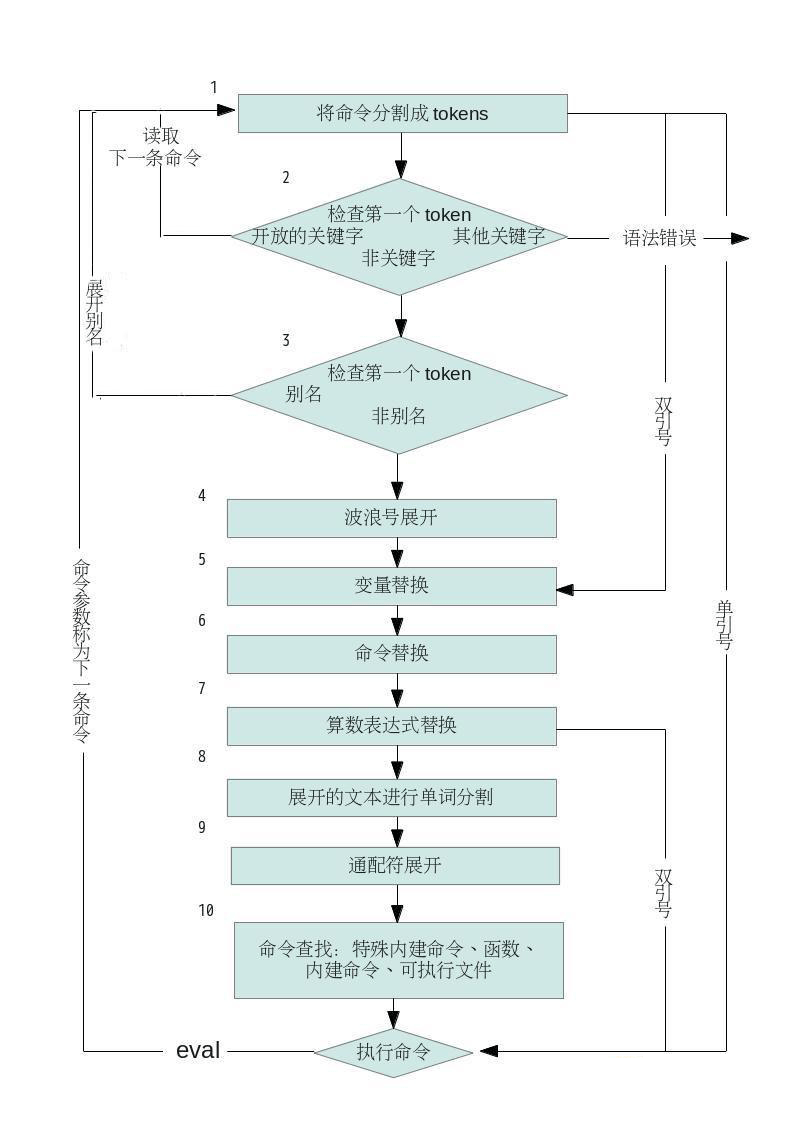
整个步骤顺序如上图所示,看起来有些复杂。当命令行被处理时,每一个步骤都是在Shell的内存里发生的;Shell不会真的把每个步骤的发生显示给你看。所以,你可以假想这事我们偷窥Shell内存里的情况,从而知道每个阶段的命令行是如何被转换的。我们从这个例子开始说:
$ mkidr /tmp/x 建立临时性目录
$ cd /tmp/x 切换到该目录
$ touch f1 f2 建立文件
$ f=f y="a b" 赋值两个变量
$ echo ~+/${f}[12] $y $(echo cmd subst )$ (( 3 + 2 )) > out 将结果重定向到out
上述的执行步骤概要如下:
1.命令一开始回根据Shell语法而分割为token。最重要的一点是:I/O重定向 >out 在这里是被识别的,并存储供稍后使用。流程继续处理下面这行,其中每个token的范围显示于命令下面的行上:
echo ~+/${f}[12] $y $(echo cmd subst) $((3 + 2))
| 1 | |----- 2 ----| |3 | |-------- 4----------| |----5-----|
2.检查第一个单词(echo)是否为关键字,例如 if 或 for 。这里不是,所以命令行不变继续处理。
3.检查第一个单词(echo)是否为别名。这里不是。所以命令行不变,继续处理。
4.扫描所以单词是否需要波浪号展开。在本例中,~+ 为ksh93 与 bash 的扩展,等同于$PWD,也就是当前的目录。token 2将被修改,处理如下:
echo /tmp/x/${f}[12] $y $(echo cmd subst) $((3 + 2))
| 1 | |------- 2 -------| |3 | |-------- 4----------| |----5-----|
5.下一步是变量展开:token 2 与 3 都被修改。这样会产生:
echo /tmp/x/${f}[12] a b $(echo cmd subst) $((3 + 2))
| 1 | |------- 2 -------| | 3 | |-------- 4----------| |----5-----|
6.再来要处理的是命令替换。注意,这里可用递归应用列表里的所有步骤!在这里,命令替换修改了 token 4:
echo /tmp/x/${f}[12] a b cmd subst $((3 + 2))
| 1 | |------- 2 -------| | 3 | |--- 4 ----| |----5-----|
7.现在执行算数替换。修改的是 token 5,结果:
echo /tmp/x/${f}[12] a b cmd subst 5
| 1 | |------- 2 -------| | 3 | |--- 4 ----| |5|
8.前面所有的展开产生的结果,都将再一次被扫描,看看是否有 $IFS 字符。如果有,则他们是作为分隔符(separator),产生额外的单词,例如,两个字符$y 原来是组成一个单词,单展开式“a- 空格-b”,在此阶段被切分为两个单词:a 与 b。相同方式也应用于命令$(echo cmd subst)的结果上。先前的 token 3 变成了 token 3 与
token 4.先前的 token 4则成了 token 5 与 token 6。结果:
echo /tmp/x/${f}[12] a b cmd subst 5
| 1 | |------- 2 -------| 3 4 |-5-| |- 6 -| 7
9.最后的替换阶段是通配符展开。token 2 变成了 token 2 与 token 3:
echo /tmp/x/$f1 /tmp/x/$f2 a b cmd subst 5
| 1 | |---- 2 ----| |---- 3 ----| 4 5 |-6-| |- 7 -| 8
10.这时,Shell已经准备好了要执行最后的命令了。它会去寻找 echo。正好 ksh93 与 bash 的 echo 都内建到Shell 中了。
11.Shell实际执行命令。首先执行 > out 的 I/O重定向,再调用内部的 echo 版本,显示最后的参数。
最后的结果:
$cat out
/tmp/x/f1 /tmp/x/f2 a b cmd subst 5
杂谈
分类: LinuxWe've seen how the shell uses
We've touched upon command-line processing (see
[7] Even this explanation is slightly simplified to elide the most petty details, e.g., "middles" and "ends" of compound commands, special characters within
[[ ... ]] and (( ... )) constructs, etc. The last word on this subject is the reference book, The KornShell Command and Programming Language , by Morris Bolsky and David Korn, published by Prentice-Hall.
Splits the command into
tokens that are separated by the fixed set of metacharacters : SPACE, TAB , NEWLINE, ;, ( ,), < , > , | , and & . Types of tokens include words , keywords , I/O redirectors, and semicolons. Checks the first token of each command to see if it is a
keyword with no quotes or backslashes. If it's an opening keyword ( if and other control-structure openers, function , { , ( , (( , or [[ ), then the command is actually acompound command . The shell sets things up internally for the compound command, reads the next command, and starts the process again. If the keyword isn't a compound command opener (e.g., is a control-structure "middle" like then ,else , or do , an "end" like fi or done , or a logical operator), the shell signals a syntax error. Checks the first word of each command against the list of
aliases . If a match is found, it substitutes the alias' definition and goes back to Step 1 ; otherwise it goes on to Step 4. This scheme allows recursive aliases; seeChapter 3 . It also allows aliases for keywords to be defined, e.g., alias aslongas=while or alias procedure=function . Substitutes the user's home directory (
$HOME ) for tilde if it is at the beginning of a word. Substitutes user 's home directory for ~user . [8] [8]
Two obscure variations on this: the shell substitutes the current directory ( $PWD ) for ~+ and the previous directory ( $OLDPWD ) for ~- . Performs
parameter (variable) substitution for any expression that starts with a dollar sign ( $ ). Does
command substitution for any expression of the form $( string ) . Evaluates
arithmetic expressions of the form $(( string )) . Takes the parts of the line that resulted from parameter, command, and arithmetic substitution and splits them into words again. This time it uses the characters in
$IFS as delimiters instead of the set of metacharacters in Step 1. Performs
filename generation , a.k.a. wildcard expansion , for any occurrences of *, ?, and [/] pairs. It also processes the regular expression operators that we saw in Chapter 4 . Figure 7.1: Steps in Command-line Processing

Uses the first word as a command by looking up its source according to the rest of the list in
Chapter 4 , i.e., as a built-in command, then as a function , then as a file in any of the directories in $PATH . Runs the command after setting up I/O redirection and other such things.
That's a lot of steps
alias ll="ls -l"Further assume that a file exists called
Now let's see how the shell processes the following command:
ll $(whence cc) ~fred/.*$(($$00))Here is what happens to this line:
ll $(whence cc) ~fred/.*$(($$00))
Splitting the input into words.
ll
is not a keyword, so step 2 does nothing. ls -l $(whence cc) ~fred/.*$(($$00))
Substituting
ls -l for its alias "ll". The shell then repeats steps 1 through 3; step 2 splits the ls -l into two words. [9] [9] Some of the shell's built-in aliases, however, seem to make it through single quotes:
true (an alias for : , a "do-nothing" command that always returns exit status 0), false (an alias for let 0 , which always returns exit status 1), and stop (an alias for kill -STOP ). ls -l $(whence cc) /home/fred/.*$(($$00))
Expanding
~fred into /home/fred . ls -l $(whence cc) /home/fred/.*$((253700))
Substituting
2537 for $$ . ls -l /usr/bin/cc /home/fred/.*$((253700))
Doing command substitution on "whence cc".
ls -l /usr/bin/cc /home/fred/.*537
Evaluating the arithmetic expression
253700 . ls -l /usr/bin/cc /home/fred/.*537
This step does nothing.
ls -l /usr/bin/cc /home/fred/.hist537
Substituting the filename for the wildcard expression .*
537 . The command
ls is found in /usr/bin . /usr/bin/ls
is run with the option -l and the two arguments.
Although this list of steps is fairly straightforward, it is not the whole story. There are still two ways to
source命令用法:
source FileName
作用:在当前bash环境下读取并执行FileName中的命令。
注:该命令通常用命令“.”来替代。
如:source.bash_rc与. .bash_rc是等效的。
注意:source命令与shell scripts的区别是,
source在当前bash环境下执行命令,而scripts是启动一个子shell来执行命令。这样如果把设置环境变量(或alias等等)的命令写进scripts中,就只会影响子shell,无法改变当前的BASH,所以通过文件(命令列)设置环境变量时,要用source命令。
管道命令和xargs的区别(经典解释)
一直弄不懂,管道不就是把前一个命令的结果作为参数给下一个命令吗,那在 | 后面加不加xargs有什么区别
NewUserFF 写道:
懒蜗牛Gentoo 写道:
管道是实现“将前面的标准输出作为后面的标准输入”
xargs是实现“将标准输入作为命令的参数”
你可以试试运行:
代码:
echo "--help"|cat
echo "--help"|xargs cat
看看结果的不同。
试过了,依然不是很确定的明白到底是什么意思,自己再探索一下看看把
如果你直接在命令行输入cat而不输入其余的任何东西,这时候的cat会等待标准输入,因此你这时候可以
通过键盘输入并按回车来让cat读取输入,cat会原样返回。而如果你输入--help,那么cat程序会在标准输出上
打印自己的帮助文档。也就是说,管道符 | 所传递给程序的不是你简单地在程序名后面输入的参数,它们会被
程序内部的读取功能如scanf和gets等接收,而xargs则是将内容作为普通的参数传递给程序,相当于你手写了
cat --help
来自:http://forum.ubuntu.org.cn/viewtopic.php?t=354669
补充解释:
在一个目录中有如下三个文件
a.c b.c c.c
find . / -print命令会打印出三个文件名
find . / -print | grep a.c 只会打印出a.c这个文件
如果只输入命令grep a.c
那么你在键盘中只输入a.c字符串时,a.c会被打印两次,否则只打印你输入的字符
如果要找三个文件中,那个文件包括有hello字符
find ./ -print | xargs grep hello
总结:管道符后不加xargs相当于先将xargs后面的命令回车执行一下再从键盘里输入
管道符前面命令执行的结果内容
加上xargs 相当于直接从键盘输入管道符前面命令执行的结果内容再回车
再总结一下,就是回车的先后顺序不太一样。
echo是一种最常用的与广泛使用的内置于Linux的bash和C shell的命令,通常用在脚本语言和批处理文件中来在标准输出或者文件中显示一行文本或者字符串。

echo命令的语法是:
- echo [选项] [字符串]
1. 输入一行文本并显示在标准输出上
- $ echo Tecmint is a community of Linux Nerds
会输出下面的文本:
- Tecmint is a community of Linux Nerds
2. 输出一个声明的变量值
比如,声明变量x并给它赋值为10。
- $ x=10
会输出它的值:
- $ echo The value of variable x = $x
- The value of variable x = 10
3. 使用‘\b‘选项
‘-e‘后带上'\b'会删除字符间的所有空格。
注意: Linux中的选项‘-e‘扮演了转义字符反斜线的翻译器。
- $ echo -e "Tecmint \bis \ba \bcommunity \bof \bLinux \bNerds"
- TecmintisacommunityofLinuxNerds
4. 使用‘\n‘选项
‘-e‘后面的带上‘\n’行会在遇到的地方作为新的一行
- $ echo -e "Tecmint \nis \na \ncommunity \nof \nLinux \nNerds"
- Tecmint
- is
- a
- community
- of
- Linux
- Nerds
5. 使用‘\t‘选项
‘-e‘后面跟上‘\t’会在空格间加上水平制表符。
- $ echo -e "Tecmint \tis \ta \tcommunity \tof \tLinux \tNerds"
- Tecmint is a community of Linux Nerds
6. 也可以同时使用换行‘\n‘与水平制表符‘\t‘
- $ echo -e "\n\tTecmint \n\tis \n\ta \n\tcommunity \n\tof \n\tLinux \n\tNerds"
- Tecmint
- is
- a
- community
- of
- Linux
- Nerds
7. 使用‘\v‘选项
‘-e‘后面跟上‘\v’会加上垂直制表符。
- $ echo -e "\vTecmint \vis \va \vcommunity \vof \vLinux \vNerds"
- Tecmint
- is
- a
- community
- of
- Linux
- Nerds
8. 也可以同时使用换行‘\n‘与垂直制表符‘\v‘
- $ echo -e "\n\vTecmint \n\vis \n\va \n\vcommunity \n\vof \n\vLinux \n\vNerds"
- Tecmint
- is
- a
- community
- of
- Linux
- Nerds
注意: 你可以按照你的需求连续使用两个或者多个垂直制表符,水平制表符与换行符。
9. 使用‘\r‘选项
‘-e‘后面跟上‘\r’来指定输出中的回车符。(LCTT 译注:会覆写行开头的字符)
- $ echo -e "Tecmint \ris a community of Linux Nerds"
- is a community of Linux Nerds
10. 使用‘\c‘选项
‘-e‘后面跟上‘\c’会抑制输出后面的字符并且最后不会换新行。
- $ echo -e "Tecmint is a community \cof Linux Nerds"
- Tecmint is a community @tecmint:~$
11. ‘-n‘会在echo完后不会输出新行
- $ echo -n "Tecmint is a community of Linux Nerds"
- Tecmint is a community of Linux Nerds@tecmint:~/Documents$
12. 使用‘\a‘选项
‘-e‘后面跟上‘\a’选项会听到声音警告。
- $ echo -e "Tecmint is a community of \aLinux Nerds"
- Tecmint is a community of Linux Nerds
注意: 在你开始前,请先检查你的音量设置。
13. 使用echo命令打印所有的文件和文件夹(ls命令的替代)
- $ echo *
- 103.odt 103.pdf 104.odt 104.pdf 105.odt 105.pdf 106.odt 106.pdf 107.odt 107.pdf 108a.odt 108.odt 108.pdf 109.odt 109.pdf 110b.odt 110.odt 110.pdf 111.odt 111.pdf 112.odt 112.pdf 113.odt linux-headers-3.16.0-customkernel_1_amd64.deb linux-image-3.16.0-customkernel_1_amd64.deb network.jpeg
14. 打印制定的文件类型
比如,让我们假设你想要打印所有的‘.jpeg‘文件,使用下面的命令。
- $ echo *.jpeg
- network.jpeg
15. echo可以使用重定向符来输出到一个文件而不是标准输出
- $ echo "Test Page" > testpage
- ## Check Content
- avi@tecmint:~$ cat testpage
- Test Page
echo 选项列表
就是这些了,不要忘记在下面留下你的反馈。
inux的echo命令, 在shell编程中极为常用, 在终端下打印变量value的时候也是常常用到的, 因此有必要了解下echo的用法
echo命令的功能是在显示器上显示一段文字,一般起到一个提示的作用。
该命令的一般格式为: echo [ -n ] 字符串
其中选项n表示输出文字后不换行;字符串能加引号,也能不加引号。用echo命令输出加引号的字符串时,将字符串原样输出;用echo命令输出不加引号的字符串时,将字符串中的各个单词作为字符串输出,各字符串之间用一个空格分割。
功能说明:显示文字。
语 法:echo [-ne][字符串]或 echo [--help][--version]
补充说明:echo会将输入的字符串送往标准输出。输出的字符串间以空白字符隔开, 并在最后加上换行号。
参 数:-n 不要在最后自动换行
-e 若字符串中出现以下字符,则特别加以处理,而不会将它当成一般
文字输出:
\a 发出警告声;
\b 删除前一个字符;
\c 最后不加上换行符号;
\f 换行但光标仍旧停留在原来的位置;
\n 换行且光标移至行首;
\r 光标移至行首,但不换行;
\t 插入tab;
\v 与\f相同;
\\ 插入\字符;
\nnn 插入nnn(八进制)所代表的ASCII字符;
–help 显示帮助
–version 显示版本信息
Linux 下的两个特殊的文件 -- /dev/null 和 /dev/zero 简介及对比
目录(?)[+]
Linux 下的两个特殊的文件 -- /dev/null 和 /dev/zero 简介及对比
目录(?)[+]
1、概论 -- 来自维基的解释
/dev/null : 在类Unix系统中,/dev/null,或称空设备,是一个特殊的设备文件,它丢弃一切写入其中的数据(但报告写入操作成功),读取它则会立即得到一个EOF。在程序员行话,尤其是Unix行话中,/dev/null 被称为位桶(bit bucket)或者黑洞(black hole)。空设备通常被用于丢弃不需要的输出流,或作为用于输入流的空文件。这些操作通常由重定向完成。
/dev/zero : 在类UNIX 操作系统中, /dev/zero 是一个特殊的文件,当你读它的时候,它会提供无限的空字符(NULL, ASCII NUL, 0x00)。
其中的一个典型用法是用它提供的字符流来覆盖信息,另一个常见用法是产生一个特定大小的空白文件。BSD就是通过mmap把/dev/zero映射到虚地址空间实现共享内存的。可以使用mmap将/dev/zero映射到一个虚拟的内存空间,这个操作的效果等同于使用一段匿名的内存(没有和任何文件相关)。
2、 /dev/null 的日常使用
把/dev/null看作"黑洞"。它等价于一个只写文件,并且所有写入它的内容都会永远丢失,而尝试从它那儿读取内容则什么也读不到。然而, /dev/null对命令行和脚本都非常的有用。我们都知道 cat $filename 会输出filename对应的文件内容(输出到标准输出)
而使用 cat $filename >/dev/null 则不会得到任何信息,因为我们将本来该通过标准输出显示的文件信息重定向到了 /dev/null 中,so what will you get ?
使用 cat $filename 1>/dev/null 也会得到同样的效果,因为默认重定向的 1 就是标准输出。 如果你对 shell 脚本或者重定向比较熟悉的话,应该会联想到 2 ,也即标准错误输出。
我们使用 cat $filename 时如果filename对应的文件不存在,系统肯定会报错: “ cat: filename: 没有那个文件或目录 ” 。
如果我们不想看到错误输出呢?我们可以禁止标准错误: cat $badname 2>/dev/null
我们可以通过下面这个测试来更加深刻的理解/dev/null :
- <span style="font-size:18px">$cat test.txt
- just for test
- $cat test.txt >/dev/null
- $cat test.txt 1>/dev/null
- $cat test2.txt
- cat: test2.txt: 没有那个文件或目录
- $cat test2.txt >/dev/null
- cat: test2.txt: 没有那个文件或目录
- $cat test2.txt 2>/dev/null
- $
- </span>
有些时候,我并不想看道任何输出,我只想看到这条命令运行是不是正常,那么我们可以同时禁止标准输出和标准错误的输出:
cat $filename 2>/dev/null >/dev/null
所以:
* 如果"$filename"不存在,将不会有任何错误信息提示,
* 如果"$filename"存在, 文件的内容不会打印到标准输出。* 因此, 上面的代码根本不会输出任何信息,当只想测试命令的退出码而不想有任何输出时非常有用。
当然,使用 cat $filename &>/dev/null 也可以达到 cat $filename 2>/dev/null >/dev/null 一样的效果。
- <span style="font-size:18px">$cat test2.txt 2>/dev/null
- $cat test.txt 2>/dev/null >/dev/null
- $echo $?
- 0
- $cat test2.txt 2>/dev/null >/dev/null
- $echo $?
- 1
- $cat test.txt &>/dev/null
- $echo $?
- 0
- </span>
有时候,我们需要删除一些文件的内容而不删除文件本身:(这个方法可以用来删除日志文件,在我的Debian笔记本上我给 /var 盘配的空间有些过小,有时候就需要手动使用这个操作来清空日志)
# cat /dev/null > /var/log/messages# : > /var/log/messages 有同样的效果,但不会产生新的进程。(因为:是内建的)
下面的实例中,使用/dev/null 来删除cookie 并且不再使用cookie
- <span style="font-size:18px"> if [ -f ~/.netscape/cookies ] # 如果存在则删除,删除后才可以添加软链接
- then
- rm -f ~/.netscape/cookies
- fi
- ln -s /dev/null ~/.netscape/cookies </span>
其中,cookies的目录是可以变换的,比如说我自己电脑上的firefox的cookie目录为: ~/.mozilla/firefox/nah4b6di.default/cookies*
3、/dev/zero 的日常使用
像/dev/null一样,/dev/zero也是一个伪文件,但它实际上产生连续不断的null的流(二进制的零流,而不是ASCII型的)。写入它的输出会丢失不见,/dev/zero主要的用处是用来创建一个指定长度用于初始化的空文件,像临时交换文件。比如说,在我的前一篇博客中(《尝试安装Chrome OS的新版本 Vanilla & 安装之后U盘遇到的问题解决》),提到我使用dd 制作的U盘系统,而我的U盘有16G,而制作好后,系统盘只占了2.5G,而其他的空间(将近12G)都无发使用。我只能使用 dd if=/dev/zero of=/dev/sdb bs=4M 来重新给我整个U盘清零。
脚本实例 1. 用/dev/zero创建一个交换临时文件
- <span style="font-size:18px">#!/bin/bash
- # 创建一个交换文件,参数为创建的块数量(不带参数则为默认),一块为1024B(1K)
- ROOT_UID=0 # Root 用户的 $UID 是 0.
- E_WRONG_USER=65 # 不是 root?
- FILE=/swap
- BLOCKSIZE=1024
- MINBLOCKS=40
- SUCCESS=0
- # 这个脚本必须用root来运行,如果不是root作出提示并退出
- if [ "$UID" -ne "$ROOT_UID" ]
- then
- echo; echo "You must be root to run this script."; echo
- exit $E_WRONG_USER
- fi
- blocks=${1:-$MINBLOCKS} # 如果命令行没有指定,则设置为默认的40块.
- # 上面这句等同如:
- # --------------------------------------------------
- # if [ -n "$1" ]
- # then
- # blocks=$1
- # else
- # blocks=$MINBLOCKS
- # fi
- # --------------------------------------------------
- if [ "$blocks" -lt $MINBLOCKS ]
- then
- blocks=$MINBLOCKS # 最少要有 40 个块长,如果带入参数比40小,将块数仍设置成40
- fi
- echo "Creating swap file of size $blocks blocks (KB)."
- dd if=/dev/zero of=$FILE bs=$BLOCKSIZE count=$blocks # 把零写入文件.
- mkswap $FILE $blocks # 将此文件建为交换文件(或称交换分区).
- swapon $FILE # 激活交换文件.
- echo "Swap file created and activated."
- exit $SUCCESS
- </span>
运行效果我们可以看到:
- <span style="font-size:18px">long@Raring:/tmp$ vim testswap.sh
- long@Raring:/tmp$ chmod +x testswap.sh
- long@Raring:/tmp$ sudo ./testswap.sh
- [sudo] password for long:
- long@Raring:/tmp$ ./testswap.sh
- You must be root to run this script.
- long@Raring:/tmp$ sudo ./testswap.sh
- [sudo] password for long:
- Creating swap file of size 40 blocks (KB).
- 记录了40+0 的读入
- 记录了40+0 的写出
- 40960字节(41 kB)已复制,0.000904021 秒,45.3 MB/秒
- 正在设置交换空间版本 1,大小 = 36 KiB
- 无标签, UUID=3e59eddf-098f-454d-9507-aba55f434a8c
- Swap file created and activated.
- </span>
关于 /dev/zero 的另一个应用是为特定的目的而用零去填充一个指定大小的文件,如挂载一个文件系统到环回设备 (loopback device) 或"安全地" 删除一个文件。
脚本实例2. 创建ramdisk
- <span style="font-size:18px">#!/bin/bash
- # ramdisk.sh
- # "ramdisk"是系统RAM内存的一段,它可以被当成是一个文件系统来操作.
- # 优点:存取速度非常快 (包括读和写).
- # 缺点: 易失性, 当计算机重启或关机时会丢失数据.
- # 会减少系统可用的RAM.
- #
- # 那么ramdisk有什么作用呢?
- # 保存一个较大的数据集在ramdisk, 比如一张表或字典,这样可以加速数据查询, 因为在内存里查找比在磁盘里查找快得多.
- E_NON_ROOT_USER=70 # 必须用root来运行.
- ROOTUSER_NAME=root
- MOUNTPT=/mnt/ramdisk
- SIZE=2000 # 2K 个块 (可以合适的做修改)
- BLOCKSIZE=1024 # 每块有1K (1024 byte) 的大小
- DEVICE=/dev/ram0 # 第一个 ram 设备
- username=`id -nu`
- if [ "$username" != "$ROOTUSER_NAME" ]
- then
- echo "Must be root to run ""`basename $0`""."
- exit $E_NON_ROOT_USER
- fi
- if [ ! -d "$MOUNTPT" ] # 测试挂载点是否已经存在了,
- then #+ 如果这个脚本已经运行了好几次了就不会再建这个目录了
- mkdir $MOUNTPT #+ 因为前面已经建立了.
- fi
- dd if=/dev/zero of=$DEVICE count=$SIZE bs=$BLOCKSIZE # 把RAM设备的内容用零填充.
- # 为何需要这么做?
- mke2fs $DEVICE # 在RAM设备上创建一个ext2文件系统.
- mount $DEVICE $MOUNTPT # 挂载设备.
- chmod 777 $MOUNTPT # 使普通用户也可以存取这个ramdisk,但是, 只能由root来缷载它.
- echo """$MOUNTPT"" now available for use."
- # 现在 ramdisk 即使普通用户也可以用来存取文件了.
- # 注意, ramdisk是易失的, 所以当计算机系统重启或关机时ramdisk里的内容会消失.
- #
- # 重启之后, 运行这个脚本再次建立起一个 ramdisk.
- # 仅重新加载 /mnt/ramdisk 而没有其他的步骤将不会正确工作.
- # 如果加以改进, 这个脚本可以放在 /etc/rc.d/rc.local,以使系统启动时能自动设立一个ramdisk。这样很合适速度要求高的数据库服务器.
- exit 0
- </span>
运行起来效果如下:
- <span style="font-size:18px">long@Raring:/tmp$ vim ramdisk.sh
- long@Raring:/tmp$ chmod +x ramdisk.sh
- long@Raring:/tmp$ ./ramdisk.sh
- Must be root to run ramdisk.sh.
- long@Raring:/tmp$ sudo ./ramdisk.sh
- 记录了2000+0 的读入
- 记录了2000+0 的写出
- 2048000字节(2.0 MB)已复制,0.0113732 秒,180 MB/秒
- mke2fs 1.42.8 (20-Jun-2013)
- Discarding device blocks: 完成
- 文件系统标签=
- OS type: Linux
- 块大小=1024 (log=0)
- 分块大小=1024 (log=0)
- Stride=0 blocks, Stripe width=0 blocks
- 16384 inodes, 65536 blocks
- 3276 blocks (5.00%) reserved for the super user
- 第一个数据块=1
- Maximum filesystem blocks=67108864
- 8 block groups
- 8192 blocks per group, 8192 fragments per group
- 2048 inodes per group
- Superblock backups stored on blocks:
- 8193, 24577, 40961, 57345
- Allocating group tables: 完成
- 正在写入inode表: 完成
- Writing superblocks and filesystem accounting information: 完成
- /mnt/ramdisk now available for use.</span>
最后值得一提的是,ELF二进制文件利用了/dev/zero。
- Linux内建命令
 我要投稿
我要投稿内建命令
内建命令指的就是包含在 Bash 工具集中的命令。这主要是考虑到执行效率的问题——内建命令将比外部命令的执行得更快,外部命令通常需要 fork 出一个单独的进程来执行。另外一部分原因是特定的内建命令需要直接存取 shell 内核部分。
一个内建命令通常与一个系统命令同名,但是 Bash 在内部重新实现了这些命令。比如,Bash 的 echo 命令与 /bin/echo 就不尽相同,虽然它们的行为绝大多数情况下是一样的。
关键字的意思就是保留字。对于 shell 来说关键字有特殊的含义,并且用来构建 shell 的语法结构。
比如,”for”,”while”,”do”和”!”都是关键字。与内建命令相同的是,关键字也是 Bash 的骨干部分,但是与内建命令不同的是,关键字自身并不是命令,而是一个比较大的命令结构的一部分。I/O 类
echo
重要程度:高
打印(到stdout)一个表达式或变量。
echo 需要使用 -e 参数来打印转义字符。
一般的每个 echo 命令都会在终端上新起一行,但是 -n 选项将会阻止新起一行。
注意:echo command 将会删除任何有命令产生的换行符。
$IFS(内部域分隔符)一般都会将\n(换行符)包含在它的空白字符集合中。Bash 因此会根据参数中的换行来分离命令的输出。然后echo 将以空格代替换行来输出这些参数。
注意:这个命令是 shell 的一个内建命令,与 /bin/echo 不同,虽然行为相似。printf
重要程度:中
printf 命令,格式化输出,是 echo 命令的增强。它是 C 语言 printf() 库函数的一个有限的变形,并且在语法上有些不同。
使用 printf 的最主要的应用就是格式化错误消息。read
重要程度:高
从 stdin 中读取一个变量的值,也就是与键盘交互取得变量的值。使用 -a 参数可以取得数组。
对 read 命令来说,-n 选项将不会检测ENTER(新行)键。
read 命令的 -t 选项允许设置read的超时值。
read 命令也可以从重定向的文件中读入变量的值。如果文件中的内容超过一行,那么只有第一行被分配到这个变量中。如果 read 命令有超过一个参数,那么每个变量都会从文件中取得以定义的空白分隔的字符串作为变量的值。文件系统类
cd
重要程度:高
cd 修改目录命令pwd
重要程度:高
打印当前的工作目录。这将给用户(或脚本)当前的工作目录。使用这个命令的结果和从内建变量 $PWD 中读取的值是相同的。pushd、popd、dirs
重要程度:低
这几个命令可以使得工作目录书签化,就是可以按顺序向前或向后移动工作目录。
压栈的动作可以保存工作目录列表。选项可以允许对目录栈作不同的操作。
pushd dir-name 把路径 dir-name 压入目录栈,同时修改当前目录到 dir-name。
popd 将目录栈中最上边的目录弹出,同时修改当前目录到弹出来的那个目录。
dirs 列出所有目录栈的内容(与 $DIRSTACK 便两相比较)。一个成功的 pushd 或者 popd 将会自动的调用 dirs 命令。变量类
let
重要程度:中
let 命令将执行变量的算术操作。在许多情况下,它被看作是复杂的 expr 版本的一个简化版。unset
重要程度:中
unset 命令用来删除一个 shell 变量,效果就是把这个变量设为 null。export
重要程度:中
export 命令将会使得被 export 的变量在运行的脚本(或shell)的所有的子进程中都可用。
不幸的是,没有办法将变量 export 到父进程(就是调用这个脚本或 shell 的进程)中。
关于 export 命令的一个重要的使用就是用在启动文件中,启动文件是用来初始化并且设置环境变量,让用户进程可以存取环境变量。getopts
重要程度:中
可以说这是分析传递到脚本的命令行参数的最强力工具。这个命令与 getopt 外部命令,和C语言中的库函数 getopt 的作用是相同的。它允许传递和连接多个选项到脚本中,并能分
配多个参数到脚本中。
getopts 结构通常都组成一组放在一个 while 循环中,循环过程中每次处理一个选项和参数,然后增加隐含变量 $OPTIND 的值,再进行下一次的处理。
注意: 1.通过命令行传递到脚本中的参数前边必须加上一个减号(-)。这是一个前缀,这样getopts 命令将会认为这个参数是一个选项。事实上,getopts 不会处理不带”-“前缀的参数,如果第一个参数就没有”-“,那么将结束选项的处理。
2.使用 getopts 的 while 循环模版还是与标准的while 循环模版有些不同。没有标准 while循环中的[]判断条件。
3.getopts 结构将会取代 getopt 外部命令。脚本行为
source, . (点命令)
重要程度:高
这个命令在命令行上执行的时候,将会执行一个脚本。在一个文件内一个 source file-name将会加载 file-name 文件。source 一个文件(或点命令)将会在脚本中引入代码,并附加到脚本中(与 C 语言中的 #include 指令的效果相同)。最终的结果就像是在使用 “sourced”行上插入了相应文件的内容,这在多个脚本需要引用相同的数据,或函数库时非常有用。exit
重要程度:高
绝对的停止一个脚本的运行。exit 命令有可以随便找一个整数变量作为退出脚本返回 shell时的退出码。使用 exit 0 对于退出一个简单脚本来说是种好习惯,表明成功运行。
注意:如果不带参数的使用 exit 来退出,那么退出码将是脚本中最后一个命令的退出码。等价于exit $?。exec
重要程度:中
这个 shell 内建命令将使用一个特定的命令来取代当前进程。一般的当 shell 遇到一个命令,它会 fork off 一个子进程来真正的运行命令。使用 exec 内建命令,shell 就不会 fork 了,并且命令的执行将会替换掉当前 shell。因此,当我们在脚本中使用它时,当命令实行完毕,
它就会强制退出脚本。ture
重要程度:高
一个返回成功(就是返回0)退出码的命令,但是除此之外什么事也不做。type[cmd]
重要程度:中
与 which 扩展命令很相像,type cmd 将给出”cmd”的完整路径。与 which 命令不同的是,type 命令是 Bash 内建命令。一个很有用的选项是 -a 选项,使用这个选项可以鉴别所识别的参数是关键字还是内建命令,也可以定位同名的系统命令。bind
重要程度:低
bind 内建命令用来显示或修改readline[5]的键绑定。help
重要程度:中
获得 shell 内建命令的一个小的使用总结。这与 whatis 命令比较象,但是 help 是内建命令。作业控制命令
jobs
重要程度:中
在后台列出所有正在运行的作业,给出作业号。disown
重要程度:中
从 shell 的当前作业表中,删除作业。fg、bg
重要程度:中
fg 命令可以把一个在后台运行的作业放到前台来运行。而 bg 命令将会重新启动一个挂起的作业,并且在后台运行它。如果使用 fg 或者 bg 命令的时候没指定作业号,那么默认将对当前正在运行的作业做操作。wait
重要程度:中
停止脚本的运行,直到后台运行的所有作业都结束为止,或者直到指定作业号或进程号为选项的作业结束为止。
你可以使用 wait 命令来防止在后台作业没完成(这会产生一个孤儿进程)之前退出脚本。logout
重要程度:中
退出一个登陆的 shell,也可以指定一个退出码。times
重要程度:中
给出执行命令所占的时间,使用如下形式输出:
0m0.020s 0m0.020s
这是一种很有限的能力,因此这不常出现于 shell 脚本中。kill
重要程度:高
通过发送一个适当的结束信号,来强制结束一个进程。command
重要程度:中
command 命令会禁用别名和函数的查找。它只查找内部命令以及搜索路径中找到的脚本或可执行程序。注意一下bash 执行命令的优先级:
1.别名
2.关键字
3.函数
4.内置命令
5.脚本或可执行程序($PATH)builtin
重要程度:低
在”builtin”后边的命令将只调用内建命令。暂时的禁用同名的函数或者是同名的扩展命令。enable
重要程度:低
这个命令或者禁用内建命令或者恢复内建命令。如:enable -n kill 将禁用 kill 内建命令,所以当我们调用 kill 时,使用的将是 /bin/kill 外部命令。
-a 选项将会恢复相应的内建命令,如果不带参数的话,将会恢复所有的内建命令。
选项 -f filename 将会从适当的编译过的目标文件[6]中以共享库(DLL)的形式来加载一个内建命令。autoload
重要程度:低
这是从 ksh 的 autoloader 命令移植过来的。一个带有”autoload”声明的函数,在它第一次被调用的时候才会被加载。这样做会节省系统资源。
注意:autoload 命令并不是 Bash 安装时候的核心命令的一部分。这个命令需要使用命令enable -f(见上边enable 命令)来加载。
用途说明
我们知道,在Linux系统中,冒号(:)常用来做路径的分隔符(PATH),数据字段的分隔符(/etc/passwd)等。其实,冒号(:)在Bash中也是一个内建命令,它啥也不做,是个空命令、只起到占一个位置的作用,但有时候确实需要它。当然,它也有它的用途的,否则没必要存在。在·Linux的帮助页中说它除了参数扩展和重定向之外不产生任何作用。
No effect; the command does nothing beyond expanding arguments and performing any specified redirections. A zero exit code is returned.
常用参数
格式::
·啥也不做,只起到占位符的作用。比如在编写脚本的过程中,某些语法结构需要多个部分组成,但开始阶段并没有想好或完成相应的代码,这时就可以用:来做占位符,否则执行时就会报错。
- if [ "today" == "2011-08-29" ]; then
- :
- else
- :
- fi
格式:: your comment here
格式:# your comment here
写代码注释(单行注释)。
格式:: 'comment line1
comment line2
more comments'
写多行注释。
格式:: >file
格式:>file
清空文件file的内容。
格式:: ${VAR:=DEFAULT}
当变量VAR没有声明或者为NULL时,将VAR设置为默认值DEFAULT。如果不在前面加上:命令,那么就会把${VAR:=DEFAULT}本身当做一个命令来执行,报错是肯定的。
使用示例
示例一 参数扩展
[root@node56 ~]# : abc=1234
[root@node56 ~]# echo $abc
[root@node56 ~]# : ${abc:=1234}
[root@node56 ~]# echo $abc
1234
[root@node56 ~]# ${abc:=1234}
-bash: 1234: command not found
[root@node56 ~]#
示例二 清空文件
[root@node56 ~]# cat <<<"Hello" >123.txt
[root@node56 ~]# cat 123.txt
Hello
[root@node56 ~]# : >123.txt
[root@node56 ~]# cat 123.txt
[root@node56 ~]#
示例三 脚本注释、占位符
脚本test_colon.sh
- #!/bin/sh
- : this is single line comment
- : 'this is a multiline comment,
- second line
- end of comments'
- if [ "1" == "1" ]; then
- echo "yes"
- else
- :
- fi
[root@node56 ~]# ./test_colon.sh
yes
[root@node56 ~]#
在某些旧的shell脚本程序里,你会导刊冒号被用在一行的开始以引起一个注释,但现代的脚本程序总是用"#"来开始一个注释行,因为这样做的执行效率更高.
冒号命令是一个控命令.它偶尔会被用来简化逻辑条件,相当于true的一个假名.因为它是内建的,所以它比true运行的要快,但它的可读性要差了不少. 读者可能会在while循环的某个条件里面看到它,"while :" 表示这是一个无限循环,相当于更常见的"while true". ":"还被用在对变量进行条件化设置的情况下,比如说
Linux declare命令
 Linux 命令大全
Linux 命令大全
Linux declare命令用于声明 shell 变量。
declare为shell指令,在第一种语法中可用来声明变量并设置变量的属性([rix]即为变量的属性),在第二种语法中可用来显示shell函数。若不加上任何参数,则会显示全部的shell变量与函数(与执行set指令的效果相同)。
语法
declare [+/-][rxi][变量名称=设置值] 或 declare -f
参数说明:
- +/- "-"可用来指定变量的属性,"+"则是取消变量所设的属性。
- -f 仅显示函数。
- r 将变量设置为只读。
- x 指定的变量会成为环境变量,可供shell以外的程序来使用。
- i [设置值]可以是数值,字符串或运算式。
实例
声明整数型变量
# declare -i ab //声明整数型变量# ab=56 //改变变量内容# echo $ab //显示变量内容56
改变变量属性
# declare -i ef //声明整数型变量# ef=1 //变量赋值(整数值)# echo $ef //显示变量内容1# ef="wer" //变量赋值(文本值)# echo $ef 0# declare +i ef //取消变量属性# ef="wer"# echo $efwer
设置变量只读
# declare -r ab //设置变量为只读# ab=88 //改变变量内容-bash: ab: 只读变量# echo $ab //显示变量内容56
声明数组变量
# declare -a cd='([0]="a" [1]="b" [2]="c")' //声明数组变量# echo ${cd[1]}b //显示变量内容# echo ${cd[@]} //显示整个数组变量内容a b c
显示函数
# declare -fcommand_not_found_handle () { if [ -x /usr/lib/command-not-found ]; then /usr/bin/python /usr/lib/command-not-found -- $1; return $?; else if [ -x /usr/share/command-not-found ]; then /usr/bin/python /usr/share/command-not-found -- $1; return $?; else return 127; fi; fi}
Linux export命令
Linux 命令大全
Linux export命令用于设置或显示环境变量。
在shell中执行程序时,shell会提供一组环境变量。export可新增,修改或删除环境变量,供后续执行的程序使用。export的效力仅及于该次登陆操作。
语法
export [-fnp][变量名称]=[变量设置值]
参数说明:
- -f 代表[变量名称]中为函数名称。
- -n 删除指定的变量。变量实际上并未删除,只是不会输出到后续指令的执行环境中。
- -p 列出所有的shell赋予程序的环境变量。
实例
列出当前所有的环境变量
# export -p //列出当前的环境变量值declare -x HOME=“/root“declare -x LANG=“zh_CN.UTF-8“declare -x LANGUAGE=“zh_CN:zh“declare -x LESSCLOSE=“/usr/bin/lesspipe %s %s“declare -x LESSOPEN=“| /usr/bin/lesspipe %s“declare -x LOGNAME=“root“declare -x LS_COLORS=““declare -x MAIL=“/var/mail/root“declare -x OLDPWDdeclare -x PATH=“/opt/toolchains/arm920t-eabi/bin:/opt/toolchains/arm920t-eabi/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games“declare -x PWD=“/root“declare -x SHELL=“/bin/bash“declare -x SHLVL=“1“declare -x SPEECHD_PORT=“6560“declare -x SSH_CLIENT=“192.168.1.65 1674 22“declare -x SSH_CONNECTION=“192.168.1.65 1674 192.168.1.3 22“declare -x SSH_TTY=“/dev/pts/2“declare -x TERM=“XTERM“declare -x USER=“root“declare -x XDG_SESSION_COOKIE=“93b5d3d03e032c0cf892a4474bebda9f-1273864738.954257-340206484“
定义环境变量
# export MYENV //定义环境变量# export -p //列出当前的环境变量declare -x HOME=“/root“declare -x LANG=“zh_CN.UTF-8“declare -x LANGUAGE=“zh_CN:zh“declare -x LESSCLOSE=“/usr/bin/lesspipe %s %s“declare -x LESSOPEN=“| /usr/bin/lesspipe %s“declare -x LOGNAME=“root“declare -x LS_COLORS=““declare -x MAIL=“/var/mail/root“declare -x MYENVdeclare -x OLDPWDdeclare -x PATH=“/opt/toolchains/arm920t-eabi/bin:/opt/toolchains/arm920t-eabi/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games“declare -x PWD=“/root“declare -x SHELL=“/bin/bash“declare -x SHLVL=“1“declare -x SPEECHD_PORT=“6560“declare -x SSH_CLIENT=“192.168.1.65 1674 22“declare -x SSH_CONNECTION=“192.168.1.65 1674 192.168.1.3 22“declare -x SSH_TTY=“/dev/pts/2“declare -x TERM=“XTERM“declare -x USER=“root“declare -x XDG_SESSION_COOKIE=“93b5d3d03e032c0cf892a4474bebda9f-1273864738.954257-340206484“
定义环境变量赋值
# export MYENV=7 //定义环境变量并赋值# export -pdeclare -x HOME=“/root“declare -x LANG=“zh_CN.UTF-8“declare -x LANGUAGE=“zh_CN:zh“declare -x LESSCLOSE=“/usr/bin/lesspipe %s %s“declare -x LESSOPEN=“| /usr/bin/lesspipe %s“declare -x LOGNAME=“root“declare -x LS_COLORS=““declare -x MAIL=“/var/mail/root“declare -x MYENV=“7“declare -x OLDPWDdeclare -x PATH=“/opt/toolchains/arm920t-eabi/bin:/opt/toolchains/arm920t-eabi/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games“declare -x PWD=“/root“declare -x SHELL=“/bin/bash“declare -x SHLVL=“1“declare -x SPEECHD_PORT=“6560“declare -x SSH_CLIENT=“192.168.1.65 1674 22“declare -x SSH_CONNECTION=“192.168.1.65 1674 192.168.1.3 22“declare -x SSH_TTY=“/dev/pts/2“declare -x TERM=“XTERM“declare -x USER=“root“declare -x XDG_SESSION_COOKIE=“93b5d3d03e032c0cf892a4474bebda9f-1273864738.954257-340206484“
Shell test命令
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
数值测试
实例演示:
num1=100num2=100if test $[num1] -eq $[num2]then echo '两个数相等!'else echo '两个数不相等!'fi
输出结果:
两个数相等!字符串测试
实例演示:
num1="runoob"num2="runoob"if test num1=num2then echo '两个字符串相等!'else echo '两个字符串不相等!'fi
输出结果:
两个字符串相等!文件测试
实例演示:
cd /binif test -e ./bashthen echo '文件已存在!'else echo '文件不存在!'fi
输出结果:
文件已存在!另外,Shell还提供了与( -a )、或( -o )、非( ! )三个逻辑操作符用于将测试条件连接起来,其优先级为:"!"最高,"-a"次之,"-o"最低。例如:
cd /binif test -e ./notFile -o -e ./bashthen echo '有一个文件存在!'else echo '两个文件都不存在'fi
输出结果:
有一个文件存在!Shell 变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要),如:
your_name="runoob.com"
注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
- 首个字符必须为字母(a-z,A-Z)。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
除了显式地直接赋值,还可以用语句给变量赋值,如:
for file in `ls /etc`
以上语句将 /etc 下目录的文件名循环出来。
使用变量
使用一个定义过的变量,只要在变量名前面加美元符号即可,如:
your_name="qinjx"echo $your_nameecho ${your_name}
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
for skill in Ada Coffe Action Java; do echo "I am good at ${skill}Script"done
如果不给skill变量加花括号,写成echo "I am good at $skillScript",解释器就会把$skillScript当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
推荐给所有变量加上花括号,这是个好的编程习惯。
已定义的变量,可以被重新定义,如:
your_name="tom"echo $your_nameyour_name="alibaba"echo $your_name
这样写是合法的,但注意,第二次赋值的时候不能写$your_name="alibaba",使用变量的时候才加美元符($)。
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bashmyUrl="http://www.w3cschool.cc"readonly myUrlmyUrl="http://www.runoob.com"
运行脚本,结果如下:
/bin/sh: NAME: This variable is read only.
删除变量
使用 unset 命令可以删除变量。语法:
unset variable_name变量被删除后不能再次使用。unset 命令不能删除只读变量。
实例
#!/bin/shmyUrl="http://www.runoob.com"unset myUrlecho $myUrl
以上实例执行将没有任何输出。
变量类型
运行shell时,会同时存在三种变量:
- 1) 局部变量 局部变量在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
- 2) 环境变量 所有的程序,包括shell启动的程序,都能访问环境变量,有些程序需要环境变量来保证其正常运行。必要的时候shell脚本也可以定义环境变量。
- 3) shell变量 shell变量是由shell程序设置的特殊变量。shell变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了shell的正常运行
Shell 字符串
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。单双引号的区别跟PHP类似。
单引号
str='this is a string'
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单引号(对单引号使用转义符后也不行)。
双引号
your_name='qinjx'str="Hello, I know your are \"$your_name\"! \n"
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
拼接字符串
your_name="qinjx"greeting="hello, "$your_name" !"greeting_1="hello, ${your_name} !"echo $greeting $greeting_1
获取字符串长度
string="abcd"echo ${#string} #输出 4
提取子字符串
以下实例从字符串第 2 个字符开始截取 4 个字符:
string="runoob is a great site"echo ${string:1:4} # 输出 unoo
查找子字符串
查找字符 "i 或 s" 的位置:
string="runoob is a great company"echo `expr index "$string" is` # 输出 8
注意: 以上脚本中 "`" 是反引号,而不是单引号 "'",不要看错了哦。
Shell 数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
类似与C语言,数组元素的下标由0开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于0。
定义数组
在Shell中,用括号来表示数组,数组元素用"空格"符号分割开。定义数组的一般形式为:
数组名=(值1 值2 ... 值n)
例如:
array_name=(value0 value1 value2 value3)
或者
array_name=(value0value1value2value3)
还可以单独定义数组的各个分量:
array_name[0]=value0array_name[1]=value1array_name[n]=valuen
可以不使用连续的下标,而且下标的范围没有限制。
读取数组
读取数组元素值的一般格式是:
${数组名[下标]}
例如:
valuen=${array_name[n]}
使用@符号可以获取数组中的所有元素,例如:
echo ${array_name[@]}
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
# 取得数组元素的个数length=${#array_name[@]}# 或者length=${#array_name[*]}# 取得数组单个元素的长度lengthn=${#array_name[n]}
Shell 注释
以"#"开头的行就是注释,会被解释器忽略。
sh里没有多行注释,只能每一行加一个#号。只能像这样:
#--------------------------------------------# 这是一个注释# author:菜鸟教程# site:www.runoob.com# slogan:学的不仅是技术,更是梦想!#--------------------------------------------##### 用户配置区 开始 ######## 这里可以添加脚本描述信息# ###### 用户配置区 结束 #####
如果在开发过程中,遇到大段的代码需要临时注释起来,过一会儿又取消注释,怎么办呢?
每一行加个#符号太费力了,可以把这一段要注释的代码用一对花括号括起来,定义成一个函数,没有地方调用这个函数,这块代码就不会执行,达到了和注释一样的效果。
Shell 传递参数
我们可以在执行 Shell 脚本时,向脚本传递参数,脚本内获取参数的格式为:$n。n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推……
实例
以下实例我们向脚本传递三个参数,并分别输出,其中 $0 为执行的文件名:
#!/bin/bash# author:菜鸟教程# url:www.runoob.comecho "Shell 传递参数实例!";echo "执行的文件名:$0";echo "第一个参数为:$1";echo "第二个参数为:$2";echo "第三个参数为:$3";
为脚本设置可执行权限,并执行脚本,输出结果如下所示:
$ chmod +x test.sh $ ./test.sh 1 2 3Shell 传递参数实例!执行的文件名:./test.sh第一个参数为:1第二个参数为:2第三个参数为:3
另外,还有几个特殊字符用来处理参数:
如"$*"用「"」括起来的情况、以"$1 $2 … $n"的形式输出所有参数。$$脚本运行的当前进程ID号$!后台运行的最后一个进程的ID号$@与$*相同,但是使用时加引号,并在引号中返回每个参数。
如"$@"用「"」括起来的情况、以"$1" "$2" … "$n" 的形式输出所有参数。$-显示Shell使用的当前选项,与set命令功能相同。$?显示最后命令的退出状态。0表示没有错误,其他任何值表明有错误。
#!/bin/bash# author:菜鸟教程# url:www.runoob.comecho "Shell 传递参数实例!";echo "第一个参数为:$1";echo "参数个数为:$#";echo "传递的参数作为一个字符串显示:$*";
执行脚本,输出结果如下所示:
$ chmod +x test.sh $ ./test.sh 1 2 3Shell 传递参数实例!第一个参数为:1参数个数为:3传递的参数作为一个字符串显示:1 2 3
$* 与 $@ 区别:
- 相同点:都是引用所有参数。
- 不同点:只有在双引号中体现出来。假设在脚本运行时写了三个参数 1、2、3,,则 " * " 等价于 "1 2 3"(传递了一个参数),而 "@" 等价于 "1" "2" "3"(传递了三个参数)。
#!/bin/bash# author:菜鸟教程# url:www.runoob.comecho "-- \$* 演示 ---"for i in "$*"; do echo $idoneecho "-- \$@ 演示 ---"for i in "$@"; do echo $idone
执行脚本,输出结果如下所示:
$ chmod +x test.sh $ ./test.sh 1 2 3-- $* 演示 ---1 2 3-- $@ 演示 ---123
常用方式
示例
env
env - 在重建的环境中运行程序设置环境中的每个NAME为VALUE,并且运行COMMAND.-i, --ignore-environment 不带环境变量启动 -u, --unset=NAME 从环境变量中删除一个变量 --help 显示帮助并退出 --version 输出版本信息并退出 单独的-隐含-i.如果没有COMMAND,那么打印结果环境变量.
参数扩展的表示形式为:${expression}。expression包括各种字符直到匹配上'}'。当出现以下情况时候'}'不会被检查来匹配:
1)在转义字符\之后,如\{;
2)在引号里面,如‘}’;
3) 在算术表达式,命令替换或者变量扩展里面的,如${value}
最简单的参数扩展形式如:${parameter}
使用如下模式可以修改参数扩展:
- ${parameter:-[word]}
- Use Default Values. If parameter is unset or null, the expansion of word (or an empty string if word is omitted) shall be substituted; otherwise, the value of parameter shall be substituted.
- 当${parameter}值为空或者没有设定的时候,用[word]值来替换,否则它就是该表达式的值。
[hdfs@cdh51kdc ~]$ bb=3[hdfs@cdh51kdc ~]$ echo ${aa}[hdfs@cdh51kdc ~]$ echo ${bb}3[hdfs@cdh51kdc ~]$ echo ${aa-${bb}}3[hdfs@cdh51kdc ~]$ aa=2[hdfs@cdh51kdc ~]$ echo ${aa-${bb}}2- ${parameter:=[word]}
- Assign Default Values. If parameter is unset or null, the expansion of word (or an empty string if word is omitted) shall be assigned to parameter. In all cases, the final value of parameter shall be substituted. Only variables, not positional parameters or special parameters, can be assigned in this way.
- 当${parameter}值为空或者没有设定的时候,用[word]值来给${parameter}赋值并替换最后的表达式,否则它就是该表达式的值。
[hdfs@cdh51kdc ~]$ echo ${aa-${bb}}2[hdfs@cdh51kdc ~]$ echo ${aa:=${bb}}2[hdfs@cdh51kdc ~]$ echo ${cc}[hdfs@cdh51kdc ~]$ echo ${cc:=${bb}}3[hdfs@cdh51kdc ~]$ echo ${cc}3- ${parameter:?[word]}
- Indicate Error if Null or Unset. If parameter is unset or null, the expansion of word (or a message indicating it is unset if wordis omitted) shall be written to standard error and the shell exits with a non-zero exit status. Otherwise, the value of parametershall be substituted. An interactive shell need not exit.
- 当${parameter}值为空或者没有设定的时候,用[word]值作为标准错误输出提示并退出shell且返回非0状态。否则它就是该表达式的值。
[hdfs@cdh51kdc ~]$ echo ${cc:?"Value not set"}3[hdfs@cdh51kdc ~]$ echo ${dd:?"Value not set"}-bash: dd: Value not set- ${parameter:+[word]}
- Use Alternative Value. If parameter is unset or null, null shall be substituted; otherwise, the expansion of word (or an empty string if word is omitted) shall be substituted.
- 当${parameter}值为空或者没有设定的时候,表达式返回null。否则用[word]替换表达式的值。
[hdfs@cdh51kdc ~]$ echo ${cc:+"Value not set"}Value not set[hdfs@cdh51kdc ~]$ echo ${dd:+"Value not set"}${#parameter}
- String Length. The length in characters of the value of parameter shall be substituted. If parameter is '*' or '@', the result of the expansion is unspecified. If parameter is unset and set -u is in effect, the expansion shall fail.
- 表达式返回${parameter}值中字符的个数。
[hdfs@cdh51kdc ~]$ echo ${#cc}1[hdfs@cdh51kdc ~]$ echo ${#dd}0The following four varieties of parameter expansion provide for substring processing. In each case, pattern matching notation (see Pattern Matching Notation), rather than regular expression notation, shall be used to evaluate the patterns. Ifparameter is '#', '*', or '@', the result of the expansion is unspecified. If parameter is unset and set -u is in effect, the expansion shall fail. Enclosing the full parameter expansion string in double-quotes shall not cause the following four varieties of pattern characters to be quoted, whereas quoting characters within the braces shall have this effect. In each variety, if word is omitted, the empty pattern shall be used.
${parameter%[word]}
- Remove Smallest Suffix Pattern. The word shall be expanded to produce a pattern. The parameter expansion shall then result in parameter, with the smallest portion of the suffix matched by the pattern deleted. If present,word shall not begin with an unquoted '%'.
- 用[word]产生的模式来匹配${parameter}的后缀并去除掉最小匹配部分
[hdfs@cdh51kdc ~]$ echo ${cc}Value not set[hdfs@cdh51kdc ~]$ echo ${cc%"et"}Value not s- ${parameter%%[word]}
- Remove Largest Suffix Pattern. The word shall be expanded to produce a pattern. The parameter expansion shall then result in parameter, with the largest portion of the suffix matched by the pattern deleted.
- 用[word]产生的模式来匹配${parameter}的后缀并去除掉最大匹配部分
[hdfs@cdh51kdc ~]$ echo ${cc%%t*}Value no[hdfs@cdh51kdc ~]$ echo ${cc%t*}Value not se- ${parameter#[word]}
- Remove Smallest Prefix Pattern. The word shall be expanded to produce a pattern. The parameter expansion shall then result in parameter, with the smallest portion of the prefix matched by the pattern deleted. If present, word shall not begin with an unquoted '#'.
- ${parameter##[word]}
- Remove Largest Prefix Pattern. The word shall be expanded to produce a pattern. The parameter expansion shall then result in parameter, with the largest portion of the prefix matched by the pattern deleted.
- 最后两个分别是去除掉前缀的[word]最小匹配和最大匹配
[hdfs@cdh51kdc ~]$ echo ${cc#*t}set[hdfs@cdh51kdc ~]$ echo ${cc##*t}[hdfs@cdh51kdc ~]$ echo ${cc#V}alue not set
case语句适用于需要进行多重分支的应用情况。
#!/bin/bash
read -p "press some key ,then press return :" KEY
case $KEY in
[a-z]|[A-Z])
echo "It's a letter."
;;
[0-9])
echo "It's a digit."
;;
*)
echo "It's function keys、Spacebar or other ksys."
esac
shell里的IFS内置环境变量
Posted on 2013-03-12 18:19 幻海蓝梦 阅读(917) 评论(0) 编辑 收藏 所属分类: Shell"welcome to www groad net"item $msg"Item: $item"运行输出:
# sh temp.sh
Item: welcome
Item: to
Item: www
Item: groad
Item: net
上 面用一个 for 循环遍历了变量 msg 里的所有项。 msg 变量里存储的各个单词都是用空格分开的,而 for 能依次取出这些单词,正是依靠 IFS 这个变量作为分隔符。如果将 msg 变量改为 CSV (comma separaed values 逗号分隔值)格式,那么按照默认的 IFS 值就无法解析出各个单词,如:
sh temp.sh
Item: welcome,to,www,groad,net
这样,整个字符串就当成一个 item 被获取了。
此时如果仍然希望逐个获得各个单词,那么需要修改 IFS 变量的值,如:
"welcome,to,www,groad,net"#备份原来的值 in echo 运行输出:
# sh tmp.sh
Item: welcome
Item: to
Item: www
Item: groad
Item: net
Shell 脚本中有个变量叫IFS(Internal Field Seprator) ,内部域分隔符。完整定义是The shell uses the value stored in IFS, which is the space, tab, and newline characters by default, to delimit words for the read and set commands, when parsing output from command substitution, and when performing variable substitution.
IFS 是一种 set 变量,当 shell 处理"命令替换"和"参数替换"时,shell 根据 IFS 的值,默认是 space, tab, newline 来拆解读入的变量,然后对特殊字符进行处理,最后重新组合赋值给该变量。
1 查看IFS的值
echo "$IFS"
echo "$IFS"|od -b
0000000 040 011 012 012
0000004
直接输出IFS是看不到值的,转化为二进制就可以看到了,"040"是空格,"011"是Tab,"012"是换行符"\n" 。最后一个 012 是因为 echo 默认是会换行的。
2 实际中的应用
#!/bin/bash
OLD_IFS=$IFS #保存原始值
IFS="" #改变IFS的值
...
说到shell通配符(wildcard),大家在使用时候会经常用到。下面是一个实例:
11234[chengmo@localhost ~/shell]$lsa.txt b.txt c.old#21234[chengmo@localhost ~/shell]$ls*.txta.txt b.txt#312[chengmo@localhost ~/shell]$lsd*.txtls: 无法访问 d*.txt: 没有那个文件或目录
从上面这个实例,不知道大家有没有发现问题呢。我们先了解一下,通配符相关知识,再分析下这个实例吧。
一、linux shell通配符(wildcard)
通配符是由shell处理的(不是由所涉及到命令语句处理的,其实我们在shell各个命令中也没有发现有这些通配符介绍), 它只会出现在 命令的“参数”里(它不用在 命令名称里, 也不用在 操作符上)。当shell在“参数”中遇到了通配符时,shell会将其当作路径或文件名去在磁盘上搜寻可能的匹配:若符合要求的匹配存在,则进行代换(路径扩展);否则就将该通配符作为一个普通字符传递给“命令”,然后再由命令进行处理。总之,通配符 实际上就是一种shell实现的路径扩展功能。在 通配符被处理后, shell会先完成该命令的重组,然后再继续处理重组后的命令,直至执行该命令。
我们回过头分析上面命令吧:在第2个命令中,*.txt 实际shell搜索文件,找到了符合条件的文件,命令会变成:ls a.txt b.txt ,实际在执行ls 时候传给它的是a.txt b.txt .
而命令3,d*.txt 由于当前目录下面没有这样的文件或目录,直接将”d*.txt” 作为ls 参数,传给了 ls .这个时候”*” 只是一个普通的 ls 参数而已,已经失去了它通配意义。 由于找不到文件,所以会出现:无法访问提示!
了解了shell通配符,我们现在看下,shell常见通配符有那一些了。
shell常见通配符:
字符含义实例*匹配 0 或多个字符a*b a与b之间可以有任意长度的任意字符, 也可以一个也没有, 如aabcb, axyzb, a012b, ab。?匹配任意一个字符a?b a与b之间必须也只能有一个字符, 可以是任意字符, 如aab, abb, acb, a0b。[list] 匹配 list 中的任意单一字符a[xyz]b a与b之间必须也只能有一个字符, 但只能是 x 或 y 或 z, 如: axb, ayb, azb。[!list] 匹配 除list 中的任意单一字符a[!0-9]b a与b之间必须也只能有一个字符, 但不能是阿拉伯数字, 如axb, aab, a-b。[c1-c2]匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z]a[0-9]b 0与9之间必须也只能有一个字符 如a0b, a1b... a9b。{string1,string2,...}匹配 sring1 或 string2 (或更多)其一字符串a{abc,xyz,123}b a与b之间只能是abc或xyz或123这三个字符串之一。
需要说明的是:通配符看起来有点象正则表达式语句,但是它与正则表达式不同的,不能相互混淆。把通配符理解为shell 特殊代号字符就可。而且涉及的只有,*,? [] ,{} 这几种。
二、shell元字符(特殊字符 Meta)
shell 除了有通配符之外,由shell 负责预先先解析后,将处理结果传给命令行之外,shell还有一系列自己的其他特殊字符。
字符说明IFS由 <space> 或 <tab> 或 <enter> 三者之一组成(我们常用 space )。CR由 <enter> 产生。=设定变量。$作变量或运算替换(请不要与 shell prompt 搞混了)。>重导向 stdout。 *<重导向 stdin。 *|命令管线。 *&重导向 file descriptor ,或将命令置于背境执行。 *( )将其内的命令置于 nested subshell 执行,或用于运算或命令替换。 *{ }将其内的命令置于 non-named function 中执行,或用在变量替换的界定范围。;在前一个命令结束时,而忽略其返回值,继续执行下一个命令。 *&&在前一个命令结束时,若返回值为 true,继续执行下一个命令。 *||在前一个命令结束时,若返回值为 false,继续执行下一个命令。 *!执行 history 列表中的命令。*加入”*” 都是作用在命令名直接。可以看到shell 元字符,基本是作用在命令上面,用作多命令分割(或者参数分割)。因此看到与通配符有相同的字符,但是实际上作用范围不同。所以不会出现混淆。
以下是man bash 得到的英文解析:
metacharacter
A character that, when unquoted, separates words. One of the following:
| & ; ( ) < > space tab
control operator
A token that performs a control function. It is one of the following symbols:
|| & && ; ;; ( ) | <newline>
三、shell转义符
有时候,我们想让 通配符,或者元字符 变成普通字符,不需要使用它。那么这里我们就需要用到转义符了。 shell提供转义符有三种。
字符说明‘’(单引号)又叫硬转义,其内部所有的shell 元字符、通配符都会被关掉。注意,硬转义中不允许出现’(单引号)。“”(双引号)又叫软转义,其内部只允许出现特定的shell 元字符:$用于参数代换 `用于命令代替\(反斜杠) 又叫转义,去除其后紧跟的元字符或通配符的特殊意义。man bash 英文解释如下:
There are three quoting mechanisms: the escape character, single quotes, and double quotes.
实例:
1234567891011[chengmo@localhost ~/shell]$ls\*.txtls: 无法访问 *.txt: 没有那个文件或目录[chengmo@localhost ~/shell]$ls'*.txt'ls: 无法访问 *.txt: 没有那个文件或目录[chengmo@localhost ~/shell]$ls'a.txt'a.txt[chengmo@localhost ~/shell]$ls*.txta.txt b.txt
可以看到,加入了转义符 “*”已经失去了通配符意义了。
四、shell解析脚本的过程
看到上面说的这些,想必大家会问到这个问题是,有这么想特殊字符,通配符,那么 shell在得到一条命令,到达是怎么样处理的呢?我们看下下面的图:
如果用双引号包括起来,shell检测跳过了1-4步和9-10步,单引号包括起来,shell检测就会跳过了1-10步。也就是说,双引号 只经过参数扩展、命令代换和算术代换就可以送入执行步骤,而单引号转义符直接会被送入执行步骤。而且,无论是双引号转义符还是单引号转义符在执行的时候能够告诉各个命令自身内部是一体的,但是其本身在执行时是并不是命令中文本的一部分。

SHELL中的IFS详解
在bash中IFS是内部的域分隔符,manual中对其的叙述如下:
IFS The Internal Field Separator that is used for word splitting after expansion and to split lines into words with the read builtin command. The default value is ”.
如下是一些值得注意的地方。
1. IFS的默认值为:空白(包括:空格,tab, 和新行),将其ASSII码用十六进制打印出来就是:20 09 0a (见下面的shell脚本)。
2. IFS对空格的空白的处理和其他字符不一样,左右两边的纯空白会被忽略,多个连续的空白被当成一个IFS处理。
3. S*中使用IFS中的第一个字符。
4. awk中的FS(域分隔符)也和IFS有类似的用法和作用。
我写了一个shell脚本来演示IFS的用法和作用,如下:
运行这个脚本结果如下:
1.echo -e $"\n"
2.echo $'\n'
3.echo $"\n"
\n
第一个第二个执行结果为两个空行,第三个执行结果为\n,这是什么愿意呢,求大神解释下

SATA硬盘相互之间独立工作,主板上的每个SATA端口只连接一个SATA硬盘,所以多个SATA硬盘同时使用时无需任何设置,可以同时工作。
PATA硬盘则需要设置主从。当主板上的1个IDE端口同时连接两个PATA硬盘时,必须将两个硬盘分别设为主盘和从盘,主板控制器才能区分。
PATA硬盘的产品标签上都有主从设置方法的说明,不同产品设置方法不同,但是都是通过设置硬盘接口的跳线来实现的。标签上的Master即为主盘,Slave即为从盘,Cable Select为线缆选择的自动模式。
常见的PATA硬盘主从设置标签示意图如下图:

硬盘的种类主要是SCSI 、IDE 、以及现在流行的SATA等;任何一种硬盘的生产都要一定的标准;随着相应的标准的升级,硬盘生产技术也在升级;比如 SCSI标准已经经历了SCSI-1 、SCSI-2、SCSI-3;其中目前咱们经常在服务器网站看到的 Ultral-160就是基于SCSI-3标准的;IDE 遵循的是ATA标准,而目前流行的SATA,是ATA标准的升级版本;IDE是并口设备,而SATA是串口,SATA的发展目的是替换IDE;
我们知道信息存储在硬盘里,把它拆开也看不见里面有任何东西,只有些盘片。假设,你用显微镜把盘片放大,会看见盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化;凸起的地方代表数字1(磁化为1),凹的地方代表数字0。因此硬盘可以以二进制来存储表示文字、图片等信息。
1、硬盘的组成
硬盘大家一定不会陌生,我们可以把它比喻成是我们电脑储存数据和信息的大仓库。一般说来,无论哪种硬盘,都是由盘片、磁头、盘片主轴、控制电机、磁头控制器、数据转换器、接口、缓存等几个部份组成。
平面图:

立体图
所有的盘片都固定在一个旋转轴上,这个轴即盘片主轴。而所有盘片之间是绝对平行的,在每个盘片的存储面上都有一个磁头,磁头与盘片之间的距离比头发 丝的直径还小。所有的磁头连在一个磁头控制器上,由磁头控制器负责各个磁头的运动。磁头可沿盘片的半径方向动作,(实际是斜切向运动),每个磁头同一时刻也必须是同轴的,即从正上方向下看,所有磁头任何时候都是重叠的(不过目前已经有多磁头独立技术,可不受此限制)。而盘片以每分钟数千转到上万转的速度在高速旋转,这样磁头就能对盘片上的指定位置进行数据的读写操作。
由于硬盘是高精密设备,尘埃是其大敌,所以必须完全密封。
2、硬盘的工作原理
硬盘在逻辑上被划分为磁道、柱面以及扇区.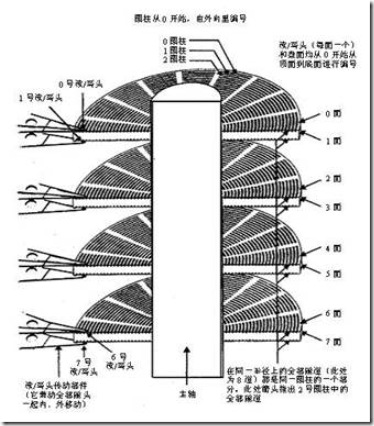
硬盘的每个盘片的每个面都有一个读写磁头,磁盘盘面区域的划分如图所示。
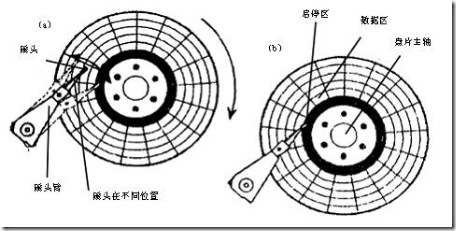


磁头靠近主轴接触的表面,即线速度最小的地方,是一个特殊的区域,它不存放任何数据,称为启停区或着陆区(LandingZone),启停区外就是数据区。在最外圈,离主轴最远的地方是“0”磁道,硬盘数据的存放就是从最外圈开始的。那么,磁头是如何找到“0”磁道的位置的 呢?在硬盘中还有一个叫“0”磁道检测器的构件,它是用来完成硬盘的初始定位。“0”磁道是如此的重要,以致很多硬盘仅仅因为“0”磁道损坏就报废,这是 非常可惜的。
早期的硬盘在每次关机之前需要运行一个被称为Parking的程序,其作用是让磁头回到启停区。现代硬盘在设计上已摒弃了这个虽不复杂却很让人不愉快的小缺陷。硬盘不工作时,磁头停留在启停区,当需要从硬盘读写数据时,磁盘开始旋转。旋转速度达到额定的高速时,磁头就会因盘片旋转产生的气流而抬起, 这时磁头才向盘片存放数据的区域移动。
盘片旋转产生的气流相当强,足以使磁头托起,并与盘面保持一个微小的距离。这个距离越小,磁头读写数据的灵敏度就越高,当然对硬盘各部件的要求也越 高。早期设计的磁盘驱动器使磁头保持在盘面上方几微米处飞行。稍后一些设计使磁头在盘面上的飞行高度降到约0.1μm~0.5μm,现在的水平已经达到 0.005μm~0.01μm,这只是人类头发直径的千分之一。
气流既能使磁头脱离开盘面,又能使它保持在离盘面足够近的地方,非常紧密地跟随着磁盘表面呈起伏运动,使磁头飞行处于严格受控状态。磁头必须飞行在盘面上方,而不是接触盘面,这种位置可避免擦伤磁性涂层,而更重要的是不让磁性涂层损伤磁头。
但是,磁头也不能离盘面太远,否则,就不能使盘面达到足够强的磁化,难以读出盘上的磁化翻转(磁极转换形式,是磁盘上实际记录数据的方式)。
硬盘驱动器磁头的飞行悬浮高度低、速度快,一旦有小的尘埃进入硬盘密封腔内,或者一旦磁头与盘体发生碰撞,就可能造成数据丢失,形成坏块,甚至造成 磁头和盘体的损坏。所以,硬盘系统的密封一定要可靠,在非专业条件下绝对不能开启硬盘密封腔,否则,灰尘进入后会加速硬盘的损坏。另外,硬盘驱动器磁头的寻道伺服电机多采用音圈式旋转或直线运动步进电机,在伺服跟踪的调节下精确地跟踪盘片的磁道,所以,硬盘工作时不要有冲击碰撞,搬动时要小心轻放。
这种硬盘就是采用温彻斯特(Winchester)技术制造的硬盘,所以也被称为温盘,目前绝大多数硬盘都采用此技术。
3、盘面、磁道、柱面和扇区
硬盘的读写是和扇区有着紧密关系的。在说扇区和读写原理之前先说一下和扇区相关的”盘面”、“磁道”、和“柱面”。
1. 盘面
硬盘的盘片一般用铝合金材料做基片,高速硬盘也可能用玻璃做基片。硬盘的每一个盘片都有两个盘面(Side),即上、下盘面,一般每个盘面都会利用,都可以存储数据,成为有效盘片,也有极个别的硬盘盘面数为单数。每一个这样的有效盘面都有一个盘面号,按顺序从上至下从“0”开始依次编号。在硬盘系统中,盘面号又叫磁头号,因为每一个有效盘面都有一个对应的读写磁头。硬盘的盘片组在2~14片不等,通常有2~3个盘片,故盘面号(磁头号)为0~3或 0~5。
2. 磁道
磁盘在格式化时被划分成许多同心圆,这些同心圆轨迹叫做磁道(Track)。磁道从外向内从0开始顺序编号。硬盘的每一个盘面有300~1 024个磁道,新式大容量硬盘每面的磁道数更多。信息以脉冲串的形式记录在这些轨迹中,这些同心圆不是连续记录数据,而是被划分成一段段的圆弧,这些圆弧的角速度一样。由于径向长度不一样,所以,线速度也不一样,外圈的线速度较内圈的线速度大,即同样的转速下,外圈在同样时间段里,划过的圆弧长度要比内圈 划过的圆弧长度大。每段圆弧叫做一个扇区,扇区从“1”开始编号,每个扇区中的数据作为一个单元同时读出或写入。一个标准的3.5寸硬盘盘面通常有几百到几千条磁道。磁道是“看”不见的,只是盘面上以特殊形式磁化了的一些磁化区,在磁盘格式化时就已规划完毕。
3. 柱面
所有盘面上的同一磁道构成一个圆柱,通常称做柱面(Cylinder),每个圆柱上的磁头由上而下从“0”开始编号。数据的读/写按柱面进行,即磁 头读/写数据时首先在同一柱面内从“0”磁头开始进行操作,依次向下在同一柱面的不同盘面即磁头上进行操作,只在同一柱面所有的磁头全部读/写完毕后磁头 才转移到下一柱面(同心圆的再往里的柱面),因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。电子切换相当快,比在机械上磁头向邻近磁道移动快得多,所以,数据的读/写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写,一个柱面写满后,才移到下一个扇区开始写数据。读数据也按照这种方式进行,这样就提高了硬盘的读/写效率。
一块硬盘驱动器的圆柱数(或每个盘面的磁道数)既取决于每条磁道的宽窄(同样,也与磁头的大小有关),也取决于定位机构所决定的磁道间步距的大小。
4.扇区
操作系统以扇区(Sector)形式将信息存储在硬盘上,每个扇区包括512个字节的数据和一些其他信息。一个扇区有两个主要部分:存储数据地点的标识符和存储数据的数据段。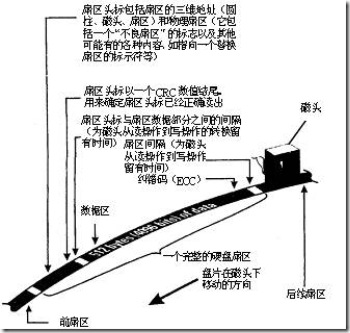
扇区的第一个主要部分是标识符。标识符,就是扇区头标,包括组成扇区三维地址的三个数字:
盘面号:扇区所在的磁头(或盘面)
柱面号:磁道,确定磁头的径向方向。
扇区号:在磁道上的位置。也叫块号。确定了数据在盘片圆圈上的位置。
头标中还包括一个字段,其中有显示扇区是否能可靠存储数据,或者是否已发现某个故障因而不宜使用的标记。有些硬盘控制器在扇区头标中还记录有指示字,可在原扇区出错时指引磁盘转到替换扇区或磁道。最后,扇区头标以循环冗余校验(CRC)值作为结束,以供控制器检验扇区头标的读出情况,确保准确无误。
扇区的第二个主要部分是存储数据的数据段,可分为数据和保护数据的纠错码(ECC)。在初始准备期间,计算机用512个虚拟信息字节(实际数据的存放地)和与这些虚拟信息字节相应的ECC数字填入这个部分。
5. 访盘请求完成过程 :
确定磁盘地址(柱面号,磁头号,扇区号),内存地址(源/目):
当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。
为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点:
1)首先必须找到柱面,即磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,
2)然后目标扇区旋转到磁头下,即磁盘旋转将目标扇区旋转到磁头下。这个过程耗费的时间叫做旋转时间。
即一次访盘请求(读/写)完成过程由三个动作组成:
1)寻道(时间):磁头移动定位到指定磁道
2)旋转延迟(时间):等待指定扇区从磁头下旋转经过
3)数据传输(时间):数据在磁盘与内存之间的实际传输
因此在磁盘上读取扇区数据(一块数据)所需时间:
Ti/o=tseek +tla + n *twm
其中:
tseek 为寻道时间
tla为旋转时间
twm 为传输时间
4、磁盘的读写原理
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。
(文件的记录在同一盘组上存放是,应先集中放在一个柱面上,然后再顺序存放在相邻的柱面上,对应同一柱面,则应该按盘面的次序顺序存放。)
(从上到下,然后从外到内。数据的读/写按柱面进行,而不按盘面进行,先)
系统也以相同的顺序读出数据。读出数据时通过告诉磁盘控制器要读出扇区所在的柱面号、磁头号和扇区号(物理地址的三个组成部分)进行。磁盘控制器则 直接使磁头部件步进到相应的柱面,选通相应的磁头,等待要求的扇区移动到磁头下。在扇区到来时,磁盘控制器读出每个扇区的头标,把这些头标中的地址信息与期待检出的磁头和柱面号做比较(即寻道),然后,寻找要求的扇区号。待磁盘控制器找到该扇区头标时,根据其任务是写扇区还是读扇区,来决定是转换写电路, 还是读出数据和尾部记录。找到扇区后,磁盘控制器必须在继续寻找下一个扇区之前对该扇区的信息进行后处理。如果是读数据,控制器计算此数据的ECC码,然 后,把ECC码与已记录的ECC码相比较。如果是写数据,控制器计算出此数据的ECC码,与数据一起存储。在控制器对此扇区中的数据进行必要处理期间,磁 盘继续旋转。
5、局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
6、磁盘碎片的产生
俗话说一图胜千言,先用一张ACSII码图来解释为什么会产生磁盘碎片。
上面的ASCII图表示磁盘文件系统,由于目前上面没有任何数据文件,所以我把他表示成0。
在图的最上侧和左侧各有a-z 26个字母,这是用来定位每个数据字节的具体位置,如第1行1列是aa,26行26列是zz。
我们创建一个新文件,理所当然的,我们的文件系统就产生了变化,现在是
如图所示:”内容表”(TOC)占据了前四行,在TOC里存贮着每件文件在系统里所在的位置。
在上图,TOC包括了一个名字叫hello.txt的文件,其具体内容是”Hello, world”,在系统里的位置是ae到le。
接下来再新建一个文件
如图,我们新建的文件bye.txt紧贴着第一个文件hello.txt。
其实这是最理想的系统结构,如果你将你的文件都按照上图所表示的那样一个挨着一个,紧紧的贴放在一起的话,那么读取他们将会非常的容易和迅速,这是因为在硬盘里动得最慢的(相对来说)就是传动手臂,少位移一些,读取文件数据的时间就会快一些。
然而恰恰这就是问题的所在。现在我想在”Hello, World”后加上些感叹号来表达我强烈的感情,现在的问题是:在这样的系统上,文件所在的行就没有地方让我放这些感叹号了,因为bye.txt占据了剩下的位置。
现在有俩个方法可以选择,但是没有一个是完美的
1.我们从原位置删除文件,重新建个文件重新写上”Hello, World!!”. –这就无意中延长了文件系统的读和写的时间。
2.打碎文件,就是在别的空的地方写上感叹号,也就是”身首异处”–这个点子不错,速度很快,而且方便,但是,这就同时意味着大大的减慢了读取下一个新文件的时间。
如果你对上面的文字没概念,上图
这里所说的方法二就像是我们的windows系统的存储方式,每个文件都是紧挨着的,但如果其中某个文件要更改的话,那么就意味着接下来的数据将会被放在磁盘其他的空余的地方。
如果这个文件被删除了,那么就会在系统中留下空格,久而久之,我们的文件系统就会变得支离破碎,碎片就是这么产生的。
试着简单点,讲给mm听的硬盘读写原理简化版 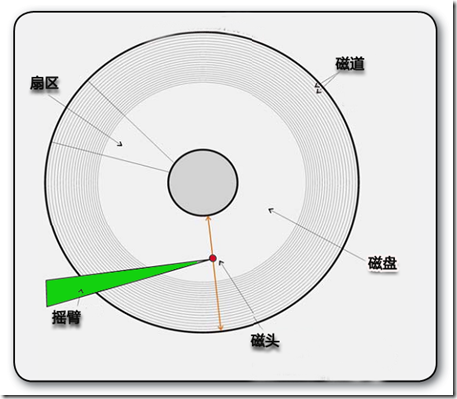
硬盘的结构就不多说了,我们平常电脑的数据都是存在磁道上的,大致上和光盘差不多.读取都是靠磁头来进行.
我们都知道,我们的数据资料都是以信息的方式存储在盘面的扇区的磁道上,硬盘读取是由摇臂控制磁头从盘面的外侧向内侧进行读写的.所以外侧的数据读取速度会比内侧的数据快很多.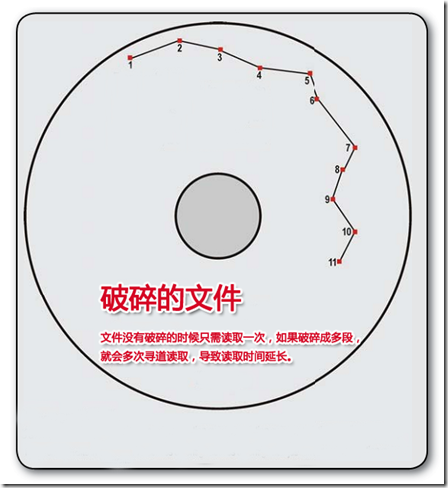
其实我们的文件大多数的时候都是破碎的,在文件没有破碎的时候,摇臂只需要寻找1次磁道并由磁头进行读取,只需要1次就可以成功读取;但是如果文件破碎成 11处,那么摇臂要来回寻找11次磁道磁头进行11次读取才能完整的读取这个文件,读取时间相对没有破碎的时候就变得冗长.
因此,磁盘碎片往往也是拖慢系统的重要因素之一,Vista之家团队也计划在Vista优化大师后续版本内加入磁盘碎片整理功能,敬请期待。
7、硬盘容量及分区大小的计算
在linux系统,要计算硬盘容量及分区大小,我们先通过fdsik -l查看硬盘信息:
Disk /dev/hda: 80.0 GB, 80026361856 bytes
255 heads, 63 sectors/track, 9729 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 765 6144831 7 HPFS/NTFS
/dev/hda2 766 2805 16386300 c W95 FAT32 (LBA)
/dev/hda3 2806 9729 55617030 5 Extended
/dev/hda5 2806 3825 8193118+ 83 linux
/dev/hda6 3826 5100 10241406 83 linux
/dev/hda7 5101 5198 787153+ 82 linux swap / Solaris
/dev/hda8 5199 6657 11719386 83 linux
/dev/hda9 6658 7751 8787523+ 83 linux
/dev/hda10 7752 9729 15888253+ 83 linux
其中
heads 是磁盘面;
sectors 是扇区;
cylinders 是柱面;
每个扇区大小是 512byte,也就是0.5K;
通过上面的例子,我们发现此硬盘有 255个磁盘面,有63个扇区,有9729个柱面;所以整个硬盘体积换算公式应该是:
磁面个数 * 扇区个数 * 每个扇区的大小512 * 柱面个数 = 硬盘体积 (单位bytes)
所以在本例中磁盘的大小应该计算如下:
255 x 63 x 512 x 9729 = 80023749120 bytes
提示:由于硬盘生产商和操作系统换算不太一样,硬盘厂家以10进位的办法来换算,而操作系统是以2进位制来换算,所以在换算成M或者G 时,不同的算法结果却不一样;所以我们的硬盘有时标出的是80G,在操作系统下看却少几M;
上面例子中,硬盘厂家算法 和 操作系统算数比较:
硬盘厂家: 80023749120 bytes = 80023749.120 K = 80023.749120 M (向大单位换算,每次除以1000)
操作系统: 80023749120 bytes = 78148192.5 K = 76316.594238281 M (向大单位换算,每次除以1024)
我们在查看分区大小的时候,可以用生产厂家提供的算法来简单推算分区的大小;把小数点向前移动六位就是以G表示的大小;比如 hda1 的大小约为 6.144831G ;


硬盘的存储原理和内部架构
硬盘主要由盘体、控制电路板和接口部件组成。盘体就是一个密封,封装了多个盘片的腔体;控制电路包含硬盘BIOS,主控芯片和硬盘缓存等单元;接口部件包含电源、数据接口主从跳线等。
硬盘的盘片一般采用合金材料,多数为铝合金(IBM曾经开发过玻璃材质的盘片,好像现在有些厂家也生产玻璃材质的盘片,但不多见),盘面上涂着磁性材料,厚度一般在0.5mm左右。有些硬盘只装一张盘片,有些则有多张。硬盘盘片安装在主轴电机的转轴上,在主轴电机的带动下作高速旋转。每张盘片的容量称为单碟容量,而一块硬盘的总容量就是所有盘片容量的总和。早期硬盘由于单碟容量低,所以盘片较多。现代的硬盘盘片一般只有少数几片。 盘片上的记录密度很大,而且盘片工作时会高速旋转,为保证其工作的稳定,数据保存的长久,所以硬片都是密封在硬盘内部。不可自行拆卸硬盘,在普通环境下空气中的灰尘、指纹、头发丝等细小杂质都会对硬盘造成永久损害。一个被大卸八块的硬盘如下:

接下来我们了解一下硬盘的盘面,柱面,磁道和扇区的概念。
盘面
硬盘一般会有一个或多个盘片,每个盘片可以有两个面(Side),即第1个盘片的正面称为0面,反面称为1面;第2个盘片的正面称为2面,反面称为3面...依次类推。每个盘面对应一个磁头(head)用于读写数据。第一个盘面的正面的磁头称为0磁头,背面称为1磁头;第二个盘片正面的磁头称为2磁头,背面称为3磁头,以此类推。盘面数和磁头数是相等的。
一张单面的盘片需要一个磁头,双面的盘片则需要两个磁头。硬盘采用高精度、轻型磁头驱动和定位系统。这种系统能使磁头在盘面上快速移动,读写硬盘时,磁头依靠磁盘的高速旋转引起的空气动力效应悬浮在盘面上,与盘面的距离不到1微米(约为头发直径的百分之一),可以在极短的时间内精确定位到计算机指令指定的磁道上。
早期由于定位系统限制,磁头传动臂只能在盘片的内外磁道之间移动。因此,不管开机还是关机,磁头总在盘片上。所不同的是,关机时磁头停留在盘片启停区,开机时磁头“飞行”在磁盘片上方。
磁道
每个盘片的每个盘面被划分成多个狭窄的同心圆环,数据就是存储在这样的同心圆环上,我们将这样的圆环称为磁道(Track),每个盘面可以划分多个磁道。关机时磁头停留在硬盘的着陆区(Landing Zone),这个着陆区以前是位于离盘心最近的区域,不存放任何数据。在后期的硬盘工艺中有些硬盘生产厂商将这个区域被移动到了盘片的外面,如下所示:
在每个盘面的最外圈,离盘心最远的地方是“0”磁道,向盘心方向依次增长为1磁道,2磁道,等等。硬盘数据的存放就是从最外圈开始。
扇区
根据硬盘规格的不同,磁道数可以从几百到成千上万不等。每个磁道上可以存储数KB的数据,但计算机并不需要一次读写这么多数据。在这一这基础上,又把每个磁道划分成若干弧段,每段称为一个扇区(Sector)。扇区是硬盘上存储的物理单位,每个扇区可存储128×2N次方(N=0,1,2,3)字节的数据。从DOS时代起,每扇区是128×22=512字节,现在已经成了业界不成文的规定,也没有哪个硬盘厂商试图去改变这种约定。也就是说即使计算机只需要硬盘上存储的某个字节,也须一次把这个字节所在的扇区中的全部512字节读入内存,再选择所需的那个字节。扇区的编号是从1开始,而不是0,这一点需要注意。另外,硬盘在划分扇区时,和软盘是有一定区别的。软盘的一个磁道中,扇区号一般依次编排,如1号,2号,3号...以此类推。但在硬盘磁道中,扇区号是按照某个间隔跳跃着编排。比如,2号扇区并不是1号扇区后的按顺序的第一个而是第八个,3号扇区又是2号扇区后的按顺序的第八个,依此类推,这个“八”称为交叉因子。
这个交叉因子的来历有必要详述一下,我们知道,数据读取经常需要按顺序读取一系列相邻的扇区(逻辑数据相邻)。如对磁道扇区按物理顺序进行编号,很有可能出现当磁头读取完第一个扇区后,由于盘片转速过快来不及读取下一个扇区,(要知道物理相邻扇区位置距离是极小的),必须等待转完一圈,这极大浪费了时间。所以就用交叉来解决这个问题。增加了交叉因子后的扇区编号一般是下面这个样子:
柱面
柱面其实是我们抽象出来的一个逻辑概念,前面说过,离盘心最远的磁道为0磁道,依此往里为1磁道,2磁道,3磁道....,不同面上相同磁道编号则组成了一个圆柱面,即所称的柱面(Cylinder)。这里要注意,硬盘数据的读写是按柱面进行,即磁头读写数据时首先在同一柱面内从0磁头开始进行操作,依次向下在同一柱面的不同盘面(即磁头上)进行操作,只有在同一柱面所有的磁头全部读写完毕后磁头才转移到下一柱面,因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。电子切换比从在机械上磁头向邻近磁道移动快得多。因此,数据的读写按柱面进行,而不按盘面进行。 读写数据都是按照这种方式进行,尽可能提高了硬盘读写效率。
簇
将物理相邻的若干个扇区称为了一个簇。操作系统读写磁盘的基本单位是扇区,而文件系统的基本单位是簇(Cluster)。在Windows下,随便找个几字节的文件,在其上面点击鼠标右键选择属性,看看实际大小与占用空间两项内容,如大小:15 字节 (15 字节), 占用空间:4.00 KB (4,096 字节)。这里的占用空间就是你机器分区的簇大小,因为再小的文件都会占用空间,逻辑基本单位是4K,所以都会占用4K。 簇一般有这几类大小 4K,8K,16K,32K,64K等。簇越大存储性能越好,但空间浪费严重。簇越小性能相对越低,但空间利用率高。NTFS格式的文件系统簇的大小为4K。
硬盘读写数据的过程
现代硬盘寻道都是采用CHS(Cylinder Head Sector)的方式,硬盘读取数据时,读写磁头沿径向移动,移到要读取的扇区所在磁道的上方,这段时间称为寻道时间(seek time)。因读写磁头的起始位置与目标位置之间的距离不同,寻道时间也不同。目前硬盘一般为2到30毫秒,平均约为9毫秒。磁头到达指定磁道后,然后通过盘片的旋转,使得要读取的扇区转到读写磁头的下方,这段时间称为旋转延迟时间(rotational latencytime)。
一个7200(转/每分钟)的硬盘,每旋转一周所需时间为60×1000÷7200=8.33毫秒,则平均旋转延迟时间为8.33÷2=4.17毫秒(平均情况下,需要旋转半圈)。平均寻道时间和平均选装延迟称为平均存取时间。
所以,最后看一下硬盘的容量计算公式:
硬盘容量=盘面数×柱面数×扇区数×512字节
在博文“Linux启动过程分析”中我们提到过MBR,它是存在于硬盘的0柱面,0磁头,1扇区里,占512字节的空间。这512字节里包含了主引导程序Bootloader和磁盘分区表DPT。其中Bootloader占446字节,分区表占64字节,一个分区要占用16字节,64字节的分区表只能被划分4个分区,这也就是目前我们的硬盘最多只能支持4个分区记录的原因。

即,如果你将硬盘分成4个主分区的话,必须确保所有的磁盘空间都被使用了(这不是废话么),一般情况下我们都是划分一个主分区加一个扩展分区,然后在扩展分区里再继续划分逻辑分区。当然,逻辑分区表也需要分区表,它是存在于扩展分区的第一个扇区里,所以逻辑分区的个数最多也只能有512/16=32个,并不是想分多少个逻辑分区都可以。
注意,我们所说的扩展分区也是要占用分区表项的。例如,如果我们的硬盘只划分一个主分区和一个逻辑分区,此时的分区表的排列如下:
Device Boot Start End Blocks Id System
/dev/sda1 * 1 19 152586 83 Linux
/dev/sda2 20 2569 20482875 83 Extended
/dev/sda5 2570 19457 4128705 82 Linux
2.1 磁碟连接的方式与装置档名的关系
2.2 磁碟的组成复习
2.3 磁盘分区表(partition table)
2.4 启动流程与主要启动记录区(MBR)
2.5 Linux安装模式下,磁盘分区的选择(极重要)
这一章在规划的重点是为了要安装Linux,那Linux系统是安装在计算机组件的那个部分呢?就是磁碟啦!所以我们当然要来认识一下磁碟先。 我们知道一块磁碟是可以被分割成多个分割槽的(partition),以旧有的Windows观点来看,你可能会有一颗磁碟并且将他分割成为C:, D:, E:槽对吧!那个C, D, E就是分割槽(partition)罗。但是Linux的装置都是以文件的型态存在,那分割槽的档名又是什么? 如何进行磁盘分区,磁盘分区有哪些限制?是我们这个小节所要探讨的内容罗。
由第零章提到的磁碟说明,我们知道个人计算机常见的磁碟介面有两种, 分别是IDE与SATA介面,目前(2009)的主流已经是SATA介面了,但是老一点的主机其实大部分还是使用IDE介面。 我们称呼可连接到IDE介面的装置为IDE装置,不管是磁碟还是光盘设备。
以IDE介面来说,由於一个IDE排线可以连接两个IDE装置,又通常主机都会提供两个IDE介面,因此最多可以接到四个IDE装置。 也就是说,如果你已经有一个光盘设备了,那么最多就只能再接三颗IDE介面的磁碟罗。 这两个IDE介面通常被称为IDE1(primary)及IDE2(secondary), 而每条排线上面的IDE装置可以被区分为Master与Slave。这四个IDE装置的档名为:
IDE\JumperMasterSlaveIDE1(Primary)/dev/hda/dev/hdbIDE2(Secondary)/dev/hdc/dev/hdd例题:
再以SATA介面来说,由於SATA/U盘/SCSI等磁碟介面都是使用SCSI模块来驱动的, 因此这些介面的磁碟装置档名都是/dev/sd[a-p]的格式。 但是与IDE介面不同的是,SATA/U盘介面的磁碟根本就没有一定的顺序,那如何决定他的装置档名呢? 这个时候就得要根据Linux核心侦测到磁碟的顺序了!这里以底下的例子来让你了解罗。
例题:- SATA1插槽上的档名:/dev/sda
- SATA5插槽上的档名:/dev/sdb
- U盘磁碟(启动完成后才被系统捉到):/dev/sdc
通过上面的介绍后,你应该知道了在Linux系统下的各种不同介面的磁碟的装置档名了。 OK!好像没问题了呦!才不是呢~问题很大呦! 因为如果你的磁碟被分割成两个分割槽,那么每个分割槽的装置档名又是什么?在了解这个问题之前,我们先来复习一下磁碟的组成, 因为现今磁碟的分割与他物理的组成很有关系!
我们在计算机概论谈过磁碟的组成主要有磁碟盘、机械手臂、磁碟读取头与主轴马达所组成, 而数据的写入其实是在磁碟盘上面。磁碟盘上面又可细分出磁区(Sector)与磁柱(Cylinder)两种单位, 其中磁区每个为512bytes那么大。假设磁碟只有一个磁碟盘,那么磁碟盘有点像底下这样:

图2.2.1、磁碟盘组成示意图
那么是否每个磁区都一样重要呢?其实整颗磁碟的第一个磁区特别的重要,因为他记录了整颗磁碟的重要资讯! 磁碟的第一个磁区主要记录了两个重要的资讯,分别是:
- 主要启动记录区(Master Boot Record, MBR):可以安装启动管理程序的地方,有446 bytes
- 分割表(partition table):记录整颗硬盘分割的状态,有64 bytes
MBR是很重要的,因为当系统在启动的时候会主动去读取这个区块的内容,这样系统才会知道你的程序放在哪里且该如何进行启动。 如果你要安装多重启动的系统,MBR这个区块的管理就非常非常的重要了! ^_^
那么分割表又是啥?其实你刚刚拿到的整颗硬盘就像一根原木,你必须要在这根原木上面切割出你想要的区段, 这个区段才能够再制作成为你想要的家具!如果没有进行切割,那么原木就不能被有效的使用。 同样的道理,你必须要针对你的硬盘进行分割,这样硬盘才可以被你使用的!
更多的磁盘分区与文件系统管理,我们将在第二篇的时候深入介绍喔!

但是硬盘总不能真的拿锯子来切切割割吧?那硬盘还真的是会坏掉去!那怎办?在前一小节的图示中, 我们有看到『开始与结束磁柱』吧?那是文件系统的最小单位,也就是分割槽的最小单位啦!没有错, 我们就是利用参考对照磁柱号码的方式来处理啦! 在分割表所在的64 bytes容量中,总共分为四组记录区,每组记录区记录了该区段的启始与结束的磁柱号码。 若将硬盘以长条形来看,然后将磁柱以直条图来看,那么那64 bytes的记录区段有点像底下的图示:

图2.3.1、磁盘分区表的作用示意图
假设上面的硬盘装置档名为/dev/hda时,那么这四个分割槽在Linux系统中的装置档名如下所示, 重点在於档名后面会再接一个数字,这个数字与该分割槽所在的位置有关喔!
- P1:/dev/hda1
- P2:/dev/hda2
- P3:/dev/hda3
- P4:/dev/hda4
上图中我们假设硬盘只有400个磁柱,共分割成为四个分割槽,第四个分割槽所在为第301到400号磁柱的范围。 当你的操作系统为Windows时,那么第一到第四个分割槽的代号应该就是C, D, E, F。当你有数据要写入F槽时, 你的数据会被写入这颗磁碟的301~400号磁柱之间的意思。
由於分割表就只有64 bytes而已,最多只能容纳四笔分割的记录, 这四个分割的记录被称为主要(Primary)或延伸(Extended)分割槽。 根据上面的图示与说明,我们可以得到几个重点资讯:
- 其实所谓的『分割』只是针对那个64 bytes的分割表进行配置而已!
- 硬盘默认的分割表仅能写入四组分割资讯
- 这四组分割资讯我们称为主要(Primary)或延伸(Extended)分割槽
- 分割槽的最小单位为磁柱(cylinder)
- 当系统要写入磁碟时,一定会参考磁盘分区表,才能针对某个分割槽进行数据的处理
咦!你会不会突然想到,为啥要分割啊?基本上你可以这样思考分割的角度:
- 数据的安全性:
因为每个分割槽的数据是分开的!所以,当你需要将某个分割槽的数据重整时,例如你要将计算机中Windows的C槽重新安装一次系统时, 可以将其他重要数据移动到其他分割槽,例如将邮件、壁纸数据移动到D槽去,那么C槽重灌系统并不会影响到D槽! 所以善用分割槽,可以让你的数据更安全。 - 系统的效能考量:
由於分割槽将数据集中在某个磁柱的区段,例如上图当中第一个分割槽位於磁柱号码1~100号,如此一来当有数据要读取自该分割槽时, 磁碟只会搜寻前面1~100的磁柱范围,由於数据集中了,将有助於数据读取的速度与效能!所以说,分割是很重要的!
既然分割表只有记录四组数据的空间,那么是否代表我一颗硬盘最多只能分割出四个分割槽?当然不是啦!有经验的朋友都知道, 你可以将一颗硬盘分割成十个以上的分割槽的!那又是如何达到的呢?在Windows/Linux系统中, 我们是透过刚刚谈到的扩展分配(Extended)的方式来处理的啦!扩展分配的想法是: 既然第一个磁区所在的分割表只能记录四笔数据, 那我可否利用额外的磁区来记录更多的分割资讯?实际上图示有点像底下这样:

图2.3.2、磁盘分区表的作用示意图
在上图当中,我们知道硬盘的四个分割记录区仅使用到两个,P1为主要分割,而P2则为扩展分配。请注意, 扩展分配的目的是使用额外的磁区来记录分割资讯,扩展分配本身并不能被拿来格式化。 然后我们可以透过扩展分配所指向的那个区块继续作分割的记录。
如上图右下方那个区块有继续分割出五个分割槽, 这五个由扩展分配继续切出来的分割槽,就被称为逻辑分割槽(logical partition)。 同时注意一下,由於逻辑分割槽是由扩展分配继续分割出来的,所以他可以使用的磁柱范围就是扩展分配所配置的范围喔! 也就是图中的101~400啦!
同样的,上述的分割槽在Linux系统中的装置档名分别如下:
- P1:/dev/hda1
- P2:/dev/hda2
- L1:/dev/hda5
- L2:/dev/hda6
- L3:/dev/hda7
- L4:/dev/hda8
- L5:/dev/hda9
仔细看看,怎么装置档名没有/dev/hda3与/dev/hda4呢?因为前面四个号码都是保留给Primary或Extended用的嘛! 所以逻辑分割槽的装置名称号码就由5号开始了!这是个很重要的特性,不能忘记喔!
主要分割、扩展分配与逻辑分割的特性我们作个简单的定义罗:
- 主要分割与扩展分配最多可以有四笔(硬盘的限制)
- 扩展分配最多只能有一个(操作系统的限制)
- 逻辑分割是由扩展分配持续切割出来的分割槽;
- 能够被格式化后,作为数据存取的分割槽为主要分割与逻辑分割。扩展分配无法格式化;
- 逻辑分割的数量依操作系统而不同,在Linux系统中,IDE硬盘最多有59个逻辑分割(5号到63号), SATA硬盘则有11个逻辑分割(5号到15号)。
事实上,分割是个很麻烦的东西,因为他是以磁柱为单位的『连续』磁碟空间, 且扩展分配又是个类似独立的磁碟空间,所以在分割的时候得要特别注意。我们举底下的例子来解释一下好了:
例题:
图2.3.3、磁碟空间整合示意图
- 上图可以整合:因为上图的D与E同属於扩展分配内的逻辑分割,因此只要将两个分割槽删除,然后再重新创建一个新的分割槽, 就能够在不影响其他分割槽的情况下,将两个分割槽的容量整合成为一个。
- 下图不可整合:因为D与E分属主分割与逻辑分割,两者不能够整合在一起。除非将扩展分配破坏掉后再重新分割。 但如此一来会影响到所有的逻辑分割槽,要注意的是:如果扩展分配被破坏,所有逻辑分割将会被删除。 因为逻辑分割的资讯都记录在扩展分配里面嘛!
由於第一个磁区所记录的分割表与MBR是这么的重要,几乎只要读取硬盘都会先由这个磁区先读起。 因此,如果整颗硬盘的第一个磁区(就是MBR与partition table所在的磁区)物理实体坏掉了,那这个硬盘大概就没有用了! 因为系统如果找不到分割表,怎么知道如何读取磁柱区间呢?您说是吧!底下还有一些例题您可以思考看看:
例题:- 由於Primary+Extended最多只能有四个,其中Extended最多只能有一个,这个例题想要分割出四个分割槽且还要预留剩余容量, 因此P+P+P+P的分割方式是不适合的。因为如果使用到四个P,则即使硬盘还有剩余容量, 因为无法再继续分割,所以剩余容量就被浪费掉了。
- 假设你想要将所有的四笔记录都花光,那么P+P+P+E是比较适合的。所以可以用的四个partitions有3个主要及一个逻辑分割, 剩余的容量在扩展分配中。
- 如果你要分割超过4槽以上时,一定要有Extended分割槽,而且必须将所有剩下的空间都分配给Extended, 然后再以logical的分割来规划Extended的空间。 另外,考虑到磁碟的连续性,一般建议将Extended的磁柱号码分配在最后面的磁柱内。
例题:
例题:
- P+P+P+E的环境:

图2.3.4、分割示意图 - P+E的环境:

图2.3.5、分割示意图
我们在计算机概论里面谈到了,没有运行软件的硬件是没有用的,除了会电人之外..., 而为了计算机硬件系统的资源合理分配,因此有了操作系统这个系统软件的产生。由於操作系统会控制所有的硬件并且提供核心功能, 因此我们的计算机就能够认识硬盘内的文件系统,并且进一步的读取硬盘内的软件文件与运行该软件来达成各项软件的运行目的。
问题是,你有没有发现,既然操作系统也是软件,那么我的计算机又是如何认识这个操作系统软件并且运行他的? 明明启动时我的计算机还没有任何软件系统,那他要如何读取硬盘内的操作系统文件啊?嘿嘿!这就得要牵涉到计算机的启动程序了! 底下就让我们来谈一谈这个启动程序吧!
在计算机概论里面我们有谈到那个可爱的BIOS与CMOS两个东西, CMOS是记录各项硬件参数且嵌入在主板上面的储存器,BIOS则是一个写入到主板上的一个韧体(再次说明, 韧体就是写入到硬件上的一个软件程序)。这个BIOS就是在启动的时候,计算机系统会主动运行的第一个程序了!
接下来BIOS会去分析计算机里面有哪些储存设备,我们以硬盘为例,BIOS会依据使用者的配置去取得能够启动的硬盘, 并且到该硬盘里面去读取第一个磁区的MBR位置。 MBR这个仅有446 bytes的硬盘容量里面会放置最基本的启动管理程序, 此时BIOS就功成圆满,而接下来就是MBR内的启动管理程序的工作了。
这个启动管理程序的目的是在加载(load)核心文件, 由於启动管理程序是操作系统在安装的时候所提供的,所以他会认识硬盘内的文件系统格式,因此就能够读取核心文件, 然后接下来就是核心文件的工作,启动管理程序也功成圆满,之后就是大家所知道的操作系统的任务啦!
简单的说,整个启动流程到操作系统之前的动作应该是这样的:
- BIOS:启动主动运行的韧体,会认识第一个可启动的装置;
- MBR:第一个可启动装置的第一个磁区内的主要启动记录区块,内含启动管理程序;
- 启动管理程序(boot loader):一支可读取核心文件来运行的软件;
- 核心文件:开始操作系统的功能...
由上面的说明我们会知道,BIOS与MBR都是硬件本身会支持的功能,至於Boot loader则是操作系统安装在MBR上面的一套软件了。由於MBR仅有446 bytes而已,因此这个启动管理程序是非常小而美的。 这个boot loader的主要任务有底下这些项目:
- 提供菜单:使用者可以选择不同的启动项目,这也是多重启动的重要功能!
- 加载核心文件:直接指向可启动的程序区段来开始操作系统;
- 转交其他loader:将启动管理功能转交给其他loader负责。
上面前两点还容易理解,但是第三点很有趣喔!那表示你的计算机系统里面可能具有两个以上的启动管理程序呢! 有可能吗?我们的硬盘不是只有一个MBR而已?是没错啦!但是启动管理程序除了可以安装在MBR之外, 还可以安装在每个分割槽的启动磁区(boot sector)喔!瞎密?分割槽还有各别的启动磁区喔? 没错啊!这个特色才能造就『多重启动』的功能啊!
我们举一个例子来说,假设你的个人计算机只有一个硬盘,里面切成四个分割槽,其中第一、二分割槽分别安装了Windows及Linux, 你要如何在启动的时候选择用Windows还是Linux启动呢?假设MBR内安装的是可同时认识Windows/Linux操作系统的启动管理程序, 那么整个流程可以图示如下:

图2.4.1、启动管理程序的工作运行示意图
在上图中我们可以发现,MBR的启动管理程序提供两个菜单,菜单一(M1)可以直接加载Windows的核心文件来启动; 菜单二(M2)则是将启动管理工作交给第二个分割槽的启动磁区(boot sector)。当使用者在启动的时候选择菜单二时, 那么整个启动管理工作就会交给第二分割槽的启动管理程序了。 当第二个启动管理程序启动后,该启动管理程序内(上图中)仅有一个启动菜单,因此就能够使用Linux的核心文件来启动罗。 这就是多重启动的工作情况啦!我们将上图作个总结:
- 每个分割槽都拥有自己的启动磁区(boot sector)
- 图中的系统槽为第一及第二分割槽,
- 实际可启动的核心文件是放置到各分割槽内的!
- loader只会认识自己的系统槽内的可启动核心文件,以及其他loader而已;
- loader可直接指向或者是间接将管理权转交给另一个管理程序。
那现在请你想一想,为什么人家常常说:『如果要安装多重启动, 最好先安装Windows再安装Linux』呢?这是因为:
- Linux在安装的时候,你可以选择将启动管理程序安装在MBR或各别分割槽的启动磁区, 而且Linux的loader可以手动配置菜单(就是上图的M1, M2...),所以你可以在Linux的boot loader里面加入Windows启动的选项;
- Windows在安装的时候,他的安装程序会主动的覆盖掉MBR以及自己所在分割槽的启动磁区,你没有选择的机会, 而且他没有让我们自己选择菜单的功能。
因此,如果先安装Linux再安装Windows的话,那MBR的启动管理程序就只会有Windows的项目,而不会有Linux的项目 (因为原本在MBR内的Linux的启动管理程序就会被覆盖掉)。 那需要重新安装Linux一次吗?当然不需要,你只要用尽各种方法来处理MBR的内容即可。 例如利用全中文的spfdisk(http://spfdisk.sourceforge.net/)软件来安装认识Windows/Linux的管理程序, 也能够利用Linux的救援模式来挽救MBR即可。
启动管理程序与Boot sector的观念是非常重要的,我们会在第二十章分别介绍,您在这里只要先对於(1)启动需要启动管理程序, 而(2)启动管理程序可以安装在MBR及Boot Sector两处这两个观念有基本的认识即可, 一开始就背太多东西会很混乱啦!
- 目录树结构(directory tree)
我们前面有谈过Linux内的所有数据都是以文件的形态来呈现的,所以罗,整个Linux系统最重要的地方就是在於目录树架构。 所谓的目录树架构(directory tree)就是以根目录为主,然后向下呈现分支状的目录结构的一种文件架构。 所以,整个目录树架构最重要的就是那个根目录(root directory),这个根目录的表示方法为一条斜线『/』, 所有的文件都与目录树有关。目录树的呈现方式如下图所示:

图2.5.1、目录树相关性示意图
如上图所示,所有的文件都是由根目录(/)衍生来的,而次目录之下还能够有其他的数据存在。上图中长方形为目录, 波浪形则为文件。那当我们想要取得mydata那个文件时,系统就得由根目录开始找,然后找到home接下来找到dmtsai, 最终的档名为:/home/dmtsai/mydata的意思。
我们现在知道整个Linux系统使用的是目录树架构,但是我们的文件数据其实是放置在磁盘分区槽当中的, 现在的问题是『如何结合目录树的架构与磁碟内的数据』呢? 这个时候就牵扯到『挂载(mount)』的问题啦!
- 文件系统与目录树的关系(挂载)
所谓的『挂载』就是利用一个目录当成进入点,将磁盘分区槽的数据放置在该目录下; 也就是说,进入该目录就可以读取该分割槽的意思。这个动作我们称为『挂载』,那个进入点的目录我们称为『挂载点』。 由於整个Linux系统最重要的是根目录,因此根目录一定需要挂载到某个分割槽的。 至於其他的目录则可依使用者自己的需求来给予挂载到不同的分割槽。我们以下图来作为一个说明:

图2.5.2、目录树与分割槽之间的相关性
上图中假设我的硬盘分为两槽,partition 1是挂载到根目录,至於partition 2则是挂载到/home这个目录。 这也就是说,当我的数据放置在/home内的各次目录时,数据是放置到partition 2的,如果不是放在/home底下的目录, 那么数据就会被放置到partition 1了!
其实判断某个文件在那个partition底下是很简单的,透过反向追踪即可。以上图来说, 当我想要知道/home/vbird/test这个文件在那个partition时,由test --> vbird --> home --> /,看那个『进入点』先被查到那就是使用的进入点了。 所以test使用的是/home这个进入点而不是/喔!
例题:- Windows: 壁纸\我的计算机\E:\我的文件
- Linux: /media/cdrom/我的文件
- /mnt/我的文件
- distributions安装时,挂载点与磁盘分区的规划:
既然我们在Linux系统下使用的是目录树系统,所以安装的时候自然就得要规划磁盘分区与目录树的挂载了。 实际上,在Linux安装的时候已经提供了相当多的默认模式让你选择分割的方式了, 不过,无论如何,分割的结果可能都不是很能符合自己主机的样子!因为毕竟每个人的『想法』都不太一样! 因此,强烈建议使用『自订安装, Custom 』这个安装模式!在某些Linux distribution中,会将这个模式写的很厉害,叫做是『Expert, 专家模式』,这个就厉害了, 请相信您自己,了解上面的说明后,就请自称为专家了吧!没有问题!
- 自订安装『Custom』:
- A:初次接触Linux:只要分割『 / 』及『swap』即可:
通常初次安装Linux系统的朋友们,我们都会建议他直接以一个最大的分割槽『 / 』来安装系统。 这样作有个好处,就是不怕分割错误造成无法安装的困境!例如/usr是Linux的可运行程序及相关的文件摆放的目录, 所以他的容量需求蛮大的,万一你分割了一块分割槽给/usr,但是却给的不够大,那么就伤脑筋了! 因为会造成无法将数据完全写入的问题,就有可能会无法安装啦!因此如果你是初次安装的话, 那么可以仅分割成两个分割槽『 / 与 Swap 』即可。
- B:建议分割的方法:预留一个备用的剩余磁碟容量!
在想要学习Linux的朋友中,最麻烦的可能就是得要常常处理分割的问题,因为分割是系统管理员很重要的一个任务。 但如果你将整个硬盘的容量都用光了,那么你要如何练习分割呢?^_^。所以鸟哥在后续的练习中也会这样做, 就是请你特别预留一块不分割的磁碟容量,作为后续练习时可以用来分割之用!
此外,预留的分割槽也可以拿来做为备份之用。因为我们在实际操作Linux系统的过程中, 可能会发现某些script或者是重要的文件很值得备份时,就可以使用这个剩余的容量分割出新的分割槽, 并使用来备份重要的配置档或者是script。这有个最大的好处, 就是当我的Linux重新安装的时候,我的一些软件或工具程序马上就可以直接在硬盘当中找到!呵呵!重新安装比较便利啦。 为什么要重新安装?因为没有安装过Linux十次以上,不要说你学会了Linux了啦!慢慢体会这句话吧! ^_^
- 选择Linux安装程序提供的默认硬盘分割方式:
对於首次接触Linux的朋友们,鸟哥通常不建议使用各个distribution所提供默认的Server安装方式, 因为会让你无法得知Linux在搞什么鬼,而且也不见得可以符合你的需求!而且要注意的是, 选择Server的时候,请『确定』你的硬盘数据是不再需要!因为Linux会自动的把你的硬盘里面旧有的数据全部杀掉! 此外,硬盘至少需要2 GB以上才可以选择这一个模式!
现在你知道Linux为什么不好学了吧?因为很多基础知识都得要先了解!否则连安装都不知道怎么安装~ 现在你知道Linux的可爱了吧!因为如果你学会了,嘿嘿!很多计算机系统/操作系统的概念都很清晰, 转换到不同的资讯跑道是比较容易的喔!^_^
2.1 调整开机媒体(BIOS)
2.2 选择安装模式与开机, 测试内存稳定度
2.3 选择语系数据
2.4 磁碟分割, 进阶软件阵列建置
2.5 开机管理程序、网络、时区设定与root密码
2.6 软件选择
2.7 其他功能:RAM testing, 安装笔记本电脑的核心参数(Option)
由於本章的内容主要是针对安装一部Linux练习机来设定的,所以安装的分割等过程较为简单。 如果你已经不是第一次接触Linux,并且想要架设一部要上线的Linux主机,请务必前往第三章看一下整体规划的想法喔! 在本章中,你只要依照前一小节的检查表单检查你所需要的安装媒体/硬件/软件资讯等等, 然后就能够安装啦!
安装的步骤在各主要Linux distributions都差不多,主要的内容大概是:
- 调整开机媒体(BIOS):务必要使用CD或DVD光盘开机,通常需要调整BIOS;
- 选择安装模式与开机:包括图形介面/文字介面等,也可加入特殊参数来开机进入安装画面;
- 选择语系数据:由於不同地区的键盘按键不同,此时需要调整语系/键盘/滑鼠等配备;
- 磁碟分割:最重要的项目之一了!记得将刚刚的规划单拿出来设定;
- 开机管理程序、网络、时区设定与root密码:一些需要的系统基础设定!
- 软件选择:需要什么样的软件?全部安装还是预设安装即可?
- 安装后的首次设定:安装完毕后还有一些事项要处理,包括使用者、SELinux与防火墙等!
你不能在Windows的环境下安装Linux的,你必须要使用Linux的安装光盘开机后才能够进行Linux的安装流程。 目前几乎所有的Linux distributions以及主板都有支援光盘开机,所以以往使用软盘开机的安装方式我们就不再介绍了。
那如何让你的主机可以用光盘开机呢?由前一章的开机流程我们知道开机的装置是由BIOS调整的, 所以要让光盘可以开机,当然就得要进入BIOS调整开机装置的顺序了。不过,各家主板使用的BIOS程序不一样, 而且进入BIOS的按键也不相同,因此这部份得要参考你的主板说明书才好。鸟哥这里使用的是我的测试机来解释喔。
- 开机进入BIOS的按键
将你的PC重新开机,在开机的画面中按下[del]按键,以进入BIOS画面,如下图的箭头所示:![按[Del]进入BIOS画面示意图](http://cn.linux.vbird.org/linux_basic/0157installcentos5_files/centos5_01_01.jpg "按[Del]进入BIOS画面示意图")
图2.1.1、按[Del]进入BIOS画面示意图 - 进入BIOS操作介面
然后会出现如下的图示,显示出目前你的BIOS主要架构:
图2.1.2、BIOS画面示意图
上图画面中最上方为主选单部分,计有『Main, Advanced, Power, Boot, Exit』等项目。我们有兴趣的地方在『Boot』中。 上图最下方则是一些BIOS操作说明,包括使用上、下、左、右等按键以及[Enter]按键等。 此时,请按照BIOS的操作说明,利用向右的方向键将选单移动到『Boot』项目 - 开机装置的顺序调整
进入到Boot的画面后,你就可以使用[+][-]按键来调整开机顺序。以鸟哥的环境来说,我就调整开机装置为光盘啦! 如下图所示:
图2.1.3、BIOS内的开机顺序选单 - 储存后离开
接下来,只要输入[F10]然后按下[Enter]就能够储存刚刚的设定,系统会自动重新开机,就能够使用光驱里面的光盘来开机了。 就是这么简单啊!
另外一款常见的BIOS画面中,会有一个『BIOS Features Setup』之类字眼的选项,进入该选项后找到『Boot Sequence』 或者是『First Boot Device』之类的字样,并选择CD-ROM开机为第一优先即可。 通常鸟哥都是用CD-ROM为第一项,然后是硬盘(HD-0)。

在调整完BIOS内的开机装置的顺序后,理论上你的主机已经可使用可开机光盘来开机了! 如果发生一些错误讯息导致无法以CentOS 5.x DVD来开机,很可能是由於:1)计算机硬件不支援; 2)光驱会挑片; 3)光盘片有问题; 如果是这样,那么建议你再仔细的确认一下你的硬件是否有超频?或者其他不正常的现象。 另外,你的光盘来源也需要再次的确认!
在进行完上面的步骤之后,请放入我们的CentOS 5.x i386的DVD进入光驱中,重新开机准备进入安装画面吧!
由於为了画面撷取的解析度,鸟哥使用Virtualbox(注1)这套软件来捉图给大家看。 所以如果有看到与上面练习机的规划的资讯不同时,请大家多多包涵啊!好了, 如果一切都没问题,那么使用DVD开机后,你应该会看到萤幕出现如下的画面了:
![安装程序的安装模式选择画面,预设的[F1]画面](http://cn.linux.vbird.org/linux_basic/0157installcentos5_files/centos5_02_01.jpg "安装程序的安装模式选择画面,预设的[F1]画面")
图2.2.1、安装程序的安装模式选择画面,预设的[F1]画面
上面的画面中说明了:
- 你可以直接按下<Enter>来进入图形介面的安装方式;
- 也可以直接在boot:(上图箭头4所指处)后面输入『linux text』来进入文字介面的安装;
- 还有其他功能选单,可按下键盘最上方那一列的[F1]...[F5]按键来查阅各功能。
要特别注意的是,如果你在 10 秒钟内没有按下任何按键的话,那么安装程序预设会使用图形介面来开始安装流程喔! 由於目前安装程序都作的非常棒!因此,建议你可以使用图形介面来安装即可。鸟哥底下就是使用图形介面来安装的。 如果想要知道安装程序还提供什么功能,我们可以按下功能键。例如底下就是[F2]的功能说明:
![安装程序的安装模式选择画面,[F2]的画面](http://cn.linux.vbird.org/linux_basic/0157installcentos5_files/centos5_02_02.jpg "安装程序的安装模式选择画面,[F2]的画面")
图2.2.2、安装程序的安装模式选择画面,[F2]的画面
上图中箭头指的地方需要留意一点点,那个是还算常用的功能!意义是这样的:
- linux noprobe (1号箭头):
不进行硬件的侦测,如果你有特殊硬件时,或许可以使用这一项来停止硬件侦测; - linux askmethod (2号箭头):
进入互动模式,安装程序会进行一些询问。如果你的硬盘内含有安装媒体时, 或者是你的环境内有安装服务器(Installation server),那就可以选这一项来填入正确的网络主机来安装; - memtest86 (3号箭头):
这个有趣了!这个项目会一直进行内存的读写,如果你怀疑你的内存稳定度不足的话, 可以使用这个项目来测试你的内存喔!测试完成后需要重新开机!
那如果按下的是[F5]时,就会进入到救援模式的说明画面,如下图所示:
![安装程序的安装模式选择画面,[F5]的救援模式说明画面](http://cn.linux.vbird.org/linux_basic/0157installcentos5_files/centos5_02_03.jpg "安装程序的安装模式选择画面,[F5]的救援模式说明画面")
图2.2.3、安装程序的安装模式选择画面,[F5]的救援模式说明画面
上图的意思是说,如果你的Linux系统因为设定错误导致无法开机时,可以使用『linux rescue』来进入救援模式。这个救援模式很有帮助喔! 在我们后面各章节的练习中有很多练习是需要更动到系统设定档的,万一你设定错误将可能会导致无法开机。 此时请拿出此片DVD来进行救援模式,能够救回你的Linux而不需要重新安装呢!
因为我们是首次安装Linux嘛!所以就请直接按下<Enter>按键,此时安装程序会开始去侦测硬件, 侦测的结果会回报到你的萤幕上,如下所示:

图2.2.4、安装程序的核心进行硬件侦测流程示意图
如果侦测过程中没有问题,那么就会出现要你选择是否要进行储存媒体的检验画面,如下所示:

图2.2.5、是否进行安装媒体的检测示意图
如果你确定你所下载的DVD或光盘没有问题的话,那么这里可以选择『Skip(忽略)』, 不过,你也可以按下『OK』来进行DVD的分析,因为通过DVD的分析后,后续的安装比较不会出现奇怪的问题。 不过如果你按下『OK』后,程序会开始分析光盘内的所有档案的资讯,会花非常多的时间喔!如下所示:

图2.2.6、是否真的要测试光盘或 DVD 碟?
若没有问题,请按下『 Test 』按钮,此时会出现分析过程如下图所示:

图2.2.7、开始分析 DVD 的内容!
最终的分析结果如下所示,按下『 OK 』即可!如果你发现了分析错误的情况,很可能是你下载的 DVD 来源档案不完整, 或者是光盘/DVD被你的光驱挑片,或者是烧录的速度倍数太高而导致烧录不完整等等,总之,可能就是要你再重新捉一片新的 DVD 啦!这就是测试 DVD 的优点,虽然会花去一些时间就是了。

图2.2.8、检验结果是正确的情况
如果还有其他光盘想要被测试时,在下图中按下『 Test 』继续!不过我们仅有一片 DVD 而已, 因此这边选择『 Continue 』来进入安装的程序喔!

图2.2.9、检验结束,开始安装的流程
接下来就是整个安装的程序了。安装的画面如下所示:

图2.3.1、欢迎画面萤幕
如果你想要了解这一版的CentOS 5.3有什么公告的注意事项,请按下上图的『Release Notes』按钮(1号箭头处), 就能够看到释出公告的项目。如果没有问题的话,请按下『Next』开始安装程序啦!如下所示会出现语系的选择了。

图2.3.2、安装过程的语系选择
我们惯用的中文为繁体中文,请先选择繁体中文的项目(Chinese, Traditional),然后继续给他『Next』即可出现如下画面:

图2.3.3、键盘字元对应表的选择
因为繁体中文预设也是使用美式英文的键盘对照表,因此你会看到画面直接就是美式英文,你只要按下『下一步』即可! 此时你也会发现,整个画面通通变成中文介面啦!真是好具有亲和力喔!
如果没有问题的话,理论上应该会进入下个步骤,亦即是磁碟分割的画面才对。不过,如果你的硬盘是全新的, 而且并没有经过任何的磁碟分割时,就会出现如下的警告讯息:

图2.3.4、安装程序找不到磁碟分割表的警告图示
因为鸟哥使用的是Virtualbox虚拟机器的环境,所以预设的那颗硬盘是全新的,所以才会出现上述的讯息。 请在上图中按下『是』吧!你的主机内的硬盘如果不是全新的,上述的警告画面不会出现!而如果你曾经安装过 Linux 的话,那么可能会出现如下图的样子:

图2.3.5、曾经安装过 CentOS 出现的全新安装或升级
如果没有其他特别的需求,那就选择全新安装吧!接下来让我们开始磁碟分割去!
如同前面谈到的,磁碟分割是整个安装过程里面最重要的部分了。CentOS预设给了我们四种分割模式,分别为:
- 移除所选磁碟上的所有分割区,并建立预设分割模式: 如果选择这种模式,你硬盘会整个被Linux拿去使用,并且硬盘里面的分割全部被删除后, 以安装程序的预设方式重新建立分割槽,使用上要特别注意!
- 移除所选磁碟上的 Linux 分割区,并建立预设的分割模式: 在这个硬盘内,只有Linux的分割槽会被删除,然后再以安装程序的预设方式重新建立分割槽。
- 使用所选取磁碟上的未使用空间,建立预设的分割模式: 如果你的这颗硬盘内还有未被分割的磁柱空间(注意,是未被分割,而不是该分割槽内没有数据的意思!), 那么使用这个项目后,他不会更动原有的分割槽,只会就剩余的未分割区块进行预设分割的建置。
- 建立自订的分割模式: 就是我们要使用的啦!不要使用安装程序的预设分割方式,使用我们需要的分割方式来处理。
如果你想要玩一玩不同的分割模式,那如下图箭头所指的地方,点一下该按钮就会出现上面说明的四种模式了。自己玩玩先! 但是因为我们已经规划好要建立四个分割槽,分别是/, /boot, /home与swap四个,所以不想要使用安装程序预设的分割方式。 因此如下所示,我们所使用的是自订分割的模式。不要搞错喔!

图2.4.1、磁碟分割方式的挑选
按下『下一步』后就会出现如下的分割视窗。这个画面主要分为三大区块,最上方为硬盘的分割示意图, 目前因为鸟哥的硬盘并未分割,所以呈现的就是一整块而且为Free的字样。中间则是指令区,下方则是每个分割槽的装置档名、 挂载点目录、文件系统类型、是否需要格式化、分割槽容量大小、开始与结束的磁柱号码等。

图2.4.2、磁碟分割操作主画面
至於指令区,总共有六大区块,其中RAID与LVM是硬盘特殊的应用,这部份我们会在后续的第十五章的进阶档案系统当中再来说明。至於其他指令的作用如下:
- 『新增』是增加新分割,亦即进行分割动作,以建立新的磁碟分割槽;
- 『编辑』则是编辑已经存在的磁碟分割槽, 你可以在实际状态显示区点选想要修改的分割槽,然后再点选『编辑』即可进行该分割槽的编辑动作。
- 『删除』则是删除一个磁碟分割槽,同样的, 你得要在实际状态显示区点选想要删除的分割槽喔!
- 『重设』则是恢复最原始的磁碟分割状态!
需要注意的是,你的系统与鸟哥的系统当然不可能完全一样,所以你萤幕上的硬盘资讯应该不会与鸟哥的相同的喔! 所以看到不同,不要太紧张啊,那是正常的!
- 建立根目录的分割槽
好,接下来我们就尝试来建立根目录(/)的分割槽看看。按下『新增』后,就会出现如下的画面。 由於我们需要的根目录是使用Linux的档案系统,因此预设就是ext3这个档案系统啦! 至於在挂载点的地方,你可以手动输入也可以用滑鼠来挑选。 最后在大小(MB)的地方输入你所需要的磁碟容量即可。不过由於鸟哥这个系统当中只有一颗磁碟, 所以在『可用的磁碟机』里面就不能够自由挑选罗!

图2.4.3、新增磁碟分割槽的画面
如果你想要知道Linux还支援什么档案系统类型,点一下上图中的ext3那个按钮,就会出现如下的画面啦!

图2.4.4、分割过程的档案系统类型挑选
这几种档案系统类型分别是:
- ext2/ext3:是Linux适用的档案系统类型。由於ext3档案系统多了日志的记录, 对於系统的复原比较快速,因此建议你务必要选择新的ext3不要用ext2了。 (日志式档案系统我们会在后续的第八章介绍他的意义。)
- physical volume (LVM):这是用来弹性调整档案系统容量的一种机制, 可以让你的档案系统容量变大或变小而不改变原有的档案数据内容!这部份我们会在第十五章、进阶档案系统管理中谈到!
- software RAID:利用Linux操作系统的特性,用软件模拟出磁盘阵列的功能! 这东西很棒!不过目前我们还用不到!在后续的第十五章再跟大家报告了!
- swap:就是内存置换空间!由於swap并不会使用到目录树的挂载, 所以用swap就不需要指定挂载点喔!
- vfat:同时被Linux与Windows所支援的档案系统类型。 如果你的主机硬盘内同时存在Windows与Linux操作系统,为了数据的交换,确实可以建置一个vfat的档案系统喔!
这几样东西都很有趣!不过,毕竟我们才刚刚碰这个Linux嘛!先安装起来其他的以后再说。 所以,你只要使用ext3以及swap这两者即可啦!
一切数据都填入妥当后,就会出现如下的画面。因为我们的根目录就是需要10GB的容量, 因此在大小(MB)的地方就得要填入10000的大小。 因为1G=1000M比较好记忆嘛!而且我们的根目录容量是固定的,所以在下图的大小选项就选择『固定大小』了。 此外,如果你硬要自己调整主要/延伸/逻辑分割的类型时,最后那个『强制成为主要分割』可以自己玩一玩先!最后按下确定吧!

图2.4.5、新增根目录分割槽的最终图示
按下确定后就会回到原本的分割操作画面(如下图所示)。此时你会看到分割示意图多了一个hda1,且在实际分割区域显示中, 也会看到/dev/hda1是对应到根目录的。在『格式化』的项目中出现一个打勾的符号, 那代表后续的安装会将/dev/hda1重新格式化的意思。接下来,我们继续按下『新增』来建立/boot这个分割槽吧!

图2.4.6、磁碟分割主画面的改变示意图
- 建立/boot目录的分割槽
同样的,在按下『新增』后,如下依序填入正确的资讯,包括挂载点、档案系统、档案大小等。 由於第三章的大硬盘配合旧主机当中我们谈到如果有/boot独立分割槽时, 务必让该分割槽在整颗硬盘的最前面部分。因此,我们针对/boot就选择『强制成为主要分割』罗!如下图所示:

图2.4.7、新增/boot分割槽的最终结果
最终建立/boot分割槽的结果如下所示,仔细看输出的结果喔!安装程序还挺聪明的, 他会主动的将/boot这个特殊目录移到磁碟最前面,所以你会看到/boot所在的磁碟分割槽为/dev/hda1,而起始磁柱则为1号呢! 很有趣吧!情况如下图所示:

图2.4.8、/boot分割槽自动调整磁柱号码示意图
- 建立内存置换空间swap的分割槽
在上图中继续按下『新增』来处理内存置换空间(swap)。如同上面谈到的, 因为swap是内存置换空间,因此不需要有挂载点。所以,请如同下图所示,在『档案系统类型』处挑选为『swap』吧!

图2.4.9、swap档案系统的挑选示意图
挑选了swap之后,你就会发现到『挂载点』部分自动变成『不适用』了!因为不需要挂载啦!那么swap应该要选多大呢? 虽然我们已经自订为1GB这么大的置换空间,不过,在传统的Linux说明文件当中特别有指定到 『swap最好为实体内存的1.5到2倍之间』。swap置换空间是很重要的, 因为他可以避免因为实体内存不足而造成的系统效能低落的问题。但是如果你的实体内存有4GB以上时, 老实说,swap也可以不必额外设定啦!
swap内存置换空间的功能是:当有数据被存放在实体内存里面,但是这些数据又不是常被CPU所取用时, 那么这些不常被使用的程序将会被丢到硬盘的swap置换空间当中, 而将速度较快的实体内存空间释放出来给真正需要的程序使用! 所以,如果你的系统不很忙,而内存又很大,自然不需要swap罗。

图2.4.10、新增swap分割的最终结果
某些安装程序在你没有指定swap为内存的1.5~2倍时会有警告讯息的告知,此时只要将警告讯息忽略,按下一步即可。 好了,如果一切都顺利完成的话,那么你就会看到如下的分割结果罗!

图2.4.11、详细的分割参数结果
- 建立/home目录的分割槽
让我们继续完成最后一个分割槽的分割吧!继续按下上图的『新增』然后完成如下数据的填写并按下确定:

图2.4.12、新增/home分割槽的最终结果
分割的最终结果终於出炉!如下图所示。你会发现到系统自动的将/dev/hda4变成延伸分割喔!然后将所有容量都给/dev/hda4, 并且将swap分配到/dev/hda5去了!这就是分割的用途!这也是为什么我们要在第三章花这么多时间来解释分割的原因啦!

图2.4.13、详细的分割参数结果
到此为止,我们这个练习机的分割就已经完成了!底下我们额外介绍如果你还想要删除与建立软件磁盘阵列, 该如何在安装时就制作呢?
- 删除已存在分割的方法:(Option, 看看就好别实作)
如果你想要将某个分割槽删除,或者是你刚刚错误指定了一个分割槽的相关参数,想要重新处理时,要怎办啊? 举例来说,我想要将上图的/dev/hda5那个swap分割槽删除掉。好,先将滑鼠指定到swap上面点一下,如下图所示, 该分割槽会反白,然后再按下『删除』此时会如下图所示跳出一个视窗,在该视窗内按下『删除』这个分割槽就被删除啦!

图2.4.14、删除已存在分割的方法
- 建立软件磁盘阵列的方法:(Option, 看看就好别实作)
如果你知道什么是磁盘阵列的话,那么底下的步骤可以让你建置一个软件模拟的磁盘阵列喔! 由於磁盘阵列在后面第十五章、进阶档案系统管理才会讲到,这里只是先告诉您, 其实磁盘阵列可以在安装时就建置了呢!首先,同样的,在分割操作按键区按下『新增』,然后出现下图,选择『Software RAID』项目,并填入1000MB的大小,按下确定!

图2.4.15、软件磁盘阵列分割槽的建立示意图
上述的动作『请要连续作两次』之后,就会出现如下图示。注意喔,由於我们尚未讲到RAID的等级(level), 所以你应该还不了解为什么要作两次。没关系,先有个底,读完整份数据后再回来查阅时,你就会知道如何处理了。 两个软件RAID的分割资讯如下图所示:

图2.4.16、在已具有软件磁盘阵列分割槽的状态下建置RAID
由於我们已经具有件RAID的分割槽,此时才能按下『RAID』来建立软件磁盘阵列的装置。 如上图所示,看到了两个软件磁盘阵列,然后按下右上方的RAID按钮,就会出现如下图示:

图2.4.17、建立软件磁盘阵列/dev/md0
与一般装置档名不同的,第一个软件磁盘阵列的装置名称为/dev/md0。 如上图所示,你会发现到系统多出了一个怪怪的装置名称,这个档名就是未来给我们格式化用的装置啦! 而这个软件磁盘阵列的装置其实是利用实体的分割槽来建立的哩。按下上图的『确定』后就会出现如下的图示:

图2.4.18、软件磁盘阵列的挂载点、等级与档案系统格式
由於我们仅建立两个软件磁盘阵列分割槽,因此在这边只能选择RAID0或RAID1。我们以RAID0来作为示范, 你会发现中间白色框框的地方会有两个可以选择的分割槽,那就是刚刚我们建立起来的software RAID分割槽。 我们将这个/dev/md0挂载到/myshare目录去!然后再按下确定吧!

图2.4.19、最终细部分割参数示意图
最终的结果就像上图所示,在实际分割区就会显示/dev/md0,而由於这个装置是Linux系统模拟来的, 所以在磁柱号码(开始/结束)的地方就会留白!这样可以了解吗?
- 开机管理程序的处理
分割完成后就会进入开机管理程序的安装了,目前较新的Linux distributions大多使用grub管理程序, 而且我们也必须要将他安装到MBR里面才行!因此如下图所示,在1号箭头的地方就得要选择整部磁碟的档名 (/dev/hda), 其实那就代表该颗硬盘的MBR之意。
下图中2号箭头所指的就是开机时若出现选单,那么选单内就会有一个名为『CentOS』的可选择标签。 这个标签代表他根目录所在的位置为/dev/hda2这样的意思。而如果开机内5秒钟不按下任何按键,就预设会以此一标签来开机。
如果你还想要加入/编辑各个标签,那可以按下3号箭头所指的那三个按键喔!

图2.5.1、开机管理程序的处理
如果你觉得『CentOS』这个选单不好看,想要自订自己的选单名称,那么在上图中先点一下『CentOS』那个标签, 然后按下3号箭头所指的『编辑』按钮,就会出现如下画面。在如下画面中可以填写你自己想要的选单名称喔! 鸟哥是很讨厌麻烦的,所以就使用预设的选单名称而已。

图2.5.2、编辑开机选单的标签名称
如果你的计算机系统当中还有其他的『已安装操作系统』时,而且你想要让Linux在开机的时候就能够让你选择不同的操作系统开机, 那么就如同下图所示,你可以先按下『新增』,然后在2号箭头的地方选择其他操作系统所在的分割槽, 并在3号箭头处填入适当的名称(例如WindowsXP等等),按下确定就能够在开机时新增一个选单罗!

图2.5.3、新增开机选单标签的示意图
如果你是个很龟毛的人,你希望你的系统除非你自己在计算机前面开机并输入密码后才能开始开机流程的话, 那么可以如同下图所示加入密码管理机制。不过grub开机管理程序加入密码虽然有好处, 但是如此一来我们就无法在远端重新开机了,因此鸟哥暂时不建议你设定开机管理程序的密码喔! 底下只是一个示意图,让你知道如何加入密码管理而已!

图2.5.4、设定开机管理程序的密码
- 将开机管理程序安装到boot sector(Option, 看看就好,不要实作)
如果你因为特殊需求,所以Linux的开机管理程序无法安装到MBR时,那就得要安装到每块partition的开机磁区(boot sector)了。果真如此的话,那么如同下图所示,先勾选『设定进阶开机管理程序选项』的地方:

图2.5.5、进阶开机管理程序选项
然后就会出现如下的图示,预设Linux会将开机管理程序安装到MBR,如果你想要安装到不同的地方去, 请如同下图的箭头处,选择『开机分割区的第一个磁区』就是该分割槽的boot sector罗!

图2.5.6、将开机管理程序安装到boot sector的方法
- 网络参数的给予
如果你的网络卡可以被安装程序捉到的话,那么你就可以设定网络参数了!例如下图所示的模样。 目前各大版本几乎都会预设网络卡IP的取得方式为『自动取得IP』,也就是所谓的『DHCP』网络协定啦! 不过,由於这个协定需要有DHCP服务器的辅助才行,如果你的环境没有种服务器存在的话, 那开机的过程中可能会等待一段时间。所以通常鸟哥都改成手动设定。不过,无论如何,都要与你的网络环境相同才是。

图2.5.7、设定网络参数的过程
在上图中我们可以看到所有的网络参数都是经过dhcp取得的,所以通通不需要设定任何项目。 至於网络装置内的白色框框中仅有一张网卡的显示。由於我们要将IP改为手动给予, 但我们尚未谈到服务器与网络基础,所以这里你不懂也没有关系,请先按照先前我们所规划的IP参数去填写即可。 请按下上图的『编辑』按钮,就会出现如下的画面了:

图2.5.8、手动编辑网络IP参数
在上图中的最上方我们可以看到这张网络卡的制造商(AMD)与网卡卡号(Hardware address:), 并且我们的Linux也支援IPv4与IPv6(第四版与第六版的IP参数)。因为目前(2009)支援IPv6的环境还是很少, 所以我们先将IPv6的支援取消(3号箭头处)。
至於IPv4的IP参数给予,如上图所示,你得先在1号箭头处点选手动设定(Manual configuration), 然后在2号箭头处输入正确的IP与子遮罩网络(Netmask),最后再按下确定即可。处理完毕后就会显示如下的图示了:

图2.5.9、设定网络参数的过程
完成IP参数的设定后,接下来是这部练习机的主机名称,请输入你喜欢的主机名称。 因为目前我们的主机尚未能与网际网络接轨,所以你可以随便填写任何你喜欢的主机名称。 主机名称通常的格式都是『主机名.网域名』,其实就有点像是『名字.姓氏』的样子。 为了不与网际网络的其他主机冲突,因此这里鸟哥使用我自己的名字作为主机名! 填写完毕后请按下『下一步』吧!

图2.5.10、未设定闸道器的警告讯息
咦!怎么会出现如同上图所示的错讯息呢?别担心,因为我们的主机还不能够连上Internet, 所以出现这个错误讯息是正常的。请按下『继续』来往后处理吧!
- 时区的选择
时区是很重要的!因为不同的时区会有不一样的日期/时间显示嘛!可能造成档案时间的不一致呢, 所以,得要告知系统我们的时区在哪里才行啊! 如下图所示,你可以直接在1号箭头处选择亚洲台北, 或直接用滑鼠在地图上面点选也可以!要特别注意的是那个『UTC』,由於广泛使用的 GMT 时间与现实的时间有点脱节了, 因此我们可以透过 UTC 这个原子钟时间的计算方式,取得较为正确的时间喔! 不过,要不要选择随你开心啦!预设是需要支援的喔!

图2.5.11、时区的选择
- 设定root的密码
再来则是最重要的『系统管理员的密码』设定啦! 在Linux底下系统管理员的预设帐号名称为root,请注意,这个密码很重要!虽然我们是练习用的主机, 不过,还是请你养成良好的习惯,最好root的密码可以设定的严格一点。可以设定至少8个字元以上, 而且含有特殊符号更好,例如:I&my_dog之类,有点怪,但是对你又挺好记的密码!

图2.5.12、设定root密码
一切都差不多之后,就能够开始挑选软件的安装啦!咦!我怎么知道我要什么套件?哈哈! 您当然不可能会知道~知道的话.....就不会来这儿查阅数据了 @_@ 没有啦!开开玩笑....呼~好冷~~
关於软件的安装有非常多的想法,如果你是初次接触Linux的话,当然是全部安装最好。 如果是已经安装过多次Linux了,那么使用预设安装即可,以后有需要其他的软件时,再透过网络安装就好了! 这样你的系统也会比较干净。但是在这个练习机的安装中,我们使用预设值加上CentOS提供的选项来安装即可。 如下图所示:

图2.6.1、额外选择多的软件群组
如上图所示,你可以增加1号箭头所指的三个项目,然后在2号箭头处保持预设值,再给他下一步即可。 这样的安装对於初学者来说已经是非常OK的啦!
- 额外的软件自订模式(Option, 进阶使用者可以参考)
在Linux的软件安装中,由於每个各别软件的功能非常庞大,很多软件的开发工具其实一般用户都用不到。 如果每个软件都仅释出一个档案给我们安装,那么我们势必会安装到很多不需要的档案。 所以,Linux开发商就将一项软件分成多个档案来给使用者选择。如果你想要了解每项软件背后的档案数据, 就可以如同下图所示,选择『立即自订』来设定专属的软件功能。

图2.6.2、软件自订安装的功能
自订软件的画面如下所示,1号箭头处为软件群组,是开发商将某些相似功能的软件绑在一起成为一个群组。 你可以在1号箭头处选择你有兴趣的功能,然后在2号箭头处挑选该项目内的细项。如下图所示, 鸟哥挑选了『程序开发』的群组后,在2号箭头处挑选了鸟哥有兴趣的『开发工具』等, 而这些工具的意义在3号箭头处所指的白色框框中就会有详细的说明了。

图2.6.3、自己选择所需软件的画面
检查完毕后安装程序会去检查你所挑选的软件有没有冲突(相依性检查),然后就会出现下列视窗, 告诉你你的安装过程写入到/root/install.log档案中,并且你刚刚选择的所有项目则写入到/root/anaconda-ks.cfg档案内。 这两个档案很有趣,安装完毕后你可以自己先看看。

图2.6.4、准备开始安装
然后就是开始一连串的等待了!这个等待的过程与你的硬件以及选择的软件数量有关。 如下图所示,2号箭头处所指的则是安装程序评估的剩余时间这个时间不见得准啦!看看就好!

图2.6.5、安装过程的画面示意图
安装完毕并按下『Reboot』重新开机后,萤幕会出现如下的讯息,这是正确的资讯,不要担心出问题啊! 此时请拿出你的DVD光盘,让系统自动重新开机。其他的后续设定,请参考下一小节呢!

图2.6.6、安装完毕后,重新开机的示意图
- 内存压力测试:memtest86
CentOS的DVD除了提供一般PC来安装Linux之外,还提供了不少有趣的东西,其中一个就是进行『烧机』的任务! 这个烧机不是台湾名产烧酒鸡啊,而是当你组装了一部新的个人计算机,想要测试这部主机是否稳定时, 就在这部主机上面运作一些比较耗系统资源的程序,让系统在高负载的情况下去运作一阵子(可能是一天), 去测试稳定度的一种情况,就称为『烧机』啦!
那要如何进行呢?同样的,放入CentOS的DVD到你的光盘中,然后用这片DVD重新开机,在进入到开机选单时, 输入memtest86即可。如下图所示:

图2.7.1、RAM测试
之后系统就会进入这支内存测试的程序中,开始一直不断的对内存写入与读出! 如果烧机个一两天,这支程序还是不断的跑而没有因为任何原因来当机,表示你的内存应该还算稳定啦! 如下所示。如果不想跑这支程序了,就按下箭头所指的『ESC』处,亦即按下[Esc]按键,就能够重新开机罗!

图2.7.2、RAM测试
对memtest86有兴趣的朋友,可以参考如下的连结喔:
- http://www.memtest.org/
- 安装笔记本电脑或其他类PC计算机的参数
由於笔记本电脑加入了非常多的省电机制或者是其他硬件的管理机制,包括显示卡常常是整合型的, 因此在笔记本电脑上面的硬件常常与一般桌上型计算机不怎么相同。所以当你使用适合於一般桌上型计算机的DVD来安装Linux时, 可能常常会出现一些问题,导致无法顺利的安装Linux到你的笔记本电脑中啊!那怎办?
其实很简单,只要在安装的时候,告诉安装程序的linux核心不要载入一些特殊功能即可。 最常使用的方法就是,在使用DVD开机时,加入底下这些选项:
boot: linux nofb apm=off acpi=off pci=noacpiapm(Advanced Power Management)是早期的电源管理模组,acpi(Advanced Configuration and Power Interface)则是近期的电源管理模组。这两者都是硬件本身就有支援的,但是笔记本电脑可能不是使用这些机制, 因此,当安装时启动这些机制将会造成一些错误,导致无法顺利安装。
nofb则是取消显示卡上面的缓冲内存侦测。因为笔记本电脑的显示卡常常是整合型的, Linux安装程序本身可能就不是很能够侦测到该显示卡模组。此时加入nofb将可能使得你的安装过程顺利一些。
对於这些在开机的时候所加入的参数,我们称为『核心参数』,这些核心参数是有意义的! 如果你对这些核心参数有兴趣的话,可以参考文后的参考资料来查询更多资讯(注2)。
BIOS 工作原理
最近几天在看《 UNIX 操作系统设计》突然想到计算机是如何启动的呢?那就得从BIOS 说起,其实这个冬冬早已是 n 多人写过的了,今天就以自己的理解来写写,权当一个学习笔记。
一、 预备知识:
很多人将 BIOS 与 CMOS 混为一谈,在开始介绍 BIOS 工作原理以前先来简单的了解以下 BIOS 、 CMOS :
什么是 BIOS
系统开机启动 BIOS ,即微机的基本输入输出系统 (Basic Input-Output System) ,是集成在主板上的一个 ROM 芯片,其中保存有微机系统最重要的基本输入 / 输出程序、系统信息设置、开机上电自检程序和系统启动自举程序。
集成在 BIOS 上得程序主要有如下几个:
BIOS 中断例程: 即 BIOS 中断服务程序。它是微机系统软、硬件之间的一个可编程接口,用于程序软件功能与微机硬件实现的衍接。 DOS/Windows 操作系统对软、硬盘、光驱与键盘、显示器等外围设备的管理即建立在系统 BIOS 的基础上。程序员也可以通过 对 INT 5 、 INT 13 等中断的访问直接调用 BIOS 中断例程。
BIOS 系统设置程序: 微机部件配置情况是放在一块可读写的 CMOS RAM 芯片中的,它保存着系统 CPU 、软硬盘驱动器、显示器、键盘等部件的信息。 关机后,系统通过一块后备电池向 CMOS 供电以保持其中的信息。如果 CMOS 中关于微机的配置信息不正确,会导致系统性能降低、零部件不能识别,并由此引发一系统的软硬件故障。在 BIOS ROM 芯片中装有一个程序称为 “ 系统设置程序 ” ,就是用来设置 CMOS RAM 中的参数的。这个程序一般在开机时按下一个或一组键即可进入(一般为 Delete 键),它提供了良好的界面供用户使用。这个设置 CMOS 参数的过程,习惯上也称为 “BIOS 设置 ”。新购的微机或新增了部件的系统,都需进行 BIOS 设置。
POST 上电自检 微机接通电源后,系统将有一个对内部各个设备进行检查的过程,这是由一个通常称之为 POST(Power On Self Test, 上电自检 ) 的程序来完成的。这也是BIOS 的一个功能。完整的 POST 自检将包括 CPU 、 640K 基本内存、 1M 以上的扩展内存、 ROM 、主板、 CMOS 存贮器、串并口、显示卡、软硬盘子系统及键盘测试。自检中若发现问题,系统将给出提示信息或鸣笛警告。
BIOS 系统启动自举程序 在完成 POST 自检后, ROM BIOS 将按照系统 CMOS 设置中的启动顺序搜寻软硬盘驱动器及 CDROM 、网络服务器等有效的启动驱动器 ,读入操作系统引导记录,然后将系统控制权交给引导记录,由引导记录完成系统的启动。
什么是 CMOS
CMOS (本意是指互补金属氧化物半导体 —— 一种大规模应用于集成电路芯片制造的原料)是微机主板上的一块可读写的 RAM 芯片,用来保存当前系统的硬件配置和用户对某些参数的设定。 CMOS 可由主板的电池供电,即使系统掉电,信息也不会丢失。CMOS RAM 本身只是一块存储器,只有数据保存功能,而对 CMOS 中各项参数的设定要通过专门的程序。早期的 CMOS 设置程序驻留在软盘上的 ( 如 IBM 的 PC/AT 机型 ) ,使用很不方便。现在多数厂家将 CMOS 设置程序做到了 BIOS 芯片中,在开机时通过特定的按键 就可进入 CMOS 设置程序方便地对系统进行设置,因此 CMOS 设置又被叫做 BIOS设置。 早期的 CMOS 是一块单独的芯片 MC146818A(DIP 封装 ) ,共有 64 个字节存放系统信息 , 见 CMOS 配置数据表。 386 以后的微机一般将 MC146818A 芯片集成到其它的 IC 芯片中 ( 如 82C 206 , PQFP 封装 ) ,最新的一些 586 主板上更是将 CMOS 与系统实时时钟和后备电池集成到一块叫做 DALLDA DS1287 的芯片中。随着微机的发展、可设置参数的增多,现在的 CMOS RAM 一般都有 128 字节及至 256 字节的容量。为保持兼容性,各 BIOS厂商都将自己的 BIOS 中关于 CMOS RAM 的前 64 字节内容的设置统一与 MC146818A 的CMOS RAM 格式一致,而在扩展出来的部分加入自己的特殊设置,所以不同厂家的 BIOS芯片一般不能互换,即使是能互换的,互换后也要对 CMOS 信息重新设置以确保系统正常运行。
二、工作原理介绍
下面从计算机加电开始,看 BIOS 是如何一步一步工作的:
1、 加电
计算机电源开始工作,当电源的输入电压稳定以后,主板的 timer 被触发,它产生一个复位脉冲送给 80X86cpu 让 cpu 开始工作,当 cpu 收到该复位脉冲后,其硬件逻辑就会置 CS 寄存器为 FFFFH , IP 寄存器为 0000H ,也就是说,会自动地到 FFFF:0000H 去取第一条指令,(在对内存编址的时候,高地址部分总是编给一些 ROM ,在这些 ROM 里是预先写好的程序或数据,地址 FFFF : 0000h 其实就是在 ROM 里。以前不懂这个规则的时候着实被搞糊涂了,不明白 FFFF : 0000h 里的跳转指令是哪里来的,其实就是写死在 ROM 里的了,就这么简单。) 这个地方只有一条 JMP 指令,告诉处理器到什么地方读取 BIOS ROM 。
2 、 POST
POST 其实是一系列的执行不同初始化和计算机硬件检测的函数或例程。 BIOS 以对主板硬件的一系列检测开始,包括检测: cpu ,数学协处理器、时钟 IC , DMA 控制器和中断请求( IRQ )控制器,检测的顺序根据主板的不同而不同。
然后, BIOS 会在地址 C000:000h 和 C780:000h 之间检测视频 ROM 是否存在,如果视频 BIOS 存在,则对视频 ROM 中的内容求校验和进行检测,如果检测成功,则 BIOS 将控制权转交给视频 BIOS 让其初始化当完成时再将控制权交回给 BIOS 。此时你将会在屏幕上看到显卡信息,例如显卡制造商的 logo ,显卡的描述信息,以及显卡 BIOS 信息等。
然后 BIOS 以 2K 的增量扫描 C800:000h 到 DF800:000h 直接的地址,以检测计算机中可能装的其他 ROM ,比如网卡、 SCSI 适配器等,如果找到一个设备的 ROM ,则对该设备的 ROM 中的内容做校验和,如果检测通过则将控制权转交给设备 BIOS 让其对设备进行初始化,初始化结束后 BIOS 再收回控制权,如果校验和检测失败,将再屏幕上显示:“ XXX ROM Error ”,其中 XXX 是检测到该 ROM 的地址的断地址。
然后, BIOS 开始检测地址为 0000:0472h 的内存,该处存放这一个标识系统是通过冷启动启动还是通过热启动启动的标志,如果为 1234h 则代表热启动(该数值是一 little endian 的格式存储的,因此在内存中的应为 3412 ), BIOS 将直接跳过剩余的 POST 例程。如果是冷启动, BIOS 将继续执行剩余的 POST 例程,在此过程中, BIOS 将一个 16进制的编码写到端口 80h (不同的计算机端口号会不同),这个 16 进制编码指示在何时检测什么。
3 、引导操作系统
POST 结束之后, BIOS 会寻找一个操作系统。通常, BIOS 会试图在软驱中寻找DOS 系统的引导盘,如果找不到,它会试图在 C 盘寻找操作系统。如果软驱中有引导盘, BIOS 将 1 扇区 0 磁头 0 柱面的内容(引导记录)载入内存 0000 : 7C 00h 开始的地方。如果软盘中没有 DOS 引导盘,则 BIOS 搜索硬盘寻找硬盘的第一个扇区,然后把主引导记录( MBR )载入内存 0000 : 7C 00h 开始的地方。 一旦引导记录加载完毕, BIOS就交出系统的执行控制权,跳转到引导程序的头部执行。下面就是硬盘的 MBR 代码流程,其中的引导扇区是指硬盘相应分区的第一个扇区,是和操作系统有关的操作系统的引导是由它来完成的,而 MBR (硬盘的第一个扇区)并不负责, MBR 和操作系统无关他的任务是把控制权转交给操作系统的引导程序 。
程序流程:
1 将程序代码由 0000:7C00H 移动到 0000:0600H (注, BIOS 把 MBR 放在 0000:7C00H处)
2 搜索可引导分区,即 80H 标志
成功: goto 3
失败:跳入 ROM BASIC
无效分区表: goto 5
3 读引导扇区 ( 注:用于操作系统的引导,将它读到 0000 : 7C 00H)
失败: goto 5
成功: goto 4
4 验证引导扇区最后是否为 55AAH
失败: goto 5
成功: goto 6
5 打印错误进入无穷循环
6 跳到 0:7C00H 进行下一步启动工作
GRUB入门教程
原文出处:未知
原文作者:未知
授权许可:创作共用协议
翻译人员:未知
编辑人员:rApJtR
校对人员:无
适用版本:
文章状态:尚待完善
备注:从论坛的翻译区整理过来,帖子作者millenniumdark 却不能确定是否是他翻译的,另外原文来源不明,等待核实。
引用地址:http://forum.ubuntu.org.cn/viewtopic.php?t=2475
目录
[隐藏]- 1 教程提示
- 1.1 我应该学习这门教程吗?
- 2 GRUB 基础
- 2.1 什么是 GRUB?
- 2.2 GRUB 很棒
- 2.3 为什么使用 GRUB?
- 3 安装 GRUB
- 3.1 下载 GRUB
- 3.2 安装步骤
- 3.3 制作引导盘
- 3.3.1 准备开始
- 3.3.2 准备磁盘
- 3.3.3 启动GRUB
- 3.3.4 完成引导盘
- 4 使用 GRUB
- 4.1 准备
- 4.2 启动 GRUB
- 4.3 首次接触
- 4.4 "root"
- 4.5 GRUB 命名约定
- 5 GRUB 内幕
- 5.1 重新调查引导软盘
- 5.2 两阶段过程
- 5.3 阶段 1、1.5 和 2
- 5.4 搜索和恢复
- 5.5 硬盘引导
- 5.6 引导菜单
- 5.7 理解引导菜单
- 6 总结
- 6.1 GRUB 的弹性
- 6.2 优秀的 GRUB 参考资料
教程提示
我应该学习这门教程吗?
本教程向您显示如何安装和使用 GRUB (Grand Unified Boot Loader)。就像 LILO 一样,GRUB 允许引导 Linux 系统,它负责装入和引导内核。但与 LILO 不同,GRUB 的功能非常多,更易于使用,更可靠和灵活,而且非常小巧。
如果已经有些熟悉 LILO,并了解了磁盘分区的基本知识,那么您就掌握了学习本教程应具备的预备知识。通过学习本教程和安装 GRUB 之后,您将改进 Linux 系统的可靠性和可用性。
如果只是想尝试 GRUB,可以学习本教程的前半部分,并制作 GRUB 引导盘,然后练习使用它来引导系统。这样做以后,您将学会在紧急情况下如何使用 GRUB 来引导系统。
但是,如果想更深入地体验 GRUB,可以学完整个教程,它将为您演示如何将 GRUB 设置成缺省引导装入器。
GRUB 基础
什么是 GRUB?
GRUB 是引导装入器 -- 它负责装入内核并引导 Linux 系统。GRUB 还可以引导其它操作系统,如 FreeBSD、NetBSD、OpenBSD、GNU HURD 和 DOS,以及 Windows 95、98、NT 和 2000。尽管引导操作系统看上去是件平凡且琐碎的任务,但它实际上很重要。如果引导装入器不能很好地完成工作或者不具有弹性,那么就可能锁住系统,而无法引导计算机。另外,好的引导装入器可以给您灵活性,让您可以在计算机上安装多个操作系统,而不必处理不必要的麻烦。
GRUB 很棒
GRUB 是一个很棒的引导装入器。它有许多功能,可以使引导过程变得非常可靠。例如,它可以直接从 FAT、minix、FFS、ext2 或 ReiserFS 分区读取 Linux 内核。这就意味着无论怎样它总能找到内核。另外,GRUB 有一个特殊的交互式控制台方式,可以让您手工装入内核并选择引导分区。这个功能是无价的:即使 GRUB 菜单配置不正确,你仍可以引导系统。哦,对了 -- GRUB 还有一个彩色引导菜单。我们只是刚开始。
为什么使用 GRUB?
您也许会奇怪,为什么全世界都需要 GRUB -- 毕竟,Linux 世界在很长一段时间里一直使用 LILO 引导装入器,而且它可以让上百万的 Linux 用户引导系统。是的,的确是这样,LILO 很有效。但是,LILO 的维修率很高,而且很不灵活。与其花很多时间来描述 GRUB 的优点,还不如演示如何创建自己的 GRUB 引导盘以及如何使用它来引导系统。然后,我将说明 GRUB 的一些很“酷”的技术细节,并指导您完成将 GRUB 安装到 MBR(主引导记录)的过程,以使它成为缺省引导装入器。
如果您有点胆小,不必害怕。可以学习本教程的前半部分,创建 GRUB 引导盘,尝试使用 GRUB 而不必弄乱现有的引导装入器。或者,可以用其安全的“驻留”方式来熟悉 GRUB。那么,让我们立即开始吧。
安装 GRUB
下载 GRUB
要开始探究 GRUB 的精妙之处,首先需要下载、编译和安装它。但不要害怕 -- 根本不会修改您的引导记录 -- 我们只是要编译和安装 GRUB,就像其它程序一样,在此过程中我们可以创建 GRUB 引导盘。请不要担心;在修改引导过程之前,我会告诉您。
现在开始。访问 ftp://alpha.gnu.org/gnu/grub/ (当前可用的ftp地址为:ftp://ftp.gnu.org/gnu/grub) 并下载可以找到的最新版本的 GRUB tar 压缩包。我编写本教程时,最新的 tar 压缩包是 grub-0.5.96.1.tar.gz。下载了最新版本后,就可以安装了。
也可以使用git来安装:git clone git://git.savannah.gnu.org/grub.git
安装步骤
这里是从 tar 压缩包安装 GRUB 所需输入的命令。我将在 /tmp 中编译源文件,并将所有部分都安装到硬盘的 /usr 目录下。
现在已经安装了 GRUB,准备开始使用它。
注意:如果在运行./configure --prefix=/usr 时出现提示 configure: error: xxxxx is not found (表示缺少xxxxx组件,配置中止) 可以用sudo apt-get install xxxxx 安装相应组件,然后再执行配置工作。
如果你使用grub-2.00在运行make时出现
make[4]: *** argp-fmtstream.o] Error 1
make[3]: *** [all-recursive] Error 1
等等的错误提示,请不要慌张,这是glibc-2.16.0的问题,你可以用一个命令来绕过去:
sed -i -e '/gets is a security/d' grub-core/gnulib/stdio.in.h
制作引导盘
准备开始
要制作引导盘,需执行一些简单的步骤。首先,在新的软盘上创建 ext2 文件系统。然后,将其安装,并将一些 GRUB 文件复制到该文件系统,最后运行 "grub" 程序,它将负责设置软盘的引导扇区。
准备磁盘
好,将一张空盘插入 1.44MB 软驱,输入:
创建了 ext2 文件系统后,需要安装该文件系统:
现在,需要创建一些目录,并将一些关键文件(原先安装 GRUB 时已安装了这些文件)复制到软盘:
只需要再有一个步骤,就能得到可用的引导盘。
启动GRUB
解压、编译和安装 GRUB 源 tar压缩包时,会将程序 grub 放到 /usr/sbin 中。该程序非常有趣并值得注意,因为它实际上是 GRUB 引导装入器的半功能性版本。是的,尽管 Linux 已经启动并正在运行,您仍可以运行 GRUB 并执行某些任务,而且其界面与使用 GRUB 引导盘或将 GRUB 安装到硬盘 MBR 时看到的界面完全相同。
这是有趣的设计策略,现在该使用驻留版本的 GRUB 来设置引导盘的引导扇区了。从 root 用户,输入 "grub"。GRUB 控制台将启动,显示如下:
欢迎使用 GRUB 控制台。现在,研究命令。
完成引导盘
在 grub> 提示符处,输入:
现在,引导盘完成了。在继续下一步骤之前,在看一下刚才输入的命令。第一个 "root" 命令告诉 GRUB 到哪里查找辅助文件 stage1 和 stage2。缺省情况下,GRUB 会在指定的分区或磁盘上的 /boot/grub 目录中进行查找。在安装引导盘时,也就是几分钟以前,我们已将这些文件复制到正确的位置。接着,输入了 setup 命令,它告诉 GRUB 将引导装入器安装到软盘的引导记录上;我们将在以后详细讨论这一过程。然后退出。现在,已经制作好引导盘,可以开始使用 GRUB 了。
使用 GRUB
准备
使用 GRUB 引导系统之前,需要知道一些信息。首先,应知道哪个分区保存了 Linux 内核,以及 root 文件系统的分区名称。然后,应查看现有 LILO 配置来寻找需要传递给内核的变量,如 "mem=128M"。一旦获取了这些信息,就可以开始了。
启动 GRUB
要启动 GRUB,需要关闭系统并退出引导盘。如果由于某些原因而不能立即关闭系统(比如上班时在部门的服务器上测试 GRUB),那么只要在提示中输入 "grub" 并继续操作。所有程序的运行情况都不会改变,只是您不能执行引导(因为 Linux 正在运行)。
首次接触
装入引导盘时,在屏幕顶部将出现一条消息,告诉您正在装入第一阶段和第二阶段。几秒后,将会出现一个熟悉的屏幕,显示如下:
可以看到,这些内容与在 Linux 中以驻留方式运行 GRUB 时出现的消息完全相同 -- 只不过现在我们是使用 GRUB 来引导 Linux。
"root"
在 Linux 中,当谈到 "root" 文件系统时,通常是指主 Linux 分区。但是,GRUB 有它自己的 root 分区定义。GRUB 的 root 分区是保存 Linux 内核的分区。这可能是您的正式 root 文件系统,也可能不是。例如,在 Gentoo Linux 中,有一个单独的小分区专用于保存 Linux 内核与引导信息。大多数情况下,我们不安装这个分区,这样在系统意外崩溃或重新引导时,就不会把它弄乱。
这些,我们讨论的是 GRUB,需要指定 GRUB 的 root 分区。进入 root 分区时,GRUB 将把这个分区安装成只读型,这样就可以从该分区中装入 Linux 内核。GRUB 的一个很“酷”的功能是它可以读取本机的 FAT、FFS、minix、ext2 和 ReiserFS 分区,我们很快就会讨论这个功能。但现在,让我们输入 root 分区。在提示中输入 root,但不要按 Enter 键:
现在,按一次 Tab 键。如果系统中有多个硬盘,GRUB 将显示可能完成的列表,从 "hd0" 开始。如果只有一个硬盘,GRUB 将插入 "hd0,"。如果有多个硬盘,继续进行,在 ("hd0") 中输入名称并在名称后紧跟着输入逗号,但不要按 Enter 键。部分完成的 root 命令看起来如下:
现在,继续操作,再按一次 Tab 键。GRUB 将显示特定硬盘上所有分区的列表,以及它们的文件系统类型。在我的系统中,按 Tab 键时得到以下列表:
如您所见,GRUB 的交互式硬盘和分区名称实现功能非常有条理。这些,只需要好好理解 GRUB 新奇的硬盘和分区命名语法,然后就可以继续操作了。
GRUB 命名约定
到目前为止,您可能会感到一点困惑,因为 GRUB 所使用的硬盘/分区命名约定与 Linux 使用的命名约定不同。在 Linux 中,第一个硬盘的第五个分区称作 "hda5"。而 GRUB 把这个分区称作 "(hd0,4)"。GRUB 对硬盘和分区的编号都是从 0 开始计算。另外,硬盘和分区都用逗号分隔,整个表达式用括号括起。现在,回来看一下 GRUB 提示,可以发现如果要引导 Linux 硬盘 hda5,应输入 "root (hd0,4)"。如果已经明白了 GRUB 硬盘/分区命名,您也许要调整当前 root 命令行,以使它指向保存 Linux 内核的分区。按以下格式输完命令,然后按 Enter 键:
GRUB 内幕
重新调查引导软盘
如果一切正常,就可以使用使用 GRUB 引导盘来引导当前 Linux 发行版。如您所见,GRUB 是功能非常强大的引导装入器,它让您可以随意动态配置以进行引导。我将向您介绍如何创建 GRUB 引导菜单,这样就可以从菜单中进行 OS 选择,而不是输入三行命令来引导 Linux。但在动手之前,现在是深入了解 GRUB 幕后是如何工作的好时机。我将说明引导盘引导过程的工作原理,这样您就可以对 GRUB 有一个更好的评价和了解。
两阶段过程
要制作引导软盘,需要做两件事 -- 将文件复制到软盘的 ext2 文件系统的 /boot/grub 目录中,运行 GRUB 的安装程序。运行 GRUB 安装程序时,GRUB 将 "stage 1" 装入器安装到软盘的引导记录中。它还将 stage 1 装入器配置成从 ext2 文件系统直接装入 stage2。通常,GRUB 通过在包含 stage2 数据的软盘上创建一列块来完成此操作,这样 stage1 装入 stage2 时不必知道 ext2 文件系统的任何情况。
但是,大多数情况下,GRUB 在安装完 stage1 之后,会立即将 stage1.5 装入器安装到引导记录中。这个特殊的 stage1.5 允许无需使用原始块列表就能从 ext2 文件系统装入 stage2,却要更灵活的标准基于路径的方法。GRUB 理解文件系统结构的这一能力使 GRUB 比 LILO 更强壮。例如,如果正好在整理引导盘文件系统的碎片,stage1 就可以找到 stage2(归功于 ext2 stage1.5)。而 LILO 就不能完成此项操作。因为 LILO 只能依赖于映射文件,每次更新内核或在磁盘上物理移动数据时,即使不更改路径,也需要重新运行它。
阶段 1、1.5 和 2
您也许会想知道:如果使用 FAT 而不是 ext2 文件系统创建引导盘,GRUB 是否可以工作。是的,它可以工作,因为在输入 "setup (fd0)" 时,GRUB 会安装与 root 文件系统类型匹配的 stage1.5。即使没有没有空间可以安装 stage1.5,GRUB 仍可以通过追溯到更原始的块列表,来装入 stage2。
搜索和恢复
在继续讨论之前,先研究一个与引导软盘相关的实用提示。由于 GRUB 的交互式性质,它为恢复软盘生成了一个很好的引导装入器。但是,如果将好的内核复制到引导盘上,那它就更好了。那样,即使硬盘上的内核坏了或者被意外删除了,也可以追溯到引导盘内核,并启动和运行系统。要将备用内核复制到引导盘,执行以下操作:
现在,软盘已包含备用内核,可以在 GRUB 中使用它来引导 Linux 发行版,操作如下:
硬盘引导
好,现在如何将 GRUB 安装到硬盘上?这个过程几乎与引导盘安装过程一样。首先,需要决定哪个硬盘分区将成为 root GRUB 分区。在这个分区上,创建 /boot/grub 目录,并将 stage1 和 stage2 文件从 /usr/share/grub/i386-pc 复制到该目录中。可以通过重新引导系统并使用引导盘,或者使用驻留版本的 GRUB 来执行后一步操作。在这两种情况下,启动 GRUB,并用 root 命令指定 root 分区。例如,如果将 stage1 和 stage2 文件复制到 hda5 的 /boot/grub 目录中,应输入 "root (hd0,4)"。现在,只差一步。
接着,决定在哪里安装 GRUB -- 在硬盘的 MBR,或者如果与 GRUB 一起使用另一个“主”引导装入器,则安装在特定分区的引导记录中。如果安装到 MBR,则可以指定整个磁盘而不必指定分区,如下(对于 hda):
如果要将 GRUB 安装到 /dev/hda5 的引导记录中,应输入:
现在,已安装 GRUB。引导系统时,应该立即以 GRUB 的控制台方式结束(如果安装到 MBR)。现在,应创建引导菜单,这样就不必在每次引导系统时都输入那些命令。
引导菜单
要创建菜单,只需在 /boot/grub 中创建一个简单的文本文件 menu.lst。如果将它放在正确位置,它将在 root GRUB 驱动器的 stage1 和 stage2 文件的旁边。这里是一个样本 menu.lst 文件,可以将它作为一个您的菜单的基础:
我将在以下的屏面中说明 menu.lst 格式。
理解引导菜单
引导菜单很容易理解。前三行设置缺省菜单项(项目号 0,第一个)、设置超时值(30 秒),并选择整个菜单的一些颜色。
接着的三行配置 "Boot Linux" 菜单项。要创建手工引导命令系列之外的菜单项,只要添加一行 "title=" 作为第一行,并从最后一行中除去 "boot" 命令(GRUB 会自动添加这个命令)。
接着的四行显示了如何使用 GRUB 来引导 initrd(初始 root 磁盘),如果您愿意的话。现在,讨论最后三行…… 链式装入器(chainloader)
这里是示例 menu.lst 的最后三行……
这里,我添加了一项来引导 Windows NT。要完成此操作,GRUB 使用了“链式装入器”。链式装入器从分区 (hd0,3) 的引导记录中装入 NT 自己的引导装入器,然后引导它。这就是这种技术叫做链式装入的原因 -- 它创建了一个从引导装入器到另一个的链。这种链式装入技术可以用于引导任何版本的 DOS 或 Windows。
总结
GRUB 的弹性
GRUB 最好的优点之一就是其强健的设计 -- 在不断使用它时请别忘了这点。如果更新内核或更改它在磁盘上的位置,不必重新安装 GRUB。事实上,如有必要,只要更新 menu.lst 文件即可,一切将保持正常。
只有少数情况下,才需要将 GRUB 引导装入器重新安装到引导记录。首先,如果更改 GRUB root 分区的分区类型(例如,从 ext2 改成 ReiserFS),则需要重新安装。或者,如果更新 /boot/grub 中的 stage1 和 stage2 文件,由于它们来自更新版本的 GRUB,很有可能要重新安装引导装入器。其它情况下,可以不必理睬!
ubuntu 10.10 以后的版本,如果修改了grub.cfg 文件,需要执行 update-grub 命令 才能起作用。
优秀的 GRUB 参考资料
我们在这里只是介绍了 GRUB 的一部分。例如,可以使用 GRUB 来执行网络引导,引导 BSD 文件系统,或更多操作。另外,GRUB 有许多配置和安全性命令也很有用。如需所有 GRUB 功能的完整描述,请阅读 GRUB 出色的 GNU 文档。只要在 bash 提示中输入 "info grub" 就可以阅读该文档。
希望您喜欢本教程,喜欢 GRUB (Grand Unified Boot Loader) 的强大功能和灵活性!
全面解析磁盘分区格式
当前越来越多的用户已经从Windows 98逐步升级到更高级的系统了,随之而来的就是必须面对Windows 98/2000/XP/2003等系统的FAT16/FAT32/NTFS磁盘分区 格式,它们到底是什么?有什么特点和优点?到底选择那种格式?如何建立的转换?如何解决使用中的各种问题? 本专题就是针对读者普通遇到的上述一系统问题,进行全方位的讨 当前越来越多的用户已经从Windows 98逐步升级到更高级的系统了,随之而来的就是必须面对windows 98/2000/XP/2003等系统的FAT16/FAT32/NTFS磁盘分区 格式,它们到底是什么?有什么特点和优点?到底选择那种格式?如何建立的转换?如何解决使用中的各种问题?
本专题就是针对读者普通遇到的上述一系统问题,进行全方位的讨论和分析。
解析磁盘、分区、文件系统
大部分读者都会经常听到诸如FAT/NTFS/CDFS等分区格式,实际上,由于不同的操作系统、不同的需求场合,存在有各种各样的分区格式,所以首先就让我们来看看这些分区格式的来龙去脉,了解它们的优缺点,根据应用需要选择好自己的分区格式方案!
在开始后面的话题前,先让我们来认识下面的对象:
1.磁盘
一般是从硬件(物理)角度来说的,它是通过磁介质存储数据的设备。包括我们常见的软盘、硬盘及不太常用的磁带盘等。另外,U盘及用内存虚拟的磁盘等虽然不是严格意义上的“磁盘”,但它们也可以使用同磁盘一样的文件系统。本文讨论的磁盘对象主要就是硬盘,这里包括普通的IDE接口和较高端的SCSI接口的硬盘,前者是大部分普通桌面用户所用的;后者多用于一些高端用户和服务器配置。不管什么接口,都属于本文的硬磁盘讨论范围。
2.分区
如我们大部分用户已经采用的方案那样,即我们的硬盘通常都会分成几个区,比如C区、D区、E区等等,其目的主要是为了更合理、有效地去保存数据,为文件安放提供更宽松的余地。我们现在所使用的PC(个人电脑)的硬盘,仍然沿用的是第一台PC硬盘所使用的分区原理,它由IBM的工程师设计,即一个硬盘只允许分为4个主分区,而其中的一个主分区可以分成若干逻辑分区,所以从理论上来说,我们的一个硬盘最多可分24个区(即从C区到Z区)。
3.文件系统
指文件命名、存储和组织的总体结构。例如Windows系列操作系统支持的FAT、FAT32 和 NTFS都是文件系统。其实文件系统也就是我们经常所说的“磁盘格式”或“分区格式”,总体都是一个概念,只不过“分区”只针对硬盘来说的,而文件系统是针对所有磁盘及存储介质的。所以大家应该明白,本专题讨论的其实也就是文件系统,只不过讨论的核心是针对硬磁盘而已。
小知识:什么是“簇”
文件占用磁盘空间时,基本单位不是字节而是簇。簇的大小与磁盘的规格有关,一般情况下,软盘每簇是1个扇区,硬盘每簇的扇区数与硬盘的总容量大小有关,可能是4、8、16、32、64……(如图1所示的每个簇占用4个扇区)。

图 1
同一个文件的数据并不一定完整地存放在磁盘的一个连续的区域内,而往往会分成若干段,像一条链子一样存放。这种存储方式称为文件的链式存储。硬盘上的文件常常要进行创建、删除、增长、缩短等操作。这样操作做的越多,盘上的文件就可能被分得越零碎(每段至少是1簇)。但是,由于硬盘上保存着段与段之间的连接信息(即FAT),操作系统在读取文件时,总是能够准确地找到各段的位置并正确读出。
不过,这种以簇为单位的存储法也是有其缺陷的。这主要表现在对空间的利用上。每个文件的最后一簇都有可能有未被完全利用的空间(称为尾簇空间)。一般来说,当文件个数比较多时,平均每个文件要浪费半个簇的空间。
文件系统大阅兵
1.FAT16
FAT的全称是“File Allocation Table”(文件分配表系统),FAT文件系统1982年开始应用于MS-DOS中。FAT文件系统主要的优点是它可以被多种操作系统访问,如MS-DOS、Windows所有系列和OS/2等。这一文件系统在使用时遵循8.3命名规则(即文件名最多为8个字符,扩展名为3个字符)。同时FAT文件系统无法支持系统高级容错特性,不具有内部安全特性等。
2.VFAT
在Windows 95中,通过对FAT文件系统的扩展,长文件名问题得到妥善解决,这也就是人们所谓的扩展FAT(VFAT)文件系统。它对FAT16文件系统进行扩展,并提供支持长文件名功能,文件名可长达255个字符,VFAT仍保留有扩展名,而且支持文件日期和时间属性,为每个文件保留了文件创建日期/时间、文件最近被修改的日期/时间和文件最近被打开的日期/时间这三项内容。
3.FAT32
FAT32是FAT16文件系统的派生,比 FAT16 支持更小的簇和更大的分区,这就使得 FAT32 分区的空间分配更有效率。FAT32主要应用于windows 98及后续Windows系统(实际从未正式发布的Windows 97,即OSR2就开始支持了),它可以增强磁盘性能并增加可用磁盘空间,同时也支持长文件名。
4.NTFS
NTFS(New Technology File System)是Microsoft Windows NT的标准文件系统,它也同时应用于Windows 2000/XP/2003。它与旧的FAT文件系统的主要区别是NTFS支持元数据(metadata),并且可以利用先进的数据结构提供更好的性能、稳定性和磁盘的利用率。NTFS有三个版本:在NT 3.51和NT 4中的1.2版,Windows 2000中的3.0版和windows xp中的3.1版。这些版本有时被提及为4.0版、5.0版和5.1版。更新的版本添加了额外的特性,比如windows 2000引入了配额。在兼容性方面,Windows的95/98/98SE和Me版都不能识别NTFS文件系统。
5.Ext2
这是Linux中使用最多的一种文件系统,是专门为Linux设计的,拥有最快的速度和最小的CPU占用率。现在已经有新一代的Linux文件系统如SGI公司的XFS、ReiserFS、ext3文件系统等出现。
分区格式大比拼
上文介绍了几种常见的文件系统,到底选择哪种文件系统?它们各自有什么优缺点?如何规划部署分区方案(包括分区数目、大小、格式类型)?
1.基本情况与功能支持
首先我们来看一下表1、2、3,它们从各个方面对NTFS/FAT32/FAT16的基本情况及支持的功能进行了综合比较。

表 1

表 2

表 3
2.文件系统优缺点
从表3中我们可以看到几个文件系统的优缺点。
3.选择何种文件系统?
普通用户在决定采用什么样的文件系统时应从以下几点出发:
1) 单一系统还是多启动的系统(即多操作系统);
2) 硬件平台;
3) 硬盘的大小与数量;
4) 安全性考虑。
在系统的安全性方面,NTFS文件系统具有很多FAT32/FAT16文件系统所不具备的特点,而且基于NTFS文件系统的windows 2000/XP/2003运行要快于基于FAT文件系统的;而在与Win 9X的兼容性方面,FAT优于NTFS。
如果要在windows 2000/XP/2003中使用大于32GB的分区的话,那么只能选择NTFS格式。但从另外一个角度来看,NTFS本身所需耗费的资源多于FAT的,所以如果格式化比较小的分区(低于512MB),建议使用FAT16。
正如微软专家建议那样,“除了多引导配置必须从非NTFS文件系统启动之外,建议用户用NTFS格式化所有的分区。” NTFS分区仅能通过Windows NT/2000/XP/2003进行访问。如果你的Windows 操作系统发生致命错误,你将无法简单地通过系统盘引导至命令行方式并解决NTFS分区上所出现的问题。为避免出现这种问题,建议在硬盘上安装第二套Windows操作系统,并通过这套操作系统来解决NTFS分区上所出现的问题。
表格说明:
●表1中的“最大容量”为理论值,“可实现最大分区容量”为目前OS可支持的最大容量;
●Windows NT必须先升级到server pack4或以上的版本才能识别FAT32和windows 2000/XP/2003的NTFS新版本文件系统;
●FAT32只是在理论上支持2TB的最大空间,在实现时,windows 98OSR2/ME 最大只能支持127.53GB,而windows 2000/XP/2003只支持32GB;
●16EB等于2~64字节,或等于16384TB;
●FAT16在windows 2000/XP/2003系统下可实现的最大格式化容量为4GB(可实现每簇最大容量64KB)
对于新买的或者需要重新分区的硬盘,我们可用以下的各种方法创建分区。
用DM快速分区格式化
在一分钟内把一个大硬盘重新分区并格式化完毕,你相信吗?在国内流行一种叫“DM万用版”的DM改进程序,它有令人惊叹的分区速度、对大容量硬盘的强有力支持、很好的硬盘适应性以及其它高级的综合能力,堪称最强大、最通用的硬盘初始化工具。有需要的读者可以到天极下载频道下载。下面来看看用DM创建分区的方法:
进入DM主界面后,将光标移到“dvanced Disk Installation”上,这时弹出一个二级菜单,在二级菜单上选择“(A)dvanced Disk Installation”进行分区的工作。这时会显示硬盘的列表,直接按回车键即可。
如果你有多个硬盘,回车后会让你选择需要对哪个硬盘进行分区工作。然后是分区格式的选择,你可以按照操作系统的需要进行选择,不过一般来说我们选择FAT32的分区格式。
选择“Windows 95/SOR2/98/98SE/Me/2000,(FAT 16 OR 32)”,接下来是一个确认是否使用FAT32的窗口,选中“YES”后,单击回车键,弹出一个新的窗口,这里可以进行分区大小的选择。DM提供了一些自动的分区方式让你选择,如果你需要按照自己的意愿进行分区,请选择“OPTION (C) Define your own”并回车。
在图2中,我们对主分区的容量进行分配。完成分区数值的设定后,会显示最后分区详细的结果。此时如果对分区不满意,还可以通过下面一些提示的按键进行调整。例如“Del”键删除分区,“N”键建立新的分区。

图 2
设定完成后要选择“Save and Continue”保存设置的结果,此时会出现提示窗口,再次确认所做的设置,如果确认无误后按“Alt+C”继续,否则按任意键回到主菜单。接下出现询问是否进行快速格式化的提示窗口,除非硬盘有问题,否则建议选择“(Y)ES”,并按回车键。接着在出现以询问分区是否按照默认簇进行的提示窗口中,选择“(Y)ES”继续。选择“(Y)ES”选项,并按回车键,出现最终确认的窗口,选择确认即可开始分区的工作。
此时DM就开始分区的工作,速度很快,一会儿就可以完成。完成分区工作后会出现一个提示窗口,可以按任意键继续进行操作。下面就会出现重新启动的提示。这样就完成了硬盘分区工作,虽然我们在这里介绍的步骤比较多,但实际上有几次操作的经验后会很熟练的。
用FDISK与FORMAT分区及格式化
FDISK 是一个基于DOS用于管理DOS分区的程序,一般的windows 98启动盘都包含这个程序。用软盘启动到纯DOS命令行状态,输入一个简单的命令:FDISK便可运行。
如果硬盘大于2GB,将会看到一个说明界面,选择“Y”则使用FAT32格式分区,选择“N”则使用FAT16格式进行分区。然后会出现如图3所示的FDISK主界面。从这个界面中,你可以创建分区、激活分区、删除主分区与逻辑分区和查看分区信息。下面重点来看看如何创建分区。

图 3
你可以在硬盘中未用的、未格式化过的区域中任意创建主分区与扩展分区。在扩展分区中,可以创建逻辑分区。但如果使用的是FAT16格式,则最大只能创建2GB的分区。
建立硬盘分区的规则是:建立基本分区→建立扩展分区→再分成1~X个逻辑驱动器。因此建立分区必须严格按照1→2→3的顺序进行。
提示:这里我们假设硬盘是从未格式化过的,如果已经有分区了,则必须先删除后再重新进行创建。
在图3中输入“1”,回车,出现如图4所示界面。

图 4
输入“1”,回车,创建主分区。主分区将被标志为C盘。
程序提示是否要将整个硬盘的大小都作为主分区,界面如图5所示。输入“N”,回车, 然后会出现主分区容量设置界面(如图6),我们在输入框中输入欲分配C盘的容量大小,比如输入2000(单位MB),回车确认。

图 5

图 6
完成后会出现主分区分配情况界面,按“Esc”键返回到FDISK主菜单(如图3),输入“1”再次进入图4所示界面。输入“2”,创建扩展分区,出现如图7所示界面。(注:逻辑分区是建立在扩展分区之上的,必须先创建扩展分区,再创建逻辑分区。)

图 7
在图7界面中输入扩展分区的大小,这里一般将主分区外的所有剩余空间都分配给扩展分区,比如本例中的48000MB。回车确认后出现主分区和扩展分区的容量分配比例界面。然后按“Esc”键,出现如图8所示界面。

图 8
在图8中输入第一个逻辑分区的大小(例如15000MB),回车确认,出现如图9所示界面。

图 9
图9显示的是第二个逻辑分区的容量设置情况,在这个界面可看到第一个逻辑分区(D盘)的容量和比例。界面出现后,在右下角输入框里输入第二个逻辑分区的大小(比如33000MB),回车确认,再按“Esc”退回FDISK主菜单(图3),输入“2”,回车,出现如图11所示界面。
提示:在本例中,总共50000MB的磁盘,主分区分了2000MB,扩展分区48000MB,第一个逻辑分区15000MB,第二个逻辑分区33000MB,如果第二个逻辑分区没有分配完剩余的扩展分区空间的话,还会反复出现图9的界面,直到扩展分区空间被分完为止。
开机自检,BIOS运行原理
首先必须明确的一点是, BIOS 运行初期,CPU 其实是不能访问内存的。
BIOS 所在的 FLASH 是那种可以被 CPU 直接寻址的 FLASH 芯片。被都固定在0x4FFFF (记不清具体地址了) 地址上了。类似 ARM 使用的 NOR FLASH。 uboot就在 NOR FLASH上。
然后,BIOS 初始化代码开始通过寄存器和北桥芯片沟通。
因为 BIOS 就是版卡厂商制作的,这不成问题。使用固化的 IO 地址就可以了。
成功和北桥联系上后, BIOS 继续前进,利用北桥提供的寄存器操控SMBUS, SMBUS是一种 I2C 总线,每个 SMBUS 设备都有一个固定的地址。SDRAM 的 EEPROM 就可以通过 SMBUS 访问! 而 SDRAM 通常在 0×50 ~ 0×53 这4个地址上,对于主板上的4个内存插槽。不过,主板厂商也可以改变这些地址。反正 BIOS 是自己出的,可以固化这些地址,无所谓。
读取 SDRAM eeprom 里超过 17 个参数后。 BIOS 就可以使用这些参数设置好北桥的寄存器了。而在这之前, BIOS 严重依赖 CPU 的寄存器做这些操作,不能使用任何内存! 北桥用来控制内存的寄存器地址,又是一个每个版卡都不一样的地方了。无所谓, BIOS 自己出,爱怎么用就怎么用。
搞定内存之后, BIOS 终于可以使用内存啦! BIOS 将内存的前 4k 作为临时stack 开始进入了第二步初始化,这个使用有了内存,就可以使用函数了。
前面,因为无法使用内存,无法进行复杂的运算,要小心编写汇编指令,全部使用寄存器进行操作,所以没法进行复杂的运算。现在有 RAM 可以用了,自然就有内存了。
BIOS 通过检查可用的内存值,将自己使用的临时 stack 移步到 > 640K 的地方。 开始继续下面的工作。
下面, BIOS 该开始检测 CPU 了。主要的工作是比较 CPU 的微代码版本是否和BIOS 里带的对应CPU的代码一致。否则更新 CPU 的微代码。所以刷新 BIOS 支持新 CPU 的道理就在这里!
再然后?那要看你是不是打开了 BIOS shadow 就会选择是不是做这一步了。
注意,这个时候 BIOS 是在一片能被 CPU 直接寻址的 FLASH 里运行的。但是FLASH毕竟比 SDRAM 慢.所以, BIOS 会通过北桥重新映射 BIOS FLASH 的地址到内存空间的顶端,原有的映射没有断开!这个时候由于 A20 gate 没有打开,高 12 位被忽略,导致 CPU寻址仍然在 640k ~ 1M,也就是 BIOS 现在在的地址,所以 BIOS 继续运行。
这个时候 BIOS 切换到 32 位寻址,注意,是 32位寻址,但是还是 16 位 模式。
想知道详细情况的,可以自己网上 google . 因为先前已经映射好了 BIOS 到高位内存,所以 BIOS 继续运行。 然后 BIOS 将原先自己所在的 6040k~1M 地址区间通过操作北桥,断开映射!是的,没错,断开了! 这个时候,这个区间其实就是RAM 而不再是 BIOS ROM 了,这个很重要!接着打开 A20。
接下来就是很平常的 memcpy 了,将自己从高位内存拷贝回 640k ~1M 区间的地位内存。 然后关闭 A20. 关闭 A20 后, CPU 寻址重新回到低位内存。 BIOS 完成了将自己拷贝到同一个地址的工作. 但是 BIOS 将运行在 SDRAM 中,而不是FLASH 里。
然后干嘛呢? 自然是继续检测基本硬件啦。基本硬件一般都已经固定使用某个 IO端口了。 BIOS 就是发送一个无害的请求看是否有返回就可以知道硬件在不在。
对于显卡和网卡这类设备, BIOS 并不包括这些设备的初始化代码, BIOS 通过调用这些设备的 BIOS 来实现。
对于任何找到的 PCI 设备,BIOS 都是直接调用对应 BIOS 设备的 BIOS 来初始化它的 。 这也是硬盘还原卡截获 init 13 中断的道理。
而这些设备的 BIOS,自然初始化工作就是配置设备的寄存器地址了。
BIOS 搞定的 PCI 设备,会形成一个表格,叫 PCI CONFIG ,保存到 PCI 控制器里 。可以通过 IO 端口 0xCFC-0xCFF 访问。
对于集成设备,这些设备的 BIOS 其实都被包含在 system BIOS 里,但是逻辑上并不是一个整体。如果用一些 BIOS 工具,还是可以分离各个设备的 BIOS 的。
没用 BIOS 将设备配置好,并写入 PCI config , Linux 内核就会当这个设备不存在 … 囧。
还有,各个 PCI 设备除了几个基本寄存器,别的都是通过 MMIO 映射到内存地址里进行的,而不是使用 IO 端口地址。BIOS 要负责分配好,使他们不会重叠。
PCI 设备的地址从 0xFFFFFFFF- sizeof (BIOS) 开始向下分配,SDRAM 的地址从0×00000000 开始向上分配。这些都是通过操作北桥的寄存器实现的。
自然,他们会在中间形成一个洞。不过,那是在你 SDRAM 内存比较少的情况下 …..
如果你的 SDRAM 内存比较多,恭喜你,你又遇到问题了,你的内存将被吞掉一部分 …. 被 PCI 设备覆盖掉了一部分高位内存… 对 CPU 而言,整个内存地址都充满了设备咯,没有空洞。
其实 Linux 认为的 640k~1MB 空洞也是不存在的。如果后续不使用 BIOS , 可以放心的当 SDRAM 来用,因为就是 SDRAM . 自然,如果你没有开启 BIOS shadow就另当别论了。
我之所以接触 Linux , 也是我本来计划自己写系统,我很讨厌 640K~1M 的内存空洞,想知道怎么解决,就去看别的 OS 是怎么实现的,结果就发现了 Linux ,然后开始看 ….
不过后来比较囧的是, Linux 确实没有利用这个区间的 RAM … 真 TMD 有点浪费啊! 现代的 BIOS 都默认 shadow 了,甚至没有地方给你配置了。 如果 Linux不使用 BIOS , 不知道留这个洞在这里干嘛. 诶。
其实我 google 了 lkml , 是有人这么提出过这个问题。不过那个 Grek H 什么的,就是貌似的Linux二号or三号人物,回的邮件里说,虽然多数系统可以回收这个空洞,不过在个别系统上报告问题了。所以就默认不回收了。如果你要回收,这里有 patch … use at your own risk ….
分类: LINUX
diff是Unix系统的一个很重要的工具程序。
它用来比较两个文本文件的差异,是代码版本管理的基石之一。你在命令行下,输入:
$ diff <变动前的文件> <变动后的文件>
diff就会告诉你,这两个文件有何差异。它的显示结果不太好懂,下面我就来说明,如何读懂diff。

一、diff的三种格式
由于历史原因,diff有三种格式:
* 正常格式(normal diff)
* 上下文格式(context diff)
* 合并格式(unified diff)
我们依次来看。
二、示例文件
为了便于讲解,先新建两个示例文件。
第一个文件叫做f1,内容是每行一个a,一共7行。
a
a
a
a
a
a
a
第二个文件叫做f2,修改f1而成,第4行变成b,其他不变。
a
a
a
b
a
a
a
三、正常格式的diff
现在对f1和f2进行比较:
$ diff f1 f2
这时,diff就会显示正常格式的结果:
4c4
< a
---
> b
第一行是一个提示,用来说明变动位置。
4c4
它分成三个部分:前面的"4",表示f1的第4行有变化;中间的"c"表示变动的模式是内容改变(change),其他模式还有"增加"(a,代表addition)和"删除"(d,代表deletion);后面的"4",表示变动后变成f2的第4行。
第二行分成两个部分。
< a
前面的小于号,表示要从f1当中去除该行(也就是第4行),后面的"a"表示该行的内容。
第三行用来分割f1和f2。
---
第四行,类似于第二行。
> b
前面的大于号表示f2增加了该行,后面的"b"表示该行的内容。
最早的Unix(即AT&T版本的Unix),使用的就是这种格式的diff。
四、上下文格式的diff
上个世纪80年代初,加州大学伯克利分校推出BSD版本的Unix时,觉得diff的显示结果太简单,最好加入上下文,便于了解发生的变动。因此,推出了上下文格式的diff。
它的使用方法是加入c参数(代表context)。
$ diff -c f1 f2
显示结果如下:
*** f1 2012-08-29 16:45:41.000000000 +0800
--- f2 2012-08-29 16:45:51.000000000 +0800
***************
*** 1,7 ****
a
a
a
!a
a
a
a
--- 1,7 ----
a
a
a
!b
a
a
a
这个结果分成四个部分。
第一部分的两行,显示两个文件的基本情况:文件名和时间信息。
*** f1 2012-08-29 16:45:41.000000000 +0800
--- f2 2012-08-29 16:45:51.000000000 +0800
"***"表示变动前的文件,"---"表示变动后的文件。
第二部分是15个星号,将文件的基本情况与变动内容分割开。
***************
第三部分显示变动前的文件,即f1。
*** 1,7 ****
a
a
a
!a
a
a
a
这时不仅显示发生变化的第4行,还显示第4行的前面三行和后面三行,因此一共显示7行。所以,前面的"*** 1,7 ****"就表示,从第1行开始连续7行。
另外,文件内容的每一行最前面,还有一个标记位。如果为空,表示该行无变化;如果是感叹号(!),表示该行有改动;如果是减号(-),表示该行被删除;如果是加号(+),表示该行为新增。
第四部分显示变动后的文件,即f2。
--- 1,7 ----
a
a
a
!b
a
a
a
除了变动行(第4行)以外,也是上下文各显示三行,总共显示7行。
五、合并格式的diff
如果两个文件相似度很高,那么上下文格式的diff,将显示大量重复的内容,很浪费空间。1990年,GNU diff率先推出了"合并格式"的diff,将f1和f2的上下文合并在一起显示。
它的使用方法是加入u参数(代表unified)。
$ diff -u f1 f2
显示结果如下:
--- f1 2012-08-29 16:45:41.000000000 +0800
+++ f2 2012-08-29 16:45:51.000000000 +0800
@@ -1,7 +1,7 @@
a
a
a
-a
+b
a
a
a
它的第一部分,也是文件的基本信息。
--- f1 2012-08-29 16:45:41.000000000 +0800
+++ f2 2012-08-29 16:45:51.000000000 +0800
"---"表示变动前的文件,"+++"表示变动后的文件。
第二部分,变动的位置用两个@作为起首和结束。
@@ -1,7 +1,7 @@
前面的"-1,7"分成三个部分:减号表示第一个文件(即f1),"1"表示第1行,"7"表示连续7行。合在一起,就表示下面是第一个文件从第1行开始的连续7行。同样的,"+1,7"表示变动后,成为第二个文件从第1行开始的连续7行。
第三部分是变动的具体内容。
a
a
a
-a
+b
a
a
a
除了有变动的那些行以外,也是上下文各显示3行。它将两个文件的上下文,合并显示在一起,所以叫做"合并格式"。每一行最前面的标志位,空表示无变动,减号表示第一个文件删除的行,加号表示第二个文件新增的行。
六、git格式的diff
版本管理系统git,使用的是合并格式diff的变体。
$ git diff
显示结果如下:
diff --git a/f1 b/f1
index 6f8a38c..449b072 100644
--- a/f1
+++ b/f1
@@ -1,7 +1,7 @@
a
a
a
-a
+b
a
a
a
第一行表示结果为git格式的diff。
diff --git a/f1 b/f1
进行比较的是,a版本的f1(即变动前)和b版本的f1(即变动后)。
第二行表示两个版本的git哈希值(index区域的6f8a38c对象,与工作目录区域的449b072对象进行比较),最后的六位数字是对象的模式(普通文件,644权限)。
index 6f8a38c..449b072 100644
第三行表示进行比较的两个文件。
--- a/f1
+++ b/f1
"---"表示变动前的版本,"+++"表示变动后的版本。
后面的行都与官方的合并格式diff相同。
@@ -1,7 +1,7 @@
a
a
a
-a
+b
a
a
a
七、阅读材料
* diff - Wikipedia
* How to read a patch or diff
* How to work with diff representation in git
(完)
本文转自http://www.ruanyifeng.com/blog/2012/08/how_to_read_diff.html
- shell
- shell
- shell
- shell
- shell
- Shell
- shell
- Shell
- shell
- shell
- SHELL
- Shell
- shell
- shell
- shell
- shell
- shell
- shell
- 分布式全文检索系统SolrCloud简介
- ubuntu16.04安装ibus中文输入法
- ubuntu16.04下安装php7.0
- Unity 简单总结
- ios-OPENGL之绘制天空盒
- shell
- Google Gson - deserialize list<class> object
- Java线程和多线程(十二)——线程池基础
- javascript函数定义
- shell
- 数据结构--树的同构
- attachEvent 与addEventListener到底有什么区别呢
- javascript函数重载
- spring事物注解配置


