字符识别opencv c++版
来源:互联网 发布:淘宝上新产品如何运营 编辑:程序博客网 时间:2024/05/21 18:37
虽然特征抓取比起Opencv所带字符识别特征量少很多,但是还是有借鉴意义。
// 获取垂直和水平方向直方图
Mat ProjectedHistogram(Mat img, int t)
{
int sz=(t)?img.rows:img.cols;
Mat mhist=Mat::zeros(1,sz,CV_32F);
for(int j=0; j<sz; j++){
Mat data=(t)?img.row(j):img.col(j);
mhist.at<float>(j)=countNonZero(data);
}
//Normalize histogram
double min, max;
minMaxLoc(mhist, &min, &max);
if(max>0)
mhist.convertTo(mhist,-1 , 1.0f/max, 0);
return mhist;
}
//获得特征
Mat features(Mat in, int sizeData)
{
//Histogram features
Mat vhist=ProjectedHistogram(in,VERTICAL);
Mat hhist=ProjectedHistogram(in,HORIZONTAL);
//Low data feature
Mat lowData;
resize(in, lowData, Size(sizeData, sizeData) );
//Last 10 is the number of moments components
int numCols=vhist.cols+hhist.cols+lowData.cols*lowData.cols;
Mat out=Mat::zeros(1,numCols,CV_32F);
int j=0;
for(int i=0; i<vhist.cols; i++)
{
out.at<float>(j)=vhist.at<float>(i);
j++;
}
for(int i=0; i<hhist.cols; i++)
{
out.at<float>(j)=hhist.at<float>(i);
j++;
}
for(int x=0; x<lowData.cols; x++)
{
for(int y=0; y<lowData.rows; y++){
out.at<float>(j)=(float)lowData.at<unsigned char>(x,y);
j++;
}
}
//if(DEBUG)
// cout << out << "\n===========================================\n";
return out;
}
layers.at<int>(0) = TrainingData.cols;
layers.at<int>(1) = _neurons;
layers.at<int>(2) = numCharacter;
ann.create(layers, CvANN_MLP::SIGMOID_SYM, 1, 1);

平均正确率0.924876,最低正确率0.697436
交叉训练,特征维度5,神网层数40
平均正确率0.929420,最低正确率0.706840
交叉训练,特征维度5,神网层数60
平均正确率0.910902,最低正确率0.684524
交叉训练,特征维度5,神网层数80
平均正确率0.946602,最低正确率0.724638
交叉训练,特征维度5,神网层数100
平均正确率0.863204,最低正确率0.000000
交叉训练,特征维度5,神网层数120
平均正确率0.630426,最低正确率0.000000
交叉训练,特征维度5,神网层数140
平均正确率0.670202,最低正确率0.000000
交叉训练,特征维度5,神网层数160
平均正确率0.579037,最低正确率0.000000
交叉训练,特征维度10,神网层数20
平均正确率0.905349,最低正确率0.718750
交叉训练,特征维度10,神网层数40
平均正确率0.759788,最低正确率0.541284
交叉训练,特征维度10,神网层数60
平均正确率0.940838,最低正确率0.620438
交叉训练,特征维度10,神网层数80
平均正确率0.898533,最低正确率0.627737
交叉训练,特征维度10,神网层数100
平均正确率0.723310,最低正确率0.000000
交叉训练,特征维度10,神网层数120
平均正确率0.668532,最低正确率0.000000
交叉训练,特征维度10,神网层数140
平均正确率0.663412,最低正确率0.000000
交叉训练,特征维度10,神网层数160
平均正确率0.713898,最低正确率0.000000
交叉训练,特征维度15,神网层数20
平均正确率0.668120,最低正确率0.043796
交叉训练,特征维度15,神网层数40
平均正确率0.821110,最低正确率0.587302
交叉训练,特征维度15,神网层数60
平均正确率0.717837,最低正确率0.000000
交叉训练,特征维度15,神网层数80
平均正确率0.740954,最低正确率0.509434
交叉训练,特征维度15,神网层数100
平均正确率0.691856,最低正确率0.000000
交叉训练,特征维度15,神网层数120
平均正确率0.653666,最低正确率0.000000
交叉训练,特征维度15,神网层数140
平均正确率0.642795,最低正确率0.000000
交叉训练,特征维度15,神网层数160
平均正确率0.676031,最低正确率0.000000
交叉训练,特征维度20,神网层数20
平均正确率0.651077,最低正确率0.029762
交叉训练,特征维度20,神网层数40
平均正确率0.731983,最低正确率0.000000
交叉训练,特征维度20,神网层数60
平均正确率0.704698,最低正确率0.000000
交叉训练,特征维度20,神网层数80
平均正确率0.747636,最低正确率0.000000
交叉训练,特征维度20,神网层数100
平均正确率0.790314,最低正确率0.000000
交叉训练,特征维度20,神网层数120
平均正确率0.726250,最低正确率0.009434
交叉训练,特征维度20,神网层数140
平均正确率0.679839,最低正确率0.000000
交叉训练,特征维度20,神网层数160
平均正确率0.650891,最低正确率0.000000
代码:http://pan.baidu.com/s/1hqvNmg0
mnist文件:http://pan.baidu.com/s/1kTuviAz http://pan.baidu.com/s/1qWoLuPI
原文地址:http://www.cnblogs.com/jsxyhelu/p/4306753.html
简要介绍
OpenCV的人工神经网络是机器学习算法中的其中一种,使用的是多层感知器(Multi- Layer Perception,MLP),是常见的一种ANN算法。MLP算法一般包括三层,分别是一个输入层,一个输出层和一个或多个隐藏层的神经网络组成。每一层由一个或多个神经元互相连结。一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图是一个简单3层的神经元感知器:(3个输入,2个输出以及包含5个神经元的隐藏层)

MLP算法中,每个神经元都有几个输入和输出神经元,每个神经元通过输入权重加上偏置计算输出值,并选择一种激励函数进行转换。 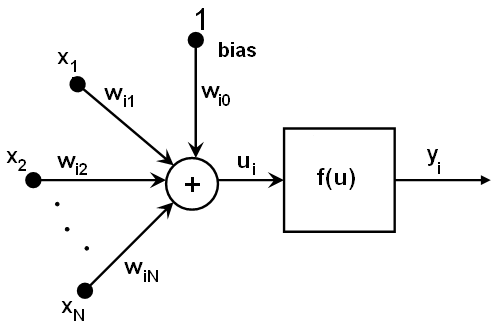
激励函数常见的有三种,分别是恒等函数,Sigmoid函数和高斯函数,OpenCV默认的是Sigmoid函数。Sigmoid函数的公式 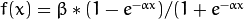
下图是Sigmoid函数的alpha参数和Beta参数为1的图像。 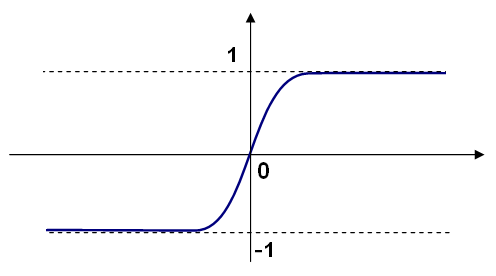
OpenCV中的MLP
OpenCV中的ANN算法通过训练来计算和学习更新每一层的权重,突触以及神经元。为了训练出分类器,需要创建两个数据矩阵,一个是特征数据矩阵,一个是标签矩阵。但要注意的是标签矩阵是一个N*M的矩阵,N表示训练样本数,M是类标签。如果第i行的样本属于第j类,那么该标签矩阵的(i,j)位置为1。
OpenCV中ANN定义了CvANN_MLP类。使用ANN算法之前,必须先初始化参数,比如神经网络的层数、神经元数,激励函数、α和β。然后使用train函数进行训练,训练完成可以训练好的参数以xml的格式保存在本地文件夹。最后就可以使用predict函数来预测识别。
OpenCV ANN的数字识别的例子
#include "stdafx.h"#include <opencv2/opencv.hpp>#include <iostream>#include <fstream>#include <sstream>#include <math.h>#include <vector>#include <windows.h>#include <io.h>#include <time.h>using namespace cv;using namespace std;#define HORIZONTAL 1#define VERTICAL 0CvANN_MLP ann;const char strCharacters[] = { '0','1','2','3','4','5',\'6','7','8','9'};const int numCharacter = 10; const int numNeurons = 40;const int predictSize = 10;void generateRandom(int n, int test_num, int min, int max, vector<int>*mark_samples){ int range = max - min; int index = rand() % range + min; if (mark_samples->at(index) == 0) { mark_samples->at(index) = 1; n++; } if (n < test_num) generateRandom(n, test_num, min, max, mark_samples);}vector<string> getFiles(const string &folder, const bool all /* = true */) { vector<string> files; list<string> subfolders; subfolders.push_back(folder); while (!subfolders.empty()) { string current_folder(subfolders.back()); if (*(current_folder.end() - 1) != '/') { current_folder.append("/*"); } else { current_folder.append("*"); } subfolders.pop_back(); struct _finddata_t file_info; long file_handler = _findfirst(current_folder.c_str(), &file_info); while (file_handler != -1) { if (all && (!strcmp(file_info.name, ".") || !strcmp(file_info.name, ".."))) { if (_findnext(file_handler, &file_info) != 0) break; continue; } if (file_info.attrib & _A_SUBDIR) { // it's a sub folder if (all) { // will search sub folder string folder(current_folder); folder.pop_back(); folder.append(file_info.name); subfolders.push_back(folder.c_str()); } } else { // it's a file string file_path; // current_folder.pop_back(); file_path.assign(current_folder.c_str()).pop_back(); file_path.append(file_info.name); files.push_back(file_path); } if (_findnext(file_handler, &file_info) != 0) break; } // while _findclose(file_handler); } return files;}void AppendText(string filename, string text){ fstream ftxt; ftxt.open(filename, ios::out | ios::app); if (ftxt.fail()) { cout << "创建文件失败!" << endl; getchar(); } ftxt << text << endl; ftxt.close();}// !获取垂直和水平方向直方图Mat ProjectedHistogram(Mat img, int t){ int sz = (t) ? img.rows : img.cols; Mat mhist = Mat::zeros(1, sz, CV_32F); for (int j = 0; j<sz; j++) { Mat data = (t) ? img.row(j) : img.col(j); mhist.at<float>(j) = countNonZero(data); //统计这一行或一列中,非零元素的个数,并保存到mhist中 } //Normalize histogram double min, max; minMaxLoc(mhist, &min, &max); if (max>0) mhist.convertTo(mhist, -1, 1.0f / max, 0);//用mhist直方图中的最大值,归一化直方图 return mhist;}Mat features(Mat in, int sizeData){ //Histogram features Mat vhist = ProjectedHistogram(in, VERTICAL); Mat hhist = ProjectedHistogram(in, HORIZONTAL); //Low data feature Mat lowData; resize(in, lowData, Size(sizeData, sizeData)); //Last 10 is the number of moments components int numCols = vhist.cols + hhist.cols + lowData.cols*lowData.cols; //int numCols = vhist.cols + hhist.cols; Mat out = Mat::zeros(1, numCols, CV_32F); //Asign values to feature,ANN的样本特征为水平、垂直直方图和低分辨率图像所组成的矢量 int j = 0; for (int i = 0; i<vhist.cols; i++) { out.at<float>(j) = vhist.at<float>(i); j++; } for (int i = 0; i<hhist.cols; i++) { out.at<float>(j) = hhist.at<float>(i); j++; } for (int x = 0; x<lowData.cols; x++) { for (int y = 0; y<lowData.rows; y++) { out.at<float>(j) = (float)lowData.at<unsigned char>(x, y); j++; } } //if(DEBUG) // cout << out << "\n===========================================\n"; return out;}void annTrain(Mat TrainData, Mat classes, int nNeruns){ ann.clear(); Mat layers(1, 3, CV_32SC1); layers.at<int>(0) = TrainData.cols; layers.at<int>(1) = nNeruns; layers.at<int>(2) = numCharacter; ann.create(layers, CvANN_MLP::SIGMOID_SYM, 1, 1); //Prepare trainClases //Create a mat with n trained data by m classes Mat trainClasses; trainClasses.create(TrainData.rows, numCharacter, CV_32FC1); for (int i = 0; i < trainClasses.rows; i++) { for (int k = 0; k < trainClasses.cols; k++) { //If class of data i is same than a k class if (k == classes.at<int>(i)) trainClasses.at<float>(i, k) = 1; else trainClasses.at<float>(i, k) = 0; } } Mat weights(1, TrainData.rows, CV_32FC1, Scalar::all(1)); //Learn classifier // ann.train( TrainData, trainClasses, weights ); //Setup the BPNetwork // Set up BPNetwork's parameters CvANN_MLP_TrainParams params; params.train_method = CvANN_MLP_TrainParams::BACKPROP; params.bp_dw_scale = 0.1; params.bp_moment_scale = 0.1; //params.train_method=CvANN_MLP_TrainParams::RPROP; // params.rp_dw0 = 0.1; // params.rp_dw_plus = 1.2; // params.rp_dw_minus = 0.5; // params.rp_dw_min = FLT_EPSILON; // params.rp_dw_max = 50.; ann.train(TrainData, trainClasses, Mat(), Mat(), params);}int recog(Mat features){ int result = -1; Mat Predict_result(1, numCharacter, CV_32FC1); ann.predict(features, Predict_result); Point maxLoc; double maxVal; minMaxLoc(Predict_result, 0, &maxVal, 0, &maxLoc); return maxLoc.x;}float ANN_test(Mat samples_set, Mat sample_labels){ int correctNum = 0; float accurate = 0; for (int i = 0; i < samples_set.rows; i++) { int result = recog(samples_set.row(i)); if (result == sample_labels.at<int>(i)) correctNum++; } accurate = (float)correctNum / samples_set.rows; return accurate;}int saveTrainData(){ cout << "Begin saveTrainData" << endl; Mat classes; Mat trainingDataf5; Mat trainingDataf10; Mat trainingDataf15; Mat trainingDataf20; vector<int> trainingLabels; string path = "charSamples"; for (int i = 0; i < numCharacter; i++) { cout << "Character: " << strCharacters[i] << "\n"; stringstream ss(stringstream::in | stringstream::out); ss << path << "/" << strCharacters[i]; auto files = getFiles(ss.str(),1); int size = files.size(); for (int j = 0; j < size; j++) { cout << files[j].c_str() << endl; Mat img = imread(files[j].c_str(), 0); Mat f5 = features(img, 5); Mat f10 = features(img, 10); Mat f15 = features(img, 15); Mat f20 = features(img, 20); trainingDataf5.push_back(f5); trainingDataf10.push_back(f10); trainingDataf15.push_back(f15); trainingDataf20.push_back(f20); trainingLabels.push_back(i); //每一幅字符图片所对应的字符类别索引下标 } } trainingDataf5.convertTo(trainingDataf5, CV_32FC1); trainingDataf10.convertTo(trainingDataf10, CV_32FC1); trainingDataf15.convertTo(trainingDataf15, CV_32FC1); trainingDataf20.convertTo(trainingDataf20, CV_32FC1); Mat(trainingLabels).copyTo(classes); FileStorage fs("train/features_data.xml", FileStorage::WRITE); fs << "TrainingDataF5" << trainingDataf5; fs << "TrainingDataF10" << trainingDataf10; fs << "TrainingDataF15" << trainingDataf15; fs << "TrainingDataF20" << trainingDataf20; fs << "classes" << classes; fs.release(); cout << "End saveTrainData" << endl; return 0;}void ANN_Cross_Train_and_Test(int Imagsize, int Layers ){ String training; Mat TrainingData; Mat Classes; FileStorage fs; fs.open("train/features_data.xml", FileStorage::READ); cout << "Begin to ANN_Cross_Train_and_Test " << endl; char *txt = new char[50]; sprintf(txt, "交叉训练,特征维度%d,网络层数%d", 40 + Imagsize * Imagsize, Layers); AppendText("output.txt", txt); cout << txt << endl; stringstream ss(stringstream::in | stringstream::out); ss << "TrainingDataF" << Imagsize; training = ss.str(); fs[training] >> TrainingData; fs["classes"] >> Classes; fs.release(); float result = 0.0; srand(time(NULL)); vector<int> markSample(TrainingData.rows, 0); generateRandom(0, 100, 0, TrainingData.rows - 1, &markSample); Mat train_set, train_labels; Mat sample_set, sample_labels; for (int i = 0; i < TrainingData.rows; i++) { if (markSample[i] == 1) { sample_set.push_back(TrainingData.row(i)); sample_labels.push_back(Classes.row(i)); } else { train_set.push_back(TrainingData.row(i)); train_labels.push_back(Classes.row(i)); } } annTrain(train_set, train_labels, Layers); result = ANN_test(sample_set, sample_labels); sprintf(txt, "正确率%f\n", result); cout << txt << endl; AppendText("output.txt", txt); cout << "End the ANN_Cross_Train_and_Test" << endl; cout << endl;}void ANN_test_Main(){ int DigitSize[4] = { 5, 10, 15, 20}; int LayerNum[14] = { 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 120, 150, 200, 500 }; for (int i = 0; i < 4; i++) { for (int j = 0; j < 14; j++) { ANN_Cross_Train_and_Test(DigitSize[i], LayerNum[j]); } }}void ANN_saveModel(int _predictsize, int _neurons){ FileStorage fs; fs.open("train/features_data.xml", FileStorage::READ); Mat TrainingData; Mat Classes; string training; if (1) { stringstream ss(stringstream::in | stringstream::out); ss << "TrainingDataF" << _predictsize; training = ss.str(); } fs[training] >> TrainingData; fs["classes"] >> Classes; //train the Ann cout << "Begin to saveModelChar predictSize:" << _predictsize << " neurons:" << _neurons << endl; annTrain(TrainingData, Classes, _neurons); cout << "End the saveModelChar" << endl; string model_name = "train/ann10_40.xml"; //if(1) //{ // stringstream ss(stringstream::in | stringstream::out); // ss << "ann_prd" << _predictsize << "_neu"<< _neurons << ".xml"; // model_name = ss.str(); //} FileStorage fsTo(model_name, cv::FileStorage::WRITE); ann.write(*fsTo, "ann");}int main(){ cout << "To be begin." << endl; saveTrainData(); //ANN_saveModel(10, 40); ANN_test_Main(); cout << "To be end." << endl; int end; cin >> end; return 0;}程序运行的结果为:
交叉训练,特征维度65,网络层数10正确率1.000000交叉训练,特征维度65,网络层数20正确率1.000000交叉训练,特征维度65,网络层数30正确率1.000000交叉训练,特征维度65,网络层数40正确率0.990000交叉训练,特征维度65,网络层数50正确率0.990000交叉训练,特征维度65,网络层数60正确率0.990000交叉训练,特征维度65,网络层数70正确率0.980000交叉训练,特征维度65,网络层数80正确率0.990000交叉训练,特征维度65,网络层数90正确率1.000000交叉训练,特征维度65,网络层数100正确率1.000000交叉训练,特征维度65,网络层数120正确率0.990000交叉训练,特征维度65,网络层数150正确率1.000000交叉训练,特征维度65,网络层数200正确率1.000000交叉训练,特征维度65,网络层数500正确率0.870000交叉训练,特征维度140,网络层数10正确率0.990000交叉训练,特征维度140,网络层数20正确率1.000000交叉训练,特征维度140,网络层数30正确率1.000000交叉训练,特征维度140,网络层数40正确率1.000000交叉训练,特征维度140,网络层数50正确率0.990000交叉训练,特征维度140,网络层数60正确率1.000000交叉训练,特征维度140,网络层数70正确率1.000000交叉训练,特征维度140,网络层数80正确率0.920000交叉训练,特征维度140,网络层数90正确率0.920000交叉训练,特征维度140,网络层数100正确率0.850000交叉训练,特征维度140,网络层数120正确率1.000000交叉训练,特征维度140,网络层数150正确率0.750000交叉训练,特征维度140,网络层数200正确率0.990000交叉训练,特征维度140,网络层数500正确率0.880000交叉训练,特征维度265,网络层数10正确率1.000000交叉训练,特征维度265,网络层数20正确率0.990000交叉训练,特征维度265,网络层数30正确率1.000000交叉训练,特征维度265,网络层数40正确率1.000000交叉训练,特征维度265,网络层数50正确率1.000000交叉训练,特征维度265,网络层数60正确率1.000000交叉训练,特征维度265,网络层数70正确率1.000000交叉训练,特征维度265,网络层数80正确率1.000000交叉训练,特征维度265,网络层数90正确率1.000000交叉训练,特征维度265,网络层数100正确率0.920000交叉训练,特征维度265,网络层数120正确率1.000000交叉训练,特征维度265,网络层数150正确率1.000000交叉训练,特征维度265,网络层数200正确率0.990000交叉训练,特征维度265,网络层数500正确率0.840000交叉训练,特征维度440,网络层数10正确率1.000000交叉训练,特征维度440,网络层数20正确率1.000000交叉训练,特征维度440,网络层数30正确率0.980000交叉训练,特征维度440,网络层数40正确率1.000000交叉训练,特征维度440,网络层数50正确率0.990000交叉训练,特征维度440,网络层数60正确率0.930000交叉训练,特征维度440,网络层数70正确率1.000000交叉训练,特征维度440,网络层数80正确率1.000000交叉训练,特征维度440,网络层数90正确率0.900000交叉训练,特征维度440,网络层数100正确率1.000000交叉训练,特征维度440,网络层数120正确率1.000000交叉训练,特征维度440,网络层数150正确率0.880000交叉训练,特征维度440,网络层数200正确率0.840000交叉训练,特征维度440,网络层数500正确率0.830000参考资料
Neural Networks — OpenCV 3.0.0-dev documentation
http://docs.opencv.org/3.0-beta/modules/ml/doc/neural_networks.html
UFLDL教程 - Ufldl
http://ufldl.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
从线性分类器到卷积神经网络 // 在路上
http://zhangliliang.com/2014/06/14/from-lr-to-cnn/
神经网络研究项目–以工程师的视角 - jsxyhelu - 博客园
http://www.cnblogs.com/jsxyhelu/p/4306753.html
OCR using Artificial Neural Network (OpenCV) – Part 1 | Nithin Raj S.
http://www.nithinrajs.in/ocr-using-artificial-neural-network-opencv-part-1/
liuruoze/EasyPR
https://github.com/liuruoze/EasyPR
willhope/code
https://github.com/willhope/code
OpenCV进阶之路:神经网络识别车牌字符 - ☆Ronny丶 - 博客园
http://www.cnblogs.com/ronny/p/opencv_road_more_01.html#commentform
感知器与梯度下降 - ☆Ronny丶 - 博客园
http://www.cnblogs.com/ronny/p/ann_01.html
神经网络入门(连载之一) - zzwu的专栏 - 博客频道 - CSDN.NET
http://blog.csdn.net/zzwu/article/details/574931/
原文地址:http://blog.csdn.net/zwhlxl/article/details/46605507
- 字符识别opencv c++版
- OpenCV OpenGL手写字符识别
- opencv实现车牌识别之字符识别
- C - 字符识别?
- opencv人脸识别(c++)
- 应用OpenCV进行OCR字符识别
- 应用OpenCV进行OCR字符识别
- opencv实现车牌识别之字符分割
- opencv的svm学习_字符识别
- 【Python-Opencv】KNN手写体字符识别
- opencv实现车牌识别之字符分割
- opencv实现车牌识别之字符分割
- Opencv车牌识别之字符提取
- opencv 11 OCR 字符识别(character_recognition) vs2015
- opencv的svm学习_字符识别
- opencv 手写选择题阅卷 (二)字符识别
- Opencv利用神经网络进行车牌识别(c++)
- 【C#】基于Opencv/Emgucv的身份证识别
- 学习笔记2015-11-16
- Objective-C编码规范
- Android 通过JitPack 发布开源项目到jcenter
- Java内部类的使用小结
- OpenCV改变图像大小的操作,resize与图像金字塔方法
- 字符识别opencv c++版
- 在onMeasure中获取已测量的子控件的宽高
- Notification (API14) 创建过程
- 263. Ugly Number
- Archive上传包出现错误ERROR ITMS-90005?
- c++类的操作符重载
- 数据库的优化-敏感信息的查询
- 图片64编码和解码
- python开发_++i,i += 1的区分


