多层神经网络BP算法 原理及推导
来源:互联网 发布:用友软件版本介绍 编辑:程序博客网 时间:2024/04/27 22:25
本文转自:http://www.cnblogs.com/liuwu265/p/4696388.html
首先什么是人工神经网络?简单来说就是将单个感知器作为一个神经网络节点,然后用此类节点组成一个层次网络结构,我们称此网络即为人工神经网络(本人自己的理解)。当网络的层次大于等于3层(输入层+隐藏层(大于等于1)+输出层)时,我们称之为多层人工神经网络。
1、神经单元的选择
那么我们应该使用什么样的感知器来作为神经网络节点呢?在上一篇文章我们介绍过感知器算法,但是直接使用的话会存在以下问题:
1)感知器训练法则中的输出
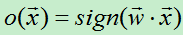
由于sign函数时非连续函数,这使得它不可微,因而不能使用上面的梯度下降算法来最小化损失函数。
2)增量法则中的输出为;
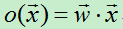
每个输出都是输入的线性组合,这样当多个线性单元连接在一起后最终也只能得到输入的线性组合,这和只有一个感知器单元节点没有很大不同。
为了解决上面存在的问题,一方面,我们不能直接使用线性组合的方式直接输出,需要在输出的时候添加一个处理函数;另一方面,添加的处理函数一定要是可微的,这样我们才能使用梯度下降算法。
满足上面条件的函数非常的多,但是最经典的莫过于sigmoid函数,又称Logistic函数,此函数能够将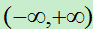 内的任意数压缩到(0,1)之间,因此这个函数又称为挤压函数。为了将此函数的输入更加规范化,我们在输入的线性组合中添加一个阀值,使得输入的线性组合以0为分界点。
内的任意数压缩到(0,1)之间,因此这个函数又称为挤压函数。为了将此函数的输入更加规范化,我们在输入的线性组合中添加一个阀值,使得输入的线性组合以0为分界点。
sigmoid函数:
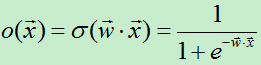
其函数曲线如图1.1所示。
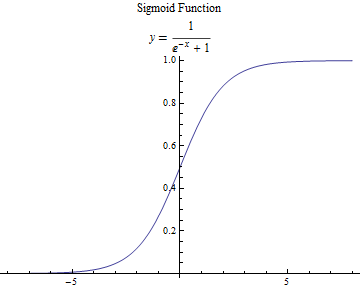
图1.1 sigmoid函数曲线[2]
此函数有个重要特性就是他的导数:
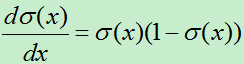
有了此特性在计算它的梯度下降时就简便了很多。
另外还有双曲函数tanh也可以用来替代sigmoid函数,二者的曲线图比较类似。
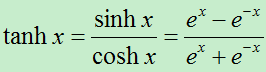
2、反向传播算法又称BP算法(Back Propagation)
现在,我们可以用上面介绍的使用sigmoid函数的感知器来搭建一个多层神经网络,为简单起见,此处我们使用三层网络来分析。假设网络拓补如图2.1所示。
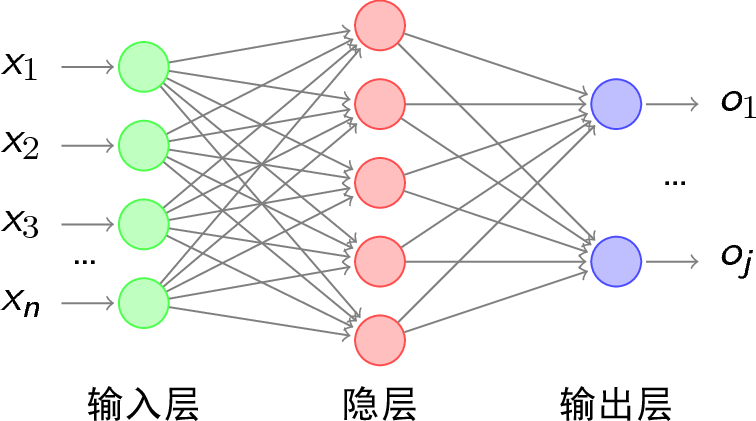
图2.1 BP网络拓补结构[3]
网络的运行流程为:当输入一个样例后,获得该样例的特征向量,再根据权向量得到感知器的输入值,然后使用sigmoid函数计算出每个感知器的输出,再将此输出作为下一层感知器的输入,依次类推,直到输出层。
那么如何确定每个感知器的权向量呢?这时我们需要使用反向传播算法来逐步进行优化。在正式介绍反向传播算法之前,我们先继续进行分析。
在上一篇介绍感知器的文章中,为了得到权向量,我们通过最小化损失函数来不断调整权向量。此方法也适用于此处求解权向量,首先我们需要定义损失函数,由于网络的输出层有多个输出结点,我们需要将输出层每个输出结点的差值平方求和。于是得到每一个训练样例的损失函数为:(前面加个0.5方便后面求导使用)
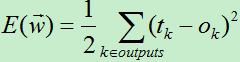
在多层的神经网络中,误差曲面可能有多个局部极小值,这意味着使用梯度下降算法找到的可能是局部极小值,而不是全局最小值。
现在我们有了损失函数,这时可以根据损失函数来调整输出结点中的输入权向量,这类似感知器中的随机梯度下降算法,然后从后向前逐层调整权重,这就是反向传播算法的思想。
具有两层sigmoid单元的前馈网络的反向传播算法:
1)将网络中的所有权值随机初始化。
2)对每一个训练样例,执行如下操作:
A)根据实例的输入,从前向后依次计算,得到输出层每个单元的输出。然后从输出层开始反向计算每一层的每个单元的误差项。
B)对于输出层的每个单元k,计算它的误差项:
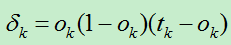
C)对于网络中每个隐藏单元h,计算它的误差项:
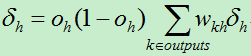
D)更新每个权值:
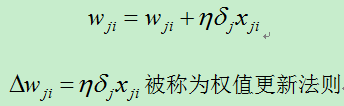
符号说明:
xji:结点i到结点j的输入,wji表示对应的权值。
outputs:表示输出层结点集合。
整个算法与delta法则的随机梯度下降算法类似,算法分析如下:
1)权值的更新方面,和delta法则类似,主要依靠学习速率,该权值对应的输入,以及单元的误差项。
2)对输出层单元,它的误差项是(t-o)乘以sigmoid函数的导数ok(1-ok),这与delta法则的误差项有所不同,delta法则的误差项为(t-o)。
3)对于隐藏层单元,因为缺少直接的目标值来计算隐藏单元的误差,因此需要以间接的方式来计算隐藏层的误差项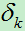 对受隐藏单元h影响的每一个单元的误差进行加权求和,每个误差权值为wkh, wkh就是隐藏单元h到输出单元k的权值。
对受隐藏单元h影响的每一个单元的误差进行加权求和,每个误差权值为wkh, wkh就是隐藏单元h到输出单元k的权值。
3、反向传播算法的推导
算法的推导过程主要是利用梯度下降算法最小化损失函数的过程,现在损失函数为:
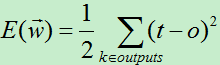
对于网络中的每个权值wji,计算其导数:
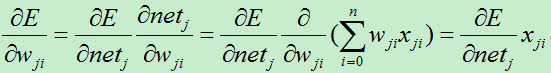
1)若j是网络的输出层单元
对netj的求导:
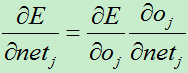
其中:
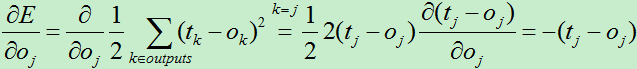
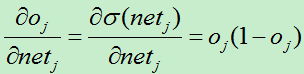
所以有:
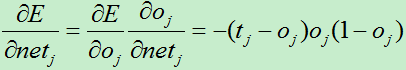
为了使表达式简洁,我们使用:
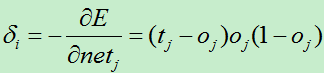
权值的改变朝着损失函数的负梯度方向,于是有权值改变量:
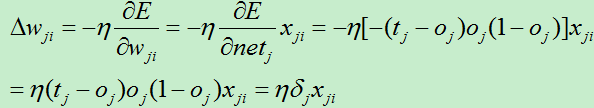
2)若j是网络中的隐藏单元
由于隐藏单元中w的值通过下一层来间接影响输入,故使用逐层剥离的方式来进行求导:
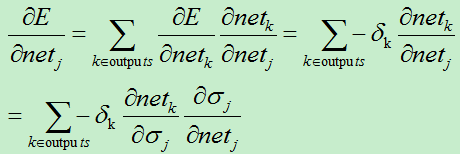
因为:
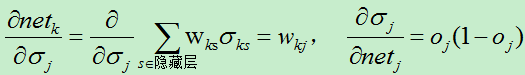
所以:
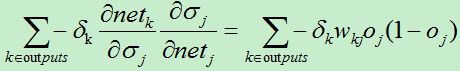
同样,我们使用:
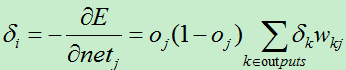
所以权值变化量:
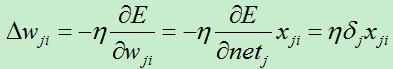
4、算法的改进
反向传播算法的应用非常的广泛,为了满足各种不同的需求,产生了很多不同的变体,下面介绍两种变体:
1)增加冲量项
此方法主要是修改权值更新法则。他的主要思想在于让第n次迭代时的权值的更新部分依赖于第n-1次的权值。
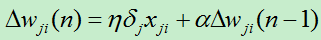
其中0<=a<1:称为冲量的系数。加入冲量项在一定程度上起到加大搜索步长的效果,从而能更快的进行收敛。另一方面,由于多层网络易导致损失函数收敛到局部极小值,但通过冲量项在某种程度上可以越过某些狭窄的局部极小值,达到更小的地方。
2)学习任意的深度的无环网络
在上述介绍的反向传播算法实际只有三层,即只有一层隐藏层的情况,要是有很多隐藏层应当如何进行处理?
现假设神经网络共有m+2层,即有m层的隐藏层。这时,只需要变化一个地方即可得到具有m个隐藏层的反向传播算法。第k层的单元r的误差 的值由更深的第k+1层的误差项计算得到:
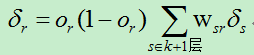
5、总结
对于反向传播算法主要从以下几个方面进行总结:
1)局部极小值
对于多层网络,误差曲面可能含有多个不同的局部极小值,梯度下降可能导致陷入局部极小值。缓解局部极小值的方法主要有增加冲量项,使用随机梯度下降,多次使用不同的初始权值训练网络等。
2)权值过多
当隐藏节点越多,层数越多时,权值成倍的增长。权值的增长意味着对应的空间的维数越高,过高的维数易导致训练后期的过拟合。
4)算法终止策略
当迭代次数达到设定的阀值时,或者损失函数小于设定的阀值时,或
3)过拟合
当网络的训练次数过多时,可能会出现过拟合的情况。解决过拟合主要两种方法:一种是使用权值衰减的方式,即每次迭代过程中以某个较小的因子降低每个权值;另一种方法就是使用验证集的方式来找出使得验证集误差最小的权值,对训练集较小时可以使用交叉验证等。
另外,神经网络中还有非常多的问题可以讨论,比如隐藏节点数量的多少,步长是否固定等,在此不展开讨论。
展望:
关于神经网络现在已有较多的研究,也产生了很多新的扩展算法,比如卷积神经网络,深度神经网络,脉冲神经网络等。尤其是脉冲神经网络被称为第三代神经网络,这些神经网络算法在未来将会有越来越多的应用,比如深度神经网络在图像识别,语音识别等领域已经取得了非常好的效果。
最后,此文主要参考Mitchell的机器学习课本撰写而成,如有错误欢迎指正!
参考文献:
[1] Tom M. Mitchell, 机器学习。
[2] Keep Going, http://www.cnblogs.com/startover/p/3143763.html
[3] HaHack, http://hahack.com/reading/ann2/
- 多层神经网络BP算法 原理及推导
- 多层神经网络BP算法 原理及推导
- 多层神经网络BP算法 原理及推导
- BP神经网络的原理及推导
- BP神经网络数学原理及推导过程
- 多层前馈神经网络及BP算法
- BP神经网络原理推导
- BP神经网络算法推导
- BP神经网络算法推导
- BP神经网络算法推导
- 神经网络及BP推导
- 多层神经网络(BP算法)介绍
- 卷积神经网络BP算法推导
- 神经网络与BP算法推导
- 神经网络BP算法简单推导
- BP神经网络原理及实现算法
- BP神经网络算法原理
- BP 神经网络算法原理
- PB 怎么动态(用代码)改变数据窗口的属性(例如窗体的字体大小,字体颜色,背景颜色)
- 内存分配方式
- LeetCode 414. Third Maximum Number
- Users Resources
- LeetCode 455. Assign Cookies
- 多层神经网络BP算法 原理及推导
- Python爬虫用Selenium抓取js生成的文件(一)
- 国内可用maven repository 配置
- 整数转换2进制
- [贪心 排序] 计蒜客 218 配对元素
- 聚类统计图
- 模板之高精度
- CTSC2014 企鹅QQ Hash模板
- #早安,努力#11.17


