集合基础
来源:互联网 发布:淘宝图片多少像素 编辑:程序博客网 时间:2024/04/30 06:52
Java是一门面向对象语言,数据多了用对象封装存储(比如,人有姓名、年龄、性别等数据信息,我们就抽象一个Person对象来封装存储),对象多了又用什么来存储呢?集合,集合就是用来存储对象的。
集合的特点就是适用于存储对象而且可以存储不同类型的对象,集合的长度是可变的。
集合框架图
集合使用不同类型的容器来存储不同类型的的对象,集合中主要有List、Set、Map三种容器,每种容器的数据结构都不一样。集合体系的类、接口非常多,方便记忆,我们将下面这个相对简洁的集合框架图分为从5个模块来学习:
1.Collection集合
2.Map集合
3.集合遍历
4.集合比较
5.集合工具类

先对图做一下解析:
l 点线框表示接口
l 实现框表示具体的类
l 带有空心箭头的点线表示一个具体的类实现了一个接口
l 实心箭头表示某一个类可以生成箭头所指向的类
l 常用的容器用黑色粗线表示
Collection集合
Collection接口
Collection是一个接口,是高度抽象出来的集合,包含了集合的基本操作:添加、删除、清空、遍历、是否为空、获取大小等等。定义如下:
public interface Collection<E> extends Iterable<E> {}
Collection接口下主要有两个子接口:List和Set。
List接口
List是Collection的一个子接口,List中的元素是有序的,可以重复,有索引。
定义如下:
public interface List<E> extends Collection<E> {}

List是继承于Collection接口,它自然就包含了Collection中的全部函数接口,由于List有自己的特点(素是有序的,可以重复,有索引),因此List也有自己特有的一些操作,如上红色框框中的。List特有的操作主要是带有索引的操作和List自身的迭代器(如上图)。List接口的常用实现类有ArrayList和LinkedList。
ArrayList
ArrayList是List接口的一个具体的实现类。ArrayList的底层数据结构是数组结构,相当于一个动态数组。ArrayList的特点是随机查询速度快、增删慢、线程不安全。ArrayList和Vector的区别是:Vector是线程安全的(synchronized实现)。定义如下:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable{}
l ArrayList 继承AbstractList,AbstractList是对一些公有操作的再次抽象,抽出一些特性操作,如根据索引操作元素,生产迭代器等。
l ArrayList 实现了RandmoAccess接口,即提供了随机访问功能,可以通过元素的索引快速获取元素对象。
l ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
l ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
ArrayList源码分析总结(源码略,建议先整体认识再打开源码对着看):
l 可以通过构造函数指定ArrayList的容量大小,若不指定则默认是10。
l 添加新元素时,容量不足以容纳全部元素时,会重新创建一个新的足以容纳全部元素的数组,把旧数组中的元素拷贝到新的数组中并返回新的数组。增量具体看源码。
l 添加的新元素添加到数组末尾。
l 查找、删除元素使用equals方法比较对象。
l ArrayList的克隆函数,即是将全部元素克隆到一个数组中。
l ArrayList的序列化,即通过java.io.ObjectOutputStream将ArrayList的长度和每一个元素写到输出流中,或者通过java.io.ObjectInputStream从输入流中读出长度和每一个元素到一个数组中。
LinkedList
LinkedList是List接口的一个具体的实现类。LinkedList底层数据结构是双向的链表结构,可以当成堆栈或者队列来使用。LinkedList的特点是增删速度很快,顺序查询效率较高,随机查询稍慢。定义如下:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable{}
l LinkedList 是继承AbstractSequentialList,AbstractSequentialList是AbstractList的一个子类。
l LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
l 同ArrayList,LinkedList同样支持克隆和序列化。
LinkedList 源码分析总结(源码略,建议先整体认识再打开源码对着看):
l LinkedList的本质是一个双向链表,各有一个头节点和尾节点,每一个节点都有个数据域、一个指向上一个节点的指针域、一个指向上下一个节点的指针域。
l 添加元素时,将元素添加到双向链表的末端。
l 查找、删除元素时,使用equals方法比较对象。
l 根据索引查找元素时,若索引值index < 双向链表长度的1/2,则从表头往后查找,否则从表尾往前找。
l LinkedList的克隆和序列化原理同ArrayList。
l LinkedList实现了Deque,Deque接口定义了在双端队列两端访问元素的方法,每种方法都存在两种形式:一种是在操作失败时抛出异常,另一种是返回一个特殊值(null 或 false)。
l LinkedList有自己特有的迭代器ListIterator。
l LinkedList不存在扩容增量的问题。
List应用举例
LinkedList实现堆栈和队列
LinkedList可以当成堆栈和队列使用,因为实现了Deque接口,Deque接口提供了一些了出栈入栈和出队入队的方法。
 View Code
View CodeArrayList保证唯一性
List中的元素是可以重复的,可以通过重写equals方法实现唯一性。下面是ArrayList实现元素去重(依据equals)的一个例子。
View Code从运行结果中可以看出,调用list的contains方法和remove方法时,调用了equals方法进行比较(List集合中判断元素是否相等依据的是equals方法)。
Set接口
Set是Collection的一个子接口,Set中的元素是无序的,不可以重复。定义如下:
public interface Set<E> extends Collection<E> {}
Set是继承于Collection接口,它自然就包含了Collection中的全部函数接口。Set接口的常用实现类有HashSet和TreeSet。实际上HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的。在此只简要列举它们的一些特点,可以直接看下面的HashMap和TreeMap的分析,理解了HashMap和TreeMap,也就理解了HashSet和TreeSet。
HashSet
HashSet是Set接口的一个具体的实现类。其特点是元素是无序的(取出顺序和存入顺序不一定一样),不可以重复。定义如下:
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable{}
l HashSet继承AbstractSet,AbstractSet抽象了equals()、hashCode()、removeAll()三个方法。
l HashSet实现了Cloneable,Serializable接口以便支持克隆和序列化。
l HashSet保证元素唯一性依赖equals()方法和hashCode()方法。
TreeSet
TreeSet是Set接口的一个具体的实现类。其特点是元素是有序的,不可以重复。定义如下:
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable{}
l TreeSet继承AbstractSet,AbstractSet抽象了equals()、hashCode()、removeAll()三个方法。
l TreeMap实现了NavigableMap接口,支持一系列的导航方法,比如返回有序的key集合。
l TreeSet实现了Cloneable,Serializable接口以便支持克隆和序列化。
l TreeSet保证元素唯一性依赖Comparator接口和Comparable接口。
Map集合
Map接口
不同于List和Set,集合体系中的Map是“双列集合”,存储的是内容是键值对(key-value),Map集合的特点是不能包含重复的键,每一个键最多能映射一个值。Map接口抽象出了基本的增删改查操作。定义如下:
public interface Map<K,V> {}
主要方法

/**添加**/V put(K key, V value);void putAll(Map<? extends K, ? extends V> m); /**删除**/void clear();V remove(Object key); /**判断**/boolean isEmpty();boolean containsKey(Object key);boolean containsValue(Object value); /**获取**/int size();V get(Object key);Collection<V> values();Set<K> keySet();Set<Map.Entry<K, V>> entrySet();
Map接口的主要实现类有HashMap和TreeMap。
HashMap
HashMap是Map接口的一个实现类,它存储的内容是键值对(key-value)。HashMap的底层是哈希表数据结构,允许存储null的键和值,同时HashMap是线程不安全的。HashMap与HashTable的区别是:HashTable不可以存储null的键和值,HashTable是线程安全的(synchronized实现)。
哈希表的定义:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。通过把关键字值key映射到哈希表中的一个位置来访问记录,以加快查找的速度。
HashMap定义如下:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable{}
l HashMap继承AbstractMap,AbstractMap抽象了Map集合的一些基本操作。
l HashMap实现了Cloneable,Serializable接口以便支持克隆和序列化。
HashMap源码分析总结(源码略,建议先整体认识再打开源码对着看):
l HashMap的几个重要成员:table, DEFAULT_INITIAL_CAPACITY ,MAXIMUM_CAPACITY ,
size, threshold, loadFactor, modCount。
(1)table是一个Entry[]数组类型,Map.Entry是一个Map接口里的一个内部接口。而Entry实际上就是一个单向链表,也称为HashMap的“数组+链式存储法”,链式存储是为了解决哈希冲突而存在。HashMap的键值对就是存储在Entry对象中(一个Entry对象包含一个key、一个value、key对应的hash和指向下一个Entry的对象)。
(2)DEFAULT_INITIAL_CAPACITY是默认的初始容量是16。
(3)MAXIMUM_CAPACITY, 最大容量(初始化容量大于这个值时将被这个值替换)。
(4)size是HashMap的大小,保存的键值对的数量。
(5)threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值="容量*加载因子",当HashMap中存储数据的数量达到threshold时,就需要将HashMap进行rehash 操作(即重建内部数据结构)是容量*2。
(6)loadFactor就是加载因子。
(7)modCount是记录HashMap被修改的次数。
l table分配空间。不同版本略有差异。在1.6的源码中,为table分配空间是在HashMap的构造函数中,而1.7的中,则在put的时候先判断table是否为空,为空则分配空间。
l get(Object key)。先计算key的hash,根据hash计算索引,根据索引在table数组中查找出对应的Entry,返回Entry中的value。
l put(K key, V value)。若key为null,则创建一个key为null的Entry对象并存储到table[0]中。否则计算其hash以及索引i,创建一个键值对和哈希值分别为key、value、hash的Entry对象并存储到table[i]中(若table[i]处为空即没有Entry链表则直接存入,否则将Entry对象添加到table[i]处的Entry链表的表头中)。需要注意的是,如果该hash已经存在Entry链表中,则用新的value取代旧的value并返回旧的value。
l putAll(Map<? extends K, ? extends V> m)。当当前实际容量小于需要的容量,则将容量*2。调用put()方法逐个添加到HashMap中。
l remove(Object key)。计算key的hash以及索引i,根据索引在table数组中查找出对应的Entry,从Entry链表删除对应的Entry节点,期间会比较hash和key(equals判断)来判断是否是要删除的节点。
l clear()。把每一个table[i]设置为null。
l Entry类中重写了equals()方法和hashCode()来判断两个Entry是否相等。
l containsKey(Object key)。比较hash和key(equals判断)来判断是否是包含该key。
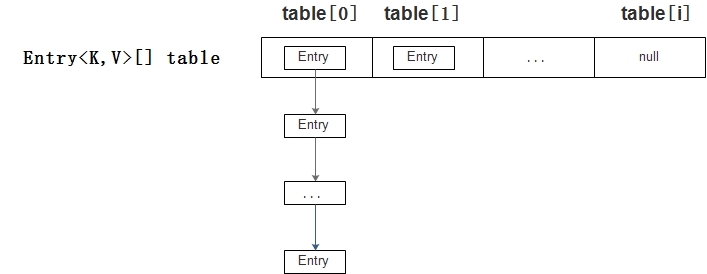
HashMap内存结构示意图
HashMap举例
通过keyset遍历
View Code通过entrySet遍历
View CodeTreeMap
TreeMap是Map接口的一个实现类,因此它存储的也是键值对(key-value)。TreeMap的底层数据结构是二叉树(红黑树),其特点是可以对元素进行排序,TreeMap是线程不安全的。定义如下:
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable{}
l TreeMap继承AbstractMap,AbstractMap抽象了Map集合的一些基本操作。
l TreeMap实现了NavigableMap接口,支持一系列的导航方法,比如返回有序的key集合。
l TreeMap实现了Cloneable,Serializable接口以便支持克隆和序列化。
TreeMap源码分析总结(源码略,建议先整体认识再打开源码对着看):
l TreeMap的几个重要成员:root, size, comparator。
(1)root是红黑树的根节点,它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
(2)comparator是比较器,使红黑树的节点具有比较性,用来给TreeMap排序。红黑数排序时,根据Entry中的key进行排序,Entry中的key比较大小是根据比较器comparator来进行判断的。
(3)size是红黑树节点的个数。
l TreeMap(Comparator<? super K> comparator)。带比较器的构造函数可以在TreeMap外部自定义TreeMap元素(红黑树节点)的比较器。
l get(Object key)。若比较器comparator不为空(即通过构造函数外部传入的),则通过Comparator接口的compare()方法从根节点开始和key逐个比较直到找出相等的节点。若比较器为空,则使用Comparable接口的compareTo()比较查找。
l put(K key, V value)。若根节点root为空,则根据key-value创建一个Entry对象插入到根节点。否则在红黑树中找到找到(key, value)的插入位置。查找插入位置还是若比较器comparator不为空则通过Comparator接口的compare()方法比较查找,否则通过Comparable接口的compareTo()方法比较查找。过程比较复杂。
l putAll(Map<? extends K, ? extends V> map)。调用AbstractMap中的putAll(),AbstractMap中的putAll()又会调用到TreeMap的put()。
l remove(Object key)。先根据key查找出对应的Entry,从红黑树中删除对应的Entry节点。
l clear()。clear把根节点设置为null即可。
l containsKey(Object key)。判断是否是包含该key的元素,查找方法同get()。
TreeMap举例
View Code由此可见,要想按照自己的方式对TreeMap进行排序,可以自定义比较器重写compare()方法重写自己的比较逻辑。
集合遍历
迭代器的设计原理
在上面List和Map的分析和举例中,已经提到迭代器了。因为每一种容器的底层数据结构不同,所以迭代的方式也不同,但是也有共同的部分,把这些共同的部分再次抽象,Iterator接口就是迭代器的顶层抽象。
List集合中有自己特有的迭代器ListIterator,ListIterator接口是Iterator接口的子接口。实现类ArrayList和LinkedList中有迭代器的具体实现(内部类)。把迭代器设计在集合的内部,这样,迭代器就可以轻松的访问集合的成员了。
private class ListItr extends Itr implements ListIterator<E>{}
而在HashMap和TreeMap的遍历中,我们经常将Map的键存到Set集合中,Set属于List的子接口,当然也继承了List特有的迭代器,通过迭代key来获取value。另一种方式是将Map中的映射关系Entry取出存储到Set集合,通过迭代每一个映射Entry关系获取Entry中的key和value。可以说,Map是借List的迭代器实现了对自身的遍历。
集合遍历效率总结
l ArrayList是数组结构,ArrayList常用遍历有for循环(索引访问)、增强for循环、迭代器迭代。其中按索引访问效率最高,其次是增强for循环,使用迭代器的效率最低。
(1)按索引访问时间复杂度为O(1),即一次定位寻址即可。
(2)查找某一个值,需要遍历数组逐个对比,时间复杂度为O(n),即需要对比n次。
(3)对于二分查找(元素有序是前提)时间复杂度为O(logn)。
(4)对于插入和删除,因为涉及到元素移动的问题,时间复杂度也为O(n)。
l LinkedList是链表结构,常用遍历也有for循环(索引访问)、增强for循环、迭代器迭代。建议不要采用随机访问的方式去遍历LinkedList,而采用逐个遍历的方式。
(1)查找某一个值,需要遍历链表逐个对比,时间复杂度为O(n)。
(2)对于插入、删除等操作,由于只需要改变前后节点之间的指针,时间复杂度为O(1)。
l HashMap是“数组+链表”的结构。其遍历方式也很多,可以通过keyset遍历、通过entrySet遍历、通过Map.values()遍历(这种方式只能获得value)。
(1)如果table[i]处没有链表,对于查找一次定位,时间复杂度为O(1),对于增加、删除,本质上也是对链表的增加、删除(可以理解table[i]处是只有一个节点的链表),所以时间复杂度为O(1)。
(2)如果table[i]处有链表,查找时需要遍历链表,时间复杂度为O(n),增加、删除时间复杂度为O(1)。
l TreeMap是二叉树结构,可以通过keyset、entrySet等方式遍历。
(1)对于二叉树的遍历,给定某一个值,它会先和二叉树的root节点对比,如果值比root节点大则在右子树遍历,否则就在左子树遍历,以此类推。因此,对于查找、增加、删除等操作,都不会遍历完整棵树,平均复杂度均为O(logn)。
集合比较
Comparator与Comparable
在TreeMap的分析和举例中,我们提到了TreeMap中的元素排序比较采用的是Comparator接口的compare()方法和Comparable接口的compareTo()。当元素本身不具备比较性或者具备的比较性不满足我们的需求时,我们就可以使用Comparator接口或者Comparable接口来重写我们需要的比较逻辑。Comparator接口和Comparable接口实现比较的主要区别是:Comparator 是在元素外部实现的排序,这是一种策略模式,就是不改变元素自身,而用一个策略对象(自定义比较器)来改变比较行为。而Comparable接口则需要修改要比较的元素,让元素具有比较性,在元素内部重新修改比较行为。看下面的两个列子。
让元素具有比较性
View Code
上面的例子中,Passenger本身并不具备比较性,但是通过修改Passenger,让其实现了Comparable 接口重写了compareTo()方法让其根据年龄具有比较性。
自定义比较器
View Code从上面的例子可以看出,Passenger本身并不具备比较性,我们也没有修改Passenger,而是在外部自定义一个比较器,传入TreeSet中,使得TreeSet中存储的Passenger具有了比较性。
集合工具类
Collections
Collections是一个工具类,提供了操作集合的常用方法:
<!--排序, 对list中元素按升序进行排序,list中的所有元素都必须实现 Comparable 接口-->void sort(List<T> list)<!--混排,打乱list中元素的顺序-->void shuffle(List<?> list)<!--反转,反转list中元素的顺序-->void reverse(List<?> list)<!--使用指定元素替换指定列表中的所有元素-->void fill(List<? super T> list, T obj)<!-- 将源list中的元素拷贝到目标list-->void copy(List<? super T> dest, List<? extends T> src)<!-- 返回集合中最小的元素-->T min(Collection<? extends T> coll)<!-- 返回集合中最大的元素-->T max(Collection<? extends T> coll)
Collections举例
View CodeArrays
Arrays也是一个工具类,提供了操作数组以及在数组和集合之间转换的一些常用方法。
/**可以对各种类型的数组进行排序**/void sort(Object[] a) /** 数组变集合**/<T> List<T> asList(T... a) /** 数组转成字符串**/String toString(Object[] a)Arrays举例
View Code需要注意的是,将数组变成集合后,不能使用集合的增加或者删除方法,因此数组的长度是固定的,使用这些方法将会报UnsupportedOperationException异常。从上面的例子也可以看出,如果数组中的元素都是对象,那么转换成集合时,数组中的元素就直接转换成集合中的元素;如果数组中的元素是基本类型,那么整个数组将作为集合的元素存在。
- 集合基础
- 【集合】 集合基础,Collectionj接口
- PASCAL基础-集合
- JAVA基础之集合
- java基础之集合
- c#基础加强--集合
- [ java ] java基础集合!
- [STL基础]set集合
- java基础:集合connection
- java基础之 集合
- java基础10 集合
- java基础--集合
- java基础---集合类
- java基础知识点集合
- java基础 集合迭代器
- JAVA基础之集合
- Java集合框架基础
- java基础--HashSet集合
- 第六篇 zabbix创建主机群组
- 为什么开通CSDN博客?
- create table #temptable 临时表 和 declare @bianliang table ()表变量
- Mysql优化分页
- MySQL运行状态show status详解
- 集合基础
- js中对方法的调用,是否需要加()
- 手机页面中如何创建1px宽度的间隔线
- LiveGiftShow-iOS直播弹幕效果(礼物连击)
- 圆形图片
- 【noip2016集训总结】
- 进程与线程及其区别
- 泛型(genericity)
- mysql 批量更新与批量更新多条记录的不同值实现方法


