Java并发编程(Concurrency)并发模型
来源:互联网 发布:ubuntu镜像文件安装 编辑:程序博客网 时间:2024/06/06 13:59
摘要:这是翻译自一个大概30个小节的关于Java并发编程的入门级教程,原作者Jakob Jenkov,译者Zhenning Lang,转载请注明出处,thanks and have a good time here~~~(希望自己不要留坑)
并发模型
并发系统可以基于不同的并发模型。并发模型描述了系统中的多个线程是如何协同完成指定的任务的。不同的并发模型以不同的方式分割任务,并且线程间也以不同的方式进行通讯和协作。本教程将分析目前(2015年)最流行的并发模型。
1 并发模型与分布式系统的相似性
本文中描述的并发模型和分布式系统中应用的不同架构具有相似性。在一个并发系统中,不同的线程间互相通信。在一个分布式系统中,不同的进程(可能在不同的计算机上)间也会相互通信。这两者本质上是相当类似的,这也是为什么不同的并发模型和分布式系统中应用的不同架构如此相似。
当然分布式系统有其独特的额外难点,例如网络中断,或者结点失效等。但一个大服务器上运行的并发系统也可能遇到类似的问题,例如CPU故障,网卡故障,磁盘故障等。尽管上述故障发生的可能性很低,但理论上是存在这些情况的。
由于并发模型和分布式系统架构的相似性,二者经常相互借鉴。例如,不同线程间的任务分配模型类似于分布式系统的负载均衡模型。二者的异常处理技术也是类似的,例如日志(logging)、故障切换(fail-over)和等幂性任务(idempotency of jobs)等。
2 并行工作者模型(Parallel workers model)
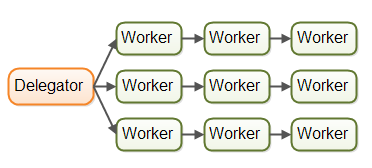
并行工作者模型是我要介绍的第一个并发模型。到来的任务被分配给不同的工作者来执行,如下图所示:
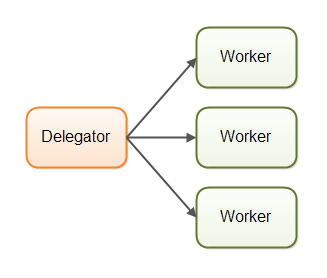
在并行工作者并发模型中一个“委托者”(delegator)将到来的任务分配给不同的工作者。每个工作者完成自己被分配的全部任务。不同的工作者是在不同的线程中(也可能是不同的CPU中)以并行的方式运行。
举个生活中的例子,如果一个汽车生产厂才用了并行工作者模型,那么每辆汽车将由一个工人负责完成制造。这需要每个工人都有汽车的生产说明书,并且从头至尾的完成每个生产细节。
并行工作者并发模型是Java应用中最常用的一种并发模型(尽管这个情况在改变)。在java.util.concurrent包中的很多并发工具类的目的是为了应用这个模型。在Java企业版的服务器应用中,也可以看到这个模型的踪迹。
2.1 并行工作者模型的优点
并行工作者模型的优点是其原理易于理解,如果想增加并行化规模只需要增加工作者的个数即可。
例如,假如你正在实现一个网络爬虫,你可以用
2.2 并行工作者模型的缺点
并行工作者模型在其简单的外表下隐藏了数个缺点,但这里我仅接受其中最明显的几个。
2.2.1 共享状态将使复杂性增加
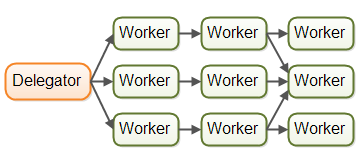
现实中的并行工作者并发模型要比上面的例子复杂得多。共享型的几个工作者需要具有一些共享资源的访问权限,这种共享既可能是内存级也可能是共享型的数据库。下图展示了这种情况下是如何使并行工作者并发模型变得复杂的:
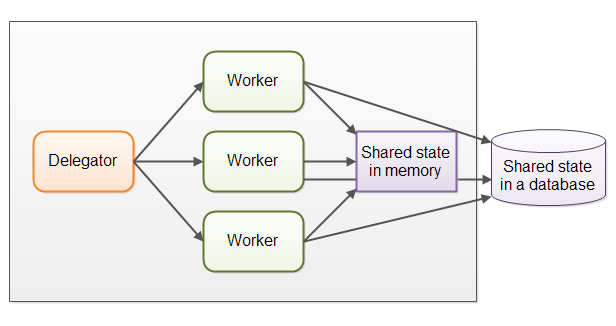
有些时候,这些共享的状态变量(数据)可能是通讯中的任务队列。然而其他时候,这些共享的状态可能是商业数据,数据缓存,数据库的连接池等等。
一旦并行工作者模型隐含了共享状态,问题将变得复杂。当线程获取共享数据时,必须通过某种方式使共享数据的变化对于其他线程是可见的(将其推送至主内存,而不仅仅是保存在执行这个线程的CPU的缓存中)。线程间需要避免竞争、死锁和许多其他的共享状态并发问题。
此外,当线程间相互等待获取共享数据的时候,程序的并行性也被削弱了。许多的并发式数据结构都是“阻塞”1式的,这意味着在指定的时间内,只有一个或者有限的线程可以访问这些数据。这将导致对于这些共享型数据结构的竞争状态,而从本质上说高度的竞争将导致获取共享数据的代码在一定程度上的串行化。
现代的非阻塞式的并发算法可以减缓这种竞争,从而使性能提升,然而非阻塞式的并发算法通常是难以实现的。
“持久化数据结构”是另一种选择。一个持久化的数据总是保存着其本身被更改前的值/状态/版本。因此,如果多个线程同时操作同一个持久化的数据并且其中一个线程修改了这个数据,那么这个做出修改动作的线程将得到新数据的引用。而其他的线程得到的是未经修改的旧数据的引用,持久化的含义就是这种不变性。Scala语言具有几种持久化的数据结构。
虽然持久化数据结构是共享数据并发读写中遇到的问题的一个看似“优雅的”解决方案,但其性能并不那么好。
举个例子,一个持久化列表(persistent list)将所有新元素(修改后的数据)添加到表头,并且返回最新添加元素的引用。其他的线程仍然使用列表中次新的元素的引用,对于这些线程来说,这个列表表现得就像没有任何改变一样,即新加入的元素对于他们来说是不可见的。
这样的一个持久化列表可以用链表来实现(linked list)。然而不幸的是,现在的硬件并不能很好的支持链表。列表中的每个元素是一个个分离的对象,这些对象的位置可能遍布计算机的内存的任何地址。目前的CPU获取连续内存数据的速度更快,这导致了利用数组(array )实现持久化列表的性能会更优。数组被用来存储在内存中连续的数据。CPU缓存(cache)可以一次性读入一个大体量的数组,从而达到缓存一次数组,CPU就可以持续地直接从缓存中读取数据的目的。对于数据元素分散在内存各处的链表来说是无法达到这种效果的。
2.2.2 无状态的工作者
共享的状态可以被系统中的其他线程进行修改,因此工作者必须在每次需要共享数据的时候重读这些数据,来保证他所获得的数据是最新的。这对于无论共享状态是保存在内存中还是保存在外部数据库中都是适用的。如果一个工作者不在其内部保存共享状态(而是每次都重新读取最新的数据),那么我们称其为无状态的。
每次都重新读取数据将使得程序变慢,尤其是从外部数据库中读取的情况。
2.2.3 任务顺序的非确定性
并行工作者模型的另一个缺点是其各个任务的执行顺序是非确定性的,没有办法保证那个任务先被执行那个任务后被执行。任务A可能比任务B先被分配给工作者,然而任务B却可能要先于任务A被执行。
并行工作者模型的不确定性导致了很难在固定的时间点推理出系统的状态,更不用说想保证一个任务在另一个任务之前被率先执行(如果这可以实现的话,可以说是难上加难)。
3. 流水线模型(Assembly line model)
流水线并发模型是我要介绍的第二个并发模型,在不同的平台/圈子中,这个模型也具有其他的名字,如反应式系统(reactive system)或事件驱动系统(event driven system)。下图是流水线并发模型的一个图示:
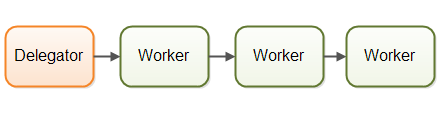
工作者被组织成沿着流水线进行工作,每个工作者仅完成全部任务的一小部分。当一个工作者完成了自己的部分,其下一个工作者将继续完成下一个部分的工作。2
每个工作者在其自己的线程中运行,和其他的工作者没有状态上的共享。所以流水线模型有时也被称为无共享并发模型。
具有流水线并发模型的系统经常被设计为使用“非阻塞”的I/O,其含义是当一个工作者开始了一个I/O操作(例如读取文件或读取网络数据)该工作者并不等待I/O操作结束。由于I/O操作太过缓慢,所以等待I/O操作实际是在浪费CPU资源。在I/O操作的同时CPU可以被用来做一些其他的事情。当I/O操作结束后,其结果(例如读取到的文件数据或者写数据的状态返回)将被传递给另一个工作者。
如果使用了非阻塞的I/O,那么I/O操作决定了两个工作者间的界限。一个工作者尽可能的完成任务,直到他不得不开始一个I/O操作。随后他放弃对任务的控制权。当I/O操作完成后,流水线中的下一个工作者继续完成任务,知道他也不得不开始I/O操作。3
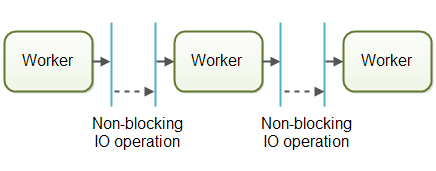
在实际情况下,任务不仅仅沿着单一的流水线被处理。由于大多数系统可以执行多于一条任务,许多的任务根据其完成情况沿着流水线逐个地被工作者们处理。现实中可能同时存在多条不同的虚拟流水线。下图是实际情况下流水线系统的示意:
在流水线并发模型中,任务可能被向前传递给不止一个工作者。例如,一个任务可能同时被传递给一个任务执行者和一个任务日志记录者。下图展示了三条流水线是如何以将任务传递给一个工作者来结束的(中间流水线的最后一个工作者):
流水线模型可能会比上述情况复杂得多。
3.1 反应式系统(Reactive system)和事件驱动系统(Event driven system)
使用流水线并发模型的系统有时也被称为反应式系统或事件驱动系统。系统中的工作者对系统中发生的事件进行反应,这些事件既可能是系统接收到来自外界的消息,也可能是来自其他工作者的消息。到来的HTTP请求或者结束将文件读入内存都是这里所说的“事件”的例子。
截止到写这个教程,已经有一些有趣的反应式/事件驱动系统平台,并且未来还会有更多。其中一些比较有名的平台如下:
- Vert.x
- Akka
- Node.JS (JavaScript)
就我个人而言,Vert.x是相当让我感兴趣的(特别是对于我这种沉迷于Java/JVM的人)
3.2 行动者(Actors) vs. 通道(Channels)
“行动者”和“通道”是流水线模型的两个类似的例子。
在一个行动者模型中,每个工作者被称为一个行动者。行动者之间可以直接相互传递信息。这些信息被异步地传递和处理。行动者模型可以被用来实现单任务或多任务流水线模型。下图是行动者模型的示意图:

在通道模型中,工作者们之间并不直接进行相互通信,取而代之的是工作者将他们的消息(事件)发布在不同的通道上。其他的工作者可以监听这些通道中的消息,这一过程中,发布消息的工作者不需要知道有谁在监听自己的消息。下图是通道模型的一个展示:
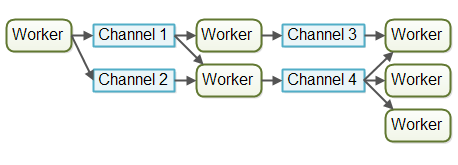
目前为止对于我来说,通道模型似乎更加的灵活。一个工作者不需要知道流水线上哪些工作者是其后续(继续处理他处理过的任务)。工作者只需要知道将任务(消息)推送到哪些通道中。通道的监听者可以在不影响发布者的情况下订阅和取消订阅通道。这在某种程度上是对工作者之间的解耦。
3.3 流水线模型的优点
与并行工作者模型相比,流水线模型具有一些优势,这里我只列举了最大的几个有点。
3.3.1 无共享状态
工作者们不共享任何状态的事实意味着在实现流水线模型时无须考虑共享状态引起的许多并发问题(竞争、死锁等)。这使得流水线模型中的任务者实现起来更加简单。在实现一个工作者时,这个工作者仿佛是处理整个任务的唯一线程 - 实际上变成了单线程编程。
3.3.2 工作者是有状态
由于工作者知道没有其他的线程会改变其数据,这样一来工作者可以被设计为有状态(Stateful)的。这里的“有状态”指的是工作者可以将其需要操作的数据存在内存中,并将最终的处理后的结果写回到外部存储系统中。一个有状态的工作者通常比无状态的工作者运行速度更快。
3.3.3 更符合硬件特性
单线程编程具有运行更符合底层硬件运行特性的优势。首先,当你能假设你的代码以单线程模式实现时,通常你可以设计出更加优化的数据结构和算法。
其次,单线程、有状态的工作者可以缓存数据。当数据被缓存后,其后续具有较大的概率还会被再次缓存,这导致了获取缓存数据将更快。4
我所说的“符合硬件特性”(hardware conformity)指的是:编写代码的方式可以自然地从底层硬件运行方式中受益。有一些开发者将其称为“器械协同”(mechanical sympathy)。而我更喜欢称其为符合硬件特性的原因是现代的计算机几乎没有机械部分,并且“协同”(sympathy)指的是合拍,而“符合”(conformity)在这里更加恰当。不过这都是一些文字游戏,你可以用你喜欢的称呼。
3.3.4 可以获知任务的执行顺序
在实现流水线并发模型时,我们可以以某种方式保证任务执行的先后顺序。保证执行顺序可以使在某个时间点获知系统状态变得更加简单。更进一步,所有到来的任务可以写进日志。这个日志可以被随后用来重建系统的状态,以防系统中任何部分的错误。
想要实现保证任务顺序并不一定简单,但通常是可以实现的。如果能做到,这将大大简化备份、数据存储等工作,因为这都可以通过日志文件来实现。
3.4 流水线模型的缺点
流水线并发模型的主要缺点是执行一个任务时通常需要涉及多个工作者,而这将导致工程中的过多的类的个数。进而,对于给定的任务,想弄清楚究竟哪段代码在执行他将变得更加困难。
同时,编码工作也可能很困难。工作者的代码很多时候被写成回调句柄(callback handler)的形式。拥有太多的回调句柄的代码将会成为所谓的“回调地狱”(callback hell),即很难从这些回调中还原并跟踪顶层函数的真实含义,并且也很难确定是否每个回调函数都有其所需数据的访问权限。
对于并行工作者模型来说,这一点是不足为虑的。你只需要打开一个工作者的实现代码并且从头至尾阅读一边。当然,并行工作者也可能被展开成多个不同的类,但是其执行过程是很容易从代码中读懂的。
4 函数并行化模型
函数并行化模型是第三个并发模型,并且在当下(2015)被广泛讨论。
函数并行化模型的基本思想是:通过函数调用来实现你的代码。函数可以被看作是“代理”(agents)或者“行动者”(actors),并且相互之间发送消息,就好像上面流水线模型中所叙述的一样。当一个函数调用另一个函数,这很类似与发送一个消息。
所有被传递给函数的参数都被复制成相应的副本再传入函数中,所以接收函数外部的所有实体都无法再对数据进行操作。这种复制是为了在本质上避免共享数据的竞争问题。这使得函数的执行类似于一个原子操作(atomic operation)。每个函数调用相对于其他函数都被独立地执行。
当一个一系列并行化函数可以被单独调用执行时(即他们之间在执行的过程中不存在数据交互等耦合),每个函数都可以在多个独立的CPU中执行。这意味着利用并发函数式模型实现的算法可以在不同的CPU中并行的运行。
随着Java 7的发布,我们可以使用java.util.concurrent包中的ForkAndJoinPool来实现类似于函数并行化模型的代码。随着Java 8的发布,我们有了并行流(streams),使得对于大型的集合(collection),其迭代器可以实现并行化。值得注意的是,有一些开发者对ForkAndJoinPool持批判态度(在我的ForkAndJoinPool教程中你可以找到具体的链接)。
函数并行化的难点在于对并行化的函数的深入了解。几个跨CPU协作的函数通常需要额外的在管理时间上的损耗,一个函数所完成的问题的规模需要足够大才能抵消这种损耗。如果调用函数的任务规模过小,并行化反而会比单线程更慢。
就我个人的理解(可能并不正确),你可以自己利用反应式/事件驱动模型来实现一个模型,并且将一个完整的任务进行拆分,其效果和函数并行化模型很相似。然而,前者却可以更加精准的控制并行化的部分和并行化的程度(个人观点)。
此外,如果想让将一个任务拆分和由多个CPU协作所产生的额外时耗变得合理和有意义,其条件是仅当该任务是程序的唯一执行的工作。然而,如果程序还同时并发的执行许多其他的任务(例如网络服务、数据库服务和许多其他事要做),试着并行化其中单一的任务并无任何意义。计算机的其他CPU总是忙着做其他工作,所以用一个更慢的函数并行化任务来拖慢这些CPU是没有意义的。这时如果用流水线并发模型可能会更好,因为流水线模型具有更少的额外损耗并且和底层硬件契合的更佳。
5 孰优孰略?
那么这些并发模型孰优孰略呢?
通常的情况是这依赖于你的系统想要完成什么样的任务。如果你的任务本身就具有很好的并行性,不同的任务间相互独立并且也不需要共享状态,那么这个系统更适合于用并行工作者模型来实现。
然而更多时候任务间并非具有天然的并行性,相互之间缺乏独立行。对于这一类系统,我认为流水线并发模型是利大于弊的,并且也优于并行工作者模型。
你甚至不需要自己编写流水线模型的基本框架。现代的诸如Vert.x的一些平台已经为你完成了大部分工作。就我个人而言我的下一个项目将使用诸如Vert.x的平台来实现。同时我个人认为,JavaEE并没有任何的局限性。
- 阻塞式I/O指操作一个I/O过程中,如果还没有完成操作,线程将停住并一直等待I/O操作结束,无法继续完成I/O操作后续的代码功能。 ↩
- 这里的理解可以考虑这样的情况,一个任务分成三个步骤完成,假设现在一个任务的第一个步骤已经完成了,那么它将到达第二个步骤;如果此时又来了一个新的任务,那么第一个任务的第二个步骤和第二个任务的第一个步骤将并发的执行 - 也就是说,只要任务是多个,就可能产生并发。但如果任务只有一个,或者第二个任务到达时第一个任务已经全部被执行完,此时就不会有并发。 ↩
- 这里的意思是说,在流水线模型中任务的划分尽量以I/O作为分界,因为这样就不用再一个任务被执行的时候调用I/O了(I/O通常都是比较慢的) ↩
- 这是因为计算机大多数(80%)的时间在处理少量(20%)的数据,所以才会有缓存可以加速程序运行的说法。
- Java并发编程(Concurrency)并发模型
- Java并发编程(Java Concurrency)(4) - 并发模型
- 深入浅出java并发编程concurrency
- Concurrency Program(并发编程)
- Java并发编程(Java Concurrency)(6) - 并发 vs. 并行(Concurrency vs. Parallelism)
- java并发编程----并发模型
- Java并发编程(Java Concurrency)(17)- 预防死锁
- Java并发编程实践评价(Java Concurrency in Practice)
- Java并发编程(Java Concurrency)(1)- Java并发编程简介
- Java 编程要点之并发(Concurrency)详解
- Java 编程要点之并发(Concurrency)详解
- Java并发框架(Concurrency)
- Go编程基础—并发(concurrency)
- Java并发编程系列(一):Java并发内存模型
- Java并发系列-4、并发编程模型
- java并发编程(二)《内存模型》
- Java Concurrency Util java并发
- java 并发编程实践( java concurrency in practice )
- 不同APP通过SharedPreferences传递数据(共享数据)
- 十几年的技术人生,未来怎么走!
- js 三大家族(offset/scroll/client)
- Codeforces#381(Div. 2) A.Alyona and copybooks【暴力】
- Netstat 命令详解
- Java并发编程(Concurrency)并发模型
- ORA-01078和LRM-00109错误解决
- windows下将redis做成服务,随系统自启动
- 使用httpclient实现上传下载(javaWeb系统数据传输http实现)
- [OpenGL]从零开始写一个Android平台下的全景视频播放器——2.3 使用GLSurfaceView和MediaPlayer播放一个平面视频(下)
- Android 内存分析
- 穷举法-柏松分酒
- js setInterval 与 setTimeout
- exit(0)与exit(1)、return区别


