深入理解groupByKey、reduceByKey
来源:互联网 发布:当量直径算法 编辑:程序博客网 时间:2024/05/01 10:03
测试源码
下面来看看groupByKey和reduceByKey的区别:
val conf = new SparkConf().setAppName("GroupAndReduce").setMaster("local") val sc = new SparkContext(conf) val words = Array("one", "two", "two", "three", "three", "three") val wordsRDD = sc.parallelize(words).map(word => (word, 1)) val wordsCountWithReduce = wordsRDD. reduceByKey(_ + _). collect(). foreach(println) val wordsCountWithGroup = wordsRDD. groupByKey(). map(w => (w._1, w._2.sum)). collect(). foreach(println)虽然两个函数都能得出正确的结果, 但reduceByKey函数更适合使用在大数据集上。 这是因为Spark知道它可以在每个分区移动数据之前将输出数据与一个共用的key结合。
借助下图可以理解在reduceByKey里发生了什么。 在数据对被搬移前,同一机器上同样的key是怎样被组合的( reduceByKey中的 lamdba 函数)。然后 lamdba 函数在每个分区上被再次调用来将所有值 reduce成最终结果。整个过程如下:
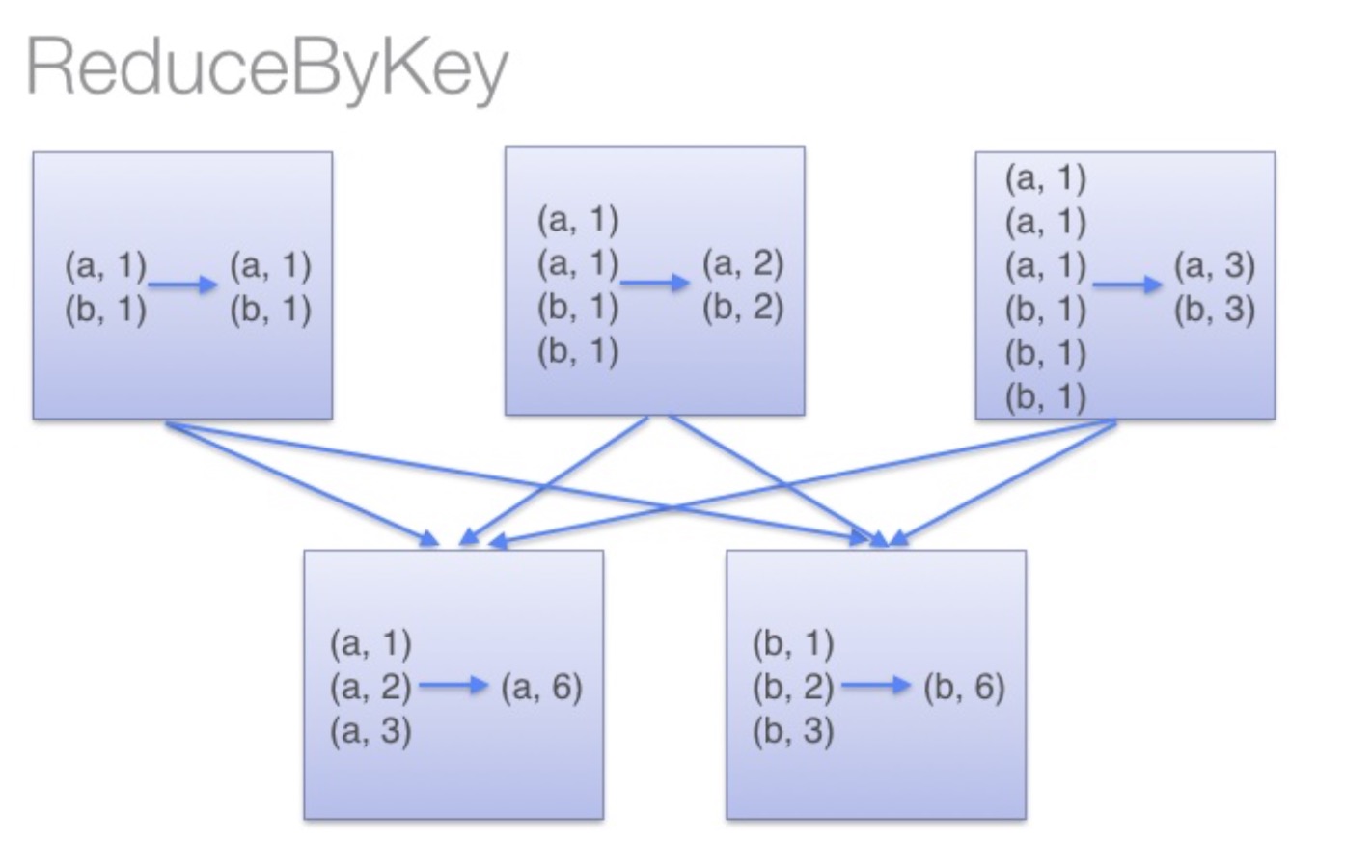
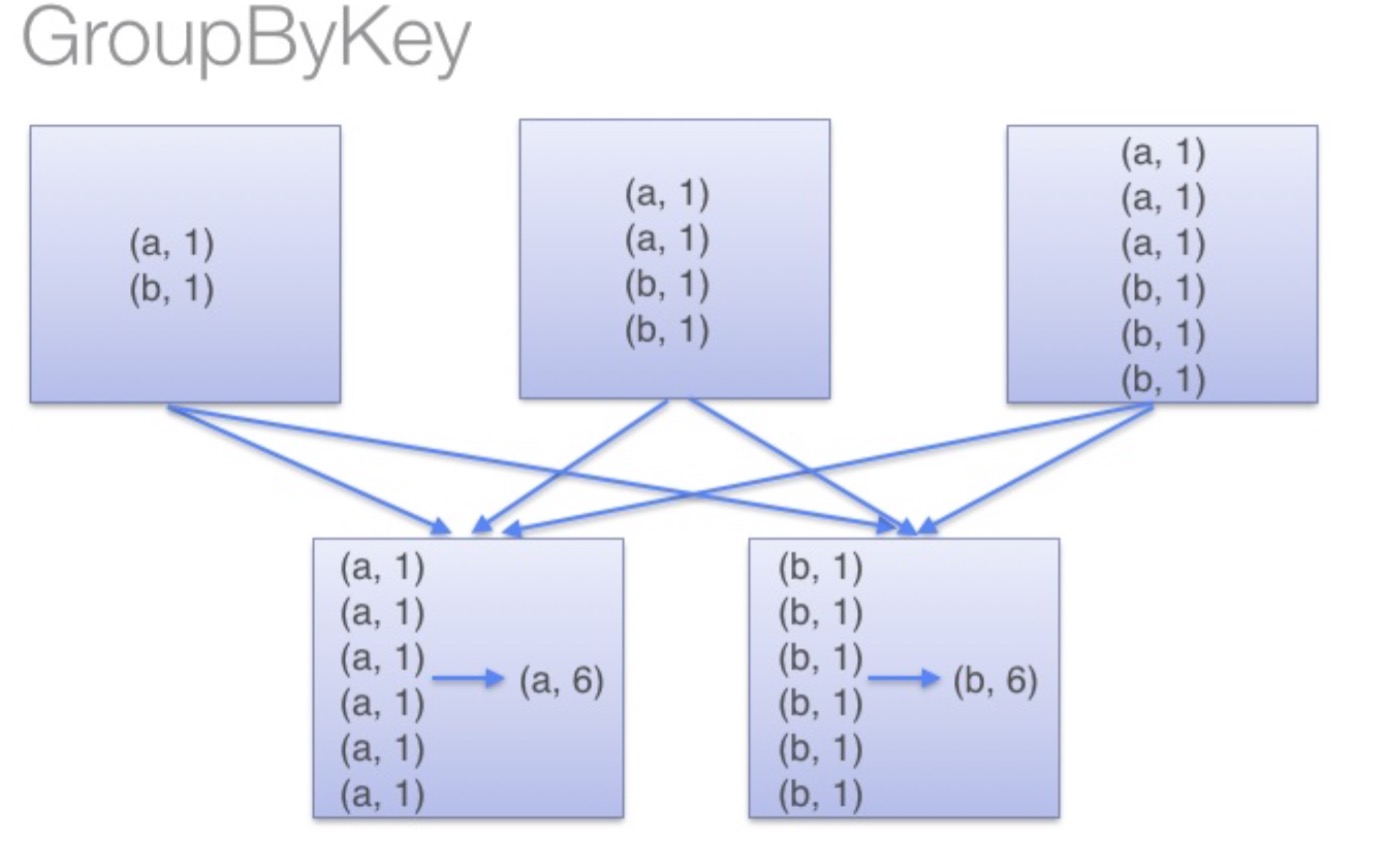
另一方面,当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动,在网络上传输这些数据非常没必要,因此避免使用 GroupByKey。
为了确定将数据对移到哪个主机,Spark会对数据对的key调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时Spark会把数据保存到磁盘上。 不过在保存时每次会处理一个key的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
我们来看看两个函数的实现:
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope { combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner) } /** * Note: As currently implemented, groupByKey must be able to hold all the key-value pairs for any * key in memory. If a key has too many values, it can result in an [[OutOfMemoryError]]. */ def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope { // groupByKey shouldn't use map side combine because map side combine does not // reduce the amount of data shuffled and requires all map side data be inserted // into a hash table, leading to more objects in the old gen. val createCombiner = (v: V) => CompactBuffer(v) val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2 val bufs = combineByKeyWithClassTag[CompactBuffer[V]]( createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false) bufs.asInstanceOf[RDD[(K, Iterable[V])]] }注意mapSideCombine=false,partitioner是HashPartitioner,但是groupByKey对小数据量比较好,一个key对应的个数少于10个。
他们都调用了combineByKeyWithClassTag,我们再来看看combineByKeyWithClassTag的定义:
def combineByKeyWithClassTag[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)]combineByKey函数主要接受了三个函数作为参数,分别为createCombiner、mergeValue、mergeCombiners。这三个函数足以说明它究竟做了什么。理解了这三个函数,就可以很好地理解combineByKey。
combineByKey是将RDD[(K,V)]combine为RDD[(K,C)],因此,首先需要提供一个函数,能够完成从V到C的combine,称之为combiner。如果V和C类型一致,则函数为V => V。倘若C是一个集合,例如Iterable[V],则createCombiner为V => Iterable[V]。
mergeValue则是将原RDD中Pair的Value合并为操作后的C类型数据。合并操作的实现决定了结果的运算方式。所以,mergeValue更像是声明了一种合并方式,它是由整个combine运算的结果来导向的。函数的输入为原RDD中Pair的V,输出为结果RDD中Pair的C。
最后的mergeCombiners则会根据每个Key所对应的多个C,进行归并。
例如:
var rdd1 = sc.makeRDD(Array(("A", 1), ("A", 2), ("B", 1), ("B", 2),("B",3),("B",4), ("C", 1))) rdd1.combineByKey( (v: Int) => v + "_", (c: String, v: Int) => c + "@" + v, (c1: String, c2: String) => c1 + "$" + c2 ).collect.foreach(println)result不确定欧,单机执行不会调用mergeCombiners:
(B,1_@2@3@4)(A,1_@2)(C,1_)在集群情况下:
(B,2_@3@4$1_)(A,1_@2)(C,1_)或者(B,1_$2_@3@4)(A,1_@2)(C,1_)mapSideCombine=false时,再体验一下运行结果。
有许多函数比goupByKey好:
- 当你combine元素时,可以使用
combineByKey,但是输入值类型和输出可能不一样 foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
//使用combineByKey计算wordcount wordsRDD.map(word=>(word,1)).combineByKey( (v: Int) => v, (c: Int, v: Int) => c+v, (c1: Int, c2: Int) => c1 + c2 ).collect.foreach(println) //使用foldByKey计算wordcount println("=======foldByKey=========") wordsRDD.map(word=>(word,1)).foldByKey(0)(_+_).foreach(println) //使用aggregateByKey计算wordcount println("=======aggregateByKey============") wordsRDD.map(word=>(word,1)).aggregateByKey(0)((u:Int,v)=>u+v,_+_).foreach(println)foldByKey,aggregateByKey都是由combineByKey实现,并且mapSideCombine=true,因此可以使用这些函数替代goupByKey。
参考
Spark中的combineByKey
databricks gitbooks
在Spark中尽量少使用GroupByKey函数
原文链接:http://www.jianshu.com/p/0c6705724cff
著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”。
- 深入理解groupByKey、reduceByKey
- 深入理解groupByKey、reduceByKey
- 深入理解groupByKey、reduceByKey
- groupByKey reduceByKey
- [spark]groupbykey reducebykey
- reducebykey groupbykey combinebykey
- groupByKey与reduceByKey区别
- groupByKey与reduceByKey区别
- reduceByKey与groupByKey的区别
- groupByKey 和reduceByKey 的区别:
- [pyspark] 尽量用reduceByKey而不用groupByKey
- Spark源码之reduceByKey与GroupByKey
- reduceByKey和groupByKey区别与用法
- reduceByKey和groupByKey区别与用法
- sparkrdd自动转换能用pairfun(否则无法用reducebykey,groupbykey)
- 【Spark系列2】reduceByKey和groupByKey区别与用法
- pair RDD groupByKey countByKey countByValue aggregateByKey reduceByKey 测试
- day17:RDD案例(join、cogroup、reduceByKey、groupByKey, join cogroup
- 第10篇 WebRTC-IOS之信令与RTCPeerConnection建立及SDP描述符 周三
- 安卓开发之自定义控件实现MaterialEditText
- 垂直行业网站destoon系统如何开启伪静态urlrewrite
- Ubuntu系统下安装AndroidStudio2.0 以及升级jdk的终端指令
- 可以滑动取消的消息指数
- 深入理解groupByKey、reduceByKey
- 事务的四个特性
- MySQL 正则表达式
- 【记事】
- 管程的思考
- AndroidStudio出现 Unknown verification type [95] in stack map frame 问题的解决办法
- URL优化之iis6.0如何开启伪静态
- Elasticsearch 2.X 自定义字段的Mapping
- kvm虚拟化的嵌套


