xgboost:一个纯小白的学习历程
来源:互联网 发布:淘宝优惠券怎么成代理 编辑:程序博客网 时间:2024/05/16 23:57
xgboost:一个纯小白的学习历程
标签(空格分隔): 机器学习 决策树 xgboost GBDT
短短三天,一开始对决策树都深感陌生的我在网上进行一番“扫荡”之后,研读了相关的技术博客,对各种名词进行了深度了解,也陆陆续续整理了自己的思路,接下来就谈谈这几天我都经历了什么吧~
为了能对xgboost有一个更好的认识,我还是把之前看过又有些遗忘的书《数据挖掘原理与实践》拿出来翻一翻,其中第3章中对于决策树的基本概念、构建及其三种算法都有较详细的解说如想了解此书,可点击此处,接下来我将对这三部分进行简要的阐述:
决策树
1. 决策树的基本概念
决策树(Decision Tree)是一种树型结构,包括决策节点(内部节点)、分支和叶节点三部分。作为一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。看图可能会更容易☟☟☟☟☟
决策树可以用来对未知样本进行分类,分类过程如下:从决策树的根节点开始,从上往下沿着某个分支往下搜索,直到叶节点,以叶节点的类标号值作为该未知样本所属类标号。
2. 决策树的构建
构建过程中主要考虑两方面:
(1)选合适的属性作为决策树的节点
(2)在适当的位置停止划分过程
3. 经典算法
主要有ID3算法(Iterative Dichotomiser 3)、C4.5算法、CART算法(分类回归树)以及Random Forest,下面通过表格来对这4个算法进行了解吧!~补充知识点:
1.信息熵():其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。可以被认为是系统有序化程度的一个度量。
2.信息增益:针对一个一个特征而言的,就是看一个特征,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息增益。其容易偏向取值较多的属性。 
3.上述算法仅仅是个简单介绍,具体的可以点击此处进行深入了解
对于决策树我们也有了进一步的了解,那么接下来就来看看xgboost是一个怎样的存在吧~不过深入了解之前我们稍微认识一下xgboost的前生GDBT~
GBDT(Gradient boosting Decision Tree)
1.基本概述
GBDT是以决策树(CART)为基学习器的GB算法,是GB和DT的结合。GBDT中的决策树是回归树,是个弱模型,深度较小一般不会超过5,叶子节点的数量也不会超过10,对于生成的每棵决策树乘上比较小的缩减系数(学习率<0.1),有些GBDT的实现加入了随机抽样(subsample 0.5<=f<=0.8)提高模型的泛化能力。通过交叉验证的方法选择最优的参数。另外,它主要由三个概念组成:Regression Decision Tree(即DT),Gradient Boosting(即GB),Shrinkage (算法的一个重要演进分枝,目前大部分源码都按该版本实现)2.核心
每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。例如:A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。3.两种描述版本
(1)残差版本:把GBDT说成一个迭代残差树,认为每一棵迭代树都在学习前N-1棵树的残差,详情请看博客GBDT(MART) 迭代决策树入门教程
(2)Gradient版本:把GDBT说成一个梯度迭代树,使用梯度迭代下降法求解,认为每一棵迭代树都在学习前N-1棵树的梯度下降值,详情请看博客 GBDT(Gradient Boosting Decision Tree) 没有实现只有原理
PS:相信看完这两个版本的描述之后你会对GBDT有一个很好的了解了,那么接下来我们就来看看xgboost吧~
xgboost
1.基本概述
xgboost的全称是eXtreme Gradient Boosting是Gradient Boosting Machine的一个c++实现,它扩展和改进了GDBT,如今风靡Kaggle、天池、DataCastle、Kesci等国内外数据竞赛平台,被称为速度快效果好的boosting模型。其支持Python,R,Java,Scala,C++等多种编程接口。2.特点
3.优化之处
(1)xgboost对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。另外,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。 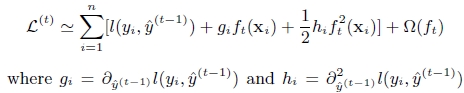
(2)xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合。 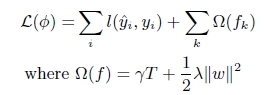
(3)xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算。
(4)对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
(5)xgboost工具支持并行。
(6)可并行的近似直方图算法。
上面对于xgboost的介绍仅仅是初步,接下来会对其进行更深入地分享~
参考资料:
1.xgboost: 速度快效果好的boosting模型
2.XGBoost浅入浅出
3.一步一步理解GB、GBDT、xgboost
4.xgboost导读和实战
- xgboost:一个纯小白的学习历程
- 一个程序员的学习历程
- 一个程序员的学习历程
- 一个程序员的学习历程
- 一个android的学习历程
- 一个程序员的学习历程(转)
- 一个c++程序员的学习历程自述
- 学习编程是一个漫长的历程
- 一个专科生的Java学习历程
- 一个立志终身学习的菜鸟之-------学习历程
- 一个程序员的历程
- 一个程序员的历程
- C_sharp:一个菜鸟学习历程
- 一个农民工学习LINUX内核的艰辛历程
- 一个初中学历程序员(本人)的学习历程
- 一个小程序员3个月的学习历程
- xgboost学习
- XGBoost学习
- ERROR: transport error 202: connect failed: Connection timed out
- 编程实现: 两个int(32位)整数m和n的二进制表达中,有多少个位(bit)不同?
- 机器学习笔记(二):matplotlib基础
- Win7系统无法验证文件数字签名(0xcoooo428)最佳解决方法
- ES5的Function新增的bind方法简单介绍
- xgboost:一个纯小白的学习历程
- Android四大组件之Service(一)
- UI控件的初始显示状态与Service的存亡状态绑定
- 我们需要什么样的前端开发环境
- http又来了
- Yeoman上安装数最多的generator
- 一步一步认识用户画像
- nyoj 255 C小加 之 随机数
- 简化DB2 9.7的安全模型


