多重left join去重
来源:互联网 发布:机械发展历史 知乎 编辑:程序博客网 时间:2024/04/29 08:57
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只 用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值。其原因是distinct只能返回它的目标字段,而无法返回其它字段,这个问题让我困扰很久,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的站来说,无疑是会直接影响到效率的,所以浪费了我大量时间。
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。关键词 distinct用于返回唯一不同的值。
1:通过 GROUP BY ***id DESC
SELECT
FROM zhengche zc LEFT JOIN zhengchebrand zb ON zc.zhengchebrand_id=zb.id
LEFT JOIN wishlist wl ON wl.product_id= zc.zhengche_id
WHERE zhengche_id IN
(SELECT wl.product_id FROM wishlist wl WHERE users_id=#{userId} AND wishlist_type=#{type})
GROUP BY zc.zhengche_id DESC
2通过distinct关键字
表A:
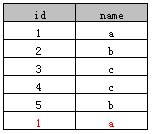
示例1
复制代码代码如下:
select distinct name from A
执行后结果如下:

示例2
复制代码代码如下:
select distinct name, id from A
执行后结果如下:
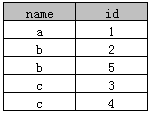
实际上是根据“name+id”来去重,distinct同时作用在了name和id上,这种方式Access和SQL Server同时支持。
示例3:统计
复制代码代码如下:
select count(distinct name) from A; --表中name去重后的数目, SQL Server支持,而Access不支持
select count(distinct name, id) from A; --SQL Server和Access都不支持
示例4
复制代码代码如下:
select id, distinct name from A; --会提示错误,因为distinct必须放在开头
0 0
- 多重left join去重
- distinct left out join group by order by之去重
- Left Join
- Left Join
- Left join
- left join
- left join
- left join
- LEFT JOIN
- Left Join
- left join
- left join
- left join
- left join
- left join
- Left Join
- left join
- left join
- 小白笔记-----------------------------关于使用UltraISO写入硬盘硬盘镜像...便捷启动...写入新的引导扇区...设备正忙的失败处理
- Telent查看应用使用的端口号
- Git的安装与配置
- Android 仿美团网,探索ListView的A-Z字母排序功能实现选择城市
- java注解的使用
- 多重left join去重
- linux 开启文件夹权限 开启用户用户组
- fetch请求;navigator界面跳转,传值
- 计划预算(PV)、实际完成工作预算(EV)、实际成本(AC)
- MFC 基础知识:对话框背景添加图片和按钮Button添加图片
- HashMap多线程问题详解
- 《Android5.1源码探究 —— ActivityManager(5):addAppTask (Activity activity, Intent intent, ActivityManager》
- error: openssl/opensslv.h: No such file or directory
- Effective Java 学习笔记(六、七)


