Hibernate映射组成关系
来源:互联网 发布:斯坦福英语软件下载 编辑:程序博客网 时间:2024/06/05 04:17
建立域模型和关系数据模型有着不同的出发点。
域模型(面向对象设计):由程序代码组成,通过细化持久化类的的粒度可提高代码的可重用性,简化编程。
关系数据模型(数据库设计):在没有数据冗余的情况下,应该尽可能减少表的数目,简化表之间的参照关系,以便提高数据的访问速度。
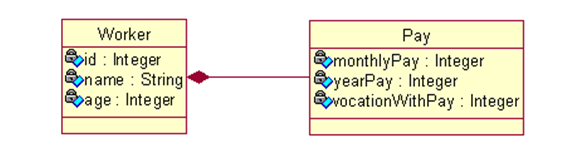
在这篇文章中我们以Worker(工人)和Pay(薪酬)之间的关系为例进行说明:
Hibernate 把持久化类的属性分为两种:
值(value)类型:没有OID,不能被单独持久化,生命周期依赖于所属的持久化类的对象的生命周期。
实体(entity)类型:有OID,可以被单独持久化,有独立的生命周期。
显然在上述例子中Worker为实体类型,Pay为值类型。如果我们将这两个类根据组成关系映射为数据库中的一张表而不是两张表,那么单表查询的速度是要快于多表查询的。
Hibernate 使用 <component> 元素来映射组成关系, 该元素表明 pay 属性是 Worker 类一个组成部分, 在 Hibernate 中称之为组件。
下面进行测试,首先新建两个java类:
public class Worker { private Integer id; private String name; private Pay pay; //getters and setters}public class Pay { private int monthlyPay; private int yearPay; private int vocationWithPay; //getters and setters}生成映射文件Worker.hbm.xml,并在映射文件中映射组成关系:
<!-- 映射组成关系 --> <component name="pay" class="Pay"> <parent name="worker"/> <!-- 指定组成关系的组件的属性 --> <property name="monthlyPay" column="MONTHLY_PAY"></property> <property name="yearPay" column="YEAR_PAY"></property> <property name="vocationWithPay" column="VOCATION_WITH_PAY"></property> </component>编写测试程序:
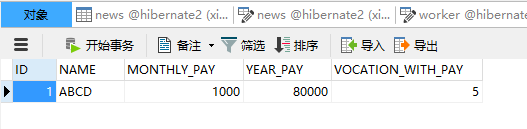
@Test public void testComponent(){ Worker worker = new Worker(); Pay pay = new Pay(); pay.setMonthlyPay(1000); pay.setYearPay(80000); pay.setVocationWithPay(5); worker.setName("ABCD"); worker.setPay(pay); session.save(worker); }运行程序,发现生成了一张数据表worker:

并且成功插入了记录:
0 0
- Hibernate映射组成关系
- Hibernate 映射组成关系
- Hibernate映射组成关系
- hibernate映射组成关系
- Hibernate -- 映射组成关系
- hibernate 映射组成关系
- Hibernate 映射组成关系
- Hibernate映射组成关系
- Hibernate之映射组成关系
- Hibernate映射组成关系简析
- hibernate 映射组成关系(第六章)
- 精通Hibernate——映射组成关系
- hibernate映射 【映射组成关系】,初学例子五
- 精通HIBERNATE---------读书笔记第十章 映射组成关系
- Hibernate学习笔记(五)【映射组成关系】
- Hibernate学习笔记(五)【映射组成关系】
- 7.映射组成关系
- 1009--映射组成关系
- 阿里云上 apt 安装 mysql5.7
- 安装SPAMS工具箱
- stursActionXML文件配置
- sparkStreaming集成Kafka
- 属于自己的《程序员的自我修养》之温故而知新
- Hibernate映射组成关系
- pat甲1118. Birds in Forest(并查集)
- android绘图初学
- 关于NFS服务器的使用
- (13)向量组的秩
- CMSIS 到底是什么?
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
- 队列
- java调用sap的RFC接口


