READING NOTE: Weakly Supervised Cascaded Convolutional Networks
来源:互联网 发布:詹姆斯总决赛数据科比 编辑:程序博客网 时间:2024/06/02 03:51
TITLE: Weakly Supervised Cascaded Convolutional Networks
AUTHOR: Ali Diba, Vivek Sharma, Ali Pazandeh, Hamed Pirsiavash, Luc Van Gool
ASSOCIATION: KU Leuven, Sharif Tech., UMBC, ETH Zürich
FROM: arXiv:1611.08258
CONTRIBUTIONS
A new architecture of cascaded networks is proposed to learn a convolutional neural network handling the task without
expensive human annotations.
METHOD
This work trains a CNN to detect objects using image level annotaion, which tells what are in one image. At training stage, the input of the network are 1) original image, 2) image level labels and 3) object proposals. At inference stage, the image level labels are excluded. The object proposals can be generated by any method, such as Selective Search and EdgeBox. Two differenct cascaded network structures are proposed.
Two-stage Cascade
The two-stage cascade network structure is illustrated in the following figure.
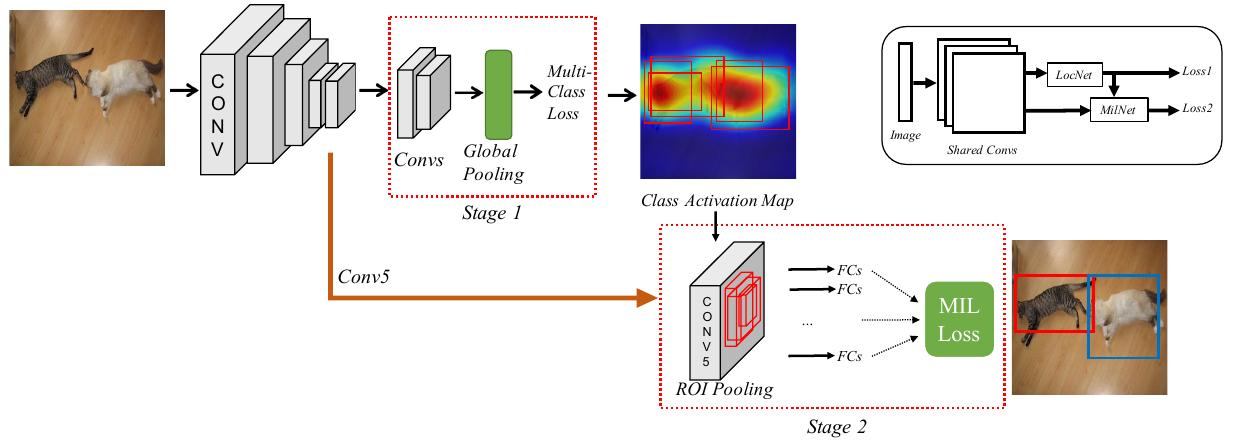
The first stage is a location network, which is a fully-convolutional CNN with a global average pooling or global maximum pooling. In order to learn multiple classes for single image, an independent loss function for each class is used. The class activation maps are used to select candidate boxes.
The second stage is multiple instance learning network. Given a bag for instances
Im my understanding, only the boxes with the most confidence in each category will be punished if they are wrong. Besides, the equations in the paper have some mistakes.
Three-stage Cascade
The three-stage cascade network structure adds a weak segmentation network between the two stages in the two-stage cascade network. It is illustrated in the following figure.
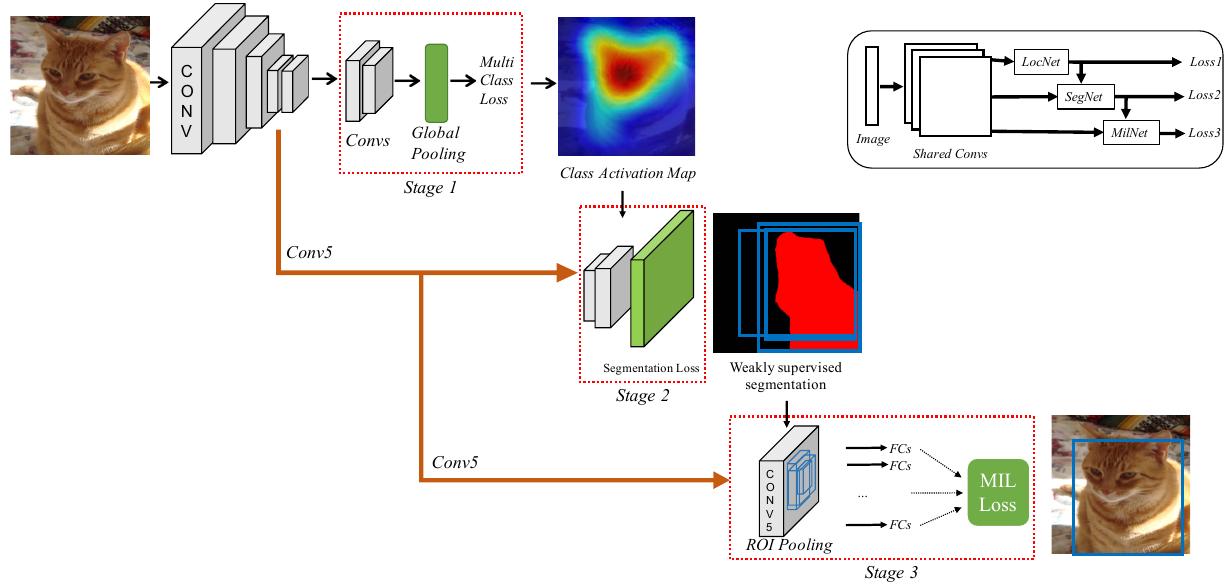
The weak segmentation network uses the results of the first stage as supervision signal.
Considering
where
SOME IDEAS
This work requires little annotation. The only annotation is the image level label. However, this kind of training still needs complete annotation. For example, we want to detect 20 categories, then we need a 20-d vector to annotate the image. What if we only know 10/20 categories’ status in one image?
- READING NOTE: Weakly Supervised Cascaded Convolutional Networks
- Weakly Supervised Object Recognition with Convolutional Neural Networks
- Weakly supervised object recognition with convolutional neural networks 论文解读
- READING NOTE: Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Trackin
- READING NOTE: Factorized Convolutional Neural Networks
- READING NOTE: Densely Connected Convolutional Networks
- Reading Note: Interpretable Convolutional Neural Networks
- 论文笔记:Weakly Supervised Deep Detection Networks
- Weakly Supervised Deep Detection Networks 阅读笔记
- READING NOTE: Chained Predictions Using Convolutional Neural Networks
- READING NOTE: Do semantic parts emerge in Convolutional Neural Networks?
- READING NOTE: Convolutional Pose Machines
- READING NOTE: Two-Stream Convolutional Networks for Action Recognition in Videos
- READING NOTE: R-FCN: Object Detection via Region-based Fully Convolutional Networks
- READING NOTE: R-FCN: Object Detection via Region-based Fully Convolutional Networks
- READING NOTE: Object Detection from Video Tubelets with Convolutional Neural Networks
- Reading Note: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- 论文笔记《IS object localization for free? Weakly-supervised learning with convolutional neural network》
- 拓扑排序学习笔记-Java
- elasticsearch使用river同步mysql数据
- 封装一个函数afterDate(date,n),得到日期date的n天后的日期
- Ubuntu 14.04下Redis安装报错:“You need tcl 8.5 or newer in order to run the Redis test”问题解决
- 计算机导论2--语言与算法
- READING NOTE: Weakly Supervised Cascaded Convolutional Networks
- 堆排序
- 未越狱iPhone访问限制密码忘了怎么办
- maven打包pom文件在windows和linux下的格式差异
- C#63课的主要内容
- 关于矩阵最通俗的解释
- C++ Primer课后练习 9-46
- JAVA小问题(持续更新)
- 线程总结


