神经网络基础整理系列(一)
来源:互联网 发布:java maven ant 编辑:程序博客网 时间:2024/05/16 11:02
本文主要是整理神经网络中的一些基础组件还有一系列的激活函数,如有错误请指出
模型术语
感知机
- 是人工神经元的类型之一,接受多个输入和并产生一个输出
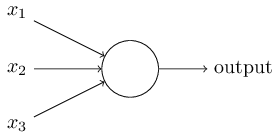
接受多个输入后进行加权去算,并输出是1或是0,其数学表达式为针对这个数学表达式我们做两个简化,首先是针对output=⎧⎩⎨⎪⎪⎪⎪01if ∑jwjxj≤ thresholdif ∑jwjxj> threshold ∑jwjxj 我们可以写成向量点乘的形式,也就是w⋅x ;然后针对threshold,我们可以将其移动到不等式的左边,并用 b= -threashold;则我们的数学表达式可以写成其几何图像如下所示output={01if w⋅x+b≤0if w⋅x+b>0 
- 在上个介绍中有b这个量,跟threshold有关,它也叫做偏置(bias),从生物细胞的角度这个量表示外界刺激激活(fire)神经元的容易程度;从表达式上来看,就是说我们的输出为1的容易程度,其越小, 输出越容易为1
- 利用感知机我们可以做
- 加权做选择(也就是根据影响因素的权值,将因素因素与权值进行加权和,并根据加权和与阀值的关系,作出选择)
- 实现基础的逻辑函数,比如AND,OR,NAND;考虑这个感知机
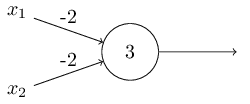
可以得到(x1,x2) = (0,0)时,值为3,输出1;(x1,x2)=(1,1)时,值为-1,输出0;(x1,x2)=(1,0)时,值为1,输出1;所以这个是NAND逻辑运算;
- 从上面我们已经知道了,使用单个的神经元(也就是感知机),可以通过分类使我们实现一些简单的函数功能,比如,如下的一些简单的逻辑运算,这里的分类主要是线性分类,也就是类别可以使用一个直线进行分离的,我们直接用Hugo Larochelle教授的神经网络课程 里面图进行说明
 上面是有两个输入的情况下实现一些简单的逻辑运算,虚线就是我们说的线性分离,线的一侧是一类,另一侧是另一类;但是有些对于一些运算是没有办法使用一个直线就区分开的,比如NOR运算
上面是有两个输入的情况下实现一些简单的逻辑运算,虚线就是我们说的线性分离,线的一侧是一类,另一侧是另一类;但是有些对于一些运算是没有办法使用一个直线就区分开的,比如NOR运算 
就没有办法只使用一个直线进行区分,怎么办呢?我们直接看结果
我们可以將输入使用更好的表示方式进行表达(提取合适分类的特征),使得线性分类可以进行;上图就是將两个输入进行了一次中间层的特征提取(也就是將数据从一种表达方式转换成另一种表达方式),然后再进行分类;也就是將网络结构扩展成
也就是我们下面要说的多层感知机
多层感知机
- 多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了与感知机一样有输入输出层外,它中间还可以有多个隐层,最简单的是只含有一个隐层,也就是三层的结构
首先我们看下输入层,这个输入层其实就是输入一个n维向量作为输入数据,n维向量对应n个神经元;接下来是隐藏层,它的神经元与前一层的神经元是使用全连接的方式的,也就是说本层的每个神经元与前一层的每一个神经元都有连接(也就是有一个权重),且都有一个偏置;也就是每层(除了输入层)的每个神经元都有一个权重向量和一个偏置用;假设我们的上一层的输入神经元的输入向量为al−1 的话,而本层的第j个神经元的权重向量为Wlj ,偏置为blj ,激活函数(详细可参考下面)为f,则我们本层的第j个神经元的输出值为其他也是类似的;对于 输出层呢,就是使用一个分类层,对我们前面得到的输出进行一个逻辑回归,比如使用softmax函数进行多类别的逻辑回归alj=f(Wljal−1+blj)

卷积神经网络
- 关于卷积神经网络呢,可以去参考 卷积神经网络,另外代码方面可以参考我的另一个 博文
- 我们首先要明白卷积神经网络的目的是去学习不同的卷积核(到神经网络中就是我们的权重和偏置了,到卷积神经网络中就是核的每个位置的值的大小了),来表示图片不同的特征,利用这些不同的特征来进行我们的图片处理问题,比如分类问题;
- 以训练ImageNet为例,我们如果只是使用普通的神经网络的话,也可以达到98%左右的效果,但是这里有一个问题,就是我们使用全连接层处理输入,因为我们还没有使用上图片的空间结构信息;而卷积神经网络就是使用了图片的空间结构来更好的达到图片分类的作用,同时使用上图片的空间结构在相同的网络层数的基础上,可以使用更少的参数,这样也可以让网络更快的训练,从而使增加层次成为可能;
- 卷积神经网络由三部分组成,local receptive fields(局部感受域),shared weights(共享参数),pooling(池化);
- 局部感受域,表示每个神经元不是连接止全部的输入像素,只是与一个区域有连接(也就是有权重),比如这个区域可以是5×5的;这里主要明白一个这个机制是怎么工作的就可以了;这里以输入层和第一层的隐层来说明,隐层的输出也可以看作是一个图片,而每个神经元会分别输出一个像素,构成这个图片;我们现在就是將我们的输入图片通过一个局部感受野(核)来生成这些我们的特征图的像素,如图产生前两个像素的过程(其中的步长使用1)


这个流程与我们使用普通的神经网络的区别就在于,我们使用普通的神经网络,使用的是全连接的,也就是可以认为局部感受野的大小就是图片的大小,而卷积神经网络的话,就是一个小窗口大小(比如5×5,3×3);这里还需要强调下,我们产生输出的时候,将感受野进行移动进行计算的操作其实在图像处理中叫做卷积操作,所以这种网络才叫做卷积神经网络;这里先说明一个卷积神经网络中,像素,图片,神经元之间的关系;我们从上面的图可以算出,我们的卷积层,通过对一个输入图片进行卷积操作得到了一个个输出图片的像素,这些图片我们后面会说到叫做特征图,每个层一般都会有多个这样的输出特征图,而特征图里面的每个像素就各自对应一个神经元,也就是一个神经元通过卷积操作输入图片的一个局部感受野的范围输出一个像素值; - 共享参数:关于共享参数这里我们主要理清楚一个问题就可以了,就是在卷积神经网络中参数是如何分配的;要说清楚这问题,我们先要说清楚两个概念,一个是特征图,一个是卷积核;直白的说,特征图就是我们每层的输出,就是我们上面的两个图片中右边的两个矩阵就是我们第一个卷积层的输出了,也就是这一层的输出特征图;再来看我们经典的Lenet-5结构里面,

可以看到我们的网络第一个卷积层的输出特征图有6个,每个的大小是28×28的;接下来就是我们的卷积核了,直白来说就是我们在对输入特征图进行卷积操作得到我们的输出特征图时,使用的参数,它的大小就是局部感受野的大小;回到我们的共享参数上来,共享参数的意思就是我们在生成一个输出特征图的时候,针对同一个输入特征图的卷积核是为所有神经元共享的,也就是说在生成一个输出特征图所有像素的时候,针对一个输入特征图使用的都是同一个卷积核,至于为什么可以这么做,是因为我们有理由相信关于同一个特征的描述在一个图片中应该是各自一致的
我在上面反复说明的共享是针对生成一个输出特征图使用在同一个输入特征图上的,这是因为往往我们会有不止一个输入特征图,也不止有一个输出牲图,我们拿lenet-5里面的第二个卷积层来说,我们可以看到这一层有6个输入特征图,每个特征图是14×14的,而输出特征图有16个,每个的大小是10×10的;那么问题就来了,怎么通过多个输入特征图得到多个输出特征图呢?这个过程是怎么样的一个过程呢?首先看一下运算的公式xlj=f(∑i∈Mjxl−1i∗klij+blj) xlj 表示第l层的第j个输出特征图,而f表示我们的激活函数,而Mj 表示在生成第j个输出特征图时使用的输入特征图下标的集合,这里我们直接让Mj 就等于所有的输出特征图下标组成的集合,而klij 表示第l层在生成第j个输出特征图时应用在第i个输入特征图上的卷积核,是一个5×5的矩阵,blj 表示第l层在生成第j个输出特征图时使用的偏置值,是一个标量;公式的意思就是如果我们第l层有n个输入特征图,我们在生成第l层的第j个输出特征图时,是让每一个输入特征图与其对应的卷积核进行卷积操作,得到n个矩阵,将这些矩阵进行矩阵加法(对应位置相加),再将每一个位置的值加上我们的偏置,最后每一个位置的值再进行激活就可以得到我们的输出特征图所以呢,可以这么理解,如果有n个输入特征图的话,我们每个输出特征图对应了n个卷积核加上一个偏置的参数量,而我们的网络就是用来学习出这些参数的;回到我们的lenet-5的第二个卷积层那里,我们总的卷积核的个数是16×6了,而参数就是16×6×5×5+1(加上一个偏置)了,而对于输出特征图的大小就是14-5+1=10了,可以通过观察一下卷积的操作看出来,如下图
至于为什么需要多个输出特征图呢?主要是因为更多的特征图表示我们可以提取更多的特征,这样我们的后面的层可以使用的特征组合也就更多,效果也就会更好了。 - 池化:池化从作用上来说是简化卷积操作产生的结果,从效果上来看就是进行了一次下采样的操作;所以池化层一般在卷积层后面;池化也会使用一个类似核一样的区域,比如使用一个2×2的,那么它的作用就是使用这个去对卷积产生的特征图进行下采样,一般使用的池化操作有最大值池化(在四个像素中取一个最大值作为输出)还有L2池化(平方和开根),均值池化

使用池化一方面可以压缩我们的信息,另一方面可以减少后续操作的参数个数 - 总结起来,就是这样的一个图

- 卷积层是不需要进行正则化的,因为我们知道卷积层是参数共享的,它们是被强制去学习整个图片的信息,基本不可能去学习出一些局部的噪音出来
激活函数
sigmoid函数
- sigmoid函数是logistic 函数的一种,它的数学表达形式是它的图像是
S(z)=11+e−z 
这个函数的求导过程为我们可以很容易得到它的导函数的图像为(11+e−z)′=−e−z(1+e−z)2∗(−z)′=e−z(1+e−z)2=11+e−z∗(1−11+e−z) 
- 这种类型的函数有什么作用呢?首先一点是它的函数值是在(0,1)之间的,而且函数值的变化是连续的,也就是其本身是可导的,函数值不会突然变化;而且从图像中我们可以看出,这个函数在函数值接近0和接近1时的导数都接近于0,其值非常小;
- 但是这种函数在输出值在0或是1的附近时,它就达到饱和了,此时学习速率会很小
- sigmoid的权重和偏置的初始化一般都是弄成一个正态分布,X~N(0,sqrt(1/n_out))
tanh函数
- 它的数学定义
tanh(z)≡ez−e−zez+e−z - tanh函数与sigmoid函数的关系有所以其实tanh可以看作是sigmoid的变种,它的函数图像
σ(z)=1+tanh(z/2)2 
- tanh函数有时表现得比sigmoid要好,主要的原因在于我们权重和偏置更新的时候,比如l+1层权重它的更新值为
alkδl+1j ,假如我们使用了sigmoid的话,因为sigmoid的结果所有的值都是正的,它的正负取决于δl+1j ,所以如果它是正的话,那么所有与之相连的输入权重(wl+1jk )都的更新值都是正的; 也就是说与同一个神经元相连的输入权重在同一轮迭代中的更新值的符号是一样;这并不是很好;所以使用tanh就可以避免这个问题(关于这个优点的理解要对反向传播的推导有一定理解)
RELu函数
- 它也是sigmoid的一种变种,全称是rectified linear neuron; 其数学定义为函数图像如下:
max(0,w⋅x+b) 
虽然它的样式与softmax和tanh不大一样,但是这也与前两者一样可以拟合出任何的函数;而且在神经网络中,在大多数情况下,使用这种类型的函数会比使用前两者的效果要好;一个直观的解释就是无论是sigmoid还是tanh都一样会在饱合状态(加权值为0或1时)学习速率很小,但是RELu并不会有这个问题;另一个方面从反向传播公式中可以看出,结合RELu函数,我们的误差值只在等于0或是小于0的时候等于0,其余的情况都等于∇aC ,这种性质就很好了,可以根据直接梯度进行调整 - 关于它的作用可以参考,知乎

softmax函数
- 它的数学定义为
softmax(z)=ez∑Kk=1ezk - 可以参考;这个文章针对softmax的求导和和损失函数的求导都进行了细致的推导
- softmax层的权重和偏置初始化一般都直接置为0
损失函数
什么叫做损失函数
- 要理解什么叫做损失函数;首先要知道我们做机器学习也好,做神经网络也好,我们都是希望通过大数据来学习我们模型的参数,让我们的参数模型去拟合我们的数据(根据输入得到输出),而损失函数就是我们在进行训练我们的参数时,我们的模型预测的结果与真实的结果之间的距离,这种距离的不同定义就产生了不同的损失函数;但是损失函数都会有两个一样的性质;首先一个是它的值是非负的,值越大表示模型目前效果还不好;另一个就是当预测值与真实值越接近时,它的值就越小
- 在下面我们会使用统一使用C表示损失函数,m表示数据用例的量,
x(i) 表示第i个输入,y(i) 表示对应的真实标签,而a(i) 表示对应我们的预测值,ak 表示我们的第k个输出(因为我们的模型可能有多个输出),f表示我们的激活函数
平方损失函数(quadratic cost function)
- 关于平方损失函数,是我们在机器学习中使用得比较多的一种损失函数了,它的定义也比较简单这里如果我们的第j个权重表示为
C=12m∑i=1m(a(i)−y(i))2 wj ,而偏置使用b 的话,则我们的我们可以得到我们权重和偏导对应的偏导为a(i)=f(∑jwjx(i)j+b) ∂C∂wj=1m∑im(a(i)−y(i))∂f∂wj∂C∂b=1m∑im(a(i)−y(i))∂f∂b - 一般 而言,平方损失函数会与线性的激活函数配合使用
交叉熵代价函数(cross-entropy cost function)
- 这种代价函数也叫做logistic回归代价函数,一般是用于sigmoid函数做为激活函数时使用的,首先先来看定义它为什么是一个损失函数,按前面说的它要满足两个条件
C=−1n∑x[ylna+(1−y)ln(1−a)] - 第一个它的值是非负数;我们知道在sigmoid函数作为激活函数时,a的值是(0,1),所以lna和ln(1-a)的值是都是负的,而y的值只可能是0或1(是二分类的问题),而y与1-y值都是非负的,所以看加方程就知道它是个正数了;
- 第二个要求是当y与a很接近的时候,C的值要接近0(自行代入y=0和y=1)
- 接下来我们来看下它的求导结果我们知道在sigmoid作为激活函数的时候,它的求导结果是
∂C∂wj=−1n∑x(yσ(z)−(1−y)1−σ(z))∂σ∂wj=−1n∑x(yσ(z)−(1−y)1−σ(z))σ′(z)xj=1n∑xσ′(z)xjσ(z)(1−σ(z))(σ(z)−y) σ′(z)=σ(z)(1−σ(z)) ,所以最终我们可以得到∂C∂wj=1n∑xxj(σ(z)−y) - 这个公式很容易就可以拓展到有多个输出神经元的情况下
C=−1n∑x∑j[yjlnaLj+(1−yj)ln(1−aLj)]
对数似然代价函数(log-likelihood cost function)
- 对于这种代价函数,一般是使用softmax作为激活函数,它的定义是而它对应的偏导是
C=−∑kyklog(ak) ∂C∂bj=aj−yj∂C∂wjk=aL−1k(aLj−yj) - 关于这种代价函数可以参考 对数似然
负对数似然代价函数(negative log-likelihood cost function)
是logistic回归代价函数的推广,其定义式为
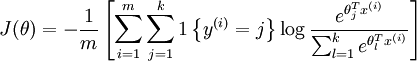
如何理解这个代价函数呢?首先看一下这个代价函数做的事情,log部分是计算出了本次用例i得到的所有k个输出,亡为log数组,代表了k个概率,也就是k个类别的可能性;然后我们要去取这些个输出中猜对的那个的概率,也就是说比如我们的y = 3,我们就取第3个输出的概率值也就是log[3],而就可以表示这样的做用,它是值当大括号里面的值为正时,取1,否则取0;关于更多的这方面的内容可以参考urfldl1{y(i)=j} 关于这些个损失函数与激活函数的搭配问题可以查看我的神经网络基础整理系列二
参考
- http://neuralnetworksanddeeplearning.com/
- http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92#.E4.BB.A3.E4.BB.B7.E5.87.BD.E6.95.B0
- http://list.youku.com/albumlist/show?id=22795577&ascending=1&page=1
0 0
- 神经网络基础整理系列(一)
- 神经网络基础整理系列(二)
- 神经网络基础介绍(一)
- deeplearning系列(一)浅层神经网络
- 深度学习基础(一)神经网络
- 二值化神经网络系列一:二值化神经网络介绍
- 二值化神经网络系列一:二值化神经网络介绍
- 整理JAVA基础(一)
- Java基础整理(一)
- Java 基础整理(一)
- java基础整理一(基础准备)
- 多线程系列基础(一)
- java基础系列(一)
- java基础系列(一)
- C++ 人工智能算法系列一(神经网络算法基础知识)
- 基于BP神经网络的数字识别基础系统(一)
- 吴恩达Deeplearning.ai专项课程笔记(一)-- 神经网络基础
- java基础整理十四(集合一)
- retrofit2学习笔记
- 创建 Pool & VIP - 每天5分钟玩转 OpenStack(122)
- python np.stack()解析
- Kafka的 Consumer和Producer
- #Qt+VS#01计算圆的面积
- 神经网络基础整理系列(一)
- 161206
- Linux命令种类和帮助
- 一起talk C栗子吧(第一百九十回:C语言实例--文件定位三 )
- gdfsg
- poj 2352 Stars
- 类图
- 基本线性回归两种方法实现
- Python--CentOS 从Python2.6升级到Python2.7


