kdtree&knn
来源:互联网 发布:java培训机构大全 编辑:程序博客网 时间:2024/04/29 05:57
前言:本文关于kdtree的知识基本来源于kdtree_wiki
一、what's kdtree
kdtree是 k-dimensional tree的缩写,它是一种用于组织k维空间中数据点的基于空间划分的数据结构。kdtree常用于搜索多维搜索词,包括区间搜索和最近邻搜索。kdtree是一种二叉树结构,它是BSP(Binary space partationing)树的一种特殊情况。【注:BSP的空间划分的超平面是任意的,而kdtree中是的划分超平面是垂直坐标轴的。】

[ from wikipedia ]A 3-dimensional k-d tree. The first split (the red vertical plane) cuts the root cell (white) into two subcells, each of which is then split (by the green horizontal planes) into two subcells. Finally, those four cells are split (by the four blue vertical planes) into two subcells. Since there is no more splitting, the final eight are called leaf cells.
二、operations on kdtree
1.建树
因为存在很多种选择轴对齐( axis-aligned )划分平面的方法,所以存在很多种不同的构建kdtree的方法。
规范的构建方法有如下限制:
1)随着移动到树的底端,我们不断地循环坐标axes来划分空间;
2)通过选择子树中点的中位数,来插入点。
伪代码如下:
function kdtree (list of points pointList, int depth){ // Select axis based on depth so that axis cycles through all valid values var int axis := depth mod k; // Sort point list and choose median as pivot element select median by axis from pointList; // Create node and construct subtrees var tree_node node; node.location := median; node.leftChild := kdtree(points in pointList before median, depth+1); node.rightChild := kdtree(points in pointList after median, depth+1); return node;}对那些在median上的点,我们其实也可以使其属于分裂后的某个子空间,比如分裂得到的子集定义为“小于”和“大于等于”。
该方法构建了一个平衡kdtree(通过选择中位数),但是平衡树并不是对所有应用都是最优的。
并且,这种方法需要寻找中位数(每次O(N)复杂度),或者是对所有点进行堆排序或归并排序(复杂度O( nlogn ))。一个常用的实践方法是随机选取一定的点,对它们进行排序,并从中选择中位数。这种方法在实践中经常生成优雅的平衡树。
可以先预排序(presort)点,然后构建kdtree,来减少每次寻找中位数的花销。
2.添加元素
添加元素的方法就是按照树的规律不断向下找到该插入的位置。插入元素要注意的是,它可能会影响树的平衡性。
3.移除元素
4.平衡
因为kdtree是在多维度上排序的,所以树旋转的平衡方法并不适用。
5.最近邻搜索
最近邻搜索意在树中搜索得到与给定点最近的点。最近邻搜索可以kdtree树高效地实现,因为kdtree可以快速地移除不满足搜索条件的搜索空间。
1)从根节点开始,递归地往下移动;
2)一旦算法移动到叶子节点,那么将该节点作为“当前最佳”;
3)算法展开树的递归,在每个节点上执行如下步骤:
a.如果当前点更近,那么将其作为当前最佳;
b.算法检查分裂平面的另一边,看是否有比当前最近的点。概念上,这是通过检查以目标点为球心,目标点到当前最近点的距离为半径的超球面来实现的,该超球面可以横贯子空间。
如果该超球面穿过某分裂平面,那么可能在平面另一边有更近的点,那么算法必须从该点的另一分支向下搜索。
如果不想交,那么算法继续沿树向上,该点的另一个分支被忽略。
举一个栗子:样本集{(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)},建树如下:
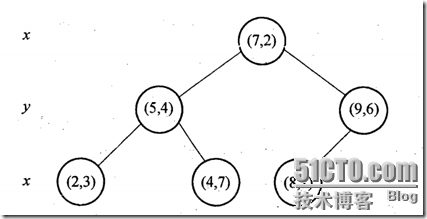
我们来查找点(2.1,3.1),在(7,2)点测试到达(5,4),在(5,4)点测试到达(2,3),然后search_path中的结点为<(7,2), (5,4), (2,3)>,从search_path中取出(2,3)作为当前最佳结点nearest, dist为0.141;
然后回溯至(5,4),以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆,并不和超平面y=4相交,如下图,所以不必跳到结点(5,4)的右子空间去搜索,因为右子空间中不可能有更近样本点了。
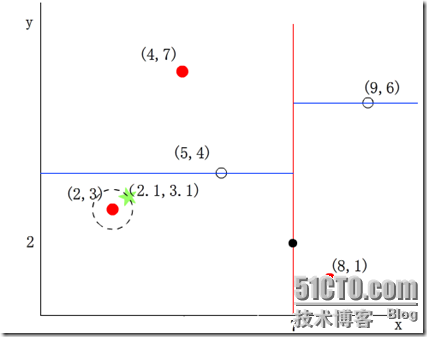
于是在回溯至(7,2),同理,以(2.1,3.1)为圆心,以dist=0.141为半径画一个圆并不和超平面x=7相交,所以也不用跳到结点(7,2)的右子空间去搜索。
至此,搜索结束,返回最近点(2,3)。
注意:若查找的target节点与当前节点的axis轴相交,则需查找target节点的child,注意这里查找child节点需要递归调用该查找方法,而不是简单地将其child节点添加到查找栈中。为什么呢?
我们首先搜索到“最近的”叶子节点,然后往上回溯,这时候上面这个点axis上的轴如果与目标节点相交的话,则要搜索上面这个点的另一半子空间。这个子空间还得用这个搜索函数去递归的搜索,为什么不是简单的添加那个节点的child呢?原因就在于向上回溯有这个性质,向下回溯可没有啊。所以还是得对这个子空间用一样的方法去搜索。如图:

后记:看到这里会发现,为了搜索那个超球体内可能的更近邻,需要大量的回溯,这会大大影响搜索性能。因此研究人员有提出改进的kdtree近邻搜索,其中一个比较著名的就是Best-Bin-First,它提供设置优先级队列和运行超时限定来获取近似的最近邻,有效减少回溯的次数。这个我也没研究过,有时间看看~
6.区间搜索
三、用kdtree实现KNN
1. scipy.spatial.KDTree
scipy实现了kdtree,用起来很方便。只需要用训练数据建一个kdtree,然后用kdtree的query函数找最近邻,然后投票即可。代码如下:
"""@ knn lazy learning@ kdtree for k-nearest-neighbor searching@ wttttt at 2016.12.12"""import numpy as npimport pandas as pdfrom scipy.spatial import KDTreeimport sys# step1: reading datadef load_data(): train = pd.read_csv('train.csv') test = pd.read_csv('test.csv') y = train.iloc[:, -1] train = train.drop(labels= train.columns[-1], axis=1) return train, y, testtrain, y, test = load_data()train = train[:, 1:] # removing idtest_id = test[:, 0]test = test[, 1:] # removing id# step2: constructig kdtree for training datatree = KDTree(train)#find the k nearest neighborif len(sys.argv) <= 1: print 'please implement arguments for knn\'s k.'dis, nearest_loc = tree.query(x=test, k= sys.argv[1], p=2) # p=2 means Euclidean distance# vote for predictiony_test = [] # storing the y of testing datafor i in range(nearest_loc.shape[0]): print 'predicting for test id {0}'.format(test_id[i]) classCounter = {} # vote for pos in nearest_loc[i]: classCounter[y[pos]] = classCounter.get(y[pos], 0) + 1 y_test.append(sorted(classCounter)[0]) print 'predicted: y is {0}'.format(y_test[-1])print 'all prediction is done, writing...'with open('result_knn_kdtree.csv') as fi: for i in range(len(y_test)): fi.write(('{0},{1}\n').format(test_id[i], y_test[i]))2.自己动手写kdtree
1)首先要建树
建树这里考虑的还是用上面提到的“循环+中位数”的方法。中位数的 查找并没有用上预排序的方法(还没想明白- -)。伪代码如下:
assignment on this point if no more than one sample to split: # stop condition returnaxis = iter_num mod n_dim # the axis chosen to splitfind median in this axisiteration on left child # iterationiteration on right child
2)然后实现k近邻搜索的方法
create a iter_list to store searching pathfind the 'nearest' leafcreate a large heap to store current 'nearest' neighborsfor point on iter_list(backtracking upside): if heap.len < k: add this point to heap elif dis(point,target)<current_max_dis: heap.pop() add this point to heap if not intersect: continue recursion, search subspace3)代码实现:
参见github,https://github.com/wttttt-wang/ml_algo_realization,这上面是实现了上述的所有算法。
另外,附上用线性方法实现的knn的代码:
"""@ knn lazy learning@ two ways: general searching & kdtree searching@ wttttt at 2016.12.07"""import numpy as npimport pandas as pddef load_data(): # read training data as numpy.array, attention that containing id & y # train = numpy.loadtxt(open('train.csv','rb'), delimiter=',', skiprows=1) # test = numpy.loadtxt(open('test.csv','rb'), delimiter=',', skiprows=1 ) # containing id train = pd.read_csv('train.csv') test = pd.read_csv('test.csv') y = train.iloc[:, -1] train = train.drop(labels= train.columns[-1], axis=1) return np.array(train), np.array(y), np.array(test)# square distancedef do_classify(k=10): train, y, test = load_data() num_instance, num_cols = train.shape train = train[:, 1:] # removing id y_test = [] # storing the y of testing data for test_one in test: # for each testing instances print 'predicting for test id{0}'.format(test_one[0]) test_one = test_one[1:] # removing id # compute the diff of the test instance of each train instance diff = train - np.tile(test_one, (num_instance, 1)) squre_diff = np.square(diff) distance = np.sum(squre_diff, axis=1)**0.5 # the square distance topk_index = np.argsort(distance) classCounter = {} for i in range(k): classCounter[y[topk_index[i]]] = classCounter.get(y[topk_index[i]],0) + 1 y_test.append(sorted(classCounter)[0]) print 'predicted: y is {0}'.format(y_test[-1]) print 'all prediction is done, writing...' with open('result_knn.csv', 'w') as fi: for i in range(len(y_test)): fi.write(('{0},{1}\n').format(test[i, 0], y_test[i]))- kdtree&knn
- HDU 4347 KNN+KDTree
- 基于KDTree的KNN实现
- kdtree
- kdTree
- KDtree
- KDTree复杂度
- 详解KDTree
- kdtree学习
- KDTree 【转】
- knn
- knn
- KNN
- KNN
- KNN
- KNN
- KNN
- knn
- python实现的推荐算法
- hadoop学习笔记
- Jquery 版本兼容性 attr("checked") 返回undefined或失效
- zmq_recvmsg
- React Native之样式
- kdtree&knn
- hadoop与zookeeper完全分布式安装
- 15.3 写入二进制数据
- throw 和 throws
- 五个典型的JavaScript面试题
- 更新JAVA最新JDK遇到的问题
- 编译超过2000+错误Error:warning: Ignoring InnerClasses attribute for an anonymous inner class
- zmq_send
- 15.4 ZIP文档


