梯度训练算法
来源:互联网 发布:jq删除数组中指定元素 编辑:程序博客网 时间:2024/05/19 00:42
1. batch GD
每次迭代的梯度方向计算由所有训练样本共同投票决定,
batch GD的损失函数是:
训练算法为:
什么意思呢,batch GD算法是计算损失函数在整个训练集上的梯度方向,沿着该方向搜寻下一个迭代点。”batch“的含义是训练集中所有样本参与每一轮迭代。
2. mini-batch GD
batch GD每一轮迭代需要所有样本参与,对于大规模的机器学习应用,经常有billion级别的训练集,计算复杂度非常高。因此,有学者就提出,反正训练集只是数据分布的一个采样集合,我们能不能在每次迭代只利用部分训练集样本呢?这就是mini-batch算法。
假设训练集有m个样本,每个mini-batch(训练集的一个子集)有b个样本,那么,整个训练集可以分成m/b个mini-batch。我们用
表示第j轮迭代中所有mini-batch集合,有:
那么, mini-batch GD算法流程如下:
--------------------
问题的引入:
考虑一个典型的有监督机器学习问题,给定m个训练样本S={x(i),y(i)},通过经验风险最小化来得到一组权值w,则现在对于整个训练集待优化目标函数为:
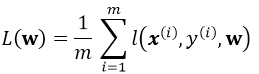
其中![]() 为单个训练样本(x(i),y(i))的损失函数,单个样本的损失表示如下:
为单个训练样本(x(i),y(i))的损失函数,单个样本的损失表示如下:
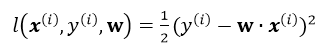
引入L2正则,即在损失函数中引入![]() ,那么最终的损失为:
,那么最终的损失为:
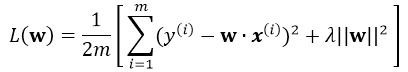
注意单个样本引入损失为(并不用除以m):
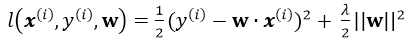
正则化的解释
这里的正则化项可以防止过拟合,注意是在整体的损失函数中引入正则项,一般的引入正则化的形式如下:
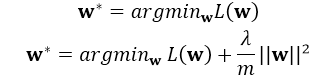
其中L(w)为整体损失,这里其实有:

这里的 C即可代表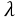 ,比如以下两种不同的正则方式:
,比如以下两种不同的正则方式:
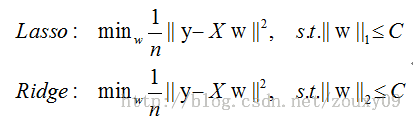
下面给一个二维的示例图:我们将模型空间限制在w的一个L1-ball 中。为了便于可视化,我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解
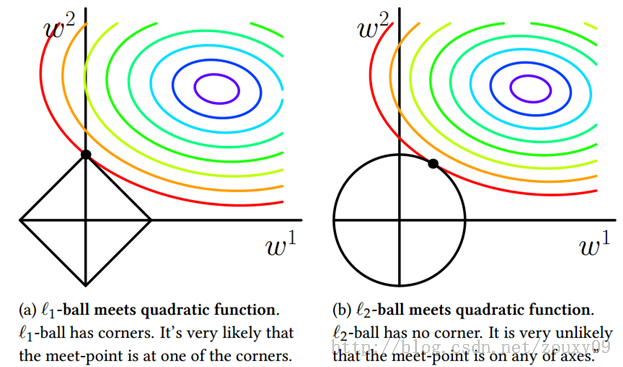
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性,相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
Batch Gradient Descent
有了以上基本的优化公式,就可以用Gradient Descent 来对公式进行求解,假设w的维度为n,首先来看标准的Batch Gradient Descent算法:
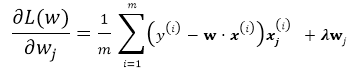
repeat until convergency{
for j=1;j<n ; j++:
![]()
}
这里的批梯度下降算法是每次迭代都遍历所有样本,由所有样本共同决定最优的方向。
stochastic Gradient Descent
随机梯度下降就是每次从所有训练样例中抽取一个样本进行更新,这样每次都不用遍历所有数据集,迭代速度会很快,但是会增加很多迭代次数,因为每次选取的方向不一定是最优的方向.
repeat until convergency{
random choice j from all m training example:
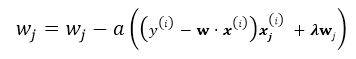
}
mini-batch Gradient Descent
这是介于以上两种方法的折中,每次随机选取大小为b的mini-batch(b<m), b通常取10,或者(2...100),这样既节省了计算整个批量的时间,同时用mini-batch计算的方向也会更加准确。
repeat until convergency{
for j=1;j<n ; j+=b:
![]()
}
最后看并行化的SGD:

若最后的v达到收敛条件则结束执行,否则回到第一个for循环继续执行,该方法同样适用于minibatch gradient descent。
3. Stochastic GD (SGD)
随机梯度下降算法(SGD)是mini-batch GD的一个特殊应用。SGD等价于b=1的mini-batch GD。即,每个mini-batch中只有一个训练样本。
4. Online GD
随着互联网行业的蓬勃发展,数据变得越来越“廉价”。很多应用有实时的,不间断的训练数据产生。在线学习(Online Learning)算法就是充分利用实时数据的一个训练算法。
Online GD于mini-batch GD/SGD的区别在于,所有训练数据只用一次,然后丢弃。这样做的好处是可以最终模型的变化趋势。比如搜索广告的点击率(CTR)预估模型,网民的点击行为会随着时间改变。用batch算法(每天更新一次)一方面耗时较长(需要对所有历史数据重新训练);另一方面,无法及时反馈用户的点击行为迁移。而Online Leaning的算法可以实时的最终网民的点击行为迁移。
机器学习中梯度下降(Gradient Descent, GD)算法只需要计算损失函数的一阶导数,计算代价小,非常适合训练数据非常大的应用。
梯度下降法的物理意义很好理解,就是沿着当前点的梯度方向进行线搜索,找到下一个迭代点。但是,为什么有会派生出 batch、mini-batch、online这些GD算法呢?
原来,batch、mini-batch、SGD、online的区别在于训练数据的选择上:
batchmini-batchStochasticOnline训练集固定固定固定实时更新单次迭代样本数整个训练集训练集的子集单个样本根据具体算法定算法复杂度高一般低低时效性低一般(delta 模型)一般(delta 模型)高收敛性稳定较稳定不稳定不稳定- 梯度训练算法
- 采用动量梯度下降算法训练 BP 网络
- 3模型训练和最优化-3.3模型训练之梯度反向传播算法(上)
- 3模型训练和最优化-3.4模型训练之梯度反向传播算法(下)
- 机器学习的训练算法(优化方法)汇总——梯度下降法及其改进算法
- 运用比例共轭梯度动量算法(trainscg)来训练BP网络
- 从梯度下降到拟牛顿法:详解训练神经网络的五大学习算法
- 逻辑回归-梯度下降训练
- 知识 | 梯度下降训练法
- 神经网络的训练--批量梯度下降 VS. 随机梯度下降
- 训练深度网络的梯度弥散及梯度膨胀问题
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
- batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
- MATLAB laplace梯度算法
- 随机梯度下降算法
- 随机梯度算法
- 梯度下降算法
- Hadoop Snappy安装终极教程
- bootstrap-多层模态框滚动条消失问题
- aapt
- android与js交互的方式(包括三种)
- UIScrollView 的基本使用
- 梯度训练算法
- 无刷直流电机的驱动的基本原理
- 复杂链表的复制
- C#进程间使用同步EVENT事件
- iOS通知观察者的添加和移除
- TextInputLayout的学习和应用
- java.net.BindException: Address already in use解决方法
- 尝试新思路——CError的另一种实现方式
- Ubuntu16.04安装jdk1.8(tar.gz方式)


