优酷视频下载爬虫
来源:互联网 发布:程序员对浏览器的 编辑:程序博客网 时间:2024/05/05 00:35
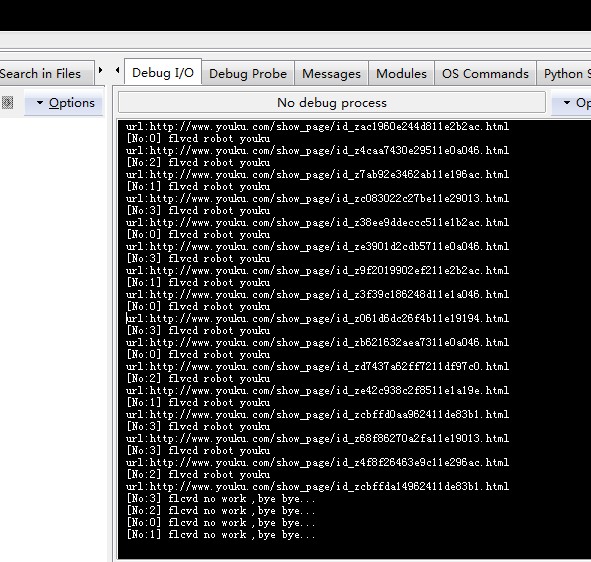
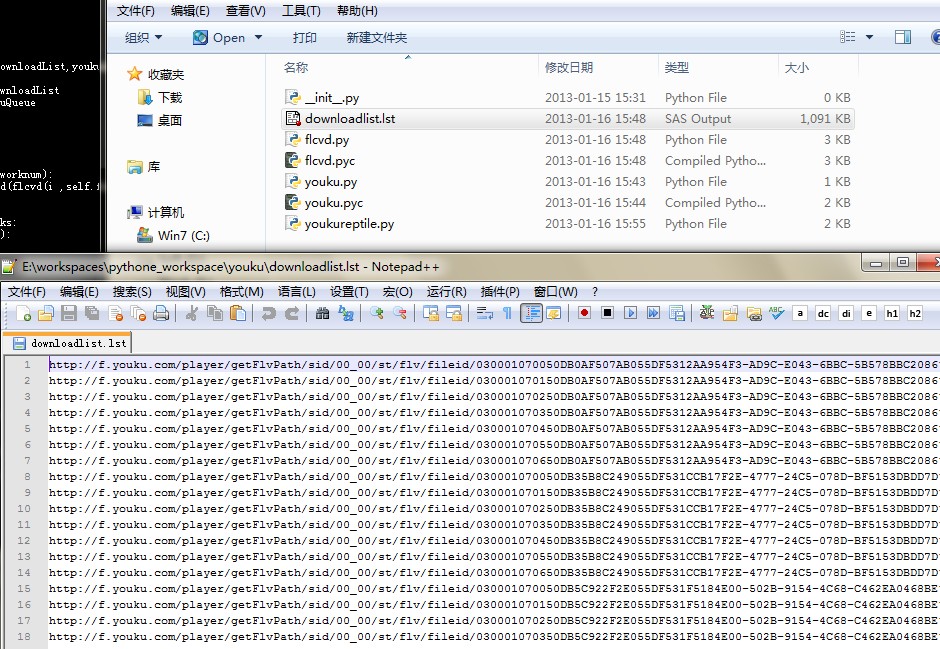
之前一直使用flcvd下载优酷视频,这周看到老师讲的爬虫。手痒痒了。于是捣腾了下!从优酷页面爬取视频页面,访问flcvd 抓取下载地址,生成迅雷下载列表。
通过爬虫对正则有更深入的理解。尤其是在优酷分2种:
'http://v\.youku\.com这个为视频播放页面。例如http://v.youku.com/v_show/id_XNDkyODQwNjgw.html 《楚汉传奇 第40集》。单集下载抓取
'http://www\.youku\.com/show_page 为剧集页面。例如:http://www.youku.com/show_page/id_z70902150919c11e0a046.html 《楚汉传奇》,可以批量抓取剧集的下载地址哦!
欢迎大家拍砖,有哪些好的建议请指出!
复制代码
复制代码
复制代码
通过爬虫对正则有更深入的理解。尤其是在优酷分2种:
'http://v\.youku\.com这个为视频播放页面。例如http://v.youku.com/v_show/id_XNDkyODQwNjgw.html 《楚汉传奇 第40集》。单集下载抓取
'http://www\.youku\.com/show_page 为剧集页面。例如:http://www.youku.com/show_page/id_z70902150919c11e0a046.html 《楚汉传奇》,可以批量抓取剧集的下载地址哦!
欢迎大家拍砖,有哪些好的建议请指出!
- #coding="utf-8"
- import re
- import urllib2
- import threading
- import Queue
- class youku(threading.Thread):
- def __init__(self,baseUrl,youkuQueue):
- threading.Thread.__init__(self)
- self.baseUrl=baseUrl if self.hasHttp().match(baseUrl) else 'http://'+baseUrl
- self.youkuQueue=youkuQueue
- self.vshow=self.youku_v_show()
- self.showpage=self.youku_show_page()
- self.start()
-
- def hasHttp(self):
- return re.compile("^http://")
-
- def youku_v_show(self):
- return re.compile(r'http://v\.youku\.com/v_show/id_.+\.html')
-
- def youku_show_page(self):
- return re.compile(r'http://www\.youku\.com/show_page/id_.+\.html')
-
- def parseUrl(self):
- req=urllib2.urlopen(self.baseUrl)
- contet=req.read()
-
-
- if self.vshow.match(self.baseUrl):
- return set(self.vshow.findall(contet))
- else:
- return set(self.showpage.findall(contet))
-
- def run(self):
- print "start parse Youku "
- matches=self.parseUrl()
- print matches
- for matche in matches:
- print 'matches:%s'%matche
- self.youkuQueue.put(matche)
- """
- if __name__=='__main__':
- Base_Url="http://www.youku.com/show_page/id_z70902150919c11e0a046.html"
- #Base_Url="http://tv.youku.com/search/"
- #Base_Url="http://v.youku.com/v_show/id_XNDkyODUyMTQ0.html"
- #Base_Url="http://www.baidu.com"
- youkuQueue=Queue.Queue()
- youku=youku(Base_Url,youkuQueue)
- """
- #coding="utf-8"
- import re
- import urllib
- import urllib2
- import threading
- import Queue
- class flcvd(threading.Thread):
- Bae_Url="http://www.flvcd.com/parse.php?"
- def __init__(self,worknum,form,downloadList,youkuQueue):
- threading.Thread.__init__(self)
- #self.url=youkuUrl
- self.showpage=self.hidentFileUrl()
- self.vshow=self.youku_v_show()
- self.herfshow=self.herfFileUrl()
- self.form=form
- self.downloadList=downloadList
- self.youkuQueue=youkuQueue
- self.worknum=worknum
- self.start()
-
- def hidentFileUrl(self):
- return re.compile('(http://f.youku.com/player/getFlvPath.+\s?)')
- def herfFileUrl(self):
- return re.compile(r'<a href=\"(http://f.youku.com/player/getFlvPath[^\"]+)')
-
- def youku_v_show(self):
- return re.compile(r'http://v\.youku\.com/v_show/id_.+\.html')
-
- def headers(self,url):
- heads={
- 'Host':'www.flvcd.com',
- 'Referer':url,
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.97 '
- }
- return heads
-
- def compileUrl(self,youkuUrl):
- params={'kw':youkuUrl}
- encode=urllib.urlencode(params)
- form="&format=%s"%(self.form if self.form else '')
- realUrl="%s%s%s"%(self.Bae_Url,encode,form)
- return realUrl
-
- def parseUrl(self,youkuUrl):
- targetUrl=self.compileUrl(youkuUrl)
- req=urllib2.Request(
- url =targetUrl,
- headers = self.headers(targetUrl)
- )
- resp=urllib2.urlopen(req)
- content=resp.read()
- if self.vshow.match(youkuUrl):
- return self.herfshow.findall(content)
- else:
- return self.showpage.findall(content)
-
- def run(self):
- while True:
- youkuUrl=self.youkuQueue.get()
- print '[No:%d] flvcd robot youku url>>%s'%(self.worknum,youkuUrl)
- matches=self.parseUrl(youkuUrl)
- #print matches
- for item in matches:
- #print item
- self.downloadList.append(item.rstrip())
-
- if self.youkuQueue.empty():
- print '[No:%d] flcvd no work ,bye bye...'%self.worknum
- break
-
-
- """ """
- if __name__=='__main__':
- youkuQueue=Queue.Queue()
- youkuQueue.put('http://v.youku.com/v_show/id_XNDkzNTk2NDQw.html')
- #youkuQueue.put('http://www.youku.com/show_page/id_z70902150919c11e0a046.html')
- downloadList=[]
- flcvd=flcvd(1,'super',downloadList,youkuQueue)
- #coding="utf-8"
- import re
- import urllib2
- from youku import youku
- from flcvd import flcvd
- from Queue import Queue
- class theadpool:
- def __init__(self,form,downloadList,youkuQueue,worknum):
- self.form=form
- self.downloadList=downloadList
- self.youkuQueue=youkuQueue
- self.works=[]
- self.worknum=worknum
- self.initflcvd()
-
- def initflcvd(self):
- for i in range(self.worknum):
- self.works.append(flcvd(i ,self.form,self.downloadList,self.youkuQueue))
-
- def finish(self):
- for work in self.works:
- if work.isAlive():
- work.join()
-
- def thunder(downloadList):
- thunderListFile=open('downloadlist.lst','w+')
- downloadList=set(downloadList)
- for download in downloadList:
- thunderListFile.write('%s\n'%download);
- thunderListFile.close()
- if __name__=='__main__':
- downloadList=[]
- youkuQueue=Queue()
- worknum=4
- Base_Url="http://v.youku.com/v_show/id_XNDkyODUyMTQ0.html"
- #Base_Url="http://www.youku.com/show_page/id_z70902150919c11e0a046.html"
-
-
- youku(Base_Url,youkuQueue)
-
- theadpools=theadpool('super',downloadList,youkuQueue,worknum)
- theadpools.finish()
-
- thunder(downloadList)
0 0
- 优酷视频下载爬虫
- 下载优酷视频
- python爬虫下载极客学院视频
- python爬虫脚本下载YouTube视频
- 【python 视频爬虫】python下载头条视频
- 优酷视频下载器 优酷视频下载方法
- 怎样下载优酷视频?
- 怎样下载优酷视频
- 如何下载优酷视频
- 最好的FLV视频下载器 维棠 (支持优酷视频下载、土豆视频下载等)
- 使用Python编写简单网络爬虫抓取视频下载资源
- 爬虫登陆极客学院,并下载视频
- Python爬虫-爬取爆米花视频下载至本地
- Python网络爬虫(四):视频下载器
- 如何直接下载优酷视频?不用优酷下载器下载视频方法技巧
- 优酷等视频网站的视频怎么下载
- 火狐浏览器下载腾讯视频优酷视频组件
- 如何下载优酷土豆、新浪等视频网站视频
- 【数据结构】数据结构C语言的实现(栈)
- nodejs初始化init
- openGL绘制正方体分别实现简单颜色绘制、纹理绘制、光照绘制
- 【数据结构】数据结构C语言的实现(队列)
- 互联网公司社会招聘Java工程师面试题整理(1)
- 优酷视频下载爬虫
- 【深度学习】windows下安装TensorFlow
- java进阶
- C#命名管道进程通信(一单向)
- 【数据结构】数据结构C语言的实现(简单二叉树)
- 数据格式化
- 互联网公司社会招聘Java工程师面试题整理(2)
- 有惊无险的广告页面数据加载
- Stylish样式——修改blog下方碍眼内容!


