正则表达式--部分整合
来源:互联网 发布:昆明网页美工招聘 编辑:程序博客网 时间:2024/04/30 15:00
通配符
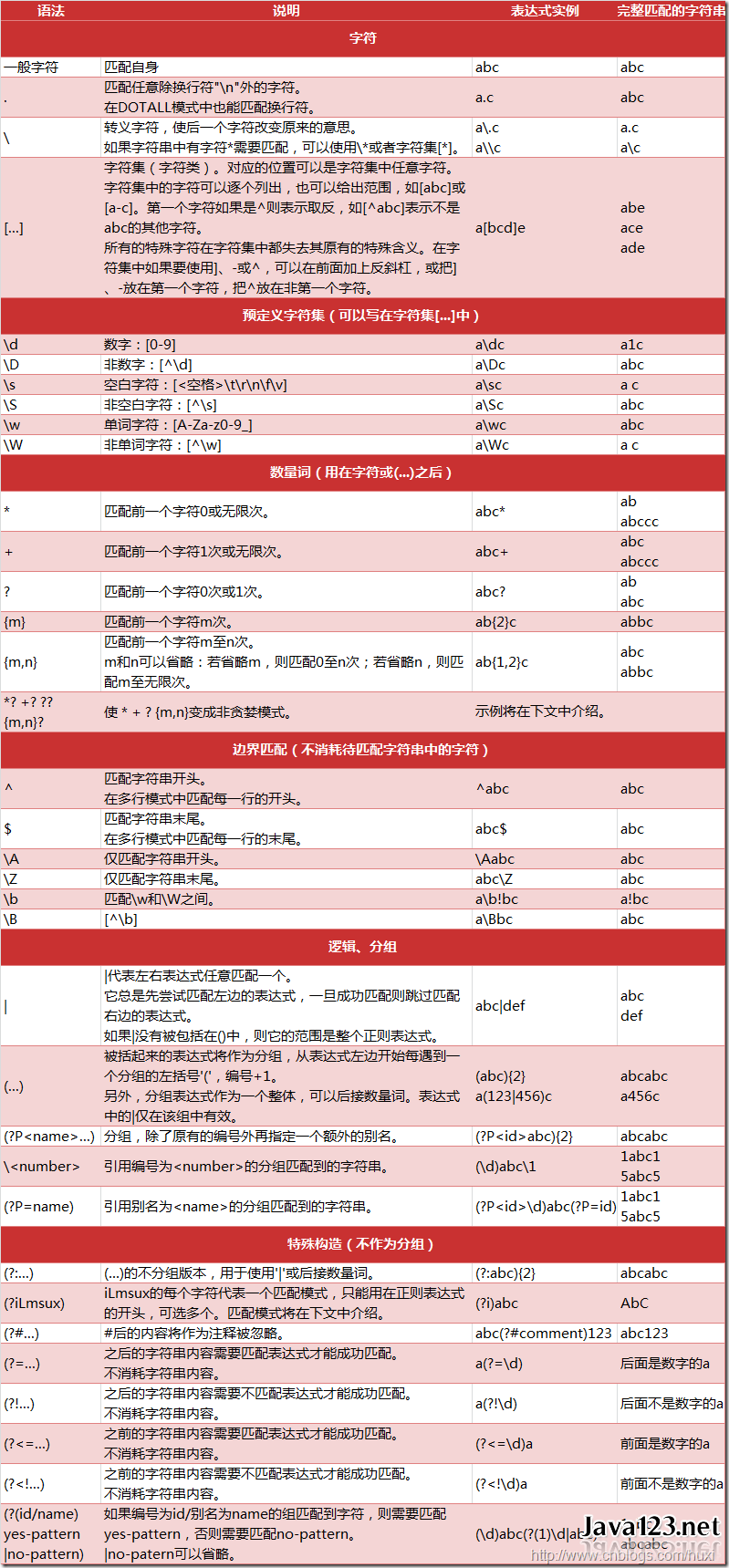
正则表达式可以匹配多于一个的字符串,可以使用一些特殊字符创建这类模式。比如点号(.)可以匹配任何字符。在我们用window 搜索时用问号(?)匹配任意一位字符,作用是一样的。那么这类符号就叫通配符。
对特殊字符进行转义
通过上面的方法,假如我们要匹配“python.org”,直接用用‘python.org’可以么?这么做可以,但这样也会匹配“pythonzorg”,这可不是所期望的结果。
我们需要对它进行转义,可以在它前面加上双斜线。因此,本例中可以使用“python\\.org”,这样就只会匹配“python.org”了。
字符集
我们可以使用中括号([ ])括住字符串来创建字符集。可以使用范围,比如‘[a-z]’能够匹配a到z的任意一个字符,还可以通过一个接一个的方式将范围联合起来使用,比如‘[a-zA-Z0-9]’能够匹配任意大小写字母和数字。
反转字符集,可以在开头使用^字符,比如‘[^abc]’可以匹配任何除了a、b、c之外的字符。
选择符
有时候只想匹配字符串’python’ 和 ’perl’ ,可以使用选择项的特殊字符:管道符号(|) 。因此, 所需模式可以写成’python|perl’ 。
子模式
但是,有些时候不需要对整个模式使用选择符---只是模式的一部分。这时可以使用圆括号起需要的部分,或称子模式。 前例可以写成 ‘p(ython | erl)’
可选项
在子模式后面加上问号,它就变成了可选项。它可能出现在匹配字符串,但并非必须的。
r’(http://)?(www\.)?python\.org’
只能匹配下列字符:
‘http://www.python.org’
‘http://python.org’
‘www.python.org’
‘python.org’
重复子模式
(pattern)* : 允许模式重复0次或多次
(pattern)+ : 允许模式重复1次或多次
(pattern){m,n} : 允许模式重复m~ n 次
例如:
r’w * \.python\.org’ 匹配 ‘www.python.org’ 、’.python.org’ 、’wwwwwww.python.org’
r’w + \.python\.org’ 匹配 ‘w.python.org’ ;但不能匹配 ’.python.org’
r’w {3,4}\.python\.org’ 只能匹配‘www.python.org’ 和‘wwww.python.org’
re模块的内容
re模块中一些重要的函数:

re.compile 将正则表达式转换为模式对象,可以实现更有效率的匹配。
re.search 会在给定字符串中寻找第一个匹配给正则表式的子字符串。找到函数返回MatchObject(值为True),否则返回None(值为False) 。因为返回值的性质,所以该函数可以用在条件语句中:
if re.serch(pat, string):
print ‘found it !’
re.math 会在给定字符串的开头匹配正则表达式。因此,re.math(‘p’ , ‘python’)返回真,re.math(‘p’ , ‘www.python’) 则返回假。
re.split 会根据模式的匹配项来分割字符串。
>>> import re>>> some_text = 'alpha , beta ,,,gamma delta '>>> re.split('[,]+',some_text)['alpha ', ' beta ', 'gamma delta ']
re. findall以列表形式返回给定模式的所有匹配项。比如,要在字符串中查找所有单词,可以像下面这么做:
>>> import re>>> pat = '[a-zA-Z]+'>>> text = '"Hm...err -- are you sure?" he said, sounding insecure.'>>> re.findall(pat,text)['Hm', 'err', 'are', 'you', 'sure', 'he', 'said', 'sounding', 'insecure']
re.sub的作用在于:使用给定的替换内容将匹配模式的子符串(最左端并且重叠子字符串)替换掉。
>>> import re>>> pat = '{name}'>>> text = 'Dear {name}...'>>> re.sub(pat, 'Mr. Gumby',text)'Dear Mr. Gumby...'
re.escape 函数,可以对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。
如果字符串很长且包含很多特殊字符,而你又不想输入一大堆反斜线,可以使用这个函数:
>>> re.escape('www.python.org')'www\\.python\\.org'>>> re.escape('but where is the ambiguity?')'but\\ where\\ is\\ the\\ ambiguity\\?'
匹配对象和组
简单来说,组就是放置在圆括号里内的子模块,组的序号取决于它左侧的括号数。组0就是整个模块,所以在下面的模式中:
‘There (was a (wee) (cooper)) who (lived in Fyfe)’
包含组有:
0 There was a wee cooper who lived in Fyfe
1 was a wee cooper
2 wee
3 cooper
4 lived in Fyfe
re 匹配对象的重要方法

下面看实例:
group方法返回模式中与给定组匹配的字符串,如果没有组号,默认为0 ;如上面:m.group()==m.group(0) ;如果给定一个组号,会返回单个字符串。
start 方法返回给定组匹配项的开始索引,
end方法返回给定组匹配项的结束索引加1;
span以元组(start,end)的形式返回给组的开始和结束位置的索引。
元字符的列表:
我们首先考察的元字符是"[" 和 "]"。它们常用来指定一个字符类别,所谓字符类别就是你想匹配的一个字符集。字符可以单个列出,也可以用“-”号分隔的两个给定字符来表示一个字符区间。例如,[abc] 将匹配"a", "b", 或 "c"中的任意一个字符;也可以用区间[a-c]来表示同一字符集,和前者效果一致。如果你只想匹配小写字母,那幺 RE 应写成 [a-z].
元字符在类别里并不起作用。例如,[akm$]将匹配字符"a", "k", "m", 或 "$" 中的任意一个;"$"通常用作元字符,但在字符类别里,其特性被除去,恢复成普通字符。
你可以用补集来匹配不在区间范围内的字符。其做法是把"^"作为类别的首个字符;其它地方的"^"只会简单匹配 "^"字符本身。例如,[^5] 将匹配除 "5" 之外的任意字符。
一些用 """ 开始的特殊字符所表示的预定义字符集通常是很有用的,象数字集,字母集,或其它非空字符集。下列是可用的预设特殊字符:
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ "t"n"r"f"v]。???
\S 匹配任何非空白字符;它相当于类 [^ "t"n"r"f"v]。?
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]。
这样特殊字符都可以包含在一个字符类中。如,["s,.]字符类将匹配任何空白字符或","或"."。
本节最後一个元字符是 . 。它匹配除了换行字符外的任何字符,在 alternate 模式(re.DOTALL)下它甚至可以匹配换行。"." 通常被用于你想匹配“任何字符”的地方。
重复
基本符号说明:
* 0次、1次或多次匹配其前的原子
+ 1次或多次匹配其前的原子
? 0次或1次匹配其前的原子
. 匹配除换行之外的任何一个字符
正则表达式第一件能做的事是能够匹配不定长的字符集,而这是其它能作用在字符串上的方法所不能做到的。 不过,如果那是正则表达式唯一的附加功能的话,那么它们也就不那么优秀了。它们的另一个功能就是你可以指定正则表达式的一部分的重复次数。
我们讨论的第一个重复功能的元字符是 *。* 并不匹配字母字符 "*";相反,它指定前一个字符可以被匹配零次或更多次,而不是只有一次。
举个例子,ca*t 将匹配 "ct" (0 个 "a" 字符), "cat" (1 个 "a"), "caaat" (3 个 "a" 字符)等等。RE 引擎有各种来自 C 的整数类型大小的内部限制,以防止它匹配超过2亿个 "a" 字符;你也许没有足够的内存去建造那么大的字符串,所以将不会累计到那个限制。
象 * 这样地重复是“贪婪的”;当重复一个 RE 时,匹配引擎会试着重复尽可能多的次数。如果模式的後面部分没有被匹配,匹配引擎将退回并再次尝试更小的重复。
RE 的结尾部分现在可以到达了,它匹配 "abcb"。这证明了匹配引擎一开始会尽其所能进行匹配,如果没有匹配然後就逐步退回并反复尝试 RE 剩下来的部分。直到它退回尝试匹配 [bcd] 到零次为止,如果随後还是失败,那么引擎就会认为该字符串根本无法匹配 RE 。
另一个重复元字符是 +,表示匹配一或更多次。请注意 * 和 + 之间的不同;*匹配零或更多次,所以根本就可以不出现,而 + 则要求至少出现一次。用同一个例子,ca+t 就可以匹配 "cat" (1 个 "a"), "caaat" (3 个 "a"), 但不能匹配 "ct"。
还有更多的限定符。问号 ? 匹配一次或零次;你可以认为它用于标识某事物是可选的。例如:home-?brew 匹配 "homebrew" 或 "home-brew"。
最复杂的重复限定符是 {m,n},其中 m 和 n 是十进制整数。该限定符的意思是至少有 m 个重复,至多到 n 个重复。举个例子,a/{1,3}b 将匹配 "a/b","a//b" 和 "a///b"。它不能匹配 "ab" 因为没有斜杠,也不能匹配 "a////b" ,因为有四个。
- 正则表达式--部分整合
- 正则表达式相关整合
- 部分正则表达式
- 部分正则表达式
- 正则表达式(部分)
- 正则表达式部分介绍
- 正则表达式 部分总结
- 正则表达式部分语法
- 自用部分正则表达式
- 正则表达式部分替换
- 正则表达式部分
- 收录部分常用正则表达式
- 正则表达式 易混淆部分
- 部分常用的正则表达式
- 正则表达式 部分格式验证
- 正则表达式知识及部分常用正则表达式
- php正则表达式(基本概念整合)
- 编译 boost 的正则表达式部分
- VGG Convolutional Neural Networks Practical(4)normalisation
- java 初始化顺序
- CentOS 7.2 服务器配置过程
- ArcGIS中的坐标系统定义与投影转换
- JVM调优:基本垃圾回收算法
- 正则表达式--部分整合
- 嵌入式开发行业对人才有哪些需求
- linux下vi命令大全
- UVa 455 - Periodic Strings
- python定制类
- 数算实习和数算期末上机总结
- 程序只运行一个实例(一)
- 主键外键的一些理解
- android导航栏隐藏及显示


