Selenium-CSS页面元素定位
来源:互联网 发布:六韬淘宝天猫托管 编辑:程序博客网 时间:2024/05/16 23:44
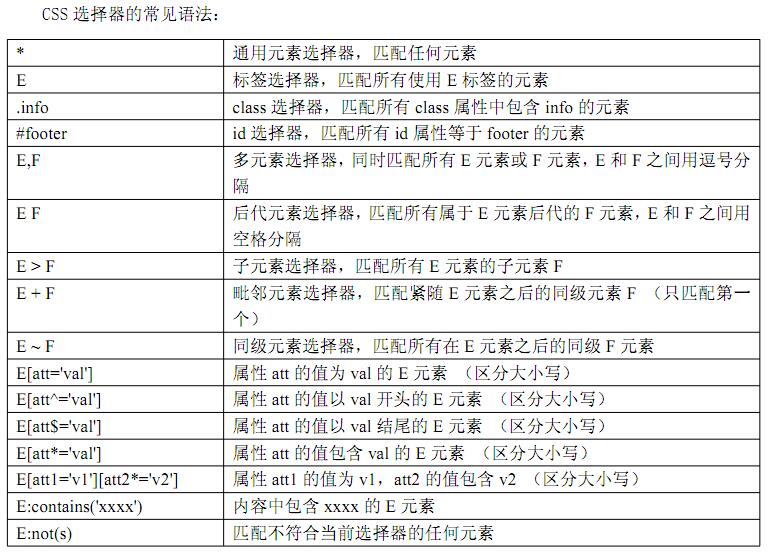
CSS 可以比较灵活选择控件的任意属性,一般情况下定位速度要比 XPath 快,但对于初学者来说比较难以学习使用,下面我们就详细的介绍 CSS的语法与使用。

<html> <body> <div class="formdiv"> <form name="fnfn"> <input name="username" type="text"></input> <input name="password" type="text"></input> <input name="continue" type="button"></input> <input name="cancel" type="button"></input> <input value="SYS123456" name="vid" type="text"> <input value="ks10cf6d6" name="cid" type="text"> </form> <div class="subdiv"> <ul id="recordlist"> <p>Heading</p> <li>Cat</li> <li>Dog</li> <li>Car</li> <li>Goat</li> </ul> </div> </div> </body></html>
定位实例:
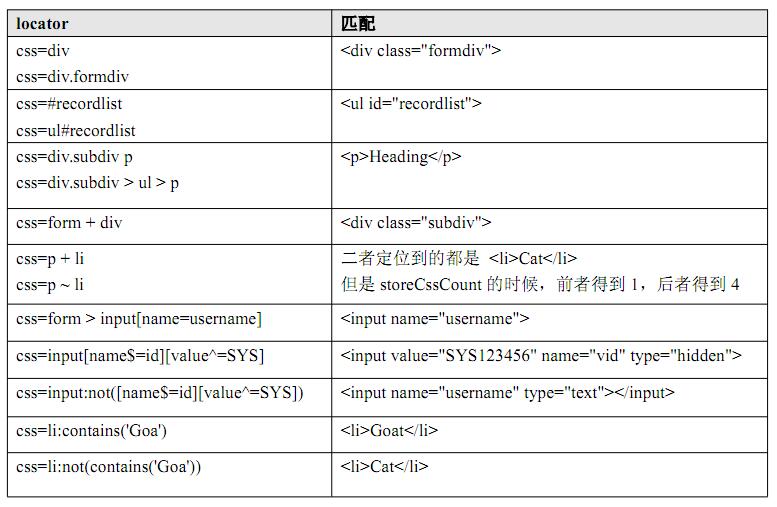
css中的结构性定位
结构性定位就是根据元素的父子、同级中位置来定位,css3标准中有定义一些结构性定位伪类如nth-of-type,nth-child,但是使用起来语法很不好理解,这里就简单介绍下。Selenium中则是采用了来自 Sizzle的 css3定位扩展,它的语法更加灵活易懂。
nth-of-type
例:
#test > li:nth-of-type(2) //表示ID为test下的第二个li元素,相当于xpath= //e[id=test]/li[2]
nth-child
例:
#test > li:nth-child(4) //表示ID为test下的第4个子元素,并且限制为li元素,如果不是则报错
解:# 表ID
>表子元素(父子关系)
nth n表第几个
type 同类型
例子2:
<div class="subdiv"> <ul id="recordlist"> <p>Heading</p> <li>Cat</li> <li>Dog</li> <li>Car</li> <li>Goat</li> </ul></div>



0 0
- Selenium-CSS页面元素定位
- 【WebDriver】selenium使用CSS定位页面元素
- selenium定位页面元素
- selenium之定位页面元素
- selenium页面元素定位方法
- selenium实践-用css去定位元素
- Selenium中CSS定位Web UI元素
- Selenium 元素定位 CSS and XPath
- Selenium定位页面元素的方法
- selenium webdriver xpath 定位页面元素
- selenium页面滚动图片元素定位
- Selenium学习一 页面元素定位
- selenium常用命令之页面元素定位
- java selenium webdriver实战 页面元素定位
- selenium 页面元素的定位方法
- 【Selenium】webdriver进行页面元素定位
- Selenium中CSS选择器与Xpath根据页面结构定位元素比较
- selenium抓取页面可用元素css
- 《爸爸妈妈》——李荣浩
- Protocol Buffers(Protobuf) 官方文档--Protobuf语言指南
- SSM配置以及mybatis generator运用
- 快讯:蓝牙5.0发布(新特性速览)
- java接口interface
- Selenium-CSS页面元素定位
- 国外电子书免费下载网站
- 用jQuery实现选tab项卡效果
- eclipse下调试jenkins插件
- BigDecimal格式化小数
- List,map排序
- DES加密
- 通知栏显示富文本和大图片
- OpenCV的Delaunay三角剖分和Voronoi图的实现


