复习(1)-- C程序的内存分布
来源:互联网 发布:数据库保留两位小数 编辑:程序博客网 时间:2024/06/07 08:40
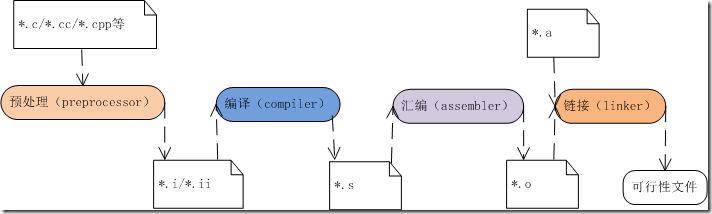
一. 从源代码到可执行文件
程序从代码编译成可执行的文件。源文件经过以下几步生成可执行文件:
编译器和汇编器创建的目标文件包含:二进制代码(指令)、源码中的数据;链接器将多个目标文件链接成一个;装载器把目标文件加载到内存。
二. 虚拟地址空间
在多任务操作系统中的每一个进程都运行在一个属于它自己的内存沙盘中。
这个沙盘就是虚拟地址空间(virtual address space),在32位模式下它总是一个4GB的内存地址块。
源程序编译后链接到一个以0x00000000地址为始地址的线性或多维虚拟地址空间。
而且每个进程都拥有这样一个空间,每个指令和数据都在这个虚拟地址空间拥有确定的地址,把这个地址称为虚拟地址(Virtual Address)。
将进程中的目标代码、数据等的虚拟地址组成的虚拟空间称为虚拟存储器(Virtual Memory)。
当进程被创建时,内核为其提供一块物理内存,将虚拟内存映射到物理内存,这些都是由操作系统来做的。

在Linux中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存。
内核代码和数据总是可寻址的,随时准备处理中断和系统调用。
与此相反,用户模式地址空间的映射随进程切换的发生而不断变化:

蓝色区域表示映射到物理内存的虚拟地址,而白色区域表示未映射的部分。
在上面的例子中,Firefox使用了相当多的虚拟地址空间,因为它是传说中的吃内存大户。
地址空间中的各个条带对应于不同的内存段(memory segment),如:堆、栈之类的。
记住,这些段只是简单的内存地址范围,与Intel处理器的段没有关系。
不管怎样,下面是一个Linux进程的标准的内存段布局:

当计算机开心、安全、可爱、正常的运转时,几乎每一个进程的各个段的起始虚拟地址都与上图完全一致,
这也给远程发掘程序安全漏洞打开了方便之门。
一个发掘过程往往需要引用绝对内存地址:栈地址,库函数地址等。
远程攻击者必须依赖地址空间布局的一致性,摸索着选择这些地址。
如果让他们猜个正着,有人就会被整了。
因此,地址空间的随机排布方式逐渐流行起来。
Linux 通过对栈内存映射段、堆的起始地址加上随机的偏移量来打乱布局。
不幸的是,32 位地址空间相当紧凑,给随机化所留下的空当不大,削弱了这种技巧的效果。
三. 数据存储类别
数据在内存中的位置取决于它的存储类别。一个对象是内存的一个位置,解析这个对象依赖于两个属性:存储类别、数据类型。
存储类别决定对象在内存中的生命周期。
数据类型决定对象值的意义,在内存中占多大空间。
C/C++中由(auto、 extern、 register、 static)存储类别和对象声明的上下文决定它的存储类别。
一般变量,若不加说明(auto),则定义在全局就是全局,定义在局部就是局部。 全局变量在数据段。局部变量(非静态)变量在栈。
extern 声明变量是全局变量(意味着可能定义在别处)。所以存储在栈。
register 的对象是自动存储类别,存储在计算机的快速寄存器中。不可以对register对象做取值操作“&”(即取地址)
static, 关键字声明变量为静态。存储在静态存储区内。
数据的作用范围:
全局变量 global int a, 作用范围是整个源程序(可能由多个文件组成)。
static 关键字可以限制变量的作用范围: static声明的全局变量只能在本文件内使用。static 声明的函数只能在本文件内使用,在内存中只有一份copy。
四. 进程的内存分布
进程是一段活动的程序,操作系统为进程提供系统资源,这个环境叫做上下文,或者叫做虚拟存储器??
进程会占用一定数量的内存,它或是用来存放从磁盘载入的程序代码,或是存放取自用户输入的数据等等。不过进程对这些内存的管理方式因内存用途 不一而不尽相同,有些内存是事先静态分配和统一回收的,而有些却是按需要动态分配和回收的。对任何一个普通进程来讲,它都会涉及到5种不同的数据段。

Linux进程的五个段(从下往上):
代码段:代码段/正文段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
数据段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量/静态变量的一块内存区域。数据段属于静态内存分配。
BSS段:BSS段(bss segment)通常是指用来存放程序中未初始化的全局变量/静态变量的一块内存区域。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)堆是链表,通常不连续。堆的使用是从低地址到高地址。
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进后出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。栈是由操作系统分配的,内存的申请与回收都由OS管理。
栈是限定仅在表头进行插入和删除操作的线性表。地址通常是连续的。栈的使用时从高地址向低地址扩展,也就是说栈顶低于栈底。低地址是栈顶(浮动),高地址是栈底(固定)。
栈上面的位置是环境变量位置,它处在逻辑地址的高地址地方。
注意:
全局的未初始化变量存在于.bss段中,具体体现为一个占位符;全局的已初始化变量存于.data段中;而函数内的自动变量都在栈上分配空间。.bss是不占用.exe文件空间的,其内容由操作系统初始化(清零);而.data却需要占用,其内容由程序初始化,因此造成了上述情况。
包含数据段和BSS段的整个区段此时通常称为数据区。
下图未包含BSS段。

- 复习(1)-- C程序的内存分布
- c程序的内存分布
- C程序的内存分布
- C程序内存分布
- c程序内存分布
- c程序内存分布
- C/C++程序的内存分布
- C语言程序的内存分布
- C程序内存分布(译)
- 程序的内存分布
- 程序的内存分布
- 程序的内存分布
- C/C++ 程序内存分布
- C语言程序内存分布
- C/C++程序内存分布
- c语言程序内存分布
- Objective-C 程序内存分布
- C 的内存分布
- Hadoop namenode的安全模式
- C# DataTable与DataSet的学习
- Jackson(二) Databind
- 其他数制与十进制转换
- Chrome插件(UserScript)开发教程
- 复习(1)-- C程序的内存分布
- 购物车3种实现方式 详解
- C++对象模型和虚函数表分析以及重载、重写、隐藏的区别
- COM技术
- 关于IllegalMonitorStateException异常的解释
- 数据结构之打印一棵二叉树
- 苏联俄罗斯文学 —— 陀思妥耶夫斯基、契科夫
- Hibernate
- 【腾讯TMQ】带你寻找谷歌的bug


