各分类方法应用场景 逻辑回归,支持向量机,随机森林,GBT,深度学习
来源:互联网 发布:安卓游戏源码改端口 编辑:程序博客网 时间:2024/05/23 09:49
http://blog.csdn.net/haipengdai/article/details/51981890
https://www.quora.com/What-are-the-advantages-of-different-classification-algorithms
训练样本的数量
特征的维度
是否线性可分
特征之间是相互独立的吗
特征是linear dependent 和target variable过拟合问题
速度,效果,内存限制
- logistic regression
应用场景:feature大概是线性(什么意思?)的,数据是线性可分的,non-linear features->linear
优点:
1.robust to noise and void overfitting,feature selection by using l2 or l1 regularization
2.can be used in Big Data scenarios since it is pretty efficient and can be distributed using, ADMM
3.can be interpreted as probability
- support vector machines
in practice: an SVM with a linear kernel is not very different from a Logistic Regression
需要使用svm的应用场景:数据不是线性可分的,需要使用非线性核的svm(虽然logistic regression也可以用不同的核,但由于实际原因(什么?)还是用svm比较好);另一个场景是特征空间维度很高,例如svm在文本分类中的效果较好
缺点:
- svm训练非常耗时间,所以在大的训练样本(多大?)的情况下不推荐使用,或者说工业级别的数据都不推荐使用svm
- Tree ensembles
随机森林Random Forests和Gradient Boosted Trees
Tree ensembles相比Logistic Regression来说的优点:
- 不要求是linear features (do not expect linear features or even features that interact linearly), 比如LR很难处理categorical features,而Tree Ensembles,是一些决策树的集合,可以很容易得处理这些情况
- 由于算法构建的过程(bagging or boosting),这些算法很容易处理高维的数据,大量的训练数据的场景
RF (Random Forests) vs GBDT (Gradient Boosted Decision Trees)
GBDTwill usually perform better, but they are harder to get right
GBDT有很多超参数可以调试,更容易过拟合, RFs can almost work "out of the box" and that is one reason why they are very popular(这句话没看明白)
- Deep Learning
总结start from esimple to set a baseline, only make it more complicated if you need to:
1.从简单的Logistic Regression开始尝试,设置一个baseline
2.Random Forests, (easy to tune)
3.GBDT
4.fancier model
5.deep learning
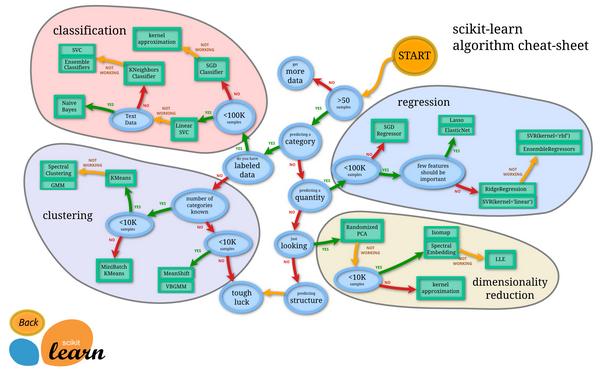
0 0
- 各分类方法应用场景 逻辑回归,支持向量机,随机森林,GBT,深度学习
- 各分类方法应用场景 逻辑回归,支持向量机,随机森林,GBT,深度学习
- 分类&回归算法-随机森林
- 机器学习概念总结笔记(二)——逻辑回归、贝叶斯分类、支持向量分类SVM、分类决策树ID3、
- SVM支持向量机和逻辑回归进行心音信号简单二分类
- 随机森林与GBT算法介绍
- 分类和回归树,随机森林,霍夫森林
- 逻辑回归,决策树,支持向量机 选择方案
- 逻辑回归、决策树和支持向量机(I)
- 逻辑回归、决策树和支持向量机(I)
- 逻辑回归、决策树和支持向量机(I)
- 逻辑回归、决策树和支持向量机的直观理解
- 逻辑回归 vs 决策树 vs 支持向量机(I)
- 逻辑回归 vs 决策树 vs 支持向量机(II)
- 逻辑回归、决策树和支持向量机(I)
- 逻辑回归、决策树和支持向量机(II)
- 逻辑回归、决策树和支持向量机(I)
- 逻辑回归 vs 决策树 vs 支持向量机(II)
- (1)Storm实时日志分析实战--项目准备
- handle机制与用法详解
- iOS调用系统的拨号功能
- Jenkins:使用Git Parameter插件实现tag或分支的选择性构建
- 权限与命令间的关系-私房菜学习笔记
- 各分类方法应用场景 逻辑回归,支持向量机,随机森林,GBT,深度学习
- (小知识点)ViewPager设置 缓存个数、页卡间距、数据更新
- 句子逆序
- dede调用公司简介的方法
- /动态规划
- JavaScript 字符串实用常操纪要
- 如何用Unity3D实现衍射效果
- Ionic2 Sticky 粘附效果
- Logback日志系统配置攻略


