03_6Pandas_分组与聚合
来源:互联网 发布:长途搬家怎么划算 知乎 编辑:程序博客网 时间:2024/05/16 14:32
1. GroupBy
import pandas as pdimport numpy as np创建一个8 * 4的DataFrame:
dict_obj = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'], 'key2' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'], 'data1': np.random.randn(8), 'data2': np.random.randn(8)}df_obj = pd.DataFrame(dict_obj)print df_obj data1 data2 key1 key20 0.922654 -0.555087 a one1 1.419044 -1.686106 b one2 0.312465 0.553175 a two3 0.000348 1.212291 b three4 -0.867338 0.051782 a two5 0.187010 -1.447387 b two6 0.463482 -0.132936 a one7 -0.588881 0.330971 a three1.1 groupBy对象
groupBy对象有两类:DataFrameGroupBy,SeriesGroupBy
groupBy对象实际上没有进行实际的运算,只是包含分组的中间数据。
把经过groupBy的DataFrame打印出来,是没有直接的数据的,如下,根据key1进行分组:
print df_obj.groupby('key1')<pandas.core.groupby.DataFrameGroupBy object at 0x7fbeaf2c7950>来打印以下这个进行了groupBy操作的DataFrame的类型,显示的是类型是DataFrameGroupBy
print type(df_obj.groupby('key1'))<class 'pandas.core.groupby.DataFrameGroupBy'>可以指定DataFrame中的某一列根据某个列分组,如下,data1列根据key1进行分组,返回的类型是SeriesGroupBy
print type(df_obj['data1'].groupby(df_obj['key1']))<class 'pandas.core.groupby.SeriesGroupBy'>1.2 分组运算
对DataFrame进行分组运算, 以下例子,整个DataFrame根据key1进行分组,并求得其他列在每组key1中的均值。因为key2是string类型的值,所以在求均值的时候自动舍弃了它的计算,故返回了data1, data2在a,b两个组中的均值。
grouped1 = df_obj.groupby('key1')print grouped1.mean() data1 data2key1 a 0.048476 0.049581b 0.535467 -0.640401对DataFrame的某一列进行分组运算:
grouped2 = df_obj['data1'].groupby(df_obj['key1'])print grouped2.mean()key1a 0.048476b 0.535467Name: data1, dtype: float64.size是一种特殊的分组运算,它返回的是每个分组中的元素个数
# sizeprint grouped1.size()print grouped2.size()key1a 5b 3dtype: int64key1a 5b 3dtype: int641.3 分组的方式
分组的方式可以归纳为以下几点:
- 按列名分组
- 按列名多层分组
- 按自定义的key分组
# 1.按列名分组print df_obj.groupby('key1')<pandas.core.groupby.DataFrameGroupBy object at 0x7fbeaf285c10># 2.按自定义key分组,列表self_def_key = [1, 1, 2, 2, 2, 1, 1, 1]print df_objprint df_obj.groupby(self_def_key).size() data1 data2 key1 key20 0.922654 -0.555087 a one1 1.419044 -1.686106 b one2 0.312465 0.553175 a two3 0.000348 1.212291 b three4 -0.867338 0.051782 a two5 0.187010 -1.447387 b two6 0.463482 -0.132936 a one7 -0.588881 0.330971 a three1 52 3dtype: int64# 按自定义key多层分组print df_obj.groupby([df_obj['key1'], df_obj['key2']]).size()key1 key2 a one 2 three 1 two 2b one 1 three 1 two 1dtype: int64# 3.按列名多层分组grouped2 = df_obj.groupby(['key1', 'key2'])print grouped2.size()key1 key2 a one 2 three 1 two 2b one 1 three 1 two 1dtype: int64# 4.多层分组按key的顺序进行grouped3 = df_obj.groupby(['key2', 'key1'])print grouped3.mean()printprint grouped3.mean().unstack() data1 data2key2 key1 one a 0.509819 -0.683087 b 0.379854 0.849821three a 0.364664 0.014630 b -0.063710 -1.136585two a -0.212407 -0.588067 b 0.854460 -0.474144 data1 data2 key1 a b a bkey2 one 0.509819 0.379854 -0.683087 0.849821three 0.364664 -0.063710 0.014630 -1.136585two -0.212407 0.854460 -0.588067 -0.474144unstack可以将多层索引的结果转换成单层的dataframe,等于就是一个二维的交叉表了。
1.3 GroupBy对象分组迭代
groupBy对象支持迭代操作。每次迭代返回一个元组(group_name, group_data)。可用于分组数据的具体运算。
单层与多层的DataFrame都可以实现分组迭代,以下分别是两个例子:
# 单层分组for group_name, group_data in grouped1: print group_name print group_dataa data1 data2 key1 key20 -0.079203 -0.844599 a one2 -0.961888 -1.502866 a two4 0.537074 0.326732 a two6 1.098841 -0.521574 a one7 0.364664 0.014630 a threeb data1 data2 key1 key21 0.379854 0.849821 b one3 -0.063710 -1.136585 b three5 0.854460 -0.474144 b two# 多层分组for group_name, group_data in grouped2: print group_name print group_data('a', 'one') data1 data2 key1 key20 -0.079203 -0.844599 a one6 1.098841 -0.521574 a one('a', 'three') data1 data2 key1 key27 0.364664 0.01463 a three('a', 'two') data1 data2 key1 key22 -0.961888 -1.502866 a two4 0.537074 0.326732 a two('b', 'one') data1 data2 key1 key21 0.379854 0.849821 b one('b', 'three') data1 data2 key1 key23 -0.06371 -1.136585 b three('b', 'two') data1 data2 key1 key25 0.85446 -0.474144 b two1.4 groupBy对象转换成字典与列表
# GroupBy对象转换listprint list(grouped1)[('a', data1 data2 key1 key20 0.922654 -0.555087 a one2 0.312465 0.553175 a two4 -0.867338 0.051782 a two6 0.463482 -0.132936 a one7 -0.588881 0.330971 a three), ('b', data1 data2 key1 key21 1.419044 -1.686106 b one3 0.000348 1.212291 b three5 0.187010 -1.447387 b two)]# GroupBy对象转换dictprint dict(list(grouped1)){'a': data1 data2 key1 key20 0.922654 -0.555087 a one2 0.312465 0.553175 a two4 -0.867338 0.051782 a two6 0.463482 -0.132936 a one7 -0.588881 0.330971 a three, 'b': data1 data2 key1 key21 1.419044 -1.686106 b one3 0.000348 1.212291 b three5 0.187010 -1.447387 b two}1.5 按列分组
# 按列分组print df_obj.dtypes# 按数据类型分组print df_obj.groupby(df_obj.dtypes, axis=1).size()print df_obj.groupby(df_obj.dtypes, axis=1).sum()data1 float64data2 float64key1 objectkey2 objectdtype: objectfloat64 2object 2dtype: int64 float64 object0 0.367567 aone1 -0.267062 bone2 0.865640 atwo3 1.212639 bthree4 -0.815557 atwo5 -1.260377 btwo6 0.330546 aone7 -0.257910 athree1.6 其他分组方法
df_obj2 = pd.DataFrame(np.random.randint(1, 10, (5,5)), columns=['a', 'b', 'c', 'd', 'e'], index=['A', 'B', 'C', 'D', 'E'])print df_obj2 a b c d eA 8 5 7 4 1B 3 9 5 4 7C 9 3 3 8 9D 8 5 3 2 6E 3 8 1 3 7# 更改部分数据为空df_obj2.ix[1, 1:4] = np.NaNprint df_obj2 a b c d eA 8 5.0 7.0 4.0 1B 3 NaN NaN NaN 7C 9 3.0 3.0 8.0 9D 8 5.0 3.0 2.0 6E 3 8.0 1.0 3.0 7- 1.6.1 通过字典分组
# 通过字典分组mapping_dict = {'a':'python', 'b':'python', 'c':'java', 'd':'C', 'e':'java'}print df_obj2.groupby(mapping_dict, axis=1).size()printprint df_obj2.groupby(mapping_dict, axis=1).count() # 非NaN的个数printprint df_obj2.groupby(mapping_dict, axis=1).sum()C 1java 2python 2dtype: int64 C java pythonA 1 2 2B 0 1 1C 1 2 2D 1 2 2E 1 2 2 C java pythonA 4.0 8.0 13.0B NaN 7.0 3.0C 8.0 12.0 12.0D 2.0 9.0 13.0E 3.0 8.0 11.0- 1.6.2 通过函数分组
df_obj3 = pd.DataFrame(np.random.randint(1, 10, (5,5)), columns=['a', 'b', 'c', 'd', 'e'], index=['AA', 'BBB', 'CC', 'D', 'EE'])print df_obj3printdef group_key(idx): """ idx 为列索引或行索引 """ #return idx return len(idx)print df_obj3.groupby(group_key).size()print# 以上自定义函数等价于print df_obj3.groupby(len).size() a b c d eAA 9 1 8 1 4BBB 3 2 9 3 2CC 2 3 9 7 1D 3 7 8 5 1EE 9 9 9 4 11 12 33 1dtype: int641 12 33 1dtype: int64- 1.6.3 通过索引级别分组
# 创建一个多层索引的DataFramecolumns = pd.MultiIndex.from_arrays([['Python', 'Java', 'Python', 'Java', 'Python'], ['A', 'A', 'B', 'C', 'B']], names=['language', 'index'])df_obj4 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns)print df_obj4language Python Java Python Java Pythonindex A A B C B0 2 9 4 6 71 6 3 5 7 42 5 9 5 3 63 4 2 5 7 54 8 3 3 8 5# 根据language进行分组print df_obj4.groupby(level='language', axis=1).sum()print print df_obj4.groupby(level='index', axis=1).sum()language Java Python0 15 131 10 152 12 163 9 144 11 16index A B C0 11 11 61 9 9 72 14 11 33 6 10 74 11 8 82. 聚合
常用于对分组后的数据进行计算
# 根据字典创建一个DataFramedict_obj = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'], 'key2' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'], 'data1': np.random.randint(1,10, 8), 'data2': np.random.randint(1,10, 8)}df_obj5 = pd.DataFrame(dict_obj)print df_obj5 data1 data2 key1 key20 7 7 a one1 2 1 b one2 9 6 a two3 3 7 b three4 8 5 a two5 2 2 b two6 3 7 a one7 9 6 a three2.1 使用内置聚合函数
常用的有sum(), mean(), max(), min(), count(), size(), describe()
# 使用内置的聚合函数print df_obj5.groupby('key1').sum()printprint df_obj5.groupby('key1').max()printprint df_obj5.groupby('key1').min()printprint df_obj5.groupby('key1').mean()printprint df_obj5.groupby('key1').size()printprint df_obj5.groupby('key1').count()printprint df_obj5.groupby('key1').describe() data1 data2key1 a 36 31b 7 10 data1 data2 key2key1 a 9 7 twob 3 7 two data1 data2 key2key1 a 3 5 oneb 2 1 one data1 data2key1 a 7.200000 6.200000b 2.333333 3.333333key1a 5b 3dtype: int64 data1 data2 key2key1 a 5 5 5b 3 3 3 data1 data2key1 a count 5.000000 5.000000 mean 7.200000 6.200000 std 2.489980 0.836660 min 3.000000 5.000000 25% 7.000000 6.000000 50% 8.000000 6.000000 75% 9.000000 7.000000 max 9.000000 7.000000b count 3.000000 3.000000 mean 2.333333 3.333333 std 0.577350 3.214550 min 2.000000 1.000000 25% 2.000000 1.500000 50% 2.000000 2.000000 75% 2.500000 4.500000 max 3.000000 7.000000常用的内置聚合函数: 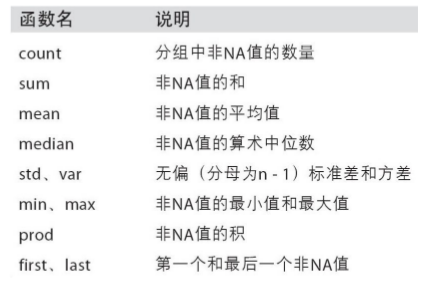
2.2 自定义函数
可自定义函数,传入agg方法中
• grouped.agg(func)
• func的参数为groupby索引对应的记录
# 自定义聚合函数def peak_range(df): """ 返回数值范围 """ #print type(df) #参数为索引所对应的记录 return df.max() - df.min()print df_obj5.groupby('key1').agg(peak_range)printprint df_obj.groupby('key1').agg(lambda df : df.max() - df.min()) data1 data2key1 a 6 2b 1 6 data1 data2key1 a 1.789992 1.108262b 1.418696 2.8983962.3 应用多个聚合函数
- 同时应用多个函数进行聚合操作,使用函数列表
# 默认列名为函数名print df_obj.groupby('key1').agg(['mean', 'std', 'count', peak_range]) data1 data2 mean std count peak_range mean std count peak_rangekey1 a 0.048476 0.750174 5 1.789992 0.049581 0.427705 5 1.108262b 0.535467 0.770871 3 1.418696 -0.640401 1.608911 3 2.898396# 通过元组提供新的列名print df_obj.groupby('key1').agg(['mean', 'std', 'count', ('range', peak_range)]) data1 data2 mean std count range mean std count rangekey1 a 0.191898 0.770756 5 2.060729 -0.505536 0.719919 5 1.829598b 0.390201 0.459173 3 0.918170 -0.253636 1.011395 3 1.986406- 对不同的列分别作用不同的聚合函数,使用dict
# 每列作用不同的聚合函数dict_mapping = {'data1':'mean', 'data2':'sum'}print df_obj.groupby('key1').agg(dict_mapping) data1 data2key1 a 0.048476 0.247905b 0.535467 -1.921202dict_mapping = {'data1':['mean','max'], 'data2':'sum'}print df_obj.groupby('key1').agg(dict_mapping) data1 data2 mean max sumkey1 a 0.048476 0.922654 0.247905b 0.535467 1.419044 -1.921202注:部分例子来自于小象学院Robin课程
- 03_6Pandas_分组与聚合
- 聚合分析与分组
- 聚合函数与分组
- 聚合函数与分组
- 聚合函数与分组
- 聚合函数与分组
- 聚合函数与分组
- 聚合函数与分组
- oracle聚合与分组
- 6.聚合函数与分组
- 数据分组与聚合函数
- 聚合函数与分组1
- 字段合并与分组聚合
- SQL数据的分组与聚合
- 第六章 聚合函数与分组
- 第六章.聚合函数与分组.总结
- 第六章聚合函数与分组总结
- Python之数据聚合与分组运算
- CentOS7下使用yum安装MySQL
- Hadoop2.X配置管理1-HDFS安装配置单机版
- ElasticSearch 简单入门
- echarts地图模拟攻击特效
- 前端开源项目周报1226
- 03_6Pandas_分组与聚合
- Spark算子:RDD行动Action操作(3)–aggregate、fold、lookup
- Maven基础学习(一)—Maven入门
- 冒泡排序最好时间复杂度为什么是O(n)?
- oracle导入.dmp文件是报错:IMP-00013: 只有 DBA 才能导入由其他 DBA 导出的文件 IMP-00000: 未成功终止导入
- U3D多人镜头跟随, FC热血格斗,PC 地狱潜行者 的镜头 代码示例
- MVC框架设计(四)
- Android动态加载jar/dex
- linux下 C语言perror函数的作用


