04_2Python绘图_seaborn
来源:互联网 发布:软件定义世界 百科 编辑:程序博客网 时间:2024/06/05 19:14
Python中的一个制图工具库,可以制作出吸引人的、信息量大的统计图
在Matplotlib上构建,支持numpy和pandas的数据结构可视化,甚至是scipy和statsmodels的统计模型可视化
seaborn的特点:
- 多个内置主题及颜色主题
- 可视化单一变量、二维变量用于比较数据集中各变量的分布情况
- 可视化线性回归模型中的独立变量及不独立变量
- 可视化矩阵数据,通过聚类算法探究矩阵间的结构
- 可视化时间序列数据及不确定性的展示
- 可在分割区域制图,用于复杂的可视化
seaborn的安装:
1. conda install seaborn
2. pip install seaborn
import numpy as npimport pandas as pdfrom scipy import statsimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline1. 数据集分布可视化
1.1 单变量分布
# 正态分布的500个数据x1 = np.random.normal(size=500)# 分布图,默认是直方+线型sns.distplot(x1);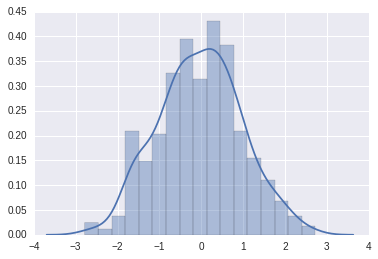
# 均匀分布的500个整数数据x2 = np.random.randint(0, 100, 500)# 分布图,默认是直方+线型sns.distplot(x2);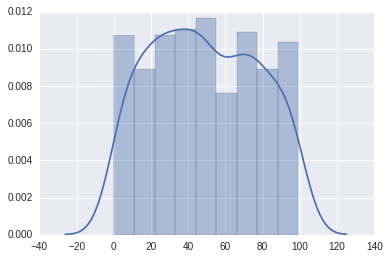
# 分布图,bin是直方的个数,kde是线型(false表示去掉线型),rug显示每个数据的分布(下面深蓝色的部分)sns.distplot(x1, bins=20, kde=False, rug=True)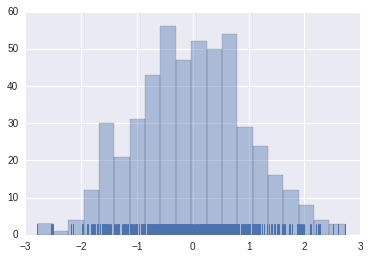
# 核密度估计,hist表示直方(false表示不要直方)sns.distplot(x2, hist=False, rug=True)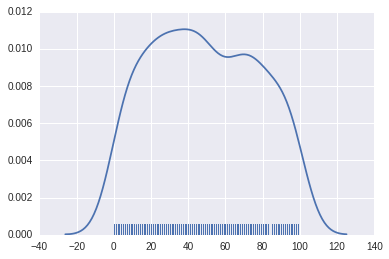
# 核密度函数也可以表示成如下,shade表示阴影sns.kdeplot(x2, shade=True)sns.rugplot(x2)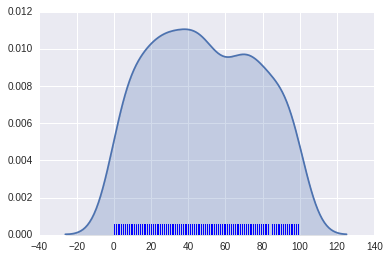
# 拟合参数分布sns.distplot(x1, kde=False, fit=stats.gamma)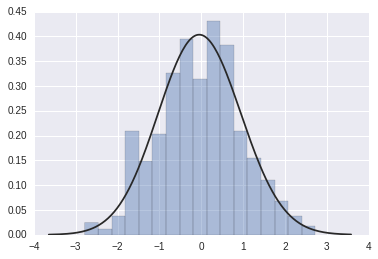
1.2 双变量分布
# 双变量分布df_obj1 = pd.DataFrame({"x": np.random.randn(500), "y": np.random.randn(500)})df_obj2 = pd.DataFrame({"x": np.random.randn(500), "y": np.random.randint(0, 100, 500)})# print df_obj1# print df_obj2# 散布图sns.jointplot(x="x", y="y", data=df_obj2)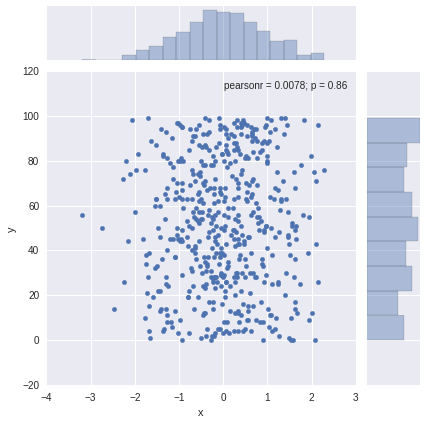
# 二维直方图sns.jointplot(x="x", y="y", data=df_obj2, kind="hex");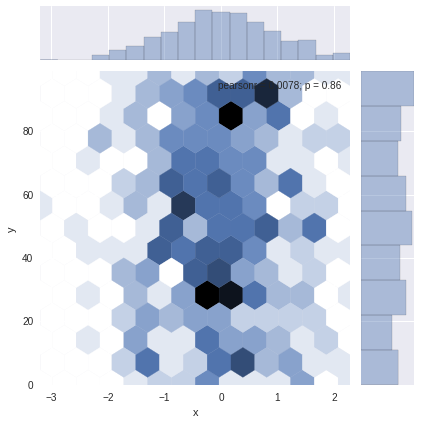
# 核密度估计sns.jointplot(x="x", y="y", data=df_obj1, kind="kde");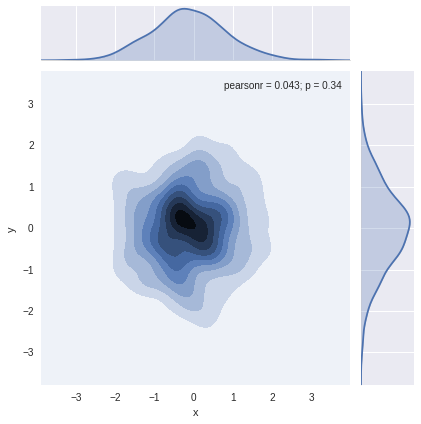
1.3 数据集中变量间关系可视化
# 数据集中变量间关系可视化dataset = sns.load_dataset("tips")#dataset = sns.load_dataset("iris")sns.pairplot(dataset);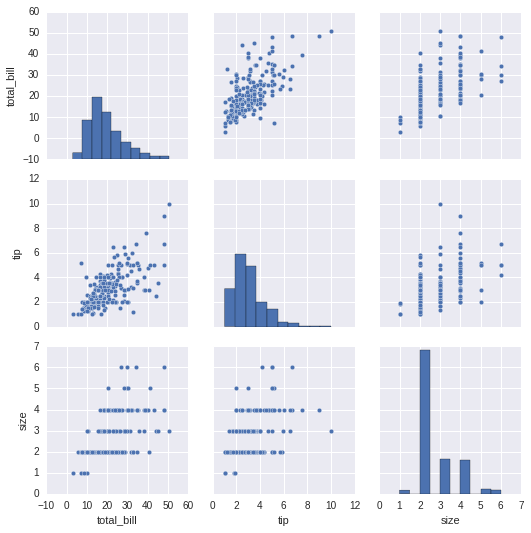
2. 类别数据可视化
#titanic = sns.load_dataset('titanic')#planets = sns.load_dataset('planets')#flights = sns.load_dataset('flights')#iris = sns.load_dataset('iris')exercise = sns.load_dataset('exercise') # 该数据集是自带的2.1 类别散布图
一个变量是类别变量,另一个是连续性变量。
使用.stripplot数据点会重叠
sns.stripplot(x="diet", y="pulse", data=exercise)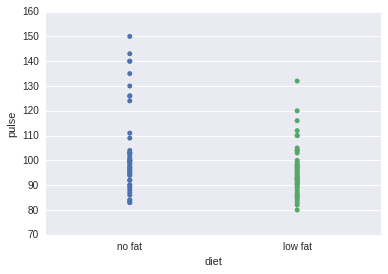
.swarmplot()数据点会避免重叠,并且会把其他列的信息也展现出来。
sns.swarmplot(x="diet", y="pulse", data=exercise, hue='kind')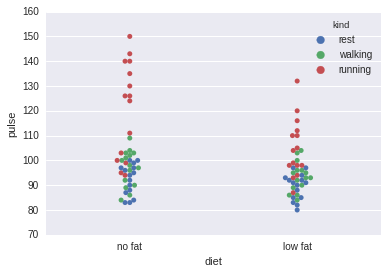
2.2 类别内数据分布
# 1.盒子图,类似与K线图sns.boxplot(x="diet", y="pulse", data=exercise)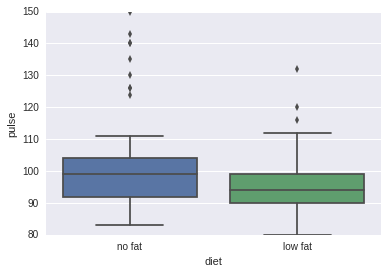
# 盒子图,hue指定子类别sns.boxplot(x="diet", y="pulse", data=exercise, hue='kind')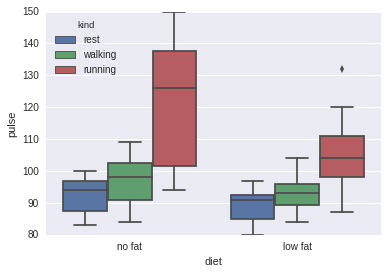
# 2.小提琴图#sns.violinplot(x="diet", y="pulse", data=exercise)sns.violinplot(x="diet", y="pulse", data=exercise, hue='kind')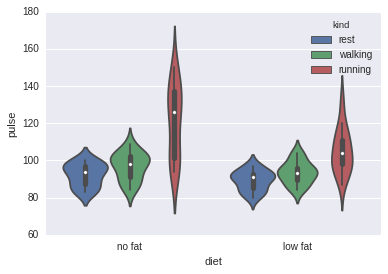
2.3 类别内统计图
# 柱状图sns.barplot(x="diet", y="pulse", data=exercise, hue='kind')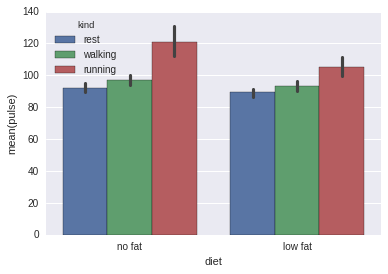
# 点图sns.pointplot(x="diet", y="pulse", data=exercise, hue='kind');
注:部分例子来自于小象学院Robin课程
0 0
- 04_2Python绘图_seaborn
- 04_1Python绘图_matplotlib
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- 绘图
- Deprecated
- 不同主机间的 Docker 容器相互通信
- 区分WORDPRESS user_login、user_nicename、user_displayname
- 使用yum更新时不升级Linux内核的方法
- Android 数据存储方法
- 04_2Python绘图_seaborn
- Oracle sqlldr快速导入
- 基于聚合数据的移动联通基站API接口的php完整代码实例
- Android中 value2的问题解决办法!
- 王朝 递归问题 汉诺塔
- javaMD5加密工具类
- 【51NOD1284】2 3 5 7的倍数(容斥原理)
- Android第二课;ImageView基本属性
- Qt模仿网易云音乐


