DL在NLP中的应用(三)RNN
来源:互联网 发布:三明网络招聘信息 编辑:程序博客网 时间:2024/04/29 10:28
本文译自http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
最近一直在做数据挖掘大作业-搜索相关性评价,利用ensemble的方法GBRT,RF等模型权重加和效果仅为52%(kappa score),想使用NN方法测试下效果,发现了RNN的两篇好文,一边翻译一边学习,若有不当之处,欢迎大家一起探讨。
第一部分 RNN简介
Recurrent Neural Networks (RNNs)循环神经网络(注意与递归神经网络的区分)在NLP中表现出了较好的应用前景。然而目前(2015.9.17)缺少关于RNNs原理和实现讲解的资源,本教程分成了几部分计划从以下几个方面进行介绍:
1.对于RNN的基本介绍(本篇文章)
2.使用Python和Theano实现一个RNN
3.理解BPTT和vanishing gradient 问题
4.实现一个GRU/LSTM RNN
作为本教程的一部分,我们会基于语言模型实现一个循环神经网络。语言模型的应用包含两方面:首先,语言模型允许我们基于句子在真实世界发生的概率给任意句子打分。这样可以方便我们对语法和语义的相似度进行测量。这种模型通常用于机器翻译系统。第二,语言模型允许我们生成新的文本。这篇文章阐述了基于RNN的字符级的语言模型可以做什么。
如果你对基本神经网络模型不了解,可以参考NN入门这篇文章。
什么是RNN?
RNN背后的思想是利用了序列信息。在传统的神经网络中,我们假设所有输入或输出都是彼此独立的。但是对于许多场景下并不适用。如果你想预测句子中的下一个单词,最好知道它的前一个单词。RNN之所以叫做循环神经网络是因为他们对于序列中的每一个元素执行相同的任务,输出与之前的计算结果有关。另一种理解是RNN对于他之前计算结果的信息有记忆功能。理论上,RNN可以利用任意长度序列的信息,但是实际上仅仅局限于后面的几步,下面是一个典型的RNN例子:

上图显示了一个RNN的展开,表明了一个完整序列的输出。例如,如果我们关注的是一个有着5个单词的句子,这个网络就会被延展为一个5层的神经网络,每层代表一个单词。RNN背后的计算原理为:
xt代表时间t时的输入。例如,x1是对应于句子中第二个单词的one-hot向量。
st是时间t时的隐藏状态。它代表网络的记忆。st的计算基于前面的隐藏状态和当前的输入:st=f(Uxt+Ws(t-1)函数 f通常是非线性函数如tanh或者ReLU.s一般初始化为0
ot是时间t的输出。例如,如果我们想预测句子中的下一个单词,结果会是一个概率向量。ot=softmax(Vst)
这里有一些需要注意的地方:
你可以认为隐藏状态是网络的记忆单元。可以捕捉到之前所有时刻产生的信息。输出仅仅依赖于时刻的记忆。就像之前提到的那样,在实际中是比较复杂的,因为通常难以捕捉许多时刻之前的信息。
与传统深度神经网络中每一层使用不同的参数的做法不同,RNN在所有时刻中共享相同的参数。这反应了在每一步中都在执行相同的任务,只是用了不同的输入。这极大地减少了需要学习的参数的个数。
上面的图中每一时刻都有输出,在具体的任务中,这可能是不必要的。例如,在预测一句话的情感时,我们关心的可能只是最终的输出,并不是每一个词之后的情感。相似地,可能并不是每一时刻都需要输入。RNN的主要特征是它的隐藏状态,可以捕捉一句话中的信息。
RNN能做什么?
RNN在NLP的很多任务中都取得了很大的成功。这里我要提下最常用的RNN类型是LSTM,相比于普通的RNN,它更擅长于捕捉长期依赖。但是不要担心,LSTM和我们这个教程里要介绍的RNN本质上是相同的,只是使用了一种不同的方式来计算隐藏状态。在后面的文章中,将会更详细的介绍LSTM。下面是RNN在NLP中的一些应用例子。
语言模型和文本生成
给定一个词的序列,我们想预测在前面的词确定之后,每个词出现的概率。语言模型可以度量一个句子出现的可能性,这可以作为机器翻译的一个重要输入(因为出现概率高的句子通常是正确的)。能预测下一个词所带来的额外效果是我们得到了一个生成模型,这可以让我们通过对输出概率采样来生成新的文本。根据训练数据的具体内容,我们可以生成任意东西。在语言模型中,输入通常是词的序列(编码成one hot向量),输出是预测得到的词的序列。在训练网络时,令ot=x(t+1),因为我们在时刻t时期望得到的是下一个词的真实值。
关于语言模型和文本生成的研究论文:
Recurrent neural network based language model Extensions of Recurrent neural network based language model
Generating Text with Recurrent Neural Networks
机器翻译
机器翻译与语言模型相似,输入是源语言中的一个词的序列(例如,德语),输出是目标语言(例如,英语)的一个词的序列。一个关键不同点在于在接收到了完整的输入后才会开始输出,因为我们要翻译得到的句子的第一个词可能需要前面整个输入序列的信息。
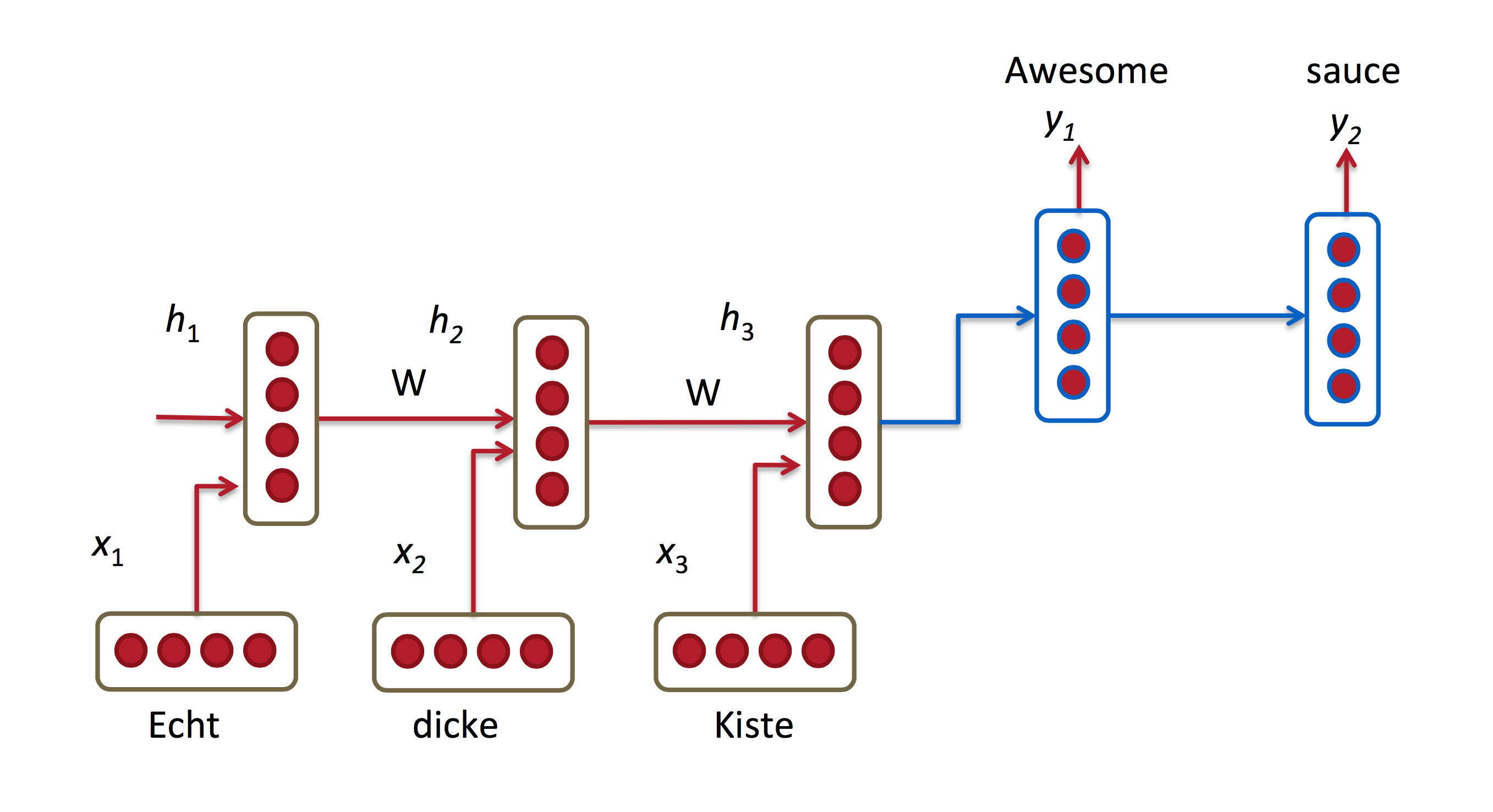
关于机器翻译的研究论文:
A Recursive Recurrent Neural Network for Statistical Machine Translation
Sequence to Sequence Learning with Neural Networks
Joint Language and Translation Modeling with Recurrent Neural Networks
语音识别
给定一段从声波中产生的输入声学信号序列,我们想要预测一个语音片段序列及其概率。
关于语音识别的研究论文:
Towards End-to-End Speech Recognition with Recurrent Neural Networks
图像描述生成
和卷及神经网络一起,RNN可以作为生成无标注图像描述模型的一部分。对于这个如何工作的看起来非常令人惊讶。这个联合模型甚至可以对齐生成的词和图像中的特征。 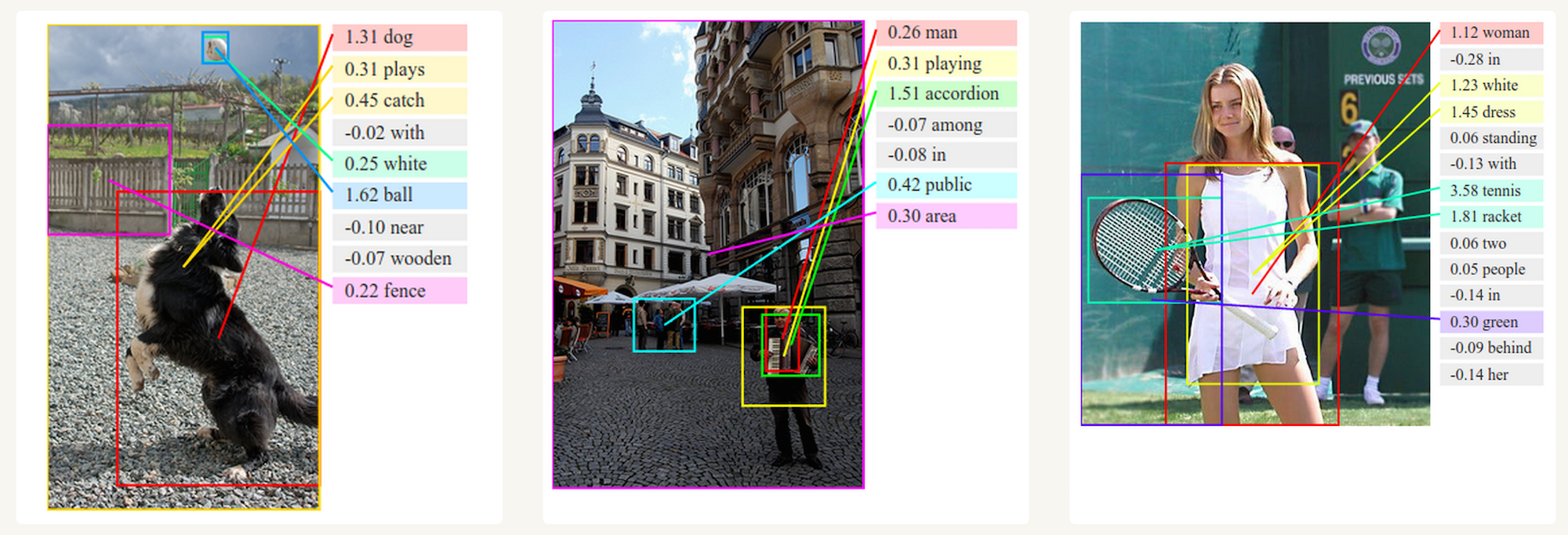
RNN训练
训练RNN和训练传统神经网络相似,同样要使用反向传播算法,但会有一些变化。因为参数在网络的所有时刻是共享的,每一次的梯度输出不仅依赖于当前时刻的计算结果,也依赖于之前所有时刻的计算结果。例如,为了计算时刻的梯度,需要反向传播3步,并把前面的所有梯度加和。这被称作随时间的反向传播(BPTT)。如果你现在没有理解,不要担心,后面会有关于更多细节的文章。现在,只要知道普通的用BPTT训练的RNN对于学习长期依赖(相距很长时间的依赖)是很困难的,因为这里存在梯度消失或爆炸问题。当然也存在一些机制来解决这些问题,特定类型的RNN(如LSTM)就是专门设计来解决这些问题的。
RNN扩展
这些年来,研究者们已经提出了更加复杂的RNN类型来克服普通RNN模型的缺点,在后面的博客中会更详细的介绍它们,这一节只是一个简单的概述让你能够熟悉模型的类别。
Bidirectional RNN的思想是时刻的输出不仅依赖于序列中之前的元素,也依赖于之后的元素。例如,要预测一句话中缺失的词,你可能需要左右上下文。Bidirecrtional RNN很直观,只是两个RNN相互堆叠在一起,输出是由两个RNN的隐藏状态计算得到的。 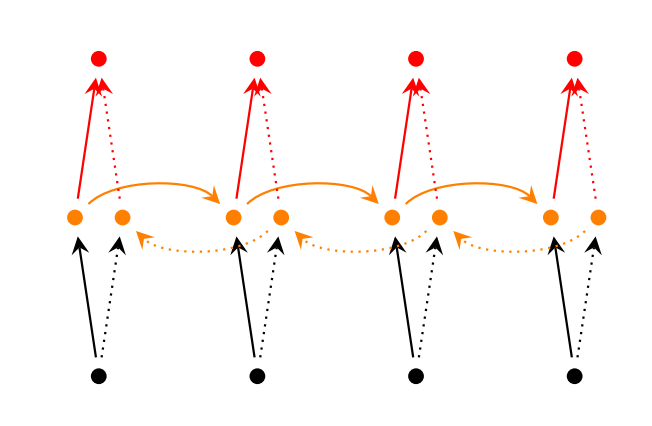
Deep (Bidirectional)RNN和Bidirectional RNN相似,只是在每个时刻会有多个隐藏层。在实际中会有更强的学习能力,但也需要更多的训练数据。 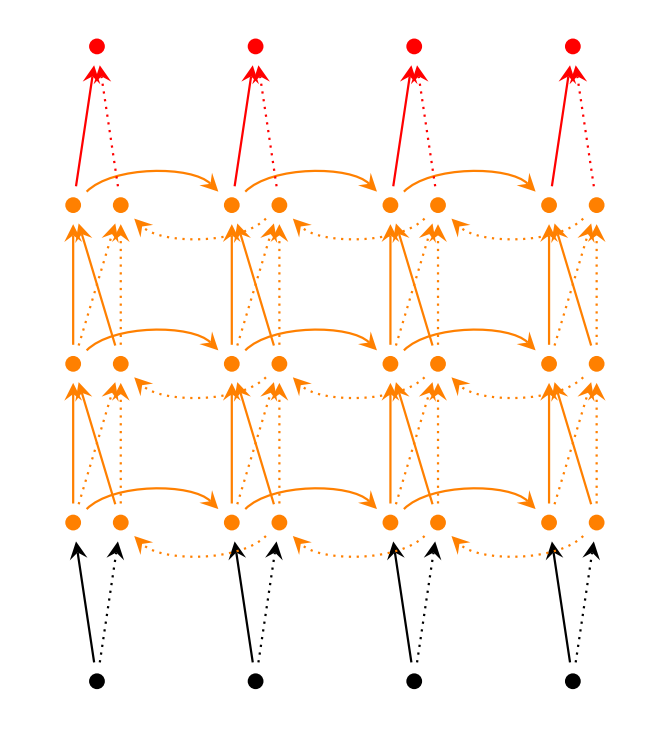
LSTM network最近非常流行,上面也简单讨论过。LSTM与RNN在结构上并没有本质的不同,只是使用了不同的函数来计算隐藏状态。LSTM中的记忆单元被称为细胞,你可以把它当作是黑盒,它把前一刻的状态和当前输入。内部这些细胞能确定什么被保存在记忆中,什么被从记忆中删除。这些细胞把之前的状态和当前的输入结合起来,事实证明这些类型的单元对处理长时间依赖时十分有效。LSTM在初学时会让人觉得困惑,如果你想了解更多,可以参考这篇博客Understanding LSTM Networks
总结
到目前为止希望你已经对RNN是什么以及能做什么有了基本的了解,在接下来的文章中,我会使用python和theano实现RNN语言模型的第一个版本。
- DL在NLP中的应用(三)RNN
- RNN(三) 在SLU中的应用
- CNN和RNN在NLP任务中的对比实验
- 自然语言处理(NLP)在企业应用中的实践(三)
- TensorFlow实战:Chapter-7上(RNN简介和RNN在NLP应用)
- 在NLP上,CNN、RNN(认为LSTM等变体也是RNN)、最简单全连结MLP,三者相比,各有何优劣?
- 自然语言处理技术(NLP)在推荐系统中的应用
- 自然语言处理技术(NLP)在推荐系统中的应用
- 自然语言处理技术(NLP)在推荐系统中的应用
- RNN在自然语言处理中的应用
- 主成分分析在nlp中的应用
- 深度学习在NLP中的应用
- CNN模型和RNN模型在分类问题中的应用(Tensorflow实现)
- TensorFlow在MNIST中的应用-循环神经网络RNN
- RNN在自然语言处理中的应用及其PyTorch实现
- RNN在自然语言处理中的应用及其PyTorch实现
- 自然语言处理(NLP)在企业应用中的实践(一)
- 自然语言处理(NLP)在企业应用中的实践(二)
- Spring 框架参考文档(四)-数据访问之 Data access with JDBC
- 【MongoDb探究】05-深入查询表达式1
- Maximum Subarray
- 使用angularjs1.x构建前台开发框架(八)——弹窗【二】
- Docker1.12版本swarm模式下的网络模型
- DL在NLP中的应用(三)RNN
- 网络程序设计课程项目总结
- Windows 10 安装GitHub Desktop问题解决
- 【转】可取消的异步操作
- 新一年新开始
- ZCMU-1312-奇偶数
- 比较详细git教程收集
- 反向代理和正向代理的区别
- js中数据类型的检测


