循环神经网络教程第3部分 BPTT
来源:互联网 发布:关键词外包优化 编辑:程序博客网 时间:2024/04/28 06:45
在本教程的前面部分,我们从头实现了RNN,但没有详细介绍如何通过BPTT算法计算梯度。在本部分中,我们将简要概述BPTT并解释它与传统反向传播的区别。然后我们将尝试理解消失梯度问题,这导致了LSTM和GRU的发展,这两个是目前应用于NLP(和其他领域)最流行的模型。消失梯度问题最初是由Sepp Hochreiter于1991年发现的,最近由于深度架构的应用的增加而受到关注。
要完全理解这一部分,我建议你先熟悉微分链式规则和基本反向传播原理。如果你不熟悉,你可以以增加难度的顺序在这里,这里和这里找到优秀的教程。
BPTT
让我们快速回顾一下RNN的基本方程。注意,现在o变成了
我们也定义了损失(或错误)是交叉熵损失:
这里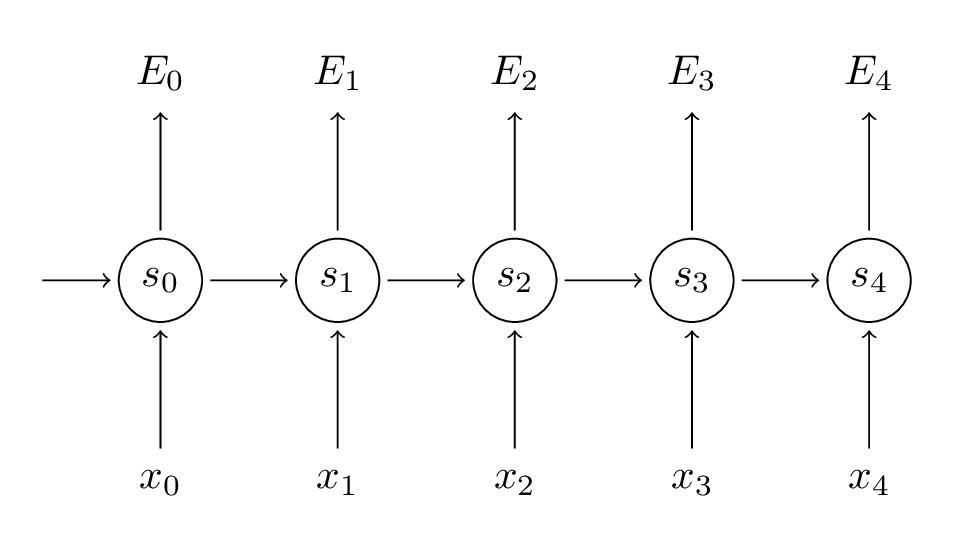
记住,我们的目标是计算参数
为了计算这些梯度,我们使用微分链式的规则。这是从错误开始应用反向传播的反向传播算法。对于本文的其余部分,我们将使用
在上式中,
但是计算
用代码实现一个原生的BPTT大概像如下这样:
def bptt(self, x, y): T = len(y) # Perform forward propagation o, s = self.forward_propagation(x) # We accumulate the gradients in these variables dLdU = np.zeros(self.U.shape) dLdV = np.zeros(self.V.shape) dLdW = np.zeros(self.W.shape) delta_o = o delta_o[np.arange(len(y)), y] -= 1. # For each output backwards... for t in np.arange(T)[::-1]: dLdV += np.outer(delta_o[t], s[t].T) # Initial delta calculation: dL/dz delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2)) # Backpropagation through time (for at most self.bptt_truncate steps) for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]: # print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step) # Add to gradients at each previous step dLdW += np.outer(delta_t, s[bptt_step-1]) dLdU[:,x[bptt_step]] += delta_t # Update delta for next step dL/dz at t-1 delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2) return [dLdU, dLdV, dLdW]从这里你可以看出为什么标准的RNN对于训练长序列(句子),20个单词或更多的句子非常困难了,因为你需要后向传播很多层。在实践中,许多人将反向传播截断到几个步骤。
梯度消失问题
让我们再仔细看一下我们上面计算的梯度:
我们可以把上面的梯度写成:
因为
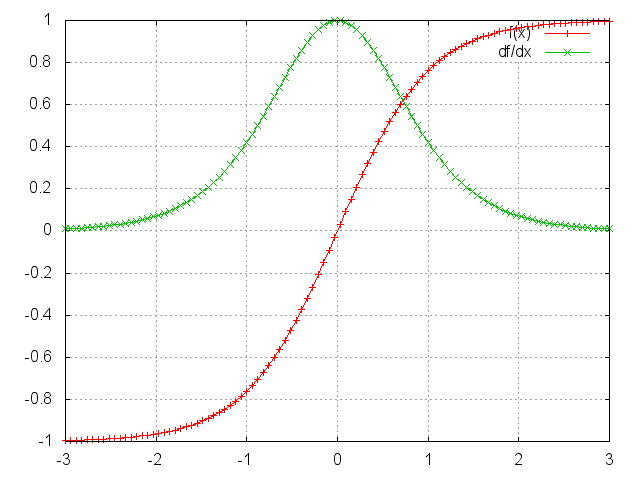
可以看出
很容易想象,根据我们的激活函数和网络参数,如果Jacobian矩阵的值很大,梯度将会爆炸而不是消失。这被称为梯度爆炸问题。梯度消失比梯度爆炸更受关注的原因有两方面的。首先,梯度爆炸是显而易见的,梯度将成为NaN(不是一个数字),你的程序会崩溃。其次,通过预定义的阈值(如这篇论文所讨论的那样)中截取梯度,对爆炸梯度来说是非常简单有效的解决方案。梯度消失有更多的问题,因为当它们发生时不是很明显,处理它们的方法也不是很容易想到。
幸运的是,有几种方法可以缓解梯度消失问题。
- 循环神经网络教程第3部分 BPTT
- 循环神经网络教程第三部分-BPTT和梯度消失
- BPTT-应用于简单的循环神经网络
- RNN循环神经网络里的BPTT算法
- 循环神经网络教程-第一部分 RNN介绍
- 循环神经网络教程第一部分-RNN简介
- 循环神经网络(RNN)反向传播算法(BPTT)理解
- 循环神经网络(RNN)反向传播算法(BPTT)理解
- 反向传播(BPTT)与循环神经网络(RNN)文本预测
- RNN循环神经网络中的权重更新算法-BPTT
- 循环神经网络(RNN)反向传播算法(BPTT)
- 循环神经网络教程第四部分-用Python和Theano实现GRU/LSTM循环神经网络
- 循环神经网络教程 Part 3笔记
- Microformats教程 第3部分
- 循环神经网络教程-第二部分 用python numpy theano实现RNN
- 循环神经网络教程 第四部分 用Python 和 Theano实现GRU/LSTM RNN
- 循环神经网络教程第二部分-用python,numpy,theano实现一个RNN
- 神经网络中的BPTT算法简单介绍
- 数据结构::堆及堆的应用~
- 斐讯K2路由器设置
- 【问题解决】configChanges详解-之解决问题:手机切换字体后,app异常崩溃
- scala数据结构和算法-02-用模式匹配实现合并排序
- Linux部分命令全称
- 循环神经网络教程第3部分 BPTT
- 与Bootstrap和CI框架纠缠的三天
- 关于RecyclerView刷新
- 【LINUX】对于安装时磁盘分区的解释
- Rx系列二 | Observer | Observable
- struts2关于"There is no Action mapped for namespace / and action name"的解决方法
- Java学习笔记--IO流的操作
- HTML attribute 与 DOM property 的对比
- 对mysql存储性能优化的基本理解


