MXNet 中文教程:图像分类
来源:互联网 发布:js文本框提示信息 编辑:程序博客网 时间:2024/05/19 13:17
本人对于 MXNet 官方文档的 github 翻译页面:
https://github.com/ironyoung/mxnet/blob/master/docs/tutorials/computer_vision/image_classification.md
这个教程中,我们将标签分配给某张图片,并得到标签符合程度的评分高低。下列图片 (source) 展示了一个例子:

获取教程中的源代码:GitHub.
训练
针对特定的数据集训练模型,使用 train_dataset.py。例如:
- 为了训练一个 mnist 数据集上的 MLP 模型,使用以下命令:
python train_mnist.py- 为了在每个训练迭代时保存中间模型,使用以下命令:
mkdir model; python train_mnist.py --model-prefix model/mnist- 为了从第8个训练迭代时保存的模型重新开始训练,使用以下命令:
python train_mnist.py --model-prefix model/mnist --load-epoch 8- 为了选择另一种初始学习速率,并且将其在每半次训练迭代时以 0.9 的比例进行衰减,使用以下命令:
python train_mnist.py --lr .1 --lr-factor .9 --lr-factor-epoch .5- 为了使用 GPU 0 在 mnist 数据集上训练卷积神经网络,使用以下命令:
python train_mnist.py --network lenet --gpus 0为了使用多块 GPU,需要指定列表;例如:
---gpus 0,1,3.To see more options, use
--help.
分布式训练
为了加速训练过程,可以利用多台电脑进行训练。
- 使用 2 个 workder 进程,快速测试你本地电脑的分布式训练:
../../tools/launch.py -n 2 python train_mnist.py --kv-store dist_sync你可以任意使用同步的 SGD dist_sync 或者异步的 SGD
dist_async(SGD:随机梯度下降法)。
- 如果你可以使用 SSH 连接多台电脑,并且 mxnet 文件夹可以被这些电脑访问到 (作为一整个 NFS 被安装;查看教程:Ubuntu),那么就可以在这些电脑上运行一个作业,首先通过在文件上保存他们的 hostname,例如:
$ cat hosts 172.30.0.172 172.30.0.171- 使用
-H选项传递这个文件:
../../tools/launch.py -n 2 -H hosts python train_mnist.py --kv-store dist_sync- 如果 mxnet 文件夹在其他电脑上不可使用,复制 mxnet 库文件到这个示例文件夹中:
cp -r ../../python/mxnet . cp -r ../../lib/libmxnet.so mxnet然后在运行之前,将此文件夹同步到其他电脑 /tmp/mxnet 中:
../../tools/launch.py -n 2 -H hosts --sync-dir /tmp/mxnet python train_mnist.py --kv-store dist_sync更多的安装选项,例如使用 YARN,以及关于如何编写分布式训练的程序的信息,请参见教程.
生成预测值
你有几个选项用于生成预测值:
- 使用 预先训练完毕的模型. 更多预先训练完毕的模型展示在 model gallery;
- 使用你自己的数据集;
- 你可以方便地运行并得到预测值在多种设备上,例如
Android/iOS。
使用你自己的数据集
有两种方式用于向 MXNet 中输入数据:
将所有例子打包到一个或多个压缩的
recordio文件中。更多有关信息请参见 逐步教程 和 使用文档。需要在打包时避免一个常见的疏忽:随机化图片列表。这回造成训练失败,例如accuracy在几轮训练中都保持为 0.001。注意: 我们自动下载了几个小型数据集,例如
mnist和cifar10。对于小数据集而言,可以被简单地导入到内存中,这里是一个例子:
from sklearn.datasets import fetch_mldata from sklearn.utils import shuffle mnist = fetch_mldata('MNIST original', data_home="./mnist") # shuffle data X, y = shuffle(mnist.data, mnist.target) # split dataset train_data = X[:50000, :].astype('float32') train_label = y[:50000] val_data = X[50000: 60000, :].astype('float32') val_label = y[50000:60000] # Normalize data train_data[:] /= 256.0 val_data[:] /= 256.0 # create a numpy iterator batch_size = 100 train_iter = mx.io.NDArrayIter(train_data, train_label, batch_size=batch_size, shuffle=True) val_iter = mx.io.NDArrayIter(val_data, val_label, batch_size=batch_size) # create model as usual: model = mx.model.FeedForward(...) model.fit(X = train_iter, eval_data = val_iter)提高性能
下列因素可以极大提高性能:
- 快速处理数据的后端。一个快速 BLAS 库,例如 openblas、atlas 和 mkl,在你使用 CPU 处理器进行训练时是必需的。而对于英伟达的 GPU 而言,我们强烈建议使用 CUDNN。
输入数据:
数据格式。使用
.rec数据格式。解码线程的数量。默认情况下,MXNet 使用 CPU 线程来解码图片,可以每秒解码多余 1 Kb 的图片。如果你在使用高档的 CPU 或者性能强劲的 GPU,可以增加线程数量。
数据存储位置。任何本地或者分布式文件系统(HDFS, Amazon S3)都可以。然而,如果多台电脑同时读取网络共享文件系统(network shared file system,NFS)中的数据,你可能会遇到问题。
批处理尺寸。我们推荐使用 GPU 显存的最大容量来容纳。当尺寸取值太大时,可能会造成收敛速度变慢。一个对于 CIFAR 10 数据库的安全批处理尺寸大约是 200;对于 ImageNet 1K,批处理尺寸大小可以超过 1 Kb。
如果你用到了多块 GPU,需要使用
kvstore。更多信息请参见这份指导文档.对于单台电脑而言,默认参数
local一般足够。对于大小超过 100 MB 的模型,例如 AlexNet 和 VGG,你可能想要使用参数local_allreduce_device。参数local_allreduce_device相较于其他参数使用了更多的 GPU 显存。对于多台电脑而言,我们首先推荐尝试使用参数
dist_sync。如果这个模型太大,或者你使用到了大量的电脑,你可能想要使用参数dist_async。
实验结果
- 电脑配置
- 数据集
CIFAR 10
- 命令
python train_cifar10.py --batch-size 128 --lr 0.1 --lr-factor .94 --num-epoch 50- 效率
- 准确率 vs 迭代次数(交互式图表):

ILSVRC 12
VGG
train_imagenet.py with --network vgg
- 效率
none 14,545 - - 2 - local 19,692 - - 4 - - 20,014 - - 2 - local_allreduce_device 9,142 - - 4 - - 8,533 - - - 384 - 5,161开始批处理正交化
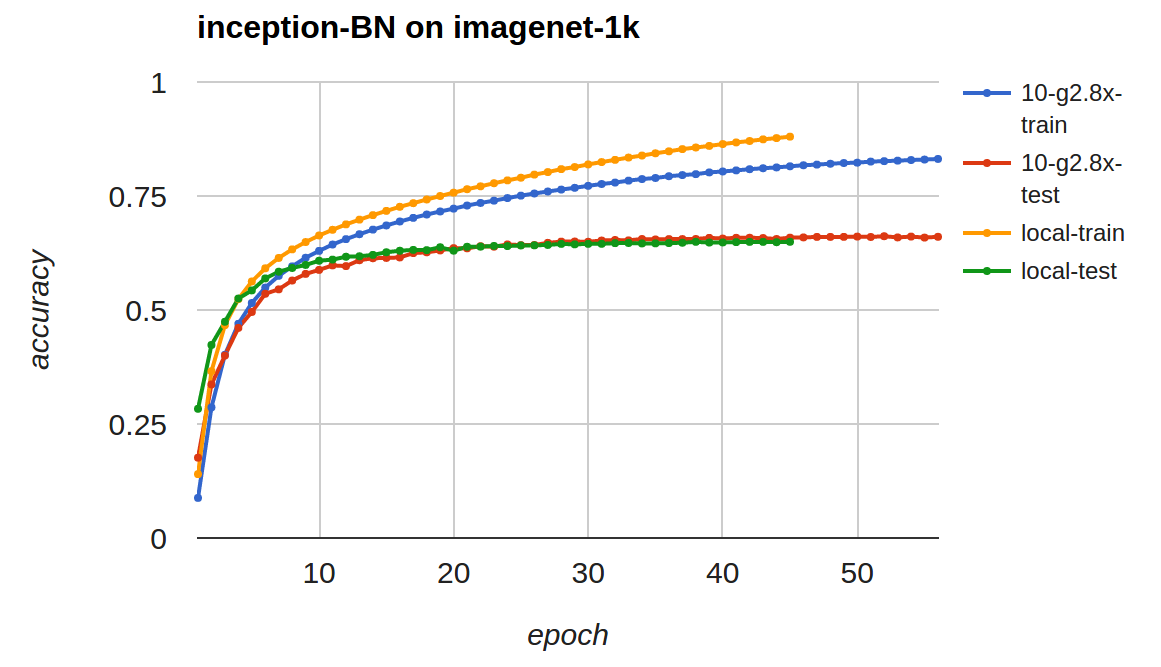
train_imagenet.py with --network inception-bn
- 效率
local 13,210 - - 2 64 - 7,198 - - 3 128 - 4,952 - - 4 - - 3,589 TitanX 1 1 128 none 10,666 - - 2 - local 5,161 - - 3 - - 3,460 - - 4 - - 2,844 - - - 512 - 2,495 EC2-g2.8x 1 4 144 local 14,203 - 10 40 144 dist_sync 1,422- 收敛
单机 :
python train_imagenet.py --batch-size 144 --lr 0.05 --lr-factor .94 \ --gpus 0,1,2,3 --num-epoch 60 --network inception-bn \ --data-dir ilsvrc12/ --model-prefix model/ilsvrc1210 x g2.8x:hosts包含 10 台电脑的私有 IP 地址../../tools/launch.py -H hosts -n 10 --sync-dir /tmp/mxnet \ python train_imagenet.py --batch-size 144 --lr 0.05 --lr-factor .94 \ --gpus 0,1,2,3 --num-epoch 60 --network inception-bn \ --kv-store dist_sync \ --data-dir s3://dmlc/ilsvrc12/ --model-prefix s3://dmlc/model/ilsvrc12注意: Amazon S3 上偶尔的不稳定性可能会造成训练中断或者频繁生成错误,首先需要组织下载数据到
/mnt文件夹中。- 准确率 vs. 迭代次数 (交互式图表):
下一步
- MXNet 教程索引
- MXNet 中文教程:图像分类
- mxnet 图像分类
- mxnet大规模图像分类
- MXNet官方文档中文版教程(9):大规模图像分类
- MXNet 中文文档
- MXNet 中文文档
- MXNet安装教程
- MXNet安装教程
- Matplotlib 中文用户指南 3.2 图像教程
- MXNet如何用mxnet.image.ImageIter直接导入图像
- Mxnet图片分类(1)准备数据集
- Mxnet图片分类(2)训练模型
- Mxnet图片分类(3)fine-tune
- R语言深度学习mxnet做分类
- 图像分类
- mxnet
- MXNet
- MXNet
- Windows平台下,将mdb文件快速向MySQL中导入数据的方法
- java学习之路 之 基本语法-程序流程控制-(if-else)语句练习题
- 交叉编译详解 三 使用脚本自动生成交叉编译链
- 两阶段提交协议与三阶段提交协议
- 机器学习入门之基本概念
- MXNet 中文教程:图像分类
- 分布式事务 - 两阶段提交与三阶段提交
- CSS学习笔记:border-image
- android mvp模式
- Surrounded Regions
- 一分钟了解两阶段提交2PC(运营MM也懂了)
- Hibernate使用注解方式
- 浅谈mysql的两阶段提交协议
- LeetCode 449. Serialize and Deserialize BST


