Encoder-Decoder模型和Attention模型
来源:互联网 发布:国泰君安港股交易软件 编辑:程序博客网 时间:2024/06/05 18:05
这两天在看attention模型,看了下知乎上的几个回答,很多人都推荐了一篇文章Neural Machine Translation by Jointly Learning to Align and Translate 我看了下,感觉非常的不错,里面还大概阐述了encoder-decoder(编码)模型的概念,以及传统的RNN实现。然后还阐述了自己的attention模型。我看了一下,自己做了一些摘录,写在下面
1.Encoder-Decoder模型及RNN的实现
所谓encoder-decoder模型,又叫做编码-解码模型。这是一种应用于seq2seq问题的模型。
那么seq2seq又是什么呢?简单的说,就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。
为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。

当然了,这个只是大概的思想,具体实现的时候,编码器和解码器都不是固定的,可选的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由组合。比如说,你在编码时使用BiRNN,解码时使用RNN,或者在编码时使用RNN,解码时使用LSTM等等。
这边为了方便阐述,选取了编码和解码都是RNN的组合。在RNN中,当前时间的隐藏状态是由上一时间的状态和当前时间输入决定的,也就是
获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后的语义向量
一种简单的方法是将最后的隐藏层作为语义向量C,即
解码阶段可以看做编码的逆过程。这个阶段,我们要根据给定的语义向量C和之前已经生成的输出序列
也可以写作
而在RNN中,上式又可以简化成
其中
encoder-decoder模型虽然非常经典,但是局限性也非常大。最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。但是这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了
2.Attention模型
为了解决这个问题,作者提出了Attention模型,或者说注意力模型。简单的说,这种模型在产生输出的时候,还会产生一个“注意力范围”表示接下来输出的时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出,如此往复。模型的大概示意图如下所示

相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
在这篇文章中,作者提出了一个用于翻译任务的结构。解码部分使用了attention模型,而在编码部分,则使用了BiRNN(bidirectional RNN,双向RNN)
2.1 解码
我们先来看看解码。解码部分使用了attention模型。类似的,我们可以将之前定义的条件概率写作
上式
注意这里的条件概率与每个目标输出
由于编码使用了双向RNN,因此可以认为
也就是说,
上面这些公式就是解码器在第i个时间段内要做的事情。作者还给了一个示意图:
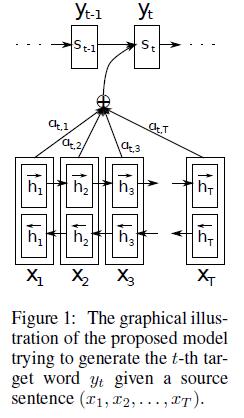
2.2 编码
相比于上面解码的创新,这边的编码就比较普通了,只是传统的单向的RNN中,数据是按顺序输入的,因此第j个隐藏状态
3.实验结果
为了检验性能,作者分别使用传统模型和attention模型在英语-法语的翻译数据集上进行了测验。
传统模型的编码器和解码器各有1000个隐藏单元。编码器中还有一个多层神经网络用于实现从隐藏状态到单词的映射。在优化方面,使用了SGD(minibatch stochastic gradient descent)以及Adadelta,前者负责采样,后者负责优化下降方向。
得到的结果如下: 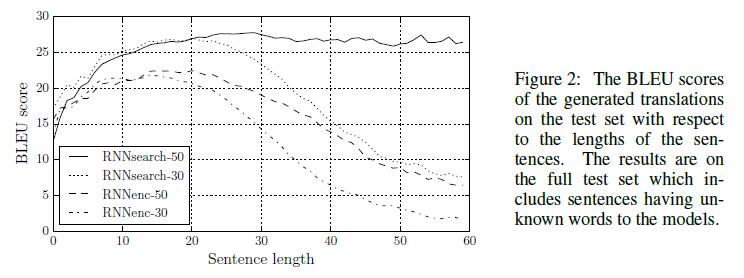
图中RNNenc表示传统的结构,而RNNsearch表示attention模型。后面的数字表示序列的长度。可以看到,不论序列长度,attention模型的性能均优于传统的编码-解码模型。而RNNsearch-50甚至在长文本上的性能也非常的优异
除了准确度之外,还有一个很值得关注的东西:注意力矩阵。之前已经提过,每个输出都有一个长为
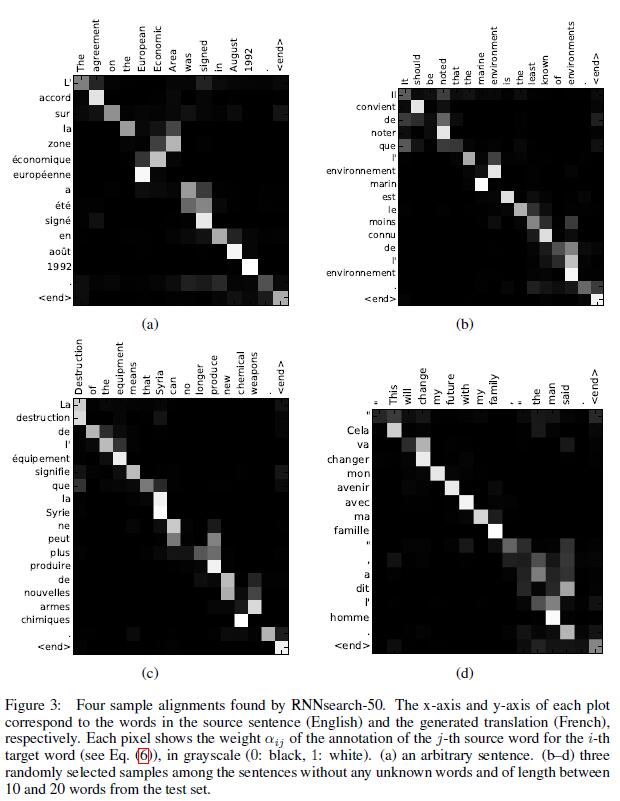
其中x轴表示待翻译的句子中的单词(英语),y轴表示翻译以后的句子中的单词(法语)。可以看到尽管从英语到法语的过程中,有些单词的顺序发生了变化,但是attention模型仍然很好的找到了合适的位置。换句话说,就是两种语言下的单词“对齐”了。因此,也有人把注意力模型叫做对齐(alignment)模型。而且像比于用语言学实现的硬对齐,这种基于概率的软对齐更加优雅,因为能够更全面的考虑到上下文的语境。
- Encoder-Decoder模型和Attention模型
- Encoder-Decoder模型和Attention模型
- Encoder-Decoder模型和Attention模型
- Encoder-Decoder模型和Attention模型
- 深度学习笔记(六):Encoder-Decoder模型和Attention模型
- 机器翻译Encoder-Decoder模型
- Encoder-Decoder模型
- 使用Encoder-Decoder模型自动生成对联的思路
- 轰炸理解深度学习里面的encoder-decoder模型
- 深度学习方法(八):自然语言处理中的Encoder-Decoder模型,基本Sequence to Sequence模型
- 深度学习-->NLP-->Seq2Seq Learning(Encoder-Decoder,Beam Search,Attention)
- encoder-decoder
- encoder-decoder
- Attention:注意力模型
- 一些encoder和decoder的资料
- Netty protobuf使用,自定义Encoder 和DeCoder
- 深度学习的Attention模型
- 深度学习的Attention模型
- 国际化用的语言代码及名称
- 关于拦截器与过滤器使用场景、拦截器与过滤器的区别整理
- Eclipse Xml编译错误Referenced file contains errors - spring-beans-4.0.xsd
- Spring - 通知(Advice)和顾问(Advisor)
- jQuery事件触发
- Encoder-Decoder模型和Attention模型
- LINUX 设备驱动(完善 版(三))
- 计算机是如何启动的?
- Android 广播大全
- C++预处理详解
- APP版本升级,服务端API设计
- 2016.12.30【初中部 GDKOI】模拟赛B组
- Spring Boot中使用JavaMailSender发送邮件
- 瑞士制造的智慧--做好最后的1%


