Adaboost算法及分析
来源:互联网 发布:飞鸽翻墙软件7.59 编辑:程序博客网 时间:2024/06/04 01:08
提升的思想:
对于分类问题,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易的多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强大分类器。大多数的提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同的训练数据分布调用弱学习算法学习一系列弱分类器。
那么就存在两个问题(1)每一轮如何改变训练数据的权值分布(2)如何将这些弱分类器线性组合起来。在AdaBoost算法中,改变训练数据的权值分布是提高那些在前一轮中分类错误样本的权值,并降低那些分类正确样本的权值。在线性组合弱分类器时,加大误差率小的弱分类器权值,减小误差率大的弱分类器权值。
Adaboost算法步骤: 

Adaboost是一种比较有特点的算法,可以总结如下:
1)每次迭代改变的是样本的分布,而不是重复采样(re weight)
2)样本分布的改变取决于样本是否被正确分类
总是分类正确的样本权值低
总是分类错误的样本权值高(通常是边界附近的样本)
3)最终的结果是弱分类器的加权组合
权值表示该弱分类器的性能
简单来说,Adaboost有很多优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting!
总之:adaboost是简单,有效。
AdaBoost例子
第一步

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1,其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:
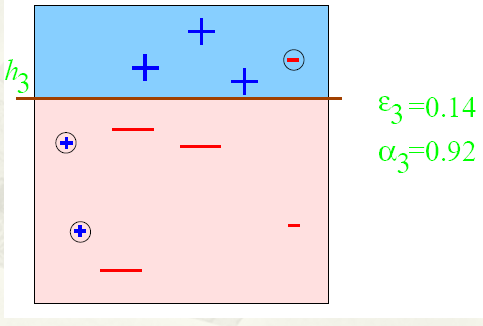
得到一个子分类器h3
整合所有子分类器:
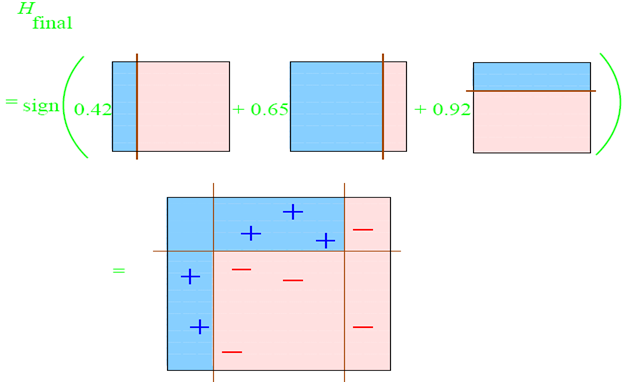
因此可以得到整合的结果,从结果中看,即使简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
Adaboost算法的某些特性是非常好的,此处,主要介绍adaboost的两个特性。一是训练的错误率上界,随着迭代次数的增加,会逐渐下降;二是adaboost算法即使训练次数很多,也不会出现过拟合的问题。
下面主要通过证明过程和图表来描述这两个特性:
1)错误率上界下降的特性(推导)



可以看出,随着迭代次数的增加,训练误差率上界以指数形式下降。
2)不会出现过拟合现象
通常,过拟合现象指的是下图描述的这种现象,即随着模型训练误差的下降,实际上,模型的泛化误差(测试误差)在上升。横轴表示迭代的次数,纵轴表示训练误差的值。
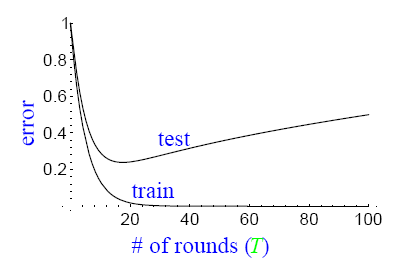
而实际上,并没有观察到adaboost算法出现这样的情况,即当训练误差小到一定程度以后,继续训练,泛化误差仍然不会增加。
对这种现象的解释,要借助margin的概念,其中margin表示如下:
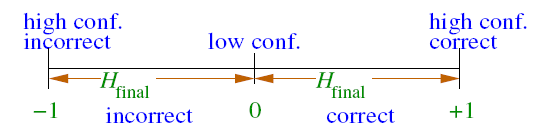
通过引入margin的概念,我们可以观察到下图所出现的现象:
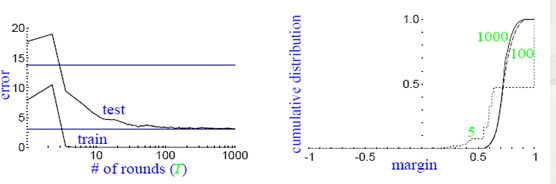
从图上左边的子图可以看到,随着训练次数的增加,test的误差率并没有升高,同时对应着右边的子图可以看到,随着训练次数的增加,margin一直在增加。这就是说,在训练误差下降到一定程度以后,更多的训练,会增加分类器的分类margin,这个过程也能够防止测试误差的上升。
参考资料:
博客 Boosting算法简介
《统计学习方法》 李航
- Adaboost算法及分析
- AdaBoost算法源码分析
- Adaboost 算法及原理
- AdaBoost算法简介及入门
- AdaBoost算法简介及入门
- AdaBoost原理、算法及应用
- AdaBoost 算法原理及推导
- AdaBoost 算法原理及推导
- 决策树理论、C4.5源码分析及AdaBoost算法的提升改造
- 【机器学习】AdaBoost算法分析与实现
- opencv中adaboost训练算法分析
- Adaboost算法原理及实例解析
- AdaBoost算法原理及OpenCV实例
- 机器学习:AdaBoost 算法及Python实现
- adaboost算法
- AdaBoost算法
- AdaBoost 算法
- Adaboost算法
- marathon升级:1.1.1到1.3.6
- UVA 272
- 每月要求 -2017
- 第37课 - 深度解析 QMap 与 QHash
- 最大子段和
- Adaboost算法及分析
- Struts2的OGNL 表达式
- jQuery 使用笔记(一)
- Ubuntu 16.04 LTS 常用软件(一)
- Linux配置java环境
- RecyclerView之ItemTouchHelper仿今日头条频道管理拖动
- 447. Number of Boomerangs#2(Done)
- Android开发之WindowManager详解
- 第十四章.滚动监听


