python学习之(7)正则表达式篇
来源:互联网 发布:minecraftpe凡家物语js 编辑:程序博客网 时间:2024/06/07 18:28
正则表达式是用于处理字符串的强大工具,其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同。下图展示了使用正则表达式进行匹配的流程:
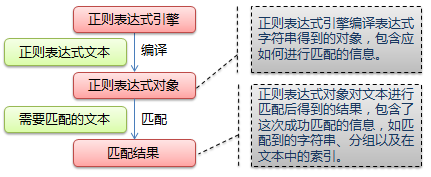
1.1介绍
正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同,不被支持的语法通常是不常用的部分。
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
1.2各种用法
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。多数字母和数字前加一个反斜杠时会拥有不同的含义。标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'/t',等价于'//t')匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。
模式
re{ n,}精确匹配n个前面表达式。re{ n, m}匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式a| b匹配a或b(re)G匹配括号内的表达式,也表示一个组(?imx)正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。(?-imx)正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。(?: re)类似 (...), 但是不表示一个组(?imx: re)在括号中使用i, m, 或 x 可选标志(?-imx: re)在括号中不使用i, m, 或 x 可选标志(?#...)注释.(?= re)前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。(?! re)前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功(?> re)匹配的独立模式,省去回溯。\w匹配字母数字\W匹配非字母数字\s匹配任意空白字符,等价于 [\t\n\r\f].\S匹配任意非空字符\d匹配任意数字,等价于 [0-9].\D匹配任意非数字\A匹配字符串开始\Z匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c\z匹配字符串结束\G匹配最后匹配完成的位置。\b匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。\B匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。\n, \t, 等.匹配一个换行符。匹配一个制表符。等\1...\9匹配第n个分组的子表达式。\10匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。
字符类
特殊字符类
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数,主要用到的方法列举如下:
#返回pattern对象re.compile(string[,flag]) #以下为匹配所用函数re.match(pattern, string[, flags])re.search(pattern, string[, flags])re.split(pattern, string[, maxsplit])re.findall(pattern, string[, flags])re.finditer(pattern, string[, flags])re.sub(pattern, repl, string[, count])re.subn(pattern, repl, string[, count]) re.match(pattern, string[, flags])
这个方法将会从 string(我们要匹配的字符串)的开头开始,尝试匹配 pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回 None,如果匹配未结束已经到达 string 的末尾,也会返回 None。两个结果均表示匹配失败,否则匹配 pattern 成功,同时匹配终止,不再对string 向后匹配。下面例子均基于python2.7。
__author__ = 'fcq'# -*- coding: utf-8 -*-#导入re模块import re# 将正则表达式编译成Pattern对象,注意jiejie前面的r的意思是“原生字符串”pattern = re.compile(r'jiejie')# 使用re.match匹配文本,获得匹配结果,无法匹配时将返回Noneresult1 = re.match(pattern,'jiejie')result2 = re.match(pattern,'jiejiej!')result3 = re.match(pattern,'jieje!')result4 = re.match(pattern,'jiejie fcq!')#如果1匹配成功if result1: # 使用Match获得分组信息 print result1.group()else: print '1匹配失败!'#如果2匹配成功if result2: # 使用Match获得分组信息 print result2.group()else: print '2匹配失败!'#如果3匹配成功if result3: # 使用Match获得分组信息 print result3.group()else: print '3匹配失败!'#如果4匹配成功if result4: # 使用Match获得分组信息 print result4.group()else: print '4匹配失败!'按F5输出结果:
>>> jiejiejiejie3匹配失败!jiejie
。。。(后面继续)
参考:
http://www.runoob.com/python3/python3-reg-expressions.html
http://blog.csdn.net/peace1213/article/details/48950593
http://www.jb51.net/article/78724.htm
http://wiki.jikexueyuan.com/project/python-crawler-guide/regular-expressions.html#7907ec6cc04be6c7f8cf8ac272215946
- python学习之(7)正则表达式篇
- Python之学习笔记(正则表达式)
- Python学习之正则表达式
- python学习之 正则表达式
- python学习之正则表达式
- python学习之正则表达式
- 正则表达式之Python篇
- Python 正则表达式之 补充学习笔记
- python学习之(五)正则表达式
- 学习PYTHON 之 松散正则表达式
- python学习之正则表达式笔记
- python之正则表达式的学习
- python学习之正则表达式应用
- python学习之2 正则表达式re
- python学习笔记之正则表达式1
- Python基础学习之re正则表达式
- Python学习之路-正则表达式
- python学习笔记之正则表达式
- 链表定义
- linux下输出文件夹下所有文件夹名称并重定向
- 用自己写的接口文档生成工具生成入参出参文档
- Git常用命令总结
- android开发技巧收集
- python学习之(7)正则表达式篇
- 关于linux下安装eclipse后可能出现空格键变短的情况
- 深度学习资料
- iOS绘图_Quartz 2D基础
- Android硬件编码
- ubuntu下java eclipse 安装
- 查看源码的调用关系
- poweredge r610的raid卡
- ImageNet和CNN可以帮助医学图像的识别吗?


