Recurrent Layers——介绍(递归神经网络原理介绍)
来源:互联网 发布:葛底斯堡演说 知乎 编辑:程序博客网 时间:2024/05/21 17:14
https://zhuanlan.zhihu.com/p/24720659?utm_source=tuicool&utm_medium=referral
链接:https://zhuanlan.zhihu.com/p/24720659
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
大家貌似都叫Recurrent Neural Networks为循环神经网络。
我之前是查维基百科的缘故,所以一直叫它递归网络。
递归神经网络(RNN)是两种人工神经网络的总称。一种是时间递归神经网络(recurrent neural network),另一种是结构递归神经网络(recursive neural network)。
下面我所提到的递归网络全部都是指Recurrent Neural Networks。
递归神经网络的讨论分为三部分
- 介绍:描述递归网络和前馈网络的差别和优劣
- 实现:梯度消失和梯度爆炸问题,及解决问题的LSTM和GRU
- 代码:用tensorflow实际演示一个任务的训练和使用
该文为第一部分:
gitbook首发原文地址:递归神经网络——介绍
文中有很多动态图,请点击观看,看不了的话建议去上面的gitbook地址阅读
递归神经网络——介绍
时序预测问题
代码演示3已经展示了如何用前馈神经网络(feedforward)来做时序信号预测。
一、用前馈神经网络来做时序信号预测有什么问题?
依赖受限:前馈网络是利用窗处理将不同时刻的向量并接成一个更大的向量。以此利用前后发生的事情预测当前所发生的情况。如下图所示:
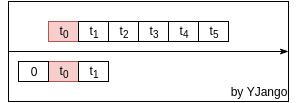
但其所能考虑到的前后依赖受限于将多少个向量(window size)并接在一起。所能考虑的依赖始终是固定长度的。
网络规格:想要更好的预测,需要让网络考虑更多的前后依赖。
例:若仅给“国()”,让玩家猜括号中的字时,所能想到的可能性非常之多。但若给“中国()”时,可能性范围降低。当给“我是中国()”时,猜中的可能性会进一步增加。
那么很自然的做法就是扩大并接向量的数量,但这样做的同时也会使输入向量的维度和神经网络第一层的权重矩阵的大小快速增加。如代码演示3中每个输入向量的维度是39,41帧的窗处理之后,维度变成了1599,并且神经网络第一层的权重矩阵也变成了1599 by n(n为下一层的节点数)。其中很多权重都是冗余的,但却不得不一直存在于每一次的预测之中。
训练所需样本数:前两点可能无伤大雅,而真正使得递归神经网络(recurrent)在时序预测中击败前馈神经网络的关键在于训练网络所需要的数据量。
网络差异之处
几乎所有的神经网络都可以看作为一种特殊制定的前馈神经网络,这里“特殊制定”的作用在于缩减寻找映射函数的搜索空间,也正是因为搜索空间的缩小,才使得网络可以用相对较少的数据量学习到更好的规律。
例:解一元二次方程。我们需要两组配对的
来解该方程。但是如果我们知道
实际上是
,这时就只需要一对
就可以确定
与
的关系。递归神经网络和卷积神经网络等神经网络的变体就具有类似的功效。
二、相比前馈神经网络,递归神经网络究竟有何不同之处?
需要注意的是递归网络并非只有一种结构,这里介绍一种最为常用和有效的递归网络结构。
数学视角
首先让我们用从输入层到隐藏层的空间变换视角来观察,不同的地方在于,这次将时间维度一起考虑在内。
注:这里的圆圈不再代表节点,而是状态,是输入向量和输入经过隐藏层后的向量。
前馈网络:window size为3帧的窗处理后的前馈网络
动态图:左侧是时间维度展开前,右侧是展开后(单位时刻实际工作的只有灰色部分。)。前馈网络的特点使不同时刻的预测完全是独立的。我们只能通过窗处理的方式让其照顾到前后相关性。
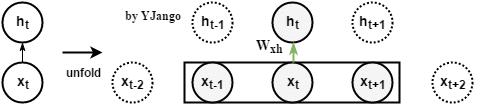
数学式子:
,concat表示将向量并接成一个更大维度的向量。
学习参数:需要从大量的数据中学习
和
。
要学习各个时刻(3个)下所有维度(39维)的关系(39*3个),就需要很多数据。
递归网络:不再有window size的概念,而是time step
动态图:左侧是时间维度展开前,回路方式的表达方式,其中黑方框表示时间延迟。右侧展开后,可以看到当前时刻的
并不仅仅取决于当前时刻的输入
,同时与上一时刻的
也相关。
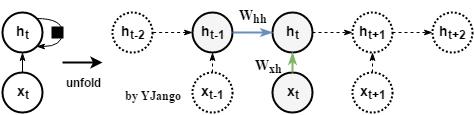
数学式子:
。
但这里多另一份信息:
,而该信息是从上一时刻的隐藏状态
变换后得出的。
注:
学习参数:前馈网络需要3个时刻来帮助学习一次
递归神经网络是在时间结构上存在共享特性的神经网络变体。
时间结构共享是递归网络的核心中的核心。
物理视角
共享特性给网络带来了诸多好处,但也产生了另一个问题:
三、为什么可以共享?
在物理视角中,YJango想给大家展示的第一点就是为什么我们可以用这种共享不同时刻权重矩阵的网络进行时序预测。
下图可以从直觉上帮助大家感受日常生活中很多时序信号是如何产生的。
例1:轨迹的产生,如地球的轨迹有两条线索决定,其中一条是地球自转,另一条是地球围绕太阳的公转。下图是太阳和其他星球。自转相当于
,而公转相当于
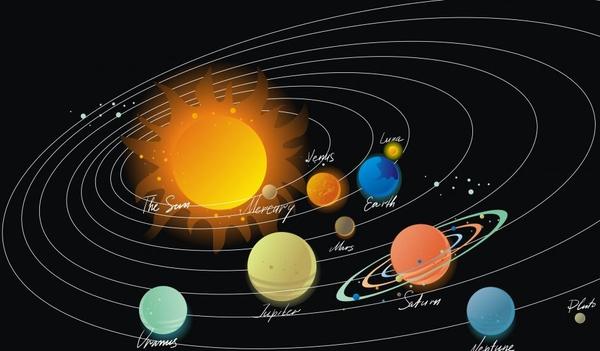
例2:同理万花尺
例3:演奏音乐时,乐器将力转成相应的震动产生声音,而整个演奏拥有一个主旋律贯穿全曲。其中乐器的物理特性就相当于
上述例子中所产生的轨迹、音乐都是我们所能观察到的observations,我们常常会利用这些observation作为依据来做出决策。
下面的例子可能更容易体会共享特性对于数据量的影响。
实例:捏陶瓷:不同角度相当于不同的时刻

若用前馈网络:网络训练过程相当于不用转盘,而是徒手将各个角度捏成想要的形状。不仅工作量大,效果也难以保证。
若用递归网络:网络训练过程相当于在不断旋转的转盘上,以一种手势捏造所有角度。工作量降低,效果也可保证。
递归网络特点
- 时序长短可变:只要知道上一时刻的隐藏状态
。并且由于计算所用到的
顾及时间依赖:若当前时刻是第5帧的时序信号,那计算当前的隐藏状态
就需要当前的输入
和第4帧的隐藏状态
,而计算
,这样不断逆推到初始时刻为止。意味着常规递归网络对过去所有状态都存在着依赖关系。
注:在计算
的值时,若没有特别指定初始隐藏状态,则会将
全部补零,
表达式会变成前馈神经网络:
未来信息依赖:前馈网络是通过并接未来时刻的向量来引入未来信息对当前内容判断的限制,但常规的递归网络只对所有过去状态存在依赖关系。所以递归网络的一个扩展就是双向(bidirectional)递归网络:两个不同方向的递归层叠加。
关系图:正向(forward)递归层是从最初时刻开始,而反向(backward)递归层是从最末时刻开始。
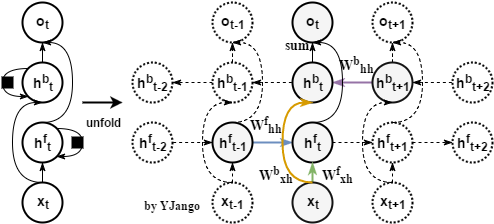
数学式子:
- 正向递归层:
- 反向递归层:
双向递归层:
注:还有并接的处理方式,即
,但反向递归层的作用是引入未来信息对当前预测判断的额外限制。并不是信息维度不够。至少在我所有的实验中,相加(sum)的方式往往优于并接。
注:也有人将正向递归层和反向递归层中的权重
与
共享,
与
共享。我没有做实验比较过。但直觉上
注:隐藏状态
将其投射到输出状态
。一个最基本的递归网络不会出现前馈神经网络那样从输入层直接到输出层的情况,而是至少会有一个隐藏层。
注:双向递归层可以提供更好的识别预测效果,但却不能实时预测,由于反向递归的计算需要从最末时刻开始,网络不得不等待着完整序列都产生后才可以开始预测。在对于实时识别有要求的线上语音识别,其应用受限。
- 正向递归层:
递归网络输出:递归网络的出现实际上是对前馈网络在时间维度上的扩展。
关系图:常规网络可以将输入和输出以向量对向量(无时间维度)的方式进行关联。而递归层的引入将其扩展到了序列对序列的匹配。从而产生了one to one右侧的一系列关联方式。较为特殊的是最后一个many to many,发生在输入输出的序列长度不确定时,其实质两个递归网络的拼接使用,公共点在紫色的隐藏状态
。
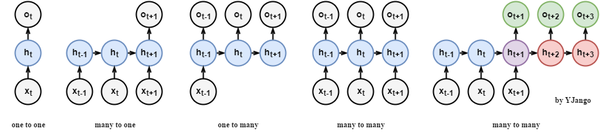
- many to one:常用在情感分析中,将一句话关联到一个情感向量上去。
- many to many:第一个many to many在DNN-HMM语音识别框架中常有用到
- many to many(variable length):第二个many to many常用在机器翻译两个不同语言时。
递归网络数据:递归网络由于引入time step的缘故,使得其训练数据与前馈网络有所不同。
前馈网络:输入和输出:矩阵
输入矩阵形状:(n_samples, dim_input)
输出矩阵形状:(n_samples, dim_output)
注:真正测试/训练的时候,网络的输入和输出就是向量而已。加入n_samples这个维度是为了可以实现一次训练多个样本,求出平均梯度来更新权重,这个叫做Mini-batch gradient descent。
如果n_samples等于1,那么这种更新方式叫做Stochastic Gradient Descent (SGD)。
递归网络:输入和输出:维度至少是3的张量,如果是图片等信息,则张量维度仍会增加。
输入张量形状:(time_steps, n_samples, dim_input)
输出张量形状:(time_steps, n_samples, dim_output)
注:同样是保留了Mini-batch gradient descent的训练方式,但不同之处在于多了time step这个维度。
Recurrent 的任意时刻的输入的本质还是单个向量,只不过是将不同时刻的向量按顺序输入网络。你可能更愿意理解为一串向量 a sequence of vectors,或者是矩阵。
网络对待
请以层的概念对待所有网络。递归神经网络是指拥有递归层的神经网络,其关键在于网络中存在递归层。
每一层的作用是将数据从一个空间变换到另一个空间下。可以视为特征抓取方式,也可以视为分类器。二者没有明显界限并彼此包含。关键在于使用者如何理解。
以层的概念理解网络的好处在于,今后的神经网络往往并不会仅用到一种处理手段。往往是前馈、递归、卷积混合使用。 这时就无法再以递归神经网络来命名该结构。
例:下图中就是在双向递归层的前后分别又加入了两个前馈隐藏层。也可以堆积更多的双向递归层,人们也会在其前面加入“深层”二字,提高逼格。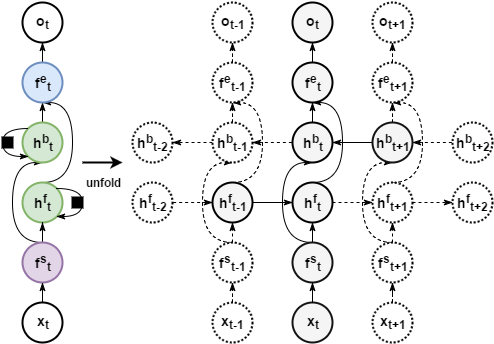
注:层并不是图中所画的圆圈,而是连线。圆圈所表示的是穿过各层前后的状态。
递归网络问题
常规递归网络从理论上应该可以顾及所有过去时刻的依赖,然而实际却无法按人们所想象工作。原因在于梯度消失(vanishinggradient)和梯度爆炸(exploding gradient)问题。下一节就是介绍Long Short Term Memory(LSTM)和Gated Recurrent Unit(GRU):递归网络的特别实现算法。
- Recurrent Layers——介绍(递归神经网络原理介绍)
- 循环神经网络(Recurrent)——介绍
- 循环神经网络(Recurrent Neutral Network)RNN介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
- 循环神经网络(RNN,Recurrent Neural Networks)介绍
- android studio 修改idea.properties
- Spring框架注解的学习
- java对日期时间的处理
- Webpack
- [人工智能]深入浅出机器学习
- Recurrent Layers——介绍(递归神经网络原理介绍)
- 告警日志、user_demp_Dest、core_dump_dest
- Java中的Random()函数
- MySQL大表优化方案
- JavaScript高级程序设计13--错误处理与调试
- 2017网易面试(java)
- 程序猿的年终总结 各种版本辣眼睛
- 机器学习-Introduction
- maven 打包时mapper.xml打不进去问题


