设计模式之16 - 迭代器模式Itertor
来源:互联网 发布:jdk 7u51 windows x32 编辑:程序博客网 时间:2024/05/16 11:58
1. 迭代器模式(Iterator Pattern)的定义
(1)定义:提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。
①迭代器迭代的是具体的聚合对象(如数组和链表等),它围绕的是“访问”做文章。
②可用不同的遍历策略来遍历聚合,比如是否需要过滤
③为不同聚合结构提供统一的迭代接口,也就是说通过一个迭代接口可以访问不同的聚合结构,这叫做多态迭代。标准的迭代模式实现基本上都是支持多态迭代的。如用同一个迭代接口来实现对数组和链表的遍历。
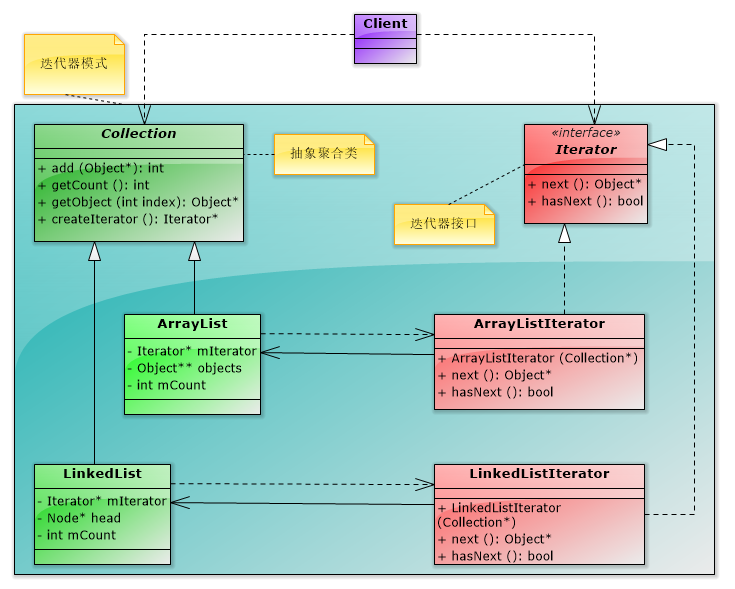
(2)迭代器模式的结构和说明

①Iterator:迭代器接口。定义访问和遍历元素的接口。
②ConcreteInterator:具体的迭代器实现对象,会持有被迭代的具体的聚合对象的引用,并对聚合对象的遍历及跟踪遍历时的当前位置。
③Aggregate:聚合对象。提供创建相应迭代器对象的函数(如createIterator())。
④ConcreteAggregate:具体聚合对象。实现创建相应迭代器对象。
【编程实验】以统一的方式对数组和链表进行遍历(多态迭代)
 View Code
View Code2. 思考迭代器模式
(1)迭代器的本质:控制访问聚合对象中的元素。迭代器能实现“无须暴露聚合对象的内部实现,就能够访问到聚合对象的各个元素的功能”,做到“透明”的访问聚合对象中的元素。注意迭代器能够即“透明”访问,又可以“控制访问”聚合对象,认识这点,对于识别和变形使用迭代器模式很有帮助。
(2)迭代器的关键思想:把对聚合对象的遍历访问从聚合对象中分离出来,放入单独的迭代器中,这样聚合对象会变得简单,而且迭代器和聚合对象可以独立地变化和发展,会大大加强系统的灵活性。
(3)迭代器的动机:
在软件构建过程中,集合对象内部结构常常变化各异。但对于这些集合对象,我们希望在不暴露其内部结构的同时,可以让外部客户代码透明地访问其中包含的元素;同时这种“透明遍历”也为“同一种算法在多种集合对象上进行操作”提供了可能。将遍历机制抽象为“迭代器对象”为“应对变化中的集合对象”提供了一种优雅的方法
(4)内部迭代器与外部迭代器
①内部迭代器:指的是由迭代器自己来控制下一个元素的步骤,即当客户端利用迭代器读取当前元素后,迭代器的当前元素自动移到一下个元素,而客户端无法干预。
②外部迭代器:则客户端控制迭代下一个元素的步骤,即客户端必须显示的next来迭代下一个元素。从总体来说外部迭代器比内部迭代器要灵活一些。这也是常见的实现方式。
【编程实验】简单模仿STL库容器类的遍历方式(变式迭代器)


//行为模式——迭代器模式//场景:简单仿STL容器类的Iterator//说明:该模式主要用于将列表的访问和遍历分离出来并放进一个迭代器中,//本例是模仿STL库的容量遍历方式#include <iostream>#include <string>using namespace std;class ArrayList{private: int cnt; int arr[100];public: typedef int* Iterator; //内部类(型) ArrayList(){cnt = 0;} //这里可以看出来Iterator声明为一个Int*类型的指针 Iterator begin() { return &arr[0]; } Iterator end() { return &arr[cnt]; } void insert(int v) { if(cnt>=100) { cout << "列表容量己满,不可再插入" << endl; return; } arr[cnt++] = v; }};int main(){ ArrayList al; for(int i = 0; i< 110; i++) { al.insert(i); } ArrayList::Iterator iter = al.begin(); while( iter != al.end()) { cout << *iter << endl; ++iter; } return 0;}
3. 迭代器模式高级应用
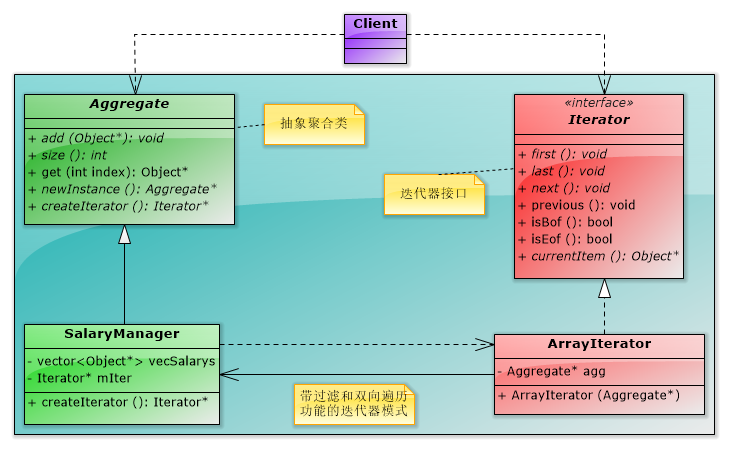
(1)带迭代策略的迭代器
①由于迭代器模式把聚合对象和访问聚合的机制实现了分离,因此可以在迭代器上实现不同的迭代策略,如实现过滤功能的迭代器
②在实现过滤功能的迭代器中,有两种常见的过滤情况,一是对数据整条过滤,如只能查看自己部门的数据;另一种情况是对数据进行部分过滤,如某些人不能查看工资数据。
③带迭代策略的迭代器实现的一个基本思路就是把聚合对象的聚合数据获取到并存储在迭代器中,这样迭代器就可以按照不同的策略来迭代数据了。
(2)双向迭代器:可以向前和向后遍历数据的迭代器
【编程实验】带过滤和双向遍历功能的工资查看系统
//行为模式——迭代器模式//场景:工资表数据遍历(带过滤和双向遍历功能)#include <iostream>#include <string>#include <vector>using namespace std;//***************************辅助类*************************//前向声明class Iterator;class SalaryModel;typedef SalaryModel Object;//工资描述模型对象class SalaryModel{private: string userName; //职工姓名 double salary; //工资数额public: string& getUserName(){return userName;} void setUserName(string name) { this->userName = name; } double getSalary(){return salary;} void setSalary(double salary) { this->salary = salary; } void toString() { cout << "userName = " << userName <<", Salary = " << salary << endl; }};//**********************迭代器接口***************************//迭代器接口,定义访问和遍历元素的操作(双向遍历)class Iterator{public: //移动到聚合对象的第一个位置 virtual void first() = 0; //移动到最后一个位置 virtual void last() = 0; //移动到聚合对象的下一个位置 virtual void next() = 0; //移动到聚合对象的上一个位置 virtual void previous() = 0; //判断是否到了尾部位置 virtual bool isEof() = 0; //判断是否到了头部位置 virtual bool isBof() = 0; //获取当前元素 virtual Object* currentItem() = 0; virtual ~Iterator(){};};//************************************抽象聚合类**************************//聚合对象的接口class Aggregate{public: //创建相应迭代器对象的接口 virtual Iterator* createIterator() = 0; //获取数量大小 virtual int size() = 0; //获取指定位置的元素 virtual Object* get(int index) = 0; //加入元素 virtual void add(Object* o) = 0; virtual Aggregate* newInstance() {return NULL;} virtual ~Aggregate(){}};//***********************具体迭代器*****************************//具体的迭代器对象//用来实现访问数组的迭代接口,加入了迭代策略//其主要思路就是在ArrayInterator中保存一份过滤后的Aggregate聚合对象数据。class ArrayIterator : public Iterator{private: Aggregate* agg; //记录当前迭代到的位置索引 int index;public: ArrayIterator(Aggregate* agg) { index = 0; //在这里先对聚合对象的数据进行过滤,比如必须在3000以上 this ->agg = agg->newInstance();//原型模式,根据agg的实际类型创建对象 //下面用一般遍历方法,而不agg的迭代器,否则那样会造成死循环。 for(int i = 0;i < agg->size(); i++) { Object* obj = agg->get(i); if (obj->getSalary()> 3000) { this->agg->add(obj); } } } void first()//移动到聚合对象的第1个位置 { index = 0; } void last()//移动到聚合对象的最后一个位置 { index = agg->size() -1; } //移动到聚合对象的下一个位置 void next() { if(index < agg->size()) ++index; } //移动到前一个位置 void previous() { if(index>=0) { --index; } } //判断是否到了尾部位置 bool isEof() { return (index >= agg->size()); } //判断是否到了头部位置 bool isBof() { return (index < 0); } //获取当前元素 Object* currentItem() { //在这里对返回的数据进行过滤,比如不让查看具体的工资数据 Object* obj = agg->get(index); obj->setSalary(0); return obj; } ~ArrayIterator() { delete agg; }};//用数组模拟具体的聚合对象class SalaryManager : public Aggregate{private: //聚合对象 vector<Object*> vecSalarys; //数组 //提供创建具体迭代器的接口 Iterator* mIter;public: SalaryManager() { mIter = NULL; } Iterator* createIterator() { if (mIter == NULL) { mIter = new ArrayIterator(this); } return mIter; } //获取数量大小 int size() { return vecSalarys.size(); } //获取指定位置的元素 Object* get(int index) { return vecSalarys[index]; } //加入元素 void add(Object* o) { vecSalarys.push_back(o); } Aggregate* newInstance() { Aggregate* ret = new SalaryManager(); return ret; } ~SalaryManager() { delete mIter; vecSalarys.clear(); }};int main(){ Aggregate* agg = new SalaryManager(); //为了测试,输入些数据进去 SalaryModel* sm = new SalaryModel(); sm->setSalary(3800); sm->setUserName("张三"); agg->add(sm); sm = new SalaryModel(); sm->setSalary(5800); sm->setUserName("李四"); agg->add(sm); sm = new SalaryModel(); sm->setSalary(2200); sm->setUserName("王五"); agg->add(sm); sm = new SalaryModel(); sm->setSalary(3500); sm->setUserName("赵六"); agg->add(sm); Iterator* it = agg->createIterator(); //正向遍历 it->first(); while(!it->isEof()) { it->currentItem()->toString(); it->next(); } //返向遍历、 it->last(); while(!it->isBof()) { it->currentItem()->toString(); it->previous(); } return 0;}
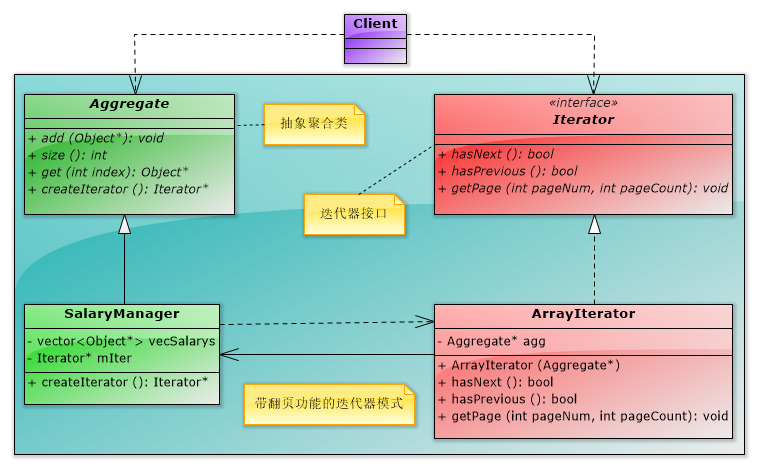
(3)翻页迭代器
①在数据库访问中,如果每页显示10条记录,通常用户很少翻到10页以后,那么在第一次访问时,可以从从数据库中获取前10页的数据,即100条记录放在内存里。
②当用户在前10页进行翻页操作时,就可以不再访问数据库而是直接从内存中获取数据,速度就快了。
③当想获取第11页的数据时,才会再次访问数据库。而翻页迭代的意思是一次迭代要求取出一页的数据,而不是一条数据。所以其实现主要把原来一次迭代一条数据的接口,都修改成一次迭代一页的数据就可以了。
【编程实验】带随机翻页功能的工资查看系统
//行为模式——迭代器模式//场景:工资表数据遍历(带随机翻页功能)//说明:翻页即每页读取若干条记录,// 随机指可以指定页数和每页的记录数的访问方式,// 而不是按顺序访问页面.#include <iostream>#include <string>#include <vector>using namespace std;//***************************辅助类*************************//前向声明class Iterator;class SalaryModel;typedef SalaryModel Object;//工资描述模型对象class SalaryModel{private: string userName; //职工姓名 double salary; //工资数额public: string& getUserName(){return userName;} void setUserName(string name) { this->userName = name; } double getSalary(){return salary;} void setSalary(double salary) { this->salary = salary; } void toString() { cout << "userName = " << userName <<", Salary = " << salary << endl; }};//**********************迭代器接口***************************//迭代器接口,定义访问和遍历元素的操作(双向遍历)class Iterator{public: //判断是否还有下一个元素,无所谓是否够一页数据 //因为最后哪怕只有一条数据,也是要算一页。 virtual bool hasNext() = 0; //判断是否还有上一个元素,无所谓是否够一页数据 //因为最后哪怕只有一条数据,也是要算一页。 virtual bool hasPrevious() = 0; //获取指定页号和每页显示的数量 virtual void getPage(int pageNum, int pageCount) = 0; virtual ~Iterator(){};};//************************************抽象聚合类**************************//聚合对象的接口class Aggregate{public: //创建相应迭代器对象的接口 virtual Iterator* createIterator() = 0; //获取数量大小 virtual int size() = 0; //获取指定位置的元素 virtual Object* get(int index) = 0; //加入元素 virtual void add(Object* o) = 0; virtual Aggregate* newInstance() {return NULL;} virtual ~Aggregate(){}};//***********************具体迭代器*****************************//具体的迭代器对象//用来实现访问数组的迭代接口,加入了迭代策略//其主要思路就是在ArrayInterator中保存一份过滤后的Aggregate聚合对象数据。class ArrayIterator : public Iterator{private: Aggregate* agg; //记录当前迭代到的位置索引 int index;public: ArrayIterator(Aggregate* agg) { index = 0; this ->agg = agg; } //判断是否还有下一个元素,无所谓是否够一页数据 //因为最后哪怕只有一条数据,也是要算一页。 bool hasNext() { return (index <agg->size()); } //判断是否还有上一个元素,无所谓是否够一页数据 //因为最后哪怕只有一条数据,也是要算一页。 bool hasPrevious() { return (index >0); } //获取指定页号和每页显示的数量 void getPage(int pageNum, int pageCount) { //这里可读取到的数据通过数组或链表返回给客户 //但为了简便,我们在这里 //计算需要获取的数据的开始条数和结束条数 int start = (pageNum - 1)* pageCount; int end = start + pageCount - 1; //控制start的边界,最小是0 if(start < 0) start = 0; //控制end的边界 if(end > agg->size()-1) end = agg->size() -1; //每次取值都是从头开始循环 index = 0; while(hasNext() && index <= end) { if(index>=start) { agg->get(index)->toString(); } index++; } }};//用数组模拟具体的聚合对象class SalaryManager : public Aggregate{private: //聚合对象 vector<Object*> vecSalarys; //数组 //提供创建具体迭代器的接口 Iterator* mIter;public: SalaryManager() { mIter = NULL; } Iterator* createIterator() { if (mIter == NULL) { mIter = new ArrayIterator(this); } return mIter; } //获取数量大小 int size() { return vecSalarys.size(); } //获取指定位置的元素 Object* get(int index) { return vecSalarys[index]; } //加入元素 void add(Object* o) { vecSalarys.push_back(o); } Aggregate* newInstance() { Aggregate* ret = new SalaryManager(); return ret; } ~SalaryManager() { delete mIter; vecSalarys.clear(); }};int main(){ Aggregate* agg = new SalaryManager(); //为了测试,输入些数据进去 SalaryModel* sm = new SalaryModel(); sm->setSalary(3800); sm->setUserName("张三"); agg->add(sm); sm = new SalaryModel(); sm->setSalary(5800); sm->setUserName("李四"); agg->add(sm); sm = new SalaryModel(); sm->setSalary(2200); sm->setUserName("王五"); agg->add(sm); sm = new SalaryModel(); sm->setSalary(3500); sm->setUserName("赵六"); agg->add(sm); sm = new SalaryModel(); sm->setSalary(2900); sm->setUserName("钱七"); agg->add(sm); //得到翻页迭代器 Iterator* it = agg->createIterator(); //获取第一页,每页显示2条 cout <<"第1页数据:" <<endl; it->getPage(1, 2); //获取第2页,每页显示2条 cout <<"第2页数据:" <<endl; it->getPage(2, 2); //再获取第1页,每页显示2条 cout <<"第1页数据:" <<endl; it->getPage(1, 2); //再获取第3页,每页显示2条 cout <<"第3页数据:" <<endl; it->getPage(3, 2); return 0;}
4. 迭代器的优缺点
(1)优点
①更好的封装性,可对一个聚合对象的访问,而无须暴露聚合对象的内部实现。
②可以不同的遍历方式来遍历一个聚合对象(如正向和反向遍历)
③将聚合对象的内容和具体的迭代算法分离开,这样就可以通过使用不同的迭代器实例、不同的遍历方式来遍历一个聚合对象。
④简化客户端调用:迭代器为遍历不同的聚合对象提供了一个统一的接口,使用客户端遍历聚合对象的内容变得更加简单。
⑤同一个聚合上可以有多个遍历。每个迭代器保持它自己的遍历状态(如索引位置),因此可以对同一个聚合对象同时进行多个遍历。只要为其设置设计不同的迭代器。
(2)缺点:
①由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。对于比较简单的遍历(像数组或者有序列表),使用迭代器方式遍历较为繁琐。
②迭代器模式在遍历的同时更改迭代器所在的集合结构会导致出现异常。所以使用foreach语句只能在对集合进行遍历,不能在遍历的同时更改集合中的元素。
5. 应用场景
(1)如果希望提供访问一个聚合对象的内容,但又不想暴露它的内部表示的时候可使用迭代器模式
(2)如果希望有多种遍历方式可以访问聚合对象。
(3)如果希望为遍历不同的聚合对象提供一个统一的接口,可以使用迭代器模式(多态迭代)。
6. 相关模式
(1)迭代器模式和组合模式
组合模式是一种递归的对象结构,在枚举某个组合对象的子对象时,通常会使用迭代器模式。
(2)迭代器模式和工厂方法模式
在聚合对象创建迭代器的时候,通常会采用工厂方法模式来实例化相应的迭代器对象。
http://www.cnblogs.com/5iedu/p/5596939.html
- 设计模式之16 - 迭代器模式Itertor
- C++之itertor迭代器
- 设计模式之迭代器模式
- 设计模式之 迭代器模式
- 设计模式之迭代器模式
- 设计模式之迭代器模式
- 设计模式之--迭代器模式
- 设计模式之迭代器模式
- 设计模式之迭代器模式
- 设计模式之迭代器模式
- 设计模式之-迭代器模式
- 设计模式之迭代器模式
- 设计模式之迭代器模式
- 设计模式之迭代器模式
- 设计模式之迭代器模式
- 设计模式之迭代器模式
- 设计模式 之 迭代器模式
- 设计模式 之 迭代器模式
- spring切面:注解:最终增强
- matlab中cell数组的全面介绍
- Java虚拟机学习(5):内存调优
- MySQL入门之调用思路
- 【LeetCode】 046. Permutations
- 设计模式之16 - 迭代器模式Itertor
- MVP+RxJava+Dagger打造的Android Album
- 5.模拟短信发送
- 前端seo
- JAVA 服务器 java home 配置的问题
- spring切面:schema:前后异常增强
- Sublime Text总在新窗口打开一个文件夹
- 冰封的CSDN博客
- centos 搭建ftp服务器


