笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting、模型融合
来源:互联网 发布:剑三公开的女神脸数据 编辑:程序博客网 时间:2024/05/16 18:46

基本内容与分类见上述思维导图。
.
.
一、模型融合方法 . 概述
本文参考:模型融合的【机器学习】模型融合方法概述
概况有五个部分:Voting、Averaging、Bagging 、Boosting、 Stacking(在多个基础模型的预测上训练一个机器学习模型)
1、Voting
有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。
.
2、Averaging
对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。
权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6
这两种方法看似简单,其实后面的高级算法也可以说是基于此而产生的,Bagging或者Boosting都是一种把许多弱分类器这样融合成强分类器的思想。
以下有三类选择权重办法:
使用算法返回最佳权重;2.使用交叉验证选择权重;3.给更精确的模型赋予高权重
在分类和回归中都可以使用平均集成。在分类中,您可以对预测概率进行平均,而在回归中,您可以直接平均不同模型的预测。
.
3、Bagging
应用场景:对不稳定的分类器做Bagging是一个好主意。在机器学习中,如果训练数据的一个小变化导致学习中的分类器的大变化,则该算法(或学习算法)被认为是不稳定的。
Bagging就是采用有放回的方式进行抽样,用抽样的样本建立子模型,对子模型进行训练,这个过程重复多次,最后进行融合。大概分为这样两步:
- 重复K次
有放回地重复抽样建模
训练子模型
- 模型融合
分类问题:voting
回归问题:average
Bagging算法不用我们自己实现,随机森林就是基于Bagging算法的一个典型例子,采用的基分类器是决策树。R和python都集成好了,直接调用。
优势:
在bagging中,基模型不依赖于彼此,因此可以平行/并行。
bagging适用于高方差低偏差模型,或者你可以说是复杂模型。
如何增强:
- 1.最大样本数
- 2.最大特征
- 3.样品引导
- 4.特征引导
.
4、Boosting
Bagging算法可以并行处理,而Boosting的思想是一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。 
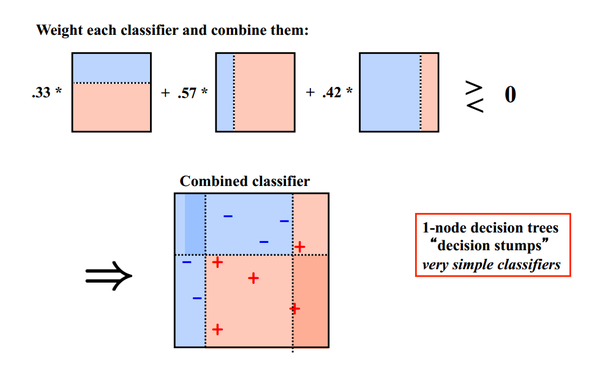
同样地,基于Boosting思想的有AdaBoost、GBDT等,在R和python也都是集成好了直接调用。
在bagging集成中,各个模型的预测不会彼此依赖。在boosting中,你总是试图添加新模型以纠正先前模型的弱点。因此它是顺序进行,而不是平行。
.
5、 Stacking
优点:
- 更强大的模型
- 更好的预测
Stacking方法其实弄懂之后应该是比Boosting要简单的,毕竟小几十行代码可以写出一个Stacking算法。我先从一种“错误”但是容易懂的Stacking方法讲起。
基模型的预测标签级联到下一个分类器:
分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2.

过拟合是非常非常严重的,因此现在的问题变成了如何在解决过拟合的前提下得到P1、P2、P3,这就变成了熟悉的节奏——K折交叉验证。
python可以简单实现stacking,但是R可以直接通过h2o,caretEnsemble来进行模型融合。 
.
二、机器学习元算法
本杂记摘录自文章《开发 | 为什么说集成学习模型是金融风控新的杀手锏?》
随机森林:决策树+bagging=随机森林
梯度提升树:决策树Boosting=GBDT

.
1、随机森林
博客:
R语言︱决策树族——随机森林算法
随机森林的原理是基于原始样本随机抽样获取子集,在此之上训练基于决策树的基学习器,然后对基学习器的结果求平均值,最终得到预测值。
随机抽样的方法常用的有放回抽样的booststrap,也有不放回的抽样。RF的基学习器主要为CART树(Classification And Regression Tree) 
CART会把输入的属性分配到各个叶子节点,而每个叶子节点上面都会对应一个实数分数。有人可能会问它和决策树(DT)的关系,其实我们可以简单地把它理解为决策树的一个扩展。从简单的类标到分数之后,我们可以做很多事情,如概率预测,排序。
.
.
2、GBDT(Gradient Boosting Decision Tree)
.
参考博客:笔记︱决策树族——梯度提升树(GBDT)
首先使用训练集和样本真值(即标准答案)训练一棵树,使用这棵树预测训练集,得到每个样本的预测值,由于预测值与真值存在偏差,所以二者相减可以得到“残差”。
接下来训练第二棵树,此时使用残差代替真值作为标准答案,两棵树训练完成后,可以再次得到每个样本的残差。然后进一步训练第三棵树,以此类推,树的总棵数可以人为指定,也可以监控某些指标如验证集上的误差来停止训练。

比如我们使用两棵树来预测一个人是否喜欢电脑游戏,如上图所示,在预测新样本时,每棵树都会有一个输出值,将这些输出值相加,就可得到样本最终的预测值,故小男孩和老人的预测值分别为两棵树预测值的加和。
.
.
3、XGBoost
参考博客:R语言︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
xgboost的全称是eXtreme Gradient Boosting。正如其名,它是Gradient Boosting Machine的一个c++实现,作者为正在华盛顿大学研究机器学习的大牛陈天奇。他在研究中深感自己受制于现有库的计算速度和精度,因此在一年前开始着手搭建xgboost项目,并在去年夏天逐渐成型。xgboost最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进提高了精度。它的处女秀是Kaggle的希格斯子信号识别竞赛,因为出众的效率与较高的预测准确度在比赛论坛中引起了参赛选手的广泛关注,在1700多支队伍的激烈竞争中占有一席之地。随着它在Kaggle社区知名度的提高,最近也有队伍借助xgboost在比赛中夺得第一。
为了方便大家使用,陈天奇将xgboost封装成了Python库。我有幸和他合作,制作了xgboost工具的R语言接口,并将其提交到了CRAN上。也有用户将其封装成了julia库。python和R接口的功能一直在不断更新,大家可以通过下文了解大致的功能,然后选择自己最熟悉的语言进行学习。
.
.
.
三、风控场景的一些经验
本杂记摘录自文章《开发 | 为什么说集成学习模型是金融风控新的杀手锏?》
现金贷场景为例,给大家看一下直观的例子:比如我们针对互联网行为、APP、运营商等得到不同Feature Domain诸如信贷历史、消费能力、社会信用等子模型。我们再将其通过XGboost、LightGBM等最先进的集成学习模型框架进行输出,就可以在反欺诈、违约概率预测、风险定价等风控业务上都可以得到广泛的应用和提升。 
事实上,这不仅解决了机构不同维度/领域数据使用的难题,因为集成学习框架可以支持不同类型模型算法作为子模型,同时也帮助金融客户实现了更高效准确的针对稀疏、高维、非线性数据的建模过程,大大简化繁琐的特征工程,使得我们的模型具有更强的容错和抗扰动能力。
值得一提的是,集成学习模型框架也更易于实现领域知识迁移,单独领域的子模型可以快速迁移应用到新业务领域,帮助我们金融机构实现新金融业务的快速成型和持续迭代优化。大型成熟金融场景中的实践也证明,集成学习模型除了在稳定性和泛化能力上相对传统模型有极大增强,在最终的效果上也显现出了超出想象的作用,相对成熟的逻辑回归模型最大ks值累积提升已经可以达到约70%及以上。

.
延伸一:集成学习一些经验
1、集成学习也适用于非监督式学习方法:https://en.wikipedia.org/wiki/Consensus_clustering
2、分类器越多样,越有效、模型之间差异要大
集成是一门将多种学习者(个体模型)组合在一起以提高模型的稳定性和预测能力的学问。因此,创建多样化模型的集成是得到更好的结果的非常重要的一个因素。
集成建模成员之间较低的相关性可以提高模型的误差校正能力。所有在集成建模时,优选使用具有低相关性的模型。
3、弱模型也有好处:不会过拟合
能力较弱的学习者(模型)对于问题的某一特定部分都比较确定。因此,低方差和高偏差的能力较弱的学习者往往不会过度拟合。
且弱模型能力较弱的学习者(模型)的集成也可以产生一个好的模型。
4、超多模型时候,如何进行选择
- A.逐步向前选择
- B.逐步向后消除
您可以应用这两种算法。在逐步向前选择中,您将从预测开始一次添加一个模型的预测,如果这样提高了整体的精度。在逐步向后消除中,你将从全部特征开始并且一个一个的移除模型预测,如果在移除模型的预测后提高了精度。
逐步向前:
- 从空集成开始
- 向集成中一个一个的添加模型预测(或者取平均值),这样提高了验证集中的指标
- 从具有验证集合的最大性能的嵌套集合中返回集成
5、dropout也是一种好办法,较多在神经网络
因为在Dropout中,权重是共享的,并且子网络的集成是一起训练的。
子网络通过“丢弃”神经元之间的某些连接而一起训练。
模型能力随随机失活率(dropout rate)的增加而减少。
延伸二:美团机器学习模型实践
干货 | 模型优化不得不思考的几个问题
模型这件事儿,许多时候追求的不仅仅是准确率,通常还有业务这一层更大的约束。如果你在做一些需要强业务可解释的模型,比如定价和反作弊,那实在没必要上一个黑箱模型来为难业务。这时候,统计学习模型就很有用,这种情况下,比拼性能的话,我觉得下面这个不等式通常成立:glmnet > LASSO >= Ridge > LR/Logistic. 相比最基本的LR/Logistic,ridge通过正则化约束缓解了LR在过拟合方面的问题,lasso更是通过L1约束做类似变量选择的工作。
不过两个算法的痛点是很难决定最优的约束强度,glmnet是Stanford给出的一套非常高效的解决方案。所以目前,我认为线性结构的模型,glmnet 的痛点是最少的,在R、Python、Spark上面都开源了。
如果我们开发复杂模型,通常成立第二个不等式 RF <= GBDT <= xgboost. 拿数据说话,29个kaggle公开的winner solution里面,17个使用了类似gbdt这样的boosting框架,其次是DNN,RF的做法在kaggle里面非常少见。
RF和GBDT的雏形,CART是两位作者在84年合作推出的。但是在90年代在发展模型集成思想the ensemble的时候,两位作者代表着两个至今也很主流的派系:stacking/ bagging & boosting.
一种是把相互独立的cart (randomized variables, bootstrapsamples)水平铺开,一种是深耕的boosting,在拟合完整体后更有在局部长尾精细刻画的能力。同时,gbdt模型相比rf更加简单,内存占用小,这都是业界喜欢的性质。xgboost在模型的轻量化和快速训练上又做了进一步的工作,也是目前我们比较喜欢尝试的模型。
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting、模型融合
- Hinton Neural Network课程笔记10a:融合模型Ensemble, Boosting, Bagging
- 集成学习(ensemble learning):bagging、boosting、random forest总结
- 集成学习(Ensemble Learning)-bagging-boosting-stacking
- 【机器学习】决策树及Bagging, Random Forest和Boosting模型融合
- 模型融合:bagging、Boosting、Blending、Stacking
- 用R建立集成学习模型(boosting、bagging、stacking)
- [集成学习] bagging和boosting
- Ensemble Learning-模型融合-Python实现
- 树模型系列之二:集成算法bagging和boosting的区别
- Ensemble learning:Bagging,Random Forest,Boosting
- 模型融合技术的两种方法:Bagging Boosting
- ensemble learning(集成学习)笔记
- 集成学习(Ensemble learning)算法之bagging
- 集成学习boosting、bagging
- 集成学习之Bagging与Boosting
- 集成学习——Boosting和Bagging
- 集成学习——Boosting和Bagging
- 服务发现的可行方案以及实践案例
- bat脚本深入学习---001
- 顺序图(Sequence Diagram)
- 监听应用卸载和安装
- SSM框架——详细整合教程(Spring+SpringMVC+MyBatis) (转载)
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting、模型融合
- iOS_一些手机型号判断的实用宏
- android support_v4遇到的问题
- QPixmap值LoadFromData
- nginx日志配置与切割
- 自动化测试的利弊
- java之static的妙用
- CRLF和LF
- addEventListener和on的区别


