特征的选择_03:ChiSqSelector卡方选择器
来源:互联网 发布:sql语句改列名 编辑:程序博客网 时间:2024/05/28 15:55
笔记整理时间:2017年1月11日
笔记整理者:王小草
1. 卡方检验
1.1 卡方检验来选择特征的原因
对于建立模型而言并非特征越多越好,因为建模的目标是使用尽量简单的模型去实现尽量好的效果。减少一些价值小贡献小的特征有利于在表现效果不变或降低度很小的前提下,新找到最简单的模型。
那么什么样的特征是价值小的呢?想想我们之所以用机器学习的模型去学习特征,是为了更好地预测被特征影响着的应变量(标签)。那么那些根本不会对应变量产生影响,或者影响很小的特征理应事先去掉。
那么怎么判断特征对应变量的影响程度的大小呢?我们可以使用卡方检验对特征与应变量进行独立性检验,如果独立性高,那么表示两者没太大关系,特征可以舍弃;如果独立性小,两者相关性高,则说明该特征会对应变量产生比较大的影响,应当选择。
1.2 卡方独立性检验的过程
卡方检验适用与类别变量,如果要对连续型变量做检验,可以将连续型变量分成多个区间,变成类别的形式。
如上所述,卡方检验可以判断两个变量之间是否有显著的相关性(也可以说成是否有显著的独立性)我们通过一个小例子来说明如何做卡方独立性检验。
假设现在有两个变量,自变量(特征)是性别,应变量是是否化妆。并且样本粮食200,其中男生100,女生100。他们中化妆与不化妆的数量如下表:
(1)零假设H0:是否化妆与性别无关。
(2)自由度为:(自变量的类别数-1)×(应变量的类别数-1)=(2-1)×(2-1))=1
(3)选择显著性水平为α=0.05
(4)求解男女生在化妆与不化妆两个特征中的期望值
(5)利用卡方统计量计算公式计算统计量
fi是实际的观测频数,npi是期望值。 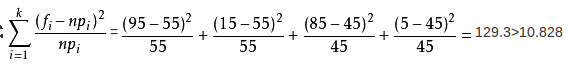
如果卡方值越大表示实际与期望的差距越大,两个变量之间独立性越小,也就是越相关,拒绝原假设H0,反之,如果卡方值越小,便是实际与期望的情况越近似,那么独立性越大,相关性越小,不拒绝原假设H0.
(6)查表对比临界值与统计量,得出结论
自由度为1时的卡方值与可信度对照表: 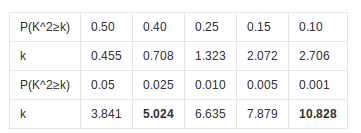
案例中计算得到的卡方值为129.3,远远大于当置信度为0.001的卡方临界值,也就是p值小于我们预先设定的显著性水平0.05,故拒绝原假设,并得出结论“性别与是否化妆的相关性大”。性别可以作为预测是否化妆的一个重要特征。
再来总结一下如何看卡方检验的结果,卡方值越大表示两者月相关,p值越小,表示两者越相关。
2. SparkML代码
Spark中的ChiSqSelector 就是使用了卡方独立性检验来决定哪些特征优秀应该被选择。它提供了3中方法:
(1)numTopFeatures,设置固定的提取特征的数量,程序会根据卡方值的高低返回前n个卡方值最高的特征。(预测能力最强的前n个特征)
(2)percentile,与上类似,设置的是一个比例。
(3)fpr,预先设定一个显著性水平α,所有p值低于α的特征将会被选择出来。
在默认情况下,使用numTopFeatures方法,并且默认选择前50个特征。
假设我们有如下一个dataframe,feature是4个特征,clicked是标签(应变量)
使用ChiSqSelector 的 umTopFeatures = 1, 即在3个特征中选择处最好的1个特征,结果显示第4个特征被选择出来:
来看看具体的代码实现:
/** * Created by cc on 17-1-11. */object FeatureSelection { def main(args: Array[String]) { Logger.getLogger("org.apache.spark").setLevel(Level.WARN) val conf = new SparkConf().setAppName("FeatureSelection").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession .builder() .appName("Feature Extraction") .config("spark.some.config.option", "some-value") .getOrCreate() // 人为创建一个dataframe val data = Seq( (7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0), (8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0), (9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0) ) val df = spark.createDataFrame(data).toDF("id", "feature", "clicked") //学习并建立模型 val selector = new ChiSqSelector() .setNumTopFeatures(1) .setFeaturesCol("feature") .setLabelCol("clicked") .setOutputCol("selectFeatures") val model = selector.fit(df) // 计算 val result = model.transform(df) println(s"ChiSqSelector output with top ${selector.getNumTopFeatures} features selected") result.show(false) spark.close() }}打印结果:
ChiSqSelector output with top 1 features selected+---+------------------+-------+--------------+|id |feature |clicked|selectFeatures|+---+------------------+-------+--------------+|7 |[0.0,0.0,18.0,1.0]|1.0 |[18.0] ||8 |[0.0,1.0,12.0,0.0]|0.0 |[12.0] ||9 |[1.0,0.0,15.0,0.1]|0.0 |[15.0] |+---+------------------+-------+--------------+- 特征的选择_03:ChiSqSelector卡方选择器
- ChiSqSelector-卡方检验选择特征
- SparkML中三种特征选择算法(VectorSlicer/RFormula/ChiSqSelector)
- 特征选择-卡方检测
- 特征选择-卡方检验
- 卡方检验特征选择
- 特征选择之一:卡方选择
- 1 - 基于卡方检验的特征选择
- 特征选择-卡方检验用于特征选择
- 卡方检验用于特征选择
- 卡方检验用于特征选择
- 特征选择算法之卡方检验
- 特征选择之卡方检验
- 卡方检验文本特征选择
- 卡方检验文本特征选择
- 卡方检验文本特征选择
- 卡方检验用于特征选择
- 特征选择算法之卡方检验
- python 匹配文本全角转半角字符
- notes goldendict github wiki
- 百度地图demo,根据ip展示地图显示地区,并在地图上高亮显示
- 188. Best Time to Buy and Sell Stock IV
- 关于ie兼容性的问题
- 特征的选择_03:ChiSqSelector卡方选择器
- ORA-55507: Encountered mining error during Flashback Transaction Backout
- 2017任务
- 节点门面和自定义事件研究
- 转发——谷歌云官方:一小时掌握深度学习和 TensorFlow
- 线程间操作无效: 从不是创建控件“Control Name'”的线程访问它问题的解决方案及原理分析
- WIN7不能被远程桌面问题
- JavaSE_13th_对象转型(casting)
- 一款基于ssd1306驱动的12864屏简介


