特征的转换_04-探索最优特征组合
来源:互联网 发布:中信超市软件 编辑:程序博客网 时间:2024/06/03 08:31
笔记整理时间:2017年1月20日
笔记整理者:王小草
向公司请了5天年假,提前回家过年。
长大了对过年反而没有太大期许,一切都是匆匆的路程,匆匆的相见,匆匆的碰杯与祝福,然后又匆匆回归朝夕规律地平淡。该想念的还是很想念,该失去的还是要失去。
希望家人和亲朋都健康幸福。
1.智能乘积ElementwiseProduct
1.1 概述
在训练模型的时候,经常会遇到这样的情况,特征之间的规模相差悬殊,对模型的训练产生了误导。此时我们需要人为的去平衡特征之间的规模,使他们都在同一个规模等级上,比如将0-1之间的特征,和100-1000之间的特征都分别乘以10,和除以100,使得两个特征的规模都在1-10之间。这个处理其实和归一化很像,只是归一化是使得所有的数据都在0-1之间分布。要注意的是规模化并不是保证所有数据一定落在某个区间内,而只是将不同的特征规模尽量放在一个水平上。
另一种情况,如果在特征中,有些特征特别重要,有些则相对重要度较低,那么需要给重要的特征以较高的权重,也可以使用本方法,将特征都乘上对应的权重从而形成新的特征组。
具体如何处理就要看具体情况的需求了。
1.2 sparkML提供的算法包的使用
ElementwiseProduct的处理逻辑非常简单,没有ml提供的方法,其实我们自己也能写出代码。
我们输入的特征一般都是Vector形式的,Vector中的每个元素表示该样本的各个特征值。创建一个与特征Vector等长的权重Vector–W,新的特征向量就是原来的特征向量与权重向量的乘积,即两个向量中位置相同的元素两两相乘。如下图: 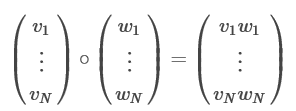
代码
object FeatureTransform01 { def main(args: Array[String]) { Logger.getLogger("org.apache.spark").setLevel(Level.WARN) val conf = new SparkConf().setAppName("FeatureTransform01").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession .builder() .appName("Feature Extraction") .config("spark.some.config.option", "some-value") .getOrCreate() // 创建一组特征向量,a,b是两个样本,分别有3个特征 val dataFrame = spark.createDataFrame(Seq( ("a", Vectors.dense(1.0, 2.0, 3.0)), ("b", Vectors.dense(4.0, 5.0, 6.0)))).toDF("id", "vector") println("特征向量:") dataFrame.show(false) // 创建一组权重,分别是3个特征的权重 val transformingVector = Vectors.dense(0.0, 1.0, 2.0) // 建立转换的模型 val transformer = new ElementwiseProduct() .setScalingVec(transformingVector) .setInputCol("vector") .setOutputCol("transformedVector") // 转换 transformer.transform(dataFrame).show() sc.stop() }}打印结果:
特征向量:+---+-------------+|id |vector |+---+-------------+|a |[1.0,2.0,3.0]||b |[4.0,5.0,6.0]|+---+-------------++---+-------------+-----------------+| id| vector|transformedVector|+---+-------------+-----------------+| a|[1.0,2.0,3.0]| [0.0,2.0,6.0]|| b|[4.0,5.0,6.0]| [0.0,5.0,12.0]|+---+-------------+-----------------+2.Interaction
将两个特征的向量彼此相乘,从而形成一个新的特征向量。
比如vec1,vec2是两个特征向量:
将它们Interaction之后会生成一个新的向量,其实就是他们的乘积:
代码如下:
object FeatureTransform01 { def main(args: Array[String]) { Logger.getLogger("org.apache.spark").setLevel(Level.WARN) val conf = new SparkConf().setAppName("FeatureTransform01").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession .builder() .appName("Feature Extraction") .config("spark.some.config.option", "some-value") .getOrCreate() //创建一个DataFrame val df = spark.createDataFrame(Seq( (1, 1, 2, 3, 8, 4, 5), (2, 4, 3, 8, 7, 9, 8), (3, 6, 1, 9, 2, 3, 6), (4, 10, 8, 6, 9, 4, 5), (5, 9, 2, 7, 10, 7, 3), (6, 1, 1, 4, 2, 8, 4) )).toDF("id1", "id2", "id3", "id4", "id5", "id6", "id7") println("创建一个DataFrame:") df.show(false) //通过VectorAssembler,挑选出多列合并成一列 val assembler1 = new VectorAssembler(). setInputCols(Array("id2", "id3", "id4")). setOutputCol("vec1") val assembled1 = assembler1.transform(df) println("生成vector1:") assembled1.show(false) //再挑选出多列合并成一列,并保留新的两列 val assembler2 = new VectorAssembler(). setInputCols(Array("id5", "id6", "id7")). setOutputCol("vec2") val assembled2 = assembler2.transform(assembled1).select("id1", "vec1", "vec2") println("生成vector1, vector2:") assembled2.show(false) // 两个向量相乘形成新的向量 val interaction = new Interaction() .setInputCols(Array("id1", "vec1", "vec2")) .setOutputCol("interactedCol") val interacted = interaction.transform(assembled2) println("相乘后形成新的特征向量:") interacted.show(truncate = false) sc.stop() }}打印结果:
创建一个DataFrame:+---+---+---+---+---+---+---+|id1|id2|id3|id4|id5|id6|id7|+---+---+---+---+---+---+---+|1 |1 |2 |3 |8 |4 |5 ||2 |4 |3 |8 |7 |9 |8 ||3 |6 |1 |9 |2 |3 |6 ||4 |10 |8 |6 |9 |4 |5 ||5 |9 |2 |7 |10 |7 |3 ||6 |1 |1 |4 |2 |8 |4 |+---+---+---+---+---+---+---+生成vector1:+---+---+---+---+---+---+---+--------------+|id1|id2|id3|id4|id5|id6|id7|vec1 |+---+---+---+---+---+---+---+--------------+|1 |1 |2 |3 |8 |4 |5 |[1.0,2.0,3.0] ||2 |4 |3 |8 |7 |9 |8 |[4.0,3.0,8.0] ||3 |6 |1 |9 |2 |3 |6 |[6.0,1.0,9.0] ||4 |10 |8 |6 |9 |4 |5 |[10.0,8.0,6.0]||5 |9 |2 |7 |10 |7 |3 |[9.0,2.0,7.0] ||6 |1 |1 |4 |2 |8 |4 |[1.0,1.0,4.0] |+---+---+---+---+---+---+---+--------------+生成vector1, vector2:+---+--------------+--------------+|id1|vec1 |vec2 |+---+--------------+--------------+|1 |[1.0,2.0,3.0] |[8.0,4.0,5.0] ||2 |[4.0,3.0,8.0] |[7.0,9.0,8.0] ||3 |[6.0,1.0,9.0] |[2.0,3.0,6.0] ||4 |[10.0,8.0,6.0]|[9.0,4.0,5.0] ||5 |[9.0,2.0,7.0] |[10.0,7.0,3.0]||6 |[1.0,1.0,4.0] |[2.0,8.0,4.0] |+---+--------------+--------------+相乘后形成新的特征向量:+---+--------------+--------------+------------------------------------------------------+|id1|vec1 |vec2 |interactedCol |+---+--------------+--------------+------------------------------------------------------+|1 |[1.0,2.0,3.0] |[8.0,4.0,5.0] |[8.0,4.0,5.0,16.0,8.0,10.0,24.0,12.0,15.0] ||2 |[4.0,3.0,8.0] |[7.0,9.0,8.0] |[56.0,72.0,64.0,42.0,54.0,48.0,112.0,144.0,128.0] ||3 |[6.0,1.0,9.0] |[2.0,3.0,6.0] |[36.0,54.0,108.0,6.0,9.0,18.0,54.0,81.0,162.0] ||4 |[10.0,8.0,6.0]|[9.0,4.0,5.0] |[360.0,160.0,200.0,288.0,128.0,160.0,216.0,96.0,120.0]||5 |[9.0,2.0,7.0] |[10.0,7.0,3.0]|[450.0,315.0,135.0,100.0,70.0,30.0,350.0,245.0,105.0] ||6 |[1.0,1.0,4.0] |[2.0,8.0,4.0] |[12.0,48.0,24.0,12.0,48.0,24.0,48.0,192.0,96.0] |+---+--------------+--------------+------------------------------------------------------+3. 特征的多项式展开PolynomialExpansion
比如现在有两个特征x1,x2.我们首先会拿这两个特征作为全部特征去建立模型,完了发现,哎呀,做出来的模型真差呀。
此时可以尝试将原始的特征进行多项式的扩展。
比如在多远线性回归中,可以根据两个特征建立回归方程:y = a0 + a1x1 + a2x2,这样的模型是线性的,如果样本点的实际分布是非线性的,那么用单纯的线性模型去预测自然是不好的喽。
如果将特征进行3维的转换,多项式的扩展后原来的(x1,x2)就变成了(x1, x2)^3.
展开后就是:(x1, x1^2, x1^3, x2, x2^2, x2^3, x1x2, x1^2x2, x1x2^2)
也就是说将2个特征进行3维多项式的扩展就变成了9个特征了。可以预测非线性的分布。
当维度越高的时候对样本点的拟合可能就越精准。但是!并不是维度越高越好,因为会造成对训练集的过拟合,从而丧失了模型的泛化能力。
使用该功能接口的代码:
def main(args: Array[String]) { Logger.getLogger("org.apache.spark").setLevel(Level.WARN) val conf = new SparkConf().setAppName("FeatureTransform01").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession .builder() .appName("Feature Extraction") .config("spark.some.config.option", "some-value") .getOrCreate() val data = Array( Vectors.dense(2.0, 1.0), Vectors.dense(0.0, 0.0), Vectors.dense(3.0, -1.0) ) val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features") val polyExpansion = new PolynomialExpansion() .setInputCol("features") .setOutputCol("polyFeatures") .setDegree(3) val polyDF = polyExpansion.transform(df) polyDF.show(false) sc.stop() }}打印结果:
+----------+------------------------------------------+|features |polyFeatures |+----------+------------------------------------------+|[2.0,1.0] |[2.0,4.0,8.0,1.0,2.0,4.0,1.0,2.0,1.0] ||[0.0,0.0] |[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0] ||[3.0,-1.0]|[3.0,9.0,27.0,-1.0,-3.0,-9.0,1.0,3.0,-1.0]|+----------+------------------------------------------+2个特征进行3维的多项式转换后变成了9个特征。
以上的方法,尤其是2,3,并非是适合所有的情况,建模的过程也是对特征的探索与测试的过程,当原有的特征并不能很好地拟合样本点时,可以尝试将特征进行相乘或多项式展开的转换,有可能会有更好的效果,但并不是绝对的。
- 特征的转换_04-探索最优特征组合
- 特征的转换_05-标签索引的转换与特征的组合
- 组合索引的特征[摘]
- 特征的转换_01-自然语言相关特征转换
- GBDT构建组合特征
- 特征的转换_06-特征降维PCA
- 特征工程(补充)--特征组合
- 数据探索-特征性分析
- Kaldi中特征文件格式的转换
- Kaldi中特征文件格式的转换
- 数据科学-通过数据探索了解我们的特征
- 特征直方图的特征参数
- 特征直方图的特征参数
- 特征直方图的特征参数
- 特征提取与转换
- 特征提取和转换
- 【机器学习】特征选择与特征转换
- 特征组合相关资源总结
- 手工指定CHANNEL与设置PARALLELISM参数的异同以及FILESPERSET参数的作用
- Linux TC(Traffic Control)框架原理解析
- 算法每日一题之成绩排序:std:stable_sort对结构体struct排序
- java 字符串转化为字符数组的3种方法
- 多线程断点下载
- 特征的转换_04-探索最优特征组合
- iOS标准时间与时间戳相互转换
- mysql中in与exists的性能与效率对比
- View的事件分发机制
- 公共头部和尾部都是html,怎么通过ajax来实现。
- Support V4的拆分
- cannot resolve symbol R
- AES与RSA加密
- js删除最后一个字符


