linux面试题
来源:互联网 发布:淘宝一千零一夜报名 编辑:程序博客网 时间:2024/05/17 01:50
二分法
写法非常简洁
非常经典的strlen函数没用我们的变量递加而用指针计数,非常耐人寻味
有时候函数原本不需要返回值,但为了增加灵活性如支持链式表达,可以附加返回值。
struct 内存对齐知识点
数据存放的大小端知识点
static union { char c[4]; unsigned long l; } endian_test __initdata = { { 'l', '?', '?', 'b' } };
#define ENDIANNESS ((char)endian_test.l)
嵌入式关键字volatile
1). 并行设备的硬件寄存器(如:状态寄存器)
2). 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
3). 多线程应用中被几个任务共享的变量
数组指针(也称行指针)
定义 int (*p)
;
指针数组
定义 int *p
;
在C/C++中,常量指针是这样声明的:
1)const int *p;
2)int const *p;
在C/C++中,指针常量这样声明:
int a;
int *const b = &a; //const放在指针声明操作符的右侧
链表的定义
struct list_head {
struct list_head *next, *prev;
};
typedef struct的用法
指针函数int *f(x,y)
函数指针int (*f) (int x);
看看signal的原型
void (*signal(int signum,void(* handler)(int)))(int);
进程与线程的区别
一、进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。
二、线程是进程的一个实体,是CPU调度和分派的基本单位,他是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),一个线程可以创建和撤销另一个线程;
中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是中断响应过程所用的时间,
即
从发出中断请求到进入中断处理所用的时间。
因为线程调度是在进程中进行,在同一存储区内操作,而进程则在不同存储区操作,所以进程调度数度比线程慢
linux使用的进程间通信方式:
(1)管道(pipe)和有名管道(FIFO)
(2)信号(signal)
(3)消息队列
(4)共享内存
(5)信号量
(6)套接字(socket)
linux 设备驱动中的并发控制:
访问共享资源的代码区域为临界区,临界区需要用某种互斥机制加心保护。
中断屏蔽、原子操作、自旋锁和信号量是linux设备驱动中可采用的互斥途径
linux进程间同步的方法互斥量,读写锁,条件变量
linux内核同步方法原子操作,信号量,自旋锁,完成量,禁止抢占
网络编程注意事项
1、返回值判断
示例:
int num = recv(s,buf, MAX,0);
能够从套接字读多少数据不是api参数能够控制的,只能通过返回来确认。
再有就是有些api调用是次序依赖的,前面的错了,后面的也会错。
所以返回值的判断是必须的。
2、端口复用
一般server异常退出后,端口没有被系统马上释放,如何才能立即使用端口呢?
on = 1;
ret = setsockopt( sock, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on) );
3、数据同步
server read/write(recv/send、recvfrom/sendto)<----->client read/write(recv/send、recvfrom/sendto)
如果收发端的速度不一致,常常会出现发送多次接收一次或是发送一次接收多次的情况。
解决方案:
A、缓存接收,加格式头来解析数据
使用循环队列,一边接收,一边按设定格式解析。
B、应答接收
接收端先请求,发送端发一次数据,接收端接收到格式指定的数据后,再发请求,发送再发送数据,依次类推。
4、发送数据包大小
A、tcp
如果write(/send、sendto)的缓存过大,协议层就会拆包发送,如果存在丢包现象(TCP应答机制会重发保证小包发送出去),实时大数据发送的时候,系统性能就会降低。
B、udp
如果write(/send、sendto)的缓存过大,协议层就会拆包发送,如果存在丢包现象(UDP发包后就不管),实时大数据发送的时候,接收端接收到数据就会不完整。
C、tcp及udp
如果write(/send、sendto)的缓存过小,譬如每次收发一个字节,大量协议内容就传递一个字节,通讯效能也就低。
解决方案:
参考内核拆包的最大容量设置及网络吞吐能力,如果应用层数据过大,就需要应用层拆包发送,保证协议层不用拆包。
5、字节序
两端主机的字节序不一致,如果不作逻辑约定,就会造成接收数据解析错误。
解决方案:
约定字节序
6、缓存字节对齐
如果发送的数据不是字节对齐的,就会出现垃圾数据,浪费流量。
7、主机异常退出
如果server和client正在进行数据交换时候,一端异常退出,就会造成另一端linux系统发出“Pipe Broken”信号,不忽略该信号,就会造成程序被终止。
解决方案:
send/recv、sendto/recvfrom的标志参数设置成MSG_NOSIGNAL,
使用read/write,则先忽略SIGPIPE信号。
写出简单的shell脚本
makefile的编写
如果找底层相关工作会考察驱动的情况
数组循环移位
设计一个算法,把一个含有N个元素的数组循环右移K位,要求时间复杂度为O(N),且只允许使用两个附加变量。
Reverse(char *arr, int b, int e)
{
for(; b < e; b++, e--)
{
char temp = arr[e];
arr[e] = arr;
arr[b] = temp;
}
}
RightShift(char *arr, int N, int k)
{
k %= N;
Reverse(arr, 0, N-k-1);
Reverse(arr, N-k, N-1);
Reverse(arr, 0, N-1);
}
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是consistent hashing。
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。
下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
[b]3.1 环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。

图 1 环形 hash 空间
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。
hash(object1) = key1;
… …
hash(object4) = key4;

图 2 4 个对象的 key 值分布
3.3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;

图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为hash 输入。
3.4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2和 object3 对应到 cache C ; object4 对应到 cache B ;
3.5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时,cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
3.5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。

图 4 Cache B 被移除后的 cache 映射
3.5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。

图 5 添加 cache D 后的映射关系
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。

图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache时的映射关系如图 7 所示。
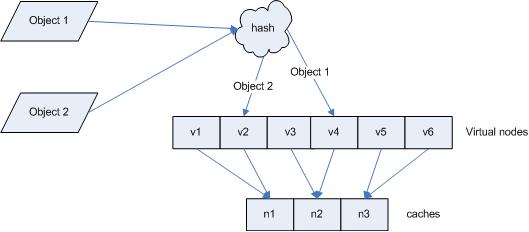
图 7 查询对象所在 cache
第二种方法是每次都将原第一个结点之后的那个结点放在list后面,下图是原始的单链表。

为了反转这个单链表,我们先让头结点的next域指向结点2,再让结点1的next域指向结点3,最后将结点2的next域指向结点1,就完成了第一次交换,顺序就变成了Header-结点2-结点1-结点3-结点4-NULL,然后进行相同的交换将结点3移动到结点2的前面,然后再将结点4移动到结点3的前面就完成了反转,思路有了,就该写代码了:
第三种方法跟第二种方法差不多,第二种方法是将后面的结点向前移动到头结点的后面,第三种方法是将前面的结点移动到原来的最后一个结点的后面,思路跟第二种方法差不多,就不贴代码了
十六进制转换为整数
//将十六进制的字符串转换成整数
int htoi(char s[])
{
int i;
int n = 0;
if (s[0] == '0' && (s[1]=='x' || s[1]=='X'))
{
i = 2;
}
else
{
i = 0;
}
for (; (s[i] >= '0' && s[i] <= '9') || (s[i] >= 'a' && s[i] <= 'z') || (s[i] >='A' && s[i] <= 'Z');++i)
{
if (tolower(s[i]) > '9')
{
n = 16 * n + (10 + tolower(s[i]) - 'a');
}
else
{
n = 16 * n + (tolower(s[i]) - '0');
}
}
return n;
}
一直以为Linux里面,那些do{}while(0)只是为了程序的源代码看起来比较好看而已
今天听说他是有特殊作用的,在线请教,是什么作用?
---------------------------------------------------------------
是为了解决使用宏的时候烦人的分号问题。
---------------------------------------------------------------
楼说的不是很全面,我给个例子吧
#define wait_event(wq,condition) /
do{ if(condition) break; __wait_event(wq,condition); }while(0)
这是一个奇怪的循环,它根本就只会运行一次,为什么不去掉外面的do{..}while结构呢?我曾一度在心里把它叫做“怪圈”。原来这也是非常巧妙的技巧。在工程中可能经常会引起麻烦,而上面的定义能够保证这些麻烦不会出现。下面是解释:
假设有这样一个宏定义
#define macro(condition) if(condition) dosomething();
现在在程序中这样使用这个宏:
if(temp)
macro(i);
else
doanotherthing();
一切看起来很正常,但是仔细想想。这个宏会展开成:
if(temp)
if(condition) dosomething();
else
doanotherthing();
这时的else不是与第一个if语句匹配,而是错误的与第二个if语句进行了匹配,编译通过了,但是运行的结果一定是错误的。
为了避免这个错误,我们使用do{….}while(0) 把它包裹起来,成为一个独立的语法单元,从而不会与上下文发生混淆。同时因为绝大多数的编译器都能够识别do{…}while(0)这种无用的循环并进行优化,所以使用这种方法也不会导致程序的性能降低。
---------------------------------------------------------------
可是直接用{}括起来的话,最后的分号会引起麻烦的
常见内存分配算法及优缺点
常见内存分配算法及优缺点如下:
(1)首次适应算法。使用该算法进行内存分配时,从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链中。
该算法倾向于使用内存中低地址部分的空闲分区,在高地址部分的空闲分区很少被利用,从而保留了高地址部分的大空闲区。显然为以后到达的大作业分配大的内 存空间创造了条件。缺点在于低址部分不断被划分,留下许多难以利用、很小的空闲区,而每次查找又都从低址部分开始,这无疑会增加查找的开销。
(2)循环首次适应算法。该算法是由首次适应算法演变而成的。在为进程分配内存空间时,不再每次从链首开始查找,而是从上次找到的空闲分区开始查找,直至 找到一个能满足要求的空闲分区,并从中划出一块来分给作业。该算法能使空闲中的内存分区分布得更加均匀,但将会缺乏大的空闲分区。
(3)最佳适应算法。该算法总是把既能满足要求,又是最小的空闲分区分配给作业。
为了加速查找,该算法要求将所有的空闲区按其大小排序后,以递增顺序形成一个空白链。这样每次找到的第一个满足要求的空闲区,必然是最优的。孤立地看, 该算法似乎是最优的,但事实上并不一定。因为每次分配后剩余的空间一定是最小的,在存储器中将留下许多难以利用的小空闲区。同时每次分配后必须重新排序, 这也带来了一定的开销。
(4)最差适应算法。最差适应算法中,该算法按大小递减的顺序形成空闲区链,分配时直接从空闲区链的第一个空闲分区中 分配(不能满足需要则不分配)。很显然,如果第一个空闲分区不能满足,那么再没有空闲分区能满足需要。这种分配方法初看起来不太合理,但它也有很强的直观 吸引力:在大空闲区中放入程序后,剩下的空闲区常常也很大,于是还能装下一个较大的新程序。
最坏适应算法与最佳适应算法的排序正好相反,它的队列指针总是指向最大的空闲区,在进行分配时,总是从最大的空闲区开始查寻。
该算法克服了最佳适应算法留下的许多小的碎片的不足,但保留大的空闲区的可能性减小了,而且空闲区回收也和最佳适应算法一样复杂。
题目:将一个4字节整数的二进制表示中的001替换为011
答:

中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是从发出中断请求到进入中断处理所用的时间。
在数组里查找这样的数,它大于等于左侧所有数,小于等于右侧所有数
分析:
最原始的方法是检查每一个数 array[i] ,看是否左边的数都小于等于它,右边的数都大于等于它。这样做的话,要找出所有这样的数,时间复杂度为O(N^2)。
其实可以有更简单的方法,我们使用额外数组,比如rightMin[],来帮我们记录原始数组array[i]右边(包括自己)的最小值。假如原始数组为: array[] = {7, 10, 2, 6, 19, 22, 32}, 那么rightMin[] = {2, 2, 2, 6, 19, 22, 32}. 也就是说,7右边的最小值为2, 2右边的最小值也是2。
有了这样一个额外数组,当我们从头开始遍历原始数组时,我们保存一个当前最大值 max, 如果当前最大值刚好等于rightMin[i], 那么这个最大值一定满足条件。还是刚才的例子。
第一个值是7,最大值也是7,因为7 不等于 2, 继续,
第二个值是10,最大值变成了10,但是10也不等于2,继续,
第三个值是2,最大值是10,但是10也不等于2,继续,
第四个值是6,最大值是10,但是10不等于6,继续,
第五个值是19,最大值变成了19,而且19也等于当前rightMin[4] = 19, 所以,满足条件。
如此继续下去,后面的几个都满足。
代码:
[java] view
plaincopy
/**
* @author beiyeqingteng
* @linkhttp://blog.csdn.net/beiyeqingteng
*/
public static void smallLarge(int[] array) throws Exception{
//the array's size must be larger than 2
if (array == null || array.length < 1) {
throw new Exception("the array is null or the array has no element!");
}
int[] rightMin = new int[array.length];
rightMin[array.length - 1] = array[array.length - 1];
//get the minimum value of the array[] from i to array.length - 1
for (int i = array.length - 2; i >= 0; i--) {
if (array[i] < rightMin[i + 1]) {
rightMin[i] = array[i];
} else {
rightMin[i] = rightMin[i + 1];
}
}
int leftMax = Integer.MIN_VALUE;
for (int i = 0; i < array.length; i++) {
if (leftMax <= array[i]) {
leftMax = array[i];
if (leftMax == rightMin[i]) {
System.out.println(leftMax);
}
}
}
}
(2005-11-06 13:26:04)

转载▼
在UNIX系统中进程由以下三部分组成:①进程控制块PCB;②数据段;③正文段。
UNIX系统为了节省进程控制块所占的内存空间,把每个进程控制块分成两部分。一部分常驻内存,不管进程是否正占有处理器运行,系统经常会对这部分内容进行查询和处理,常驻部分内容包括:进程状态、优先数、过程特征、数据段始址、等待原因和队列指针等,这是进行处理器调度时必须使用的一些主要信息。另一部分非常驻内存,当进程不占有处理器时,系统不会对这部分内容进行查询和处理,因此这部分内容可以存放在磁盘的对换区中,它随用户的程序和数据部分换进或换出内存。
UNIX系统把进程的数据段又划分成三部分:用户栈区(供用户程序使用的信息区);用户数据区(包括用户工作数据和非可重入的程序段);系统数据区(包括系统变量和对换信息)。
正文段是可重入的程序,能被若干进程共享。为了管理可共享的正文段,UNIX设置了一张正文表,每个正文段都占用一个表目,用来指出该正文段在内存和磁盘上的位置、段的大小以及调用该段的进程数等情况。
中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是中断响应过程所用的时间,
即
从发出中断请求到进入中断处理所用的时间。
题目:给定一个8*8的方格子,如下图所示,求A点到B点的最短路径有多少条?用算法实现。

答:从图中可以看出,A点到B点的最短路径为16,即A点横走8小格,纵走8小格才能最快到达B点,这是排列组合的问题,即从最短路径16中选取8个横走的小格子(或者从最短路径16中选取8个纵走的小格子)。所以从A点到B点的最短路径条数,直接可以算出来,即为:

中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是中断响应过程所用的时间,
即从发出中断请求到进入中断处理所用的时间。
linux进程是抢占式的,被抢占的进程仍然处于TASK_RUNNING状态,只是暂时不被CPU执行。
面积对象程序设计语言有三大特点:封装、继承、多态
使用linux epoll模型,水平触发模式(Level-Triggered);当socket可写时,会不停的触发socket可写的事件,如何处理?
第一种最普通的方式:
当需要向socket写数据时,将该socket加入到epoll模型(epoll_ctl);等待可写事件。
接收到socket可写事件后,调用write()或send()发送数据。。。
当数据全部写完后, 将socket描述符移出epoll模型。
这种方式的缺点是: 即使发送很少的数据,也要将socket加入、移出epoll模型。有一定的操作代价。
第二种方式,(是本人的改进方案, 叫做directly-write)
向socket写数据时,不将socket加入到epoll模型;而是直接调用send()发送;
只有当或send()返回错误码EAGAIN(系统缓存满),才将socket加入到epoll模型,等待可写事件后,再发送数据。
全部数据发送完毕,再移出epoll模型。
这种方案的优点: 当用户数据比较少时,不需要epool的事件处理。
在高压力的情况下,性能怎么样呢?
对一次性直接写成功、失败的次数进行统计。如果成功次数远大于失败的次数, 说明性能良好。(如果失败次数远大于成功的次数,则关闭这种直接写的操作,改用第一种方案。同时在日志里记录警告)
在我自己的应用系统中,实验结果数据证明该方案的性能良好。
事实上,网络数据可分为两种到达/发送情况:
一是分散的数据包, 例如每间隔40ms左右,发送/接收3-5个 MTU(或更小,这样就没超过默认的8K系统缓存)。
二是连续的数据包, 例如每间隔1s左右,连续发送/接收 20个 MTU(或更多)。
回来查了资料,发现以下两种方式:
第三种方式: 使用Edge-Triggered(边沿触发),这样socket有可写事件,只会触发一次。
可以在应用层做好标记。以避免频繁的调用 epoll_ctl( EPOLL_CTL_ADD, EPOLL_CTL_MOD)。 这种方式是epoll 的 man 手册里推荐的方式, 性能最高。但如果处理不当容易出错,事件驱动停止。
第四种方式: 在epoll_ctl()使用EPOLLONESHOT标志,当事件触发以后,socket会被禁止再次触发。
需要再次调用epoll_ctl(EPOLL_CTL_MOD),才会接收下一次事件。 这种方式可以禁止socket可写事件,应该也会同时禁止可读事件。会带来不便,同时并没有性能优势,因为epoll_ctl()有一定的操作代价。
从socket读数据时,socket缓存里的数据,可能超过用户缓存的长度,如果处理?
可以调用realloc(),扩大原有的缓存块尺寸。
但是临时申请内存的有一定性能损失。
这种情况要看接收缓存的方式。
第一种方式: 使用100k的大接收缓存为例。
如果要等待数据,并进行解析。可能发生缓存不够的情况。此时只能扩充缓存,或先处理100k的数据,再接收新的数据。
第二种方式: 使用缓存队列,分成8K大小的队列。
不存在接收缓存不够的情况。 除非用户解析已出错,使用数据接收、使用脱勾。这种方式的代价是,可能需要将缓存队列再次拷贝、拼接成一块大的缓存,再进行解析。而在本人的系统中,只需要将socket接收的数据再次原样分发给客户, 所以这种方案是最佳方案。
C++的虚函数有什么作用?
虚函数作用是实现多态, 很多人都能理解这一点。但却不会回答下面这一点。
更重要的,虚函数其实是实现封装,使得使用者不需要关心实现的细节。在很多设计模式中都是这样用法,例如Factory、Bridge、Strategy模式。 前两天在书上刚好看到这个问题,但在面试的时候却没想起来。
个人觉得这个问题可以很好的区分C++的理解水平。
步骤1: 设置非阻塞,启动连接
实现非阻塞 connect ,首先把 sockfd 设置成非阻塞的。这样调用
connect 可以立刻返回,根据返回值和 errno 处理三种情况:
(1) 如果返回 0,表示 connect 成功。
(2) 如果返回值小于 0, errno 为 EINPROGRESS, 表示连接
建立已经启动但是尚未完成。这是期望的结果,不是真正的错误。
(3) 如果返回值小于0,errno 不是 EINPROGRESS,则连接出错了。
步骤2:判断可读和可写
然后把 sockfd 加入 select 的读写监听集合,通过 select 判断 sockfd
是否可写,处理三种情况:
(1) 如果连接建立好了,对方没有数据到达,那么 sockfd 是可写的
(2) 如果在 select 之前,连接就建立好了,而且对方的数据已到达,
那么 sockfd 是可读和可写的。
(3) 如果连接发生错误,sockfd 也是可读和可写的。
判断 connect 是否成功,就得区别 (2) 和 (3),这两种情况下 sockfd 都是
可读和可写的,区分的方法是,调用 getsockopt 检查是否出错。
CPU缓存(Cache Memory)位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。由此可见,在CPU中加入缓存是一种高效的解决方案,这样整个内存储器(缓存+内存)就变成了既有缓存的高速度,又有内存的大容量的存储系统了。缓存对CPU的性能影响很大,主要是因为CPU的数据交换顺序和CPU与缓存间的带宽引起的。
缓存的工作原理是当CPU要读取一个数据时,首先从缓存中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
TCP/IP整体构架概述:
TCP/IP协议并不完全符合OSI的七层参考模型,而是采用了4层的层级结构,每一层都呼叫它的下一层所提供的网络来完成自己的需求。这4层分别为:
应用层:应用程序间沟通的层,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等。
传输层:在此层中,它提供了节点间的数据传送服务,如传输控制协议(TCP)、用户数据报协议(UDP)等,TCP和UDP给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确定数据已被送达并接收。
互连网络层:负责提供基本的数据封包传送功能,让每一块数据包都能够到达目的主机(但不检查是否被正确接收),如网际协议(IP)。
网络接口层:对实际的网络媒体的管理,定义如何使用实际网络(如Ethernet、Serial Line等)来传送数据。
三:TCP的定义及特点:
TCP---传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
TCP三次握手
在第一步中,客户端向服务端提出连接请求。这时TCP
SYN标志置位。客户端告诉服务端序列号区域合法,需要检查。客户端在TCP报头的序列号区中插入自己的ISN。服务端收到该TCP分段后,在第二步以自己的ISN回应(SYN标志置位),同时确认收到客户端的第一个TCP分段(ACK标志置位)。在第三步中,客户端确认收到服务端的ISN(ACK标志置位)。到此为止建立完整的TCP连接,开始全双工模式的数据传输过程。
OSI七个层次的功能
物理层 为数据链路层提供物理连接,在其上串行传送比特流,即所传送数据的单位是比特。此外,该层中还具有确定连接设备的电气特性和物理特性等功能。
数据链路层 负责在网络节点间的线路上通过检测、流量控制和重发等手段,无差错地传送以帧为单位的数据。为做到这一点,在每一帧中必须同时带有同步、地址、差错控制及流量控制等控制信息。
网络层 为了将数据分组从源(源端系统)送到目的地(目标端系统),网络层的任务就是选择合适的路由和交换节点,使源的传输层传下来的分组信息能够正确无误地按照地址找到目的地,并交付给相应的传输层,即完成网络的寻址功能。
传输层 传输层是高低层之间衔接的接口层。数据传输的单位是报文,当报文较长时将它分割成若干分组,然后交给网络层进行传输。传输层是计算机网络协议分层中的最关键一层,该层以上各层将不再管理信息传输问题。
会话层 该层对传输的报文提供同步管理服务。在两个不同系统的互相通信的应用进程之间建立、组织和协调交互。例如,确定是双工还是半双工工作。
表示层 该层的主要任务是把所传送的数据的抽象语法变换为传送语法,即把不同计算机内部的不同表示形式转换成网络通信中的标准表示形式。此外,对传送的数据加密(或解密)、正文压缩(或还原)也是表示层的任务。
应用层 该层直接面向用户,是OSI中的最高层。它的主要任务是为用户提供应用的接口,即提供不同计算机间的文件传送、访问与管理,电子邮件的内容处理,不同计算机通过网络交互访问的虚拟终端功能
从协议分层模型方面来讲,TCP/IP由四个层次组成:网络接口层、网间网层、传输层、应用层。其中:
网络接口层 这是TCP/IP软件的最低层,负责接收IP数据报并通过网络发送之,或者从网络上接收物理帧,抽出IP数据报,交给IP层。
网间网层 负责相邻计算机之间的通信。其功能包括三方面。一、处理来自传输层的分组发送请求,收到请求后,将分组装入IP数据报,填充报头,选择去往信宿机的路径,然后将数据报发往适当的网络接口。二、处理输入数据报:首先检查其合法性,然后进行寻径--假如该数据报已到达信宿机,则去掉报头,将剩下部分交给适当的传输协议;假如该数据报尚未到达信宿,则转发该数据报。三、处理路径、流控、拥塞等问题。
传输层 提供应用程序间的通信。其功能包括:一、格式化信息流;二、提供可靠传输。为实现后者,传输层协议规定接收端必须发回确认,并且假如分组丢失,必须重新发送。
应用层 向用户提供一组常用的应用程序,比如电子邮件、文件传输访问、远程登录等。远程登录TELNET使用TELNET协议提供在网络其它主机上注册的接口。TELNET会话提供了基于字符的虚拟终端。文件传输访问FTP使用FTP协议来提供网络内机器间的文件拷贝功能。
到商店里买200的商品返还100优惠券(可以在本商店代替现金)。请问实际上折扣是多少?
由于优惠券可以代替现金,所以可以使用200元优惠券买东西,然后还可以获得100元的优惠券。
假设开始时花了x元,那么可以买到 x + x/2 + x/4 + ...的东西。所以实际上折扣是50%.(当然,大部分时候很难一直兑换下去,所以50%是折扣的上限)
如果使用优惠券买东西不能获得新的优惠券,那么
总过花去了200元,可以买到200+100元的商品,所以实际折扣为 200/300 = 67%.
出牌有多种方式:单子,对子,顺子,三个,三带一,三带双,炸,炸带二,飞机。
下面根据用户出牌的数量来讨论
只有一个,必然是单子,合法。
两个,可能是对子,也可能是双王。如果两个不相对,则判断一下是否双王,也不是,则非法
三个,必须要求三个相同
四个,排序后,头三个相同或后三个相同。
五个,排序后,检测不同的牌的数量,必须小于等于三。
六个,可能是顺子,也可能是四带二,还可能是飞机,还可能是三个对子。先排序,看是否顺子,直接检测是否每个都相差1行了;不是再检测是否四带二,遍历一下,看是否有四个相同的;不是,则判飞机,头三个相同,且后三个相同;不是,再判三个对子,就是两两相同;不是,则不合法
七个,只可能是顺子了,排序,检测是否每个都差1;不是,则非法
八个,可能是顺子,或飞机。先检测顺子,不是顺子,再检测飞机,看是否有两个数字出现了三次,且这两个数字相邻。
九个,只可能是顺子
十个,可能是顺子,也可能是飞机,如果不是顺子,则看是否有两个数字出现了三次,且这两个数字相邻,并且有两个数字出现了两次
再大就只要检测顺子行了
编写Daemon程序有一些基本的规则,以避免不必要的麻烦。
1、首先是程序运行后调用fork,并让父进程退出。子进程获得一个新的进程ID,但继承了父进程的进程组ID。
2、调用setsid创建一个新的session,使自己成为新session和新进程组的leader,并使进程没有控制终端(tty)。
3、改变当前工作目录至根目录,以免影响可加载文件系统。或者也可以改变到某些特定的目录。
4、设置文件创建mask为0,避免创建文件时权限的影响。
5、关闭不需要的打开文件描述符。因为Daemon程序在后台执行,不需要于终端交互,通常就关闭STDIN、STDOUT和STDERR。其它根据实际情况处理。
另一个问题是Daemon程序不能和终端交互,也就无法使用printf方法输出信息了。我们可以使用syslog机制来实现信息的输出,方便程序的调试。在使用syslog前需要首先启动syslogd程序,关于syslogd程序的使用请参考它的man page,或相关文档,我们就不在这里讨论了。
atoi和strtol的区别和使用
1,atoi的返回值无法区分是正常的返回还是错误的返回,如:
int val;
val = atoi("abc"); 与val = atoi("0");
两者返回的val均为0,因此无法区分哪个是正确parse后的值。
2,strtol函数对异常的返回可以设置errno,从而可以发现异常的返回,如:
errno = 0; /* To distinguish success/failure after call */
val = strtol(str, &endptr, base);
/* Check for various possible errors */
if ((errno == ERANGE && (val == LONG_MAX || val == LONG_MIN))
|| (errno != 0 && val == 0)) {
perror("strtol");
exit(EXIT_FAILURE);
}
3,strtol函数支持不同进制的转换,而atoi只支持十进制的转换。
函数原型说明:
#include <stdlib.h>
int atoi(const char *nptr);
#include <stdlib.h>
long int
strtol(const char *nptr, char **endptr, int base);
给一个很大的数组,里面有一个数只出现过一次,其他数都出现过两次,把这两个数找出来
其实还有更加高效的方法:使用异或,两个相同的数异或,结果为0,0与任何数a异或,结果为a,并且异或具有这样的性质(忘记叫交换律还是结合律了),即 a ^ b ^ c = a ^ c ^ b;
比如3^4^3=4,,那么这样逐次异或以后,那么result就是出现次数只有一次的数字
代码如下:
int _tmain(int argc, _TCHAR* argv[])
{
int a[] = {102,102,33,33,22,44,44,100,100};
//int a[] = {102,32,99,32,45,102,45,67,67,100,100};
int result = 0;
int len=sizeof(a)/sizeof(int);
for(int i=0; i<len; i++)
{
result ^= a[i];
}
cout<<result<<endl;
system("pause");
return 0;
}
1-1000放在含有1001个元素的数组中,只有唯一的一个元素值重复,其它均只出现一次.每个数组元素只能访问一次,设计一个算法,将它找出来;不用辅助存储空间,能否设计一个算法实现?
(1) 方法一:(当N为比较大时警惕溢出)
将1001个元素相加减去1,2,3,……1000数列的和,得到的差即为重复的元素。
int Find(int* a)
{
int i;
for (i = 0;i<=1000;i++)
a[1000] += a[i];
a[1000] -= (i*(i-1))/2 //i的值为1001
return a[1000];
}
(2) 方法二:
数组取值操作可以看做一个特殊的函数f:D→R,定义域为下标值0~1000,值域为1到1000.如果对任意一个数 i,我们把f(i)叫做它的后继,i叫f(i)的前驱。0只有后继没有前驱,其他数字既有后继也有前驱,重复的那个数字有两个前驱,我们将利用这些特征。
规律:从0开始画一个箭头指向它的后继,从它的后继继续指向后继的后继,这样,必然会有一个节点指向之前已经出现过的数,即为重复的数。
利用下标与单元中所存储的内容之间的特殊关系,进行遍历访问单元,一旦访问过的单元赋予一个标记,利用标记作为发现重复数字的关键。代码如下:
void FindRepeat(int array[], int length)
{
int index = 0;
while ( true )
{
if ( array[index]<0 )
break;
array[index] *= -1; //访问过,变成相反数
index=array[index]*(-1);
}
cout<<"The repeat number is "<< -array[index] <<endl;
}
(3) 方法三
同样考虑下标与内容的关系,不过不用标记,而用两个速度不同的过程来访问。Slow每次前进一步,fast每次前进两步。在有环结构中,它们总会相遇。
void FindRepeat(int array[], int length)
{
int slow=fast= 0;
while ( true ) {
slow = array[slow];
fast = array[array[fast]];
if( slow == fast )
break;
}
fast = 0;
while( true) {
slow= array[slow];
fast =array[fast];
if( slow == fast )
break;
}
cout<<"The repeat number is "<< array[slowendl;
}
(4) 方法四:异或操作
void FindRepeat(int array[], int length)
{
int result = 0;
for(int i=1;i<=1000;i++)
result ^= i;
for(int i=0;i<=1000;i++)
result ^= array[i];
cout << result << endl;
}
Q:一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
A:将数组的每一个元素进行异或,得到的两个不同数字之间的异或,因为这两个数字不同,所以异或值必然不为0,所以我们找出异或值的一个为1的数位,按照该数位是否为0将数组分成两个子数组A和B,可以知道数组A含有的元素中有两个不同数字的一个,其他都是两两相同的数字;数组B含有的元素中有两个不同数字的另外一个,其他也都是两两相同的数字,再分别进行异或,即可求得两个数。
排序算法显神威
方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边(即i=1),指向数字6。让哨兵j指向序列的最右边(即=10),指向数字。
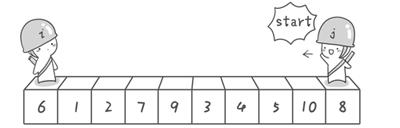
首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要(请自己想一想为什么)。哨兵j一步一步地向左挪动(即j--),直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动(即i++),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵i停在了数字7面前。


现在交换哨兵i和哨兵j所指向的元素的值。交换之后的序列如下:
6 1 2 5 9 3 4 7 10 8


到此,第一次交换结束。接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j先出发)。他发现了4(比基准数6要小,满足要求)之后停了下来。哨兵i也继续向右挪动的,他发现了9(比基准数6要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下:
6 1 2 5 4 3 9 7 10 8
第二次交换结束,“探测”继续。哨兵j继续向左挪动,他发现了3(比基准数6要小,满足要求)之后又停了下来。哨兵i继续向右移动,糟啦!此时哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。说明此时“探测”结束。我们将基准数6和3进行交换。交换之后的序列如下:
3 1 2 5 4 6 9 7 10 8



到此第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
void quicksort(int left,int right)
{
int i,j,t,temp;
if(left>right)
return;
temp=a[left]; //temp中存的就是基准数
i=left;
j=right;
while(i!=j)
{
//顺序很重要,要先从右边开始找
while(a[j]>=temp && i<j)
j--;
//再找右边的
while(a[i]<=temp && i<j)
i++;
//交换两个数在数组中的位置
if(i<j)
{
t=a[i];
a[i]=a[j];
a[j]=t;
}
}
//最终将基准数归位
a[left]=a[i];
a[i]=temp;
quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程
quicksort(i+1,right);//继续处理右边的 ,这里是一个递归的过程
}
Linux /proc目录 简介
Linux 内核提供了一种通过 /proc 文件系统,在运行时访问内核内部数据结构、改变内核设置的机制。proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。
用户和应用程序可以通过proc得到系统的信息,并可以改变内核的某些参数。由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取proc文件时,proc文件系统是动态从系统内核读出所需信息并提交的。下面列出的这些文件或子文件夹,并不是都是在你的系统中存在,这取决于你的内核配置和装载的模块。另外,在/proc下还有三个很重要的目录:net,scsi和sys。
Sys目录是可写的,可以通过它来访问或修改内核的参数,而net和scsi则依赖于内核配置。例如,如果系统不支持scsi,则scsi 目录不存在。
除了以上介绍的这些,还有的是一些以数字命名的目录,它们是进程目录。系统中当前运行的每一个进程都有对应的一个目录在/proc下,以进程的 PID号为目录名,它们是读取进程信息的接口。而self目录则是读取进程本身的信息接口,是一个link。
epoll和select区别
1.select的句柄数目受限,在linux/posix_types.h头文件有这样的声明:#define __FD_SETSIZE 1024 表示select最多同时监听1024个fd。而epoll没有,它的限制是最大的打开文件句柄数目。
2.epoll的最大好处是不会随着FD的数目增长而降低效率,在selec中采用轮询处理,其中的数据结构类似一个数组的数据结构,而epoll是维护一个队列,直接看队列是不是空就可以了。epoll只会对"活跃"的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数(把这个句柄加入队列),其他idle状态句柄则不会,在这点上,epoll实现了一个"伪"AIO。但是如果绝大部分的I/O都是“活跃的”,每个I/O端口使用率很高的话,epoll效率不一定比select高(可能是要维护队列复杂)。
3.使用mmap加速内核与用户空间的消息传递。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。
为什么人民币面值只有1,2,5?
通过以上分析我总结出如下结论:1,2,5可以组成任何面值.采用1、2、5制度可以保证组成任何金额时都不会超过三张钞票,方便结算
分类: ☆IT笔试面试题整理☆2012-04-10
13:01 1064人阅读 评论(0) 收藏 举报
面试腾讯
【题目描述】
两个数组a
,b
,其中A
的各个元素值已知,现给b[i]赋值,b[i]
= a[0]*a[1]*a[2]...*a[N-1]/a[i];
要求:
1.不准用除法运算
2.除了循环计数值,a
,b
外,不准再用其他任何变量(包括局部变量,全局变量等)
3.满足时间复杂度O(n),空间复杂度O(1)
【题目来源】腾讯2012
【题目分析】
由于题目要求甚多,就必须充分使用现有资源数组b,具体分析如下:
b[0] = a[1] *a[2] * a[3] …… * a[N-2] * a[N-1]
b[1] = a[0] * a[2]* a[3] …… * a[N-2] * a[N-1]
b[2] = a[0] * a[1]* a[3] …… * a[N-2] * a[N-1]
b[N-2] =a[0] * a[1]* a[2] * a[3] …… * a[N-3] * a[N-1]
b[N-1] =a[0] * a[1]* a[2] * a[3] …… * a[N-2]
由上面可以推得
b[i] = a[0] *a[1] * a[2] … a[i-1] * a[i+1] * a[i+2] * … a[N-2] * a[N -1]
因此可以采用分两段计算的策略解决问题。
同步通信与异步通信区别:
1.同步通信要求接收端时钟频率和发送端时钟频率一致,发送端发送连续的比特流;异步通信时不要求接收端时钟和发送端时钟同步,发送端发送完一个字节后,可经过任意长的时间间隔再发送下一个字节。
2.同步通信效率高;异步通信效率较低。
3.同步通信较复杂,双方时钟的允许误差较小;异步通信简单,双方时钟可允许一定误差。
4.同步通信可用于点对多点;异步通信只适用于点对点。
GNU编译器生成的目标文件默认格式为elf(executive linked file)格式,这是Linux系统所采用的可执行链接文件的通用文件格式。elf格式由若干个段(section)组成,由标准c源代码生成的目标文件中包含以下段:
.text(正文段)包含程序的指令代码,
.data(数据段)包含固定的数据,如常量,字符串等,
.bss(未初始化数据段)包含未初始化的变量和数组等。
在操作系统中,一个进程就是处于执行期的程序(当然包括系统资源),实际上正在执行的程序代码的活标本。那么进程的逻辑地址空间是如何划分的呢?
图1做了简单的说明(Linux系统下的):

图1
左边的是UNIX/LINUX系统的执行文件,右边是对应进程逻辑地址空间的划分情况。
一般认为在c中分为这几个存储区:
1. 栈 --有编译器自动分配释放
2. 堆 -- 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收
3. 全局区(静态区) -- 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束释放。
4. 另外还有一个专门放常量的地方。程序结束释放。 在函数体中定义的变量通常是在栈上,用malloc, calloc, realloc等分配内存的函数分配得到的就是在堆上。在所有函数体外定义的是全局量,加了static修饰符后不管在哪里都存放在全局区(静态区),在所有函数体外定义的static变量表示在该文件中有效,不能extern到别的文件用,在函数体内定义的static表示只在该函数体内有效。另外,函数中的"adgfdf"这样的字符串存放在常量区。
比如:代码:
int a = 0; //全局初始化区
char *p1; //全局未初始化区
main()
{
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //123456\0在常量区,p3在栈上。
static int c = 0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456");
//123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一块。
}
还有就是函数调用时会在栈上有一系列的保留现场及传递参数的操作。
栈的空间大小有限定,vc的缺省是2M。栈不够用的情况一般是程序中分配了大量数组和递归函数层次太深。有一点必须知道,当一个函数调用完返回后它会释放该函数中所有的栈空间。栈是由编译器自动管理的,不用你操心。
堆是动态分配内存的,并且你可以分配使用很大的内存。但是用不好会产生内存泄漏。并且频繁地malloc和free会产生内存碎片(有点类似磁盘碎片),因为c分配动态内存时是寻找匹配的内存的。而用栈则不会产生碎片。
在栈上存取数据比通过指针在堆上存取数据快些。
一般大家说的堆栈和栈是一样的,就是栈(stack),而说堆时才是堆heap. 栈是先入后出的,一般是由高地址向低地址生长。
堆(heap)和堆栈(stack)的区别
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#i nclude <...>
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
堆和栈的区别主要分:
操作系统方面的堆和栈,如上面说的那些,不多说了。
还有就是数据结构方面的堆和栈,这些都是不同的概念。这里的堆实际上指的就是(满足堆性质的)优先队列的一种数据结构,第1个元素有最高的优先权;栈实际上就是满足先进后出的性质的数学或数据结构。
虽然堆栈,堆栈的说法是连起来叫,但是他们还是有很大区别的,连着叫只是由于历史的原因。
申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap)— 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区(text)—存放函数体的二进制代码。
TCP提供的可靠数据传输服务,是依靠接收端TCP软件按序号对收到的数据分组进行逐一确认实现的。这个过程在TCP收发端开始通信时,被称为三次握手初始化。
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
16位源端口号16位目的端口号32位序列号32位确认序列号4位头部长度保留6位U
R
GA
C
KP
S
HR
S
TS
Y
NF
I
N16位窗口大小16位检验和16位紧急指针可选项数据源端口: 长度为16位,2个字节。
目的端口: 长度为16位,2个字节。
IP实现了点到点的数据通信,而TCP实现的是端到端的通信。
通信端用一个IP与端口号来唯一标识。(其实端口号就是用来标识同一主机中的不同进程。)
IP协议负责将数据传输到目标主机,而TCP可以根据数据报中的端口号,将数据交给相应的程序进行处理。
序列号: 长度32位,4个字节。
确认序列号:长度32位,4个字节。
头部长度:该字段占用4位,用来表示报文首部的长度,单位是4Byte。如:headLen = ((packet[12]>>4)&0x0F)*4;
预留6位:长度为6位,作为保留字段,暂时没有什么用处。
数据总线
(1) 是CPU与内存或其他器件之间的数据传送的通道。
(2)数据总线的宽度决定了CPU和外界的数据传送速度。
(3)每条传输线一次只能传输1位二进制数据。eg: 8根数据线一次可传送一个8位二进制数据(即一个字节)。
(4)数据总线是数据线数量之和。
地址总线
(1)CPU是通过地址总线来指定存储单元的。
(2)地址总线决定了cpu所能访问的最大内存空间的大小。eg: 10根地址线能访问的最大的内存为1024位二进制数据(1B)
(3)地址总线是地址线数量之和。
控制总线
(1)CPU通过控制总线对外部器件进行控制。
(2)控制总线的宽度决定了CPU对外部器件的控制能力。
(3)控制总线是控制线数量之和。
小结TCP与UDP的区别:
1.基于连接与无连接;
2.对系统资源的要求(TCP较多,UDP少);
3.UDP程序结构较简单;
4.流模式与数据报模式 ;
5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。
、人民币面值只有1,2,5?
通过以上分析我总结出如下结论:1,2,5可以组成任何面值.采用1、2、5制度可以保证组成任何金额时都不会超过三张钞票,方便结算
int binSearch(int x, int a[], int n) { int low, high, mid; low = 0; high = n-1; //注意,这里必须用<=, 用<不对,一直返回-1 while(low <= high) { mid = (low + high) / 2; if(x < a[mid]) high = mid - 1; else if(x > a[mid]) low = mid + 1; else return mid; } return -1; }递归二分法void Search(int p[],int low,int height,int key) { int middle=(low+height)/2; if(low>height) { printf("没有该数!"); return; } if(p[middle]==key) { printf("%d\n",middle); return; } else if(p[middle]>key) { Search(p,low,middle-1,key); } else if(p[middle]<key) { Search(p,middle+1,height,key); } }写法非常简洁
char *strcpy(char *dest, const char *src){char *tmp = dest;while ((*dest++ = *src++) != '\0')/* nothing */;return tmp;}注意移动的区域重合,所以要从不同的方向进行void *memmove(void *dest, const void *src, size_t count){char *tmp;const char *s;if (dest <= src) {tmp = dest;s = src;while (count--)*tmp++ = *s++;} else {tmp = dest;tmp += count;s = src;s += count;while (count--)*--tmp = *--s;}return dest;}char *strstr(const char *s1, const char *s2){int l1, l2;l2 = strlen(s2);if (!l2)return (char *)s1;l1 = strlen(s1);while (l1 >= l2) {l1--;if (!memcmp(s1, s2, l2))return (char *)s1;s1++;}return NULL;}非常经典的strlen函数没用我们的变量递加而用指针计数,非常耐人寻味
size_t strlen(const char *s){const char *sc;for (sc = s; *sc != '\0'; ++sc)/* nothing */;return sc - s;}有时候函数原本不需要返回值,但为了增加灵活性如支持链式表达,可以附加返回值。
struct 内存对齐知识点
数据存放的大小端知识点
static union { char c[4]; unsigned long l; } endian_test __initdata = { { 'l', '?', '?', 'b' } };
#define ENDIANNESS ((char)endian_test.l)
嵌入式关键字volatile
1). 并行设备的硬件寄存器(如:状态寄存器)
2). 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
3). 多线程应用中被几个任务共享的变量
数组指针(也称行指针)
定义 int (*p)
;
指针数组
定义 int *p
;
在C/C++中,常量指针是这样声明的:
1)const int *p;
2)int const *p;
在C/C++中,指针常量这样声明:
int a;
int *const b = &a; //const放在指针声明操作符的右侧
链表的定义
struct list_head {
struct list_head *next, *prev;
};
typedef struct的用法
指针函数int *f(x,y)
函数指针int (*f) (int x);
看看signal的原型
void (*signal(int signum,void(* handler)(int)))(int);
进程与线程的区别
一、进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。
二、线程是进程的一个实体,是CPU调度和分派的基本单位,他是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),一个线程可以创建和撤销另一个线程;
中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是中断响应过程所用的时间,
即
从发出中断请求到进入中断处理所用的时间。
因为线程调度是在进程中进行,在同一存储区内操作,而进程则在不同存储区操作,所以进程调度数度比线程慢
arm7 arm9 arm11的区别
ARM7是冯诺依慢结构ARM9、ARM11是哈佛结构,所以性能要高一点。ARM9和ARM11大多带内存管理器,跑操作系统好一点,ARM7没有MMU单元适合裸奔。不跑操作系统,价格低一点的:ARM7、cortex-M3等等。性价比高,可跑也可不跑操作系统的:ARM9、cortex-Rx等等。性能高的,通常要跑操作系统的:ARM10、ARM11、Cortex-A8等等。
linux使用的进程间通信方式:
(1)管道(pipe)和有名管道(FIFO)
(2)信号(signal)
(3)消息队列
(4)共享内存
(5)信号量
(6)套接字(socket)
linux 设备驱动中的并发控制:
访问共享资源的代码区域为临界区,临界区需要用某种互斥机制加心保护。
中断屏蔽、原子操作、自旋锁和信号量是linux设备驱动中可采用的互斥途径
linux进程间同步的方法互斥量,读写锁,条件变量
linux内核同步方法原子操作,信号量,自旋锁,完成量,禁止抢占
网络编程注意事项
1、返回值判断
示例:
int num = recv(s,buf, MAX,0);
能够从套接字读多少数据不是api参数能够控制的,只能通过返回来确认。
再有就是有些api调用是次序依赖的,前面的错了,后面的也会错。
所以返回值的判断是必须的。
2、端口复用
一般server异常退出后,端口没有被系统马上释放,如何才能立即使用端口呢?
on = 1;
ret = setsockopt( sock, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on) );
3、数据同步
server read/write(recv/send、recvfrom/sendto)<----->client read/write(recv/send、recvfrom/sendto)
如果收发端的速度不一致,常常会出现发送多次接收一次或是发送一次接收多次的情况。
解决方案:
A、缓存接收,加格式头来解析数据
使用循环队列,一边接收,一边按设定格式解析。
B、应答接收
接收端先请求,发送端发一次数据,接收端接收到格式指定的数据后,再发请求,发送再发送数据,依次类推。
4、发送数据包大小
A、tcp
如果write(/send、sendto)的缓存过大,协议层就会拆包发送,如果存在丢包现象(TCP应答机制会重发保证小包发送出去),实时大数据发送的时候,系统性能就会降低。
B、udp
如果write(/send、sendto)的缓存过大,协议层就会拆包发送,如果存在丢包现象(UDP发包后就不管),实时大数据发送的时候,接收端接收到数据就会不完整。
C、tcp及udp
如果write(/send、sendto)的缓存过小,譬如每次收发一个字节,大量协议内容就传递一个字节,通讯效能也就低。
解决方案:
参考内核拆包的最大容量设置及网络吞吐能力,如果应用层数据过大,就需要应用层拆包发送,保证协议层不用拆包。
5、字节序
两端主机的字节序不一致,如果不作逻辑约定,就会造成接收数据解析错误。
解决方案:
约定字节序
6、缓存字节对齐
如果发送的数据不是字节对齐的,就会出现垃圾数据,浪费流量。
7、主机异常退出
如果server和client正在进行数据交换时候,一端异常退出,就会造成另一端linux系统发出“Pipe Broken”信号,不忽略该信号,就会造成程序被终止。
解决方案:
send/recv、sendto/recvfrom的标志参数设置成MSG_NOSIGNAL,
使用read/write,则先忽略SIGPIPE信号。
写出简单的shell脚本
makefile的编写
如果找底层相关工作会考察驱动的情况
数组循环移位
设计一个算法,把一个含有N个元素的数组循环右移K位,要求时间复杂度为O(N),且只允许使用两个附加变量。
Reverse(char *arr, int b, int e)
{
for(; b < e; b++, e--)
{
char temp = arr[e];
arr[e] = arr;
arr[b] = temp;
}
}
RightShift(char *arr, int N, int k)
{
k %= N;
Reverse(arr, 0, N-k-1);
Reverse(arr, N-k, N-1);
Reverse(arr, 0, N-1);
}
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
hash(object)%N
一切都运行正常,再考虑如下的两种情况;
一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
有什么方法可以改变这个状况呢,这就是consistent hashing。
consistent hashing 算法的原理
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。下面就来按照 5 个步骤简单讲讲 consistent hashing 算法的基本原理。
[b]3.1 环形hash 空间
考虑通常的 hash 算法都是将 value 映射到一个 32 为的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环,如下面图 1 所示的那样。
图 1 环形 hash 空间
3.2 把对象映射到hash 空间
接下来考虑 4 个对象 object1~object4 ,通过 hash 函数计算出的 hash 值 key 在环上的分布如图 2 所示。hash(object1) = key1;
… …
hash(object4) = key4;
图 2 4 个对象的 key 值分布
3.3 把cache 映射到hash 空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的hash 算法。
假设当前有 A,B 和 C 共 3 台 cache ,那么其映射结果将如图 3 所示,他们在 hash 空间中,以对应的 hash值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C;
图 3 cache 和对象的 key 值分布
说到这里,顺便提一下 cache 的 hash 计算,一般的方法可以使用 cache 机器的 IP 地址或者机器名作为hash 输入。
3.4 把对象映射到cache
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2和 object3 对应到 cache C ; object4 对应到 cache B ;
3.5 考察cache 的变动
前面讲过,通过 hash 然后求余的方法带来的最大问题就在于不能满足单调性,当 cache 有所变动时,cache 会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析 consistent hashing 算法。
3.5.1 移除 cache
考虑假设 cache B 挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿 cache B 逆时针遍历直到下一个 cache ( cache C )之间的对象,也即是本来映射到 cache B 上的那些对象。
因此这里仅需要变动对象 object4 ,将其重新映射到 cache C 上即可;参见图 4 。
图 4 Cache B 被移除后的 cache 映射
3.5.2 添加 cache
再考虑添加一台新的 cache D 的情况,假设在这个环形 hash 空间中, cache D 被映射在对象 object2 和object3 之间。这时受影响的将仅是那些沿 cache D 逆时针遍历直到下一个 cache ( cache B )之间的对象(它们是也本来映射到 cache C 上对象的一部分),将这些对象重新映射到 cache D 上即可。
因此这里仅需要变动对象 object2 ,将其重新映射到 cache D 上;参见图 5 。
图 5 添加 cache D 后的映射关系
4 虚拟节点
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。
图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache时的映射关系如图 7 所示。
图 7 查询对象所在 cache
带头结点的单链表逆置
第二种方法是每次都将原第一个结点之后的那个结点放在list后面,下图是原始的单链表。为了反转这个单链表,我们先让头结点的next域指向结点2,再让结点1的next域指向结点3,最后将结点2的next域指向结点1,就完成了第一次交换,顺序就变成了Header-结点2-结点1-结点3-结点4-NULL,然后进行相同的交换将结点3移动到结点2的前面,然后再将结点4移动到结点3的前面就完成了反转,思路有了,就该写代码了:
第三种方法跟第二种方法差不多,第二种方法是将后面的结点向前移动到头结点的后面,第三种方法是将前面的结点移动到原来的最后一个结点的后面,思路跟第二种方法差不多,就不贴代码了
十六进制转换为整数
//将十六进制的字符串转换成整数
int htoi(char s[])
{
int i;
int n = 0;
if (s[0] == '0' && (s[1]=='x' || s[1]=='X'))
{
i = 2;
}
else
{
i = 0;
}
for (; (s[i] >= '0' && s[i] <= '9') || (s[i] >= 'a' && s[i] <= 'z') || (s[i] >='A' && s[i] <= 'Z');++i)
{
if (tolower(s[i]) > '9')
{
n = 16 * n + (10 + tolower(s[i]) - 'a');
}
else
{
n = 16 * n + (tolower(s[i]) - '0');
}
}
return n;
}
一直以为Linux里面,那些do{}while(0)只是为了程序的源代码看起来比较好看而已
今天听说他是有特殊作用的,在线请教,是什么作用?
---------------------------------------------------------------
是为了解决使用宏的时候烦人的分号问题。
---------------------------------------------------------------
楼说的不是很全面,我给个例子吧
#define wait_event(wq,condition) /
do{ if(condition) break; __wait_event(wq,condition); }while(0)
这是一个奇怪的循环,它根本就只会运行一次,为什么不去掉外面的do{..}while结构呢?我曾一度在心里把它叫做“怪圈”。原来这也是非常巧妙的技巧。在工程中可能经常会引起麻烦,而上面的定义能够保证这些麻烦不会出现。下面是解释:
假设有这样一个宏定义
#define macro(condition) if(condition) dosomething();
现在在程序中这样使用这个宏:
if(temp)
macro(i);
else
doanotherthing();
一切看起来很正常,但是仔细想想。这个宏会展开成:
if(temp)
if(condition) dosomething();
else
doanotherthing();
这时的else不是与第一个if语句匹配,而是错误的与第二个if语句进行了匹配,编译通过了,但是运行的结果一定是错误的。
为了避免这个错误,我们使用do{….}while(0) 把它包裹起来,成为一个独立的语法单元,从而不会与上下文发生混淆。同时因为绝大多数的编译器都能够识别do{…}while(0)这种无用的循环并进行优化,所以使用这种方法也不会导致程序的性能降低。
---------------------------------------------------------------
可是直接用{}括起来的话,最后的分号会引起麻烦的
某带头结点的单链表的头指针为head,则判定该链表为非空的条件是
带头节点的单链表为空的判定条件,带头节点的单链表的头节点head总是不空的,但是他的里面不存储具体的内容。他的下一个节点才是存储内容的开始,若没有下一个节点,则表示该链表没有存储内容。
常见内存分配算法及优缺点
常见内存分配算法及优缺点如下:
(1)首次适应算法。使用该算法进行内存分配时,从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链中。
该算法倾向于使用内存中低地址部分的空闲分区,在高地址部分的空闲分区很少被利用,从而保留了高地址部分的大空闲区。显然为以后到达的大作业分配大的内 存空间创造了条件。缺点在于低址部分不断被划分,留下许多难以利用、很小的空闲区,而每次查找又都从低址部分开始,这无疑会增加查找的开销。
(2)循环首次适应算法。该算法是由首次适应算法演变而成的。在为进程分配内存空间时,不再每次从链首开始查找,而是从上次找到的空闲分区开始查找,直至 找到一个能满足要求的空闲分区,并从中划出一块来分给作业。该算法能使空闲中的内存分区分布得更加均匀,但将会缺乏大的空闲分区。
(3)最佳适应算法。该算法总是把既能满足要求,又是最小的空闲分区分配给作业。
为了加速查找,该算法要求将所有的空闲区按其大小排序后,以递增顺序形成一个空白链。这样每次找到的第一个满足要求的空闲区,必然是最优的。孤立地看, 该算法似乎是最优的,但事实上并不一定。因为每次分配后剩余的空间一定是最小的,在存储器中将留下许多难以利用的小空闲区。同时每次分配后必须重新排序, 这也带来了一定的开销。
(4)最差适应算法。最差适应算法中,该算法按大小递减的顺序形成空闲区链,分配时直接从空闲区链的第一个空闲分区中 分配(不能满足需要则不分配)。很显然,如果第一个空闲分区不能满足,那么再没有空闲分区能满足需要。这种分配方法初看起来不太合理,但它也有很强的直观 吸引力:在大空闲区中放入程序后,剩下的空闲区常常也很大,于是还能装下一个较大的新程序。
最坏适应算法与最佳适应算法的排序正好相反,它的队列指针总是指向最大的空闲区,在进行分配时,总是从最大的空闲区开始查寻。
该算法克服了最佳适应算法留下的许多小的碎片的不足,但保留大的空闲区的可能性减小了,而且空闲区回收也和最佳适应算法一样复杂。
题目:将一个4字节整数的二进制表示中的001替换为011
答:
int replace(int num){ unsigned int mode3bit = 7; unsigned int mode1bit = 1; int shift = 0; int result = 0; while (shift < 32) { while (shift < 32 && (num & (mode3bit<<shift)) != (1<<shift)) { result += (num & (mode1bit<<shift)); shift++; } if (shift >= 32) { break; } else if (32 - shift < 3) //高位不足3位 { result += (num & (mode3bit<<shift)); break; } result += (3<<shift); shift += 3; } return result;}中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是从发出中断请求到进入中断处理所用的时间。
在数组里查找这样的数,它大于等于左侧所有数,小于等于右侧所有数
分析:
最原始的方法是检查每一个数 array[i] ,看是否左边的数都小于等于它,右边的数都大于等于它。这样做的话,要找出所有这样的数,时间复杂度为O(N^2)。
其实可以有更简单的方法,我们使用额外数组,比如rightMin[],来帮我们记录原始数组array[i]右边(包括自己)的最小值。假如原始数组为: array[] = {7, 10, 2, 6, 19, 22, 32}, 那么rightMin[] = {2, 2, 2, 6, 19, 22, 32}. 也就是说,7右边的最小值为2, 2右边的最小值也是2。
有了这样一个额外数组,当我们从头开始遍历原始数组时,我们保存一个当前最大值 max, 如果当前最大值刚好等于rightMin[i], 那么这个最大值一定满足条件。还是刚才的例子。
第一个值是7,最大值也是7,因为7 不等于 2, 继续,
第二个值是10,最大值变成了10,但是10也不等于2,继续,
第三个值是2,最大值是10,但是10也不等于2,继续,
第四个值是6,最大值是10,但是10不等于6,继续,
第五个值是19,最大值变成了19,而且19也等于当前rightMin[4] = 19, 所以,满足条件。
如此继续下去,后面的几个都满足。
代码:
[java] view
plaincopy
/**
* @author beiyeqingteng
* @linkhttp://blog.csdn.net/beiyeqingteng
*/
public static void smallLarge(int[] array) throws Exception{
//the array's size must be larger than 2
if (array == null || array.length < 1) {
throw new Exception("the array is null or the array has no element!");
}
int[] rightMin = new int[array.length];
rightMin[array.length - 1] = array[array.length - 1];
//get the minimum value of the array[] from i to array.length - 1
for (int i = array.length - 2; i >= 0; i--) {
if (array[i] < rightMin[i + 1]) {
rightMin[i] = array[i];
} else {
rightMin[i] = rightMin[i + 1];
}
}
int leftMax = Integer.MIN_VALUE;
for (int i = 0; i < array.length; i++) {
if (leftMax <= array[i]) {
leftMax = array[i];
if (leftMax == rightMin[i]) {
System.out.println(leftMax);
}
}
}
}
UNIX系统中进程由哪三部分组成?
(2005-11-06 13:26:04)转载▼
在UNIX系统中进程由以下三部分组成:①进程控制块PCB;②数据段;③正文段。
UNIX系统为了节省进程控制块所占的内存空间,把每个进程控制块分成两部分。一部分常驻内存,不管进程是否正占有处理器运行,系统经常会对这部分内容进行查询和处理,常驻部分内容包括:进程状态、优先数、过程特征、数据段始址、等待原因和队列指针等,这是进行处理器调度时必须使用的一些主要信息。另一部分非常驻内存,当进程不占有处理器时,系统不会对这部分内容进行查询和处理,因此这部分内容可以存放在磁盘的对换区中,它随用户的程序和数据部分换进或换出内存。
UNIX系统把进程的数据段又划分成三部分:用户栈区(供用户程序使用的信息区);用户数据区(包括用户工作数据和非可重入的程序段);系统数据区(包括系统变量和对换信息)。
正文段是可重入的程序,能被若干进程共享。为了管理可共享的正文段,UNIX设置了一张正文表,每个正文段都占用一个表目,用来指出该正文段在内存和磁盘上的位置、段的大小以及调用该段的进程数等情况。
中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是中断响应过程所用的时间,
即
从发出中断请求到进入中断处理所用的时间。
题目:给定一个8*8的方格子,如下图所示,求A点到B点的最短路径有多少条?用算法实现。
答:从图中可以看出,A点到B点的最短路径为16,即A点横走8小格,纵走8小格才能最快到达B点,这是排列组合的问题,即从最短路径16中选取8个横走的小格子(或者从最短路径16中选取8个纵走的小格子)。所以从A点到B点的最短路径条数,直接可以算出来,即为:
中断处理过程分为两个阶段:
中断响应过程和中断服务过程。
中断响应时间是中断响应过程所用的时间,
即从发出中断请求到进入中断处理所用的时间。
linux进程是抢占式的,被抢占的进程仍然处于TASK_RUNNING状态,只是暂时不被CPU执行。
面积对象程序设计语言有三大特点:封装、继承、多态
使用linux epoll模型,水平触发模式(Level-Triggered);当socket可写时,会不停的触发socket可写的事件,如何处理?
第一种最普通的方式:
当需要向socket写数据时,将该socket加入到epoll模型(epoll_ctl);等待可写事件。
接收到socket可写事件后,调用write()或send()发送数据。。。
当数据全部写完后, 将socket描述符移出epoll模型。
这种方式的缺点是: 即使发送很少的数据,也要将socket加入、移出epoll模型。有一定的操作代价。
第二种方式,(是本人的改进方案, 叫做directly-write)
向socket写数据时,不将socket加入到epoll模型;而是直接调用send()发送;
只有当或send()返回错误码EAGAIN(系统缓存满),才将socket加入到epoll模型,等待可写事件后,再发送数据。
全部数据发送完毕,再移出epoll模型。
这种方案的优点: 当用户数据比较少时,不需要epool的事件处理。
在高压力的情况下,性能怎么样呢?
对一次性直接写成功、失败的次数进行统计。如果成功次数远大于失败的次数, 说明性能良好。(如果失败次数远大于成功的次数,则关闭这种直接写的操作,改用第一种方案。同时在日志里记录警告)
在我自己的应用系统中,实验结果数据证明该方案的性能良好。
事实上,网络数据可分为两种到达/发送情况:
一是分散的数据包, 例如每间隔40ms左右,发送/接收3-5个 MTU(或更小,这样就没超过默认的8K系统缓存)。
二是连续的数据包, 例如每间隔1s左右,连续发送/接收 20个 MTU(或更多)。
回来查了资料,发现以下两种方式:
第三种方式: 使用Edge-Triggered(边沿触发),这样socket有可写事件,只会触发一次。
可以在应用层做好标记。以避免频繁的调用 epoll_ctl( EPOLL_CTL_ADD, EPOLL_CTL_MOD)。 这种方式是epoll 的 man 手册里推荐的方式, 性能最高。但如果处理不当容易出错,事件驱动停止。
第四种方式: 在epoll_ctl()使用EPOLLONESHOT标志,当事件触发以后,socket会被禁止再次触发。
需要再次调用epoll_ctl(EPOLL_CTL_MOD),才会接收下一次事件。 这种方式可以禁止socket可写事件,应该也会同时禁止可读事件。会带来不便,同时并没有性能优势,因为epoll_ctl()有一定的操作代价。
从socket读数据时,socket缓存里的数据,可能超过用户缓存的长度,如果处理?
可以调用realloc(),扩大原有的缓存块尺寸。
但是临时申请内存的有一定性能损失。
这种情况要看接收缓存的方式。
第一种方式: 使用100k的大接收缓存为例。
如果要等待数据,并进行解析。可能发生缓存不够的情况。此时只能扩充缓存,或先处理100k的数据,再接收新的数据。
第二种方式: 使用缓存队列,分成8K大小的队列。
不存在接收缓存不够的情况。 除非用户解析已出错,使用数据接收、使用脱勾。这种方式的代价是,可能需要将缓存队列再次拷贝、拼接成一块大的缓存,再进行解析。而在本人的系统中,只需要将socket接收的数据再次原样分发给客户, 所以这种方案是最佳方案。
C++的虚函数有什么作用?
虚函数作用是实现多态, 很多人都能理解这一点。但却不会回答下面这一点。
更重要的,虚函数其实是实现封装,使得使用者不需要关心实现的细节。在很多设计模式中都是这样用法,例如Factory、Bridge、Strategy模式。 前两天在书上刚好看到这个问题,但在面试的时候却没想起来。
个人觉得这个问题可以很好的区分C++的理解水平。
步骤1: 设置非阻塞,启动连接
实现非阻塞 connect ,首先把 sockfd 设置成非阻塞的。这样调用
connect 可以立刻返回,根据返回值和 errno 处理三种情况:
(1) 如果返回 0,表示 connect 成功。
(2) 如果返回值小于 0, errno 为 EINPROGRESS, 表示连接
建立已经启动但是尚未完成。这是期望的结果,不是真正的错误。
(3) 如果返回值小于0,errno 不是 EINPROGRESS,则连接出错了。
步骤2:判断可读和可写
然后把 sockfd 加入 select 的读写监听集合,通过 select 判断 sockfd
是否可写,处理三种情况:
(1) 如果连接建立好了,对方没有数据到达,那么 sockfd 是可写的
(2) 如果在 select 之前,连接就建立好了,而且对方的数据已到达,
那么 sockfd 是可读和可写的。
(3) 如果连接发生错误,sockfd 也是可读和可写的。
判断 connect 是否成功,就得区别 (2) 和 (3),这两种情况下 sockfd 都是
可读和可写的,区分的方法是,调用 getsockopt 检查是否出错。
CPU缓存(Cache Memory)的作用
CPU缓存(Cache Memory)位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。由此可见,在CPU中加入缓存是一种高效的解决方案,这样整个内存储器(缓存+内存)就变成了既有缓存的高速度,又有内存的大容量的存储系统了。缓存对CPU的性能影响很大,主要是因为CPU的数据交换顺序和CPU与缓存间的带宽引起的。缓存的工作原理是当CPU要读取一个数据时,首先从缓存中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
TCP/IP整体构架概述:
TCP/IP协议并不完全符合OSI的七层参考模型,而是采用了4层的层级结构,每一层都呼叫它的下一层所提供的网络来完成自己的需求。这4层分别为:
应用层:应用程序间沟通的层,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等。
传输层:在此层中,它提供了节点间的数据传送服务,如传输控制协议(TCP)、用户数据报协议(UDP)等,TCP和UDP给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确定数据已被送达并接收。
互连网络层:负责提供基本的数据封包传送功能,让每一块数据包都能够到达目的主机(但不检查是否被正确接收),如网际协议(IP)。
网络接口层:对实际的网络媒体的管理,定义如何使用实际网络(如Ethernet、Serial Line等)来传送数据。
三:TCP的定义及特点:
TCP---传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
TCP三次握手
在第一步中,客户端向服务端提出连接请求。这时TCP
SYN标志置位。客户端告诉服务端序列号区域合法,需要检查。客户端在TCP报头的序列号区中插入自己的ISN。服务端收到该TCP分段后,在第二步以自己的ISN回应(SYN标志置位),同时确认收到客户端的第一个TCP分段(ACK标志置位)。在第三步中,客户端确认收到服务端的ISN(ACK标志置位)。到此为止建立完整的TCP连接,开始全双工模式的数据传输过程。
OSI七个层次的功能
物理层 为数据链路层提供物理连接,在其上串行传送比特流,即所传送数据的单位是比特。此外,该层中还具有确定连接设备的电气特性和物理特性等功能。
数据链路层 负责在网络节点间的线路上通过检测、流量控制和重发等手段,无差错地传送以帧为单位的数据。为做到这一点,在每一帧中必须同时带有同步、地址、差错控制及流量控制等控制信息。
网络层 为了将数据分组从源(源端系统)送到目的地(目标端系统),网络层的任务就是选择合适的路由和交换节点,使源的传输层传下来的分组信息能够正确无误地按照地址找到目的地,并交付给相应的传输层,即完成网络的寻址功能。
传输层 传输层是高低层之间衔接的接口层。数据传输的单位是报文,当报文较长时将它分割成若干分组,然后交给网络层进行传输。传输层是计算机网络协议分层中的最关键一层,该层以上各层将不再管理信息传输问题。
会话层 该层对传输的报文提供同步管理服务。在两个不同系统的互相通信的应用进程之间建立、组织和协调交互。例如,确定是双工还是半双工工作。
表示层 该层的主要任务是把所传送的数据的抽象语法变换为传送语法,即把不同计算机内部的不同表示形式转换成网络通信中的标准表示形式。此外,对传送的数据加密(或解密)、正文压缩(或还原)也是表示层的任务。
应用层 该层直接面向用户,是OSI中的最高层。它的主要任务是为用户提供应用的接口,即提供不同计算机间的文件传送、访问与管理,电子邮件的内容处理,不同计算机通过网络交互访问的虚拟终端功能
从协议分层模型方面来讲,TCP/IP由四个层次组成:网络接口层、网间网层、传输层、应用层。其中:
网络接口层 这是TCP/IP软件的最低层,负责接收IP数据报并通过网络发送之,或者从网络上接收物理帧,抽出IP数据报,交给IP层。
网间网层 负责相邻计算机之间的通信。其功能包括三方面。一、处理来自传输层的分组发送请求,收到请求后,将分组装入IP数据报,填充报头,选择去往信宿机的路径,然后将数据报发往适当的网络接口。二、处理输入数据报:首先检查其合法性,然后进行寻径--假如该数据报已到达信宿机,则去掉报头,将剩下部分交给适当的传输协议;假如该数据报尚未到达信宿,则转发该数据报。三、处理路径、流控、拥塞等问题。
传输层 提供应用程序间的通信。其功能包括:一、格式化信息流;二、提供可靠传输。为实现后者,传输层协议规定接收端必须发回确认,并且假如分组丢失,必须重新发送。
应用层 向用户提供一组常用的应用程序,比如电子邮件、文件传输访问、远程登录等。远程登录TELNET使用TELNET协议提供在网络其它主机上注册的接口。TELNET会话提供了基于字符的虚拟终端。文件传输访问FTP使用FTP协议来提供网络内机器间的文件拷贝功能。
到商店里买200的商品返还100优惠券(可以在本商店代替现金)。请问实际上折扣是多少?
由于优惠券可以代替现金,所以可以使用200元优惠券买东西,然后还可以获得100元的优惠券。
假设开始时花了x元,那么可以买到 x + x/2 + x/4 + ...的东西。所以实际上折扣是50%.(当然,大部分时候很难一直兑换下去,所以50%是折扣的上限)
如果使用优惠券买东西不能获得新的优惠券,那么
总过花去了200元,可以买到200+100元的商品,所以实际折扣为 200/300 = 67%.
斗地主之出牌合法性检查
出牌有多种方式:单子,对子,顺子,三个,三带一,三带双,炸,炸带二,飞机。下面根据用户出牌的数量来讨论
只有一个,必然是单子,合法。
两个,可能是对子,也可能是双王。如果两个不相对,则判断一下是否双王,也不是,则非法
三个,必须要求三个相同
四个,排序后,头三个相同或后三个相同。
五个,排序后,检测不同的牌的数量,必须小于等于三。
六个,可能是顺子,也可能是四带二,还可能是飞机,还可能是三个对子。先排序,看是否顺子,直接检测是否每个都相差1行了;不是再检测是否四带二,遍历一下,看是否有四个相同的;不是,则判飞机,头三个相同,且后三个相同;不是,再判三个对子,就是两两相同;不是,则不合法
七个,只可能是顺子了,排序,检测是否每个都差1;不是,则非法
八个,可能是顺子,或飞机。先检测顺子,不是顺子,再检测飞机,看是否有两个数字出现了三次,且这两个数字相邻。
九个,只可能是顺子
十个,可能是顺子,也可能是飞机,如果不是顺子,则看是否有两个数字出现了三次,且这两个数字相邻,并且有两个数字出现了两次
再大就只要检测顺子行了
Daemon程序实现方法
编写Daemon程序有一些基本的规则,以避免不必要的麻烦。1、首先是程序运行后调用fork,并让父进程退出。子进程获得一个新的进程ID,但继承了父进程的进程组ID。
2、调用setsid创建一个新的session,使自己成为新session和新进程组的leader,并使进程没有控制终端(tty)。
3、改变当前工作目录至根目录,以免影响可加载文件系统。或者也可以改变到某些特定的目录。
4、设置文件创建mask为0,避免创建文件时权限的影响。
5、关闭不需要的打开文件描述符。因为Daemon程序在后台执行,不需要于终端交互,通常就关闭STDIN、STDOUT和STDERR。其它根据实际情况处理。
另一个问题是Daemon程序不能和终端交互,也就无法使用printf方法输出信息了。我们可以使用syslog机制来实现信息的输出,方便程序的调试。在使用syslog前需要首先启动syslogd程序,关于syslogd程序的使用请参考它的man page,或相关文档,我们就不在这里讨论了。
atoi和strtol的区别和使用
1,atoi的返回值无法区分是正常的返回还是错误的返回,如:
int val;
val = atoi("abc"); 与val = atoi("0");
两者返回的val均为0,因此无法区分哪个是正确parse后的值。
2,strtol函数对异常的返回可以设置errno,从而可以发现异常的返回,如:
errno = 0; /* To distinguish success/failure after call */
val = strtol(str, &endptr, base);
/* Check for various possible errors */
if ((errno == ERANGE && (val == LONG_MAX || val == LONG_MIN))
|| (errno != 0 && val == 0)) {
perror("strtol");
exit(EXIT_FAILURE);
}
3,strtol函数支持不同进制的转换,而atoi只支持十进制的转换。
函数原型说明:
#include <stdlib.h>
int atoi(const char *nptr);
#include <stdlib.h>
long int
strtol(const char *nptr, char **endptr, int base);
给一个很大的数组,里面有一个数只出现过一次,其他数都出现过两次,把这两个数找出来
其实还有更加高效的方法:使用异或,两个相同的数异或,结果为0,0与任何数a异或,结果为a,并且异或具有这样的性质(忘记叫交换律还是结合律了),即 a ^ b ^ c = a ^ c ^ b;
比如3^4^3=4,,那么这样逐次异或以后,那么result就是出现次数只有一次的数字
代码如下:
int _tmain(int argc, _TCHAR* argv[])
{
int a[] = {102,102,33,33,22,44,44,100,100};
//int a[] = {102,32,99,32,45,102,45,67,67,100,100};
int result = 0;
int len=sizeof(a)/sizeof(int);
for(int i=0; i<len; i++)
{
result ^= a[i];
}
cout<<result<<endl;
system("pause");
return 0;
}
找出数组中唯一的重复元素※
1-1000放在含有1001个元素的数组中,只有唯一的一个元素值重复,其它均只出现一次.每个数组元素只能访问一次,设计一个算法,将它找出来;不用辅助存储空间,能否设计一个算法实现?(1) 方法一:(当N为比较大时警惕溢出)
将1001个元素相加减去1,2,3,……1000数列的和,得到的差即为重复的元素。
int Find(int* a)
{
int i;
for (i = 0;i<=1000;i++)
a[1000] += a[i];
a[1000] -= (i*(i-1))/2 //i的值为1001
return a[1000];
}
(2) 方法二:
数组取值操作可以看做一个特殊的函数f:D→R,定义域为下标值0~1000,值域为1到1000.如果对任意一个数 i,我们把f(i)叫做它的后继,i叫f(i)的前驱。0只有后继没有前驱,其他数字既有后继也有前驱,重复的那个数字有两个前驱,我们将利用这些特征。
规律:从0开始画一个箭头指向它的后继,从它的后继继续指向后继的后继,这样,必然会有一个节点指向之前已经出现过的数,即为重复的数。
利用下标与单元中所存储的内容之间的特殊关系,进行遍历访问单元,一旦访问过的单元赋予一个标记,利用标记作为发现重复数字的关键。代码如下:
void FindRepeat(int array[], int length)
{
int index = 0;
while ( true )
{
if ( array[index]<0 )
break;
array[index] *= -1; //访问过,变成相反数
index=array[index]*(-1);
}
cout<<"The repeat number is "<< -array[index] <<endl;
}
(3) 方法三
同样考虑下标与内容的关系,不过不用标记,而用两个速度不同的过程来访问。Slow每次前进一步,fast每次前进两步。在有环结构中,它们总会相遇。
void FindRepeat(int array[], int length)
{
int slow=fast= 0;
while ( true ) {
slow = array[slow];
fast = array[array[fast]];
if( slow == fast )
break;
}
fast = 0;
while( true) {
slow= array[slow];
fast =array[fast];
if( slow == fast )
break;
}
cout<<"The repeat number is "<< array[slowendl;
}
(4) 方法四:异或操作
void FindRepeat(int array[], int length)
{
int result = 0;
for(int i=1;i<=1000;i++)
result ^= i;
for(int i=0;i<=1000;i++)
result ^= array[i];
cout << result << endl;
}
找出数组中两个只出现一次的数字
Q:一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。A:将数组的每一个元素进行异或,得到的两个不同数字之间的异或,因为这两个数字不同,所以异或值必然不为0,所以我们找出异或值的一个为1的数位,按照该数位是否为0将数组分成两个子数组A和B,可以知道数组A含有的元素中有两个不同数字的一个,其他都是两两相同的数字;数组B含有的元素中有两个不同数字的另外一个,其他也都是两两相同的数字,再分别进行异或,即可求得两个数。
1 #include <iostream> 2 using namespace std; 3 4 void Calc(int* arr,int n) 5 { 6 int result=0; 7 int a=0,b=0,index=0; 8 for(int i=0;i<n;++i) 9 result=result^arr[i];10 while(result)11 {12 if(result & 0x1==0)13 {14 index++;15 result=result>>1;16 }17 else18 break;19 }20 int cmp=1<<index;21 for(int i=0;i<n;++i)22 {23 if(arr[i] & cmp)24 a=a^arr[i];25 else26 b=b^arr[i];27 }28 cout <<a<<" "<<b<<endl;29 }30 31 int main()32 {33 int n;34 cin >>n;35 int* arr=new int;36 for(int i=0;i<n;++i)37 cin >>arr[i];38 Calc(arr,n);39 return 0;40 }
快速排序
排序算法显神威方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边(即i=1),指向数字6。让哨兵j指向序列的最右边(即=10),指向数字。
首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要(请自己想一想为什么)。哨兵j一步一步地向左挪动(即j--),直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动(即i++),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵i停在了数字7面前。
现在交换哨兵i和哨兵j所指向的元素的值。交换之后的序列如下:
6 1 2 5 9 3 4 7 10 8
到此,第一次交换结束。接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j先出发)。他发现了4(比基准数6要小,满足要求)之后停了下来。哨兵i也继续向右挪动的,他发现了9(比基准数6要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下:
6 1 2 5 4 3 9 7 10 8
第二次交换结束,“探测”继续。哨兵j继续向左挪动,他发现了3(比基准数6要小,满足要求)之后又停了下来。哨兵i继续向右移动,糟啦!此时哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。说明此时“探测”结束。我们将基准数6和3进行交换。交换之后的序列如下:
3 1 2 5 4 6 9 7 10 8
到此第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
void quicksort(int left,int right)
{
int i,j,t,temp;
if(left>right)
return;
temp=a[left]; //temp中存的就是基准数
i=left;
j=right;
while(i!=j)
{
//顺序很重要,要先从右边开始找
while(a[j]>=temp && i<j)
j--;
//再找右边的
while(a[i]<=temp && i<j)
i++;
//交换两个数在数组中的位置
if(i<j)
{
t=a[i];
a[i]=a[j];
a[j]=t;
}
}
//最终将基准数归位
a[left]=a[i];
a[i]=temp;
quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程
quicksort(i+1,right);//继续处理右边的 ,这里是一个递归的过程
}
Linux /proc目录 简介
Linux 内核提供了一种通过 /proc 文件系统,在运行时访问内核内部数据结构、改变内核设置的机制。proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。
用户和应用程序可以通过proc得到系统的信息,并可以改变内核的某些参数。由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取proc文件时,proc文件系统是动态从系统内核读出所需信息并提交的。下面列出的这些文件或子文件夹,并不是都是在你的系统中存在,这取决于你的内核配置和装载的模块。另外,在/proc下还有三个很重要的目录:net,scsi和sys。
Sys目录是可写的,可以通过它来访问或修改内核的参数,而net和scsi则依赖于内核配置。例如,如果系统不支持scsi,则scsi 目录不存在。
除了以上介绍的这些,还有的是一些以数字命名的目录,它们是进程目录。系统中当前运行的每一个进程都有对应的一个目录在/proc下,以进程的 PID号为目录名,它们是读取进程信息的接口。而self目录则是读取进程本身的信息接口,是一个link。
epoll和select区别
1.select的句柄数目受限,在linux/posix_types.h头文件有这样的声明:#define __FD_SETSIZE 1024 表示select最多同时监听1024个fd。而epoll没有,它的限制是最大的打开文件句柄数目。
2.epoll的最大好处是不会随着FD的数目增长而降低效率,在selec中采用轮询处理,其中的数据结构类似一个数组的数据结构,而epoll是维护一个队列,直接看队列是不是空就可以了。epoll只会对"活跃"的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数(把这个句柄加入队列),其他idle状态句柄则不会,在这点上,epoll实现了一个"伪"AIO。但是如果绝大部分的I/O都是“活跃的”,每个I/O端口使用率很高的话,epoll效率不一定比select高(可能是要维护队列复杂)。
3.使用mmap加速内核与用户空间的消息传递。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。
为什么人民币面值只有1,2,5?
通过以上分析我总结出如下结论:1,2,5可以组成任何面值.采用1、2、5制度可以保证组成任何金额时都不会超过三张钞票,方便结算
两个数组a
,b
,其中A
的各个元素值已知,现给b[i]赋值
分类: ☆IT笔试面试题整理☆2012-04-1013:01 1064人阅读 评论(0) 收藏 举报
面试腾讯
【题目描述】
两个数组a
,b
,其中A
的各个元素值已知,现给b[i]赋值,b[i]
= a[0]*a[1]*a[2]...*a[N-1]/a[i];
要求:
1.不准用除法运算
2.除了循环计数值,a
,b
外,不准再用其他任何变量(包括局部变量,全局变量等)
3.满足时间复杂度O(n),空间复杂度O(1)
【题目来源】腾讯2012
【题目分析】
由于题目要求甚多,就必须充分使用现有资源数组b,具体分析如下:
b[0] = a[1] *a[2] * a[3] …… * a[N-2] * a[N-1]
b[1] = a[0] * a[2]* a[3] …… * a[N-2] * a[N-1]
b[2] = a[0] * a[1]* a[3] …… * a[N-2] * a[N-1]
b[N-2] =a[0] * a[1]* a[2] * a[3] …… * a[N-3] * a[N-1]
b[N-1] =a[0] * a[1]* a[2] * a[3] …… * a[N-2]
由上面可以推得
b[i] = a[0] *a[1] * a[2] … a[i-1] * a[i+1] * a[i+2] * … a[N-2] * a[N -1]
因此可以采用分两段计算的策略解决问题。
同步通信与异步通信区别:
1.同步通信要求接收端时钟频率和发送端时钟频率一致,发送端发送连续的比特流;异步通信时不要求接收端时钟和发送端时钟同步,发送端发送完一个字节后,可经过任意长的时间间隔再发送下一个字节。
2.同步通信效率高;异步通信效率较低。
3.同步通信较复杂,双方时钟的允许误差较小;异步通信简单,双方时钟可允许一定误差。
4.同步通信可用于点对多点;异步通信只适用于点对点。
可执行程序的内存分布
GNU编译器生成的目标文件默认格式为elf(executive linked file)格式,这是Linux系统所采用的可执行链接文件的通用文件格式。elf格式由若干个段(section)组成,由标准c源代码生成的目标文件中包含以下段: .text(正文段)包含程序的指令代码,
.data(数据段)包含固定的数据,如常量,字符串等,
.bss(未初始化数据段)包含未初始化的变量和数组等。
在操作系统中,一个进程就是处于执行期的程序(当然包括系统资源),实际上正在执行的程序代码的活标本。那么进程的逻辑地址空间是如何划分的呢?
图1做了简单的说明(Linux系统下的):
图1
左边的是UNIX/LINUX系统的执行文件,右边是对应进程逻辑地址空间的划分情况。
一般认为在c中分为这几个存储区:
1. 栈 --有编译器自动分配释放
2. 堆 -- 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收
3. 全局区(静态区) -- 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束释放。
4. 另外还有一个专门放常量的地方。程序结束释放。 在函数体中定义的变量通常是在栈上,用malloc, calloc, realloc等分配内存的函数分配得到的就是在堆上。在所有函数体外定义的是全局量,加了static修饰符后不管在哪里都存放在全局区(静态区),在所有函数体外定义的static变量表示在该文件中有效,不能extern到别的文件用,在函数体内定义的static表示只在该函数体内有效。另外,函数中的"adgfdf"这样的字符串存放在常量区。
比如:代码:
int a = 0; //全局初始化区
char *p1; //全局未初始化区
main()
{
int b; //栈
char s[] = "abc"; //栈
char *p2; //栈
char *p3 = "123456"; //123456\0在常量区,p3在栈上。
static int c = 0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456");
//123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一块。
}
还有就是函数调用时会在栈上有一系列的保留现场及传递参数的操作。
栈的空间大小有限定,vc的缺省是2M。栈不够用的情况一般是程序中分配了大量数组和递归函数层次太深。有一点必须知道,当一个函数调用完返回后它会释放该函数中所有的栈空间。栈是由编译器自动管理的,不用你操心。
堆是动态分配内存的,并且你可以分配使用很大的内存。但是用不好会产生内存泄漏。并且频繁地malloc和free会产生内存碎片(有点类似磁盘碎片),因为c分配动态内存时是寻找匹配的内存的。而用栈则不会产生碎片。
在栈上存取数据比通过指针在堆上存取数据快些。
一般大家说的堆栈和栈是一样的,就是栈(stack),而说堆时才是堆heap. 栈是先入后出的,一般是由高地址向低地址生长。
堆(heap)和堆栈(stack)的区别
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#i nclude <...>
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
堆和栈的区别主要分:
操作系统方面的堆和栈,如上面说的那些,不多说了。
还有就是数据结构方面的堆和栈,这些都是不同的概念。这里的堆实际上指的就是(满足堆性质的)优先队列的一种数据结构,第1个元素有最高的优先权;栈实际上就是满足先进后出的性质的数学或数据结构。
虽然堆栈,堆栈的说法是连起来叫,但是他们还是有很大区别的,连着叫只是由于历史的原因。
申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap)— 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区(text)—存放函数体的二进制代码。
TCP协议的三次握手
TCP提供的可靠数据传输服务,是依靠接收端TCP软件按序号对收到的数据分组进行逐一确认实现的。这个过程在TCP收发端开始通信时,被称为三次握手初始化。第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
传输层——TCP报文头介绍
16位源端口号16位目的端口号32位序列号32位确认序列号4位头部长度保留6位UR
GA
C
KP
S
HR
S
TS
Y
NF
I
N16位窗口大小16位检验和16位紧急指针可选项数据源端口: 长度为16位,2个字节。
目的端口: 长度为16位,2个字节。
IP实现了点到点的数据通信,而TCP实现的是端到端的通信。
通信端用一个IP与端口号来唯一标识。(其实端口号就是用来标识同一主机中的不同进程。)
IP协议负责将数据传输到目标主机,而TCP可以根据数据报中的端口号,将数据交给相应的程序进行处理。
序列号: 长度32位,4个字节。
确认序列号:长度32位,4个字节。
头部长度:该字段占用4位,用来表示报文首部的长度,单位是4Byte。如:headLen = ((packet[12]>>4)&0x0F)*4;
预留6位:长度为6位,作为保留字段,暂时没有什么用处。
数据总线
(1) 是CPU与内存或其他器件之间的数据传送的通道。
(2)数据总线的宽度决定了CPU和外界的数据传送速度。
(3)每条传输线一次只能传输1位二进制数据。eg: 8根数据线一次可传送一个8位二进制数据(即一个字节)。
(4)数据总线是数据线数量之和。
地址总线
(1)CPU是通过地址总线来指定存储单元的。
(2)地址总线决定了cpu所能访问的最大内存空间的大小。eg: 10根地址线能访问的最大的内存为1024位二进制数据(1B)
(3)地址总线是地址线数量之和。
控制总线
(1)CPU通过控制总线对外部器件进行控制。
(2)控制总线的宽度决定了CPU对外部器件的控制能力。
(3)控制总线是控制线数量之和。
TCP (Transmission Control Protocol)和UDP(User Datagram Protocol)协议属于传输层协议。其中TCP提供IP环境下的数据可靠传输,它提供的服务[1]包括数据流传送、可靠性、有效流控、全双工操作和多路复用。通过面向连接、端到端和可靠的数据包发送。通俗说,它是事先为所发送的数据开辟出连接好的通道,然后再进行数据发送;而UDP则不为IP提供可靠性、流控或差错恢复功能。一般来说,TCP对应的是可靠性要求高的应用,而UDP对应的则是可靠性要求低、传输经济的应用。TCP支持的应用协议主要有:Telnet、FTP、SMTP等;UDP支持的应用层协议主要有:NFS(网络文件系统)、SNMP(简单网络管理协议)、DNS(主域名称系统)、TFTP(通用文件传输协议)等。
小结TCP与UDP的区别:
1.基于连接与无连接;
2.对系统资源的要求(TCP较多,UDP少);
3.UDP程序结构较简单;
4.流模式与数据报模式 ;
5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。
、人民币面值只有1,2,5?
通过以上分析我总结出如下结论:1,2,5可以组成任何面值.采用1、2、5制度可以保证组成任何金额时都不会超过三张钞票,方便结算
0 0
- 计算机专业面试题集 ----linux面试题
- linux 面试题
- linux面试题
- linux面试题参考答案
- Linux面试题(2)
- Linux面试题(1)
- linux 面试题
- Linux 面试题
- linux经典面试题
- Linux面试题大全
- [zt] linux面试题
- Linux面试题
- 《Linux面试题》
- linux面试题参考答案
- linux面试题
- Linux网络管理员面试题
- linux面试题参考答案
- 嵌入式linux面试题
- 推荐一本书《人体使用手册》
- Java 数据结构 --> Vector 类
- 使用canvas fingerprinting追踪用户信息
- 从AlexNet到squeezenet
- jq 查找控件
- linux面试题
- PowerDesigner导入sql文件
- python 乘法口诀
- MFC使用windows图片查看器
- MySQL中函数CONCAT&CONCAT_WS及GROUP_CONCAT
- 面试的那些事
- 动态绑定方法
- iOS开发多线程篇—GCD的常见用法
- Linux 退出Vi编辑器


