教育 | 学生群体分析
来源:互联网 发布:判断数据的优劣 编辑:程序博客网 时间:2024/04/28 02:49
什么是群体分析?
通俗的讲,就是一类人或者一类事情通过分析后,获得共同的特征属性或者特异的特征属性,是一种对群体画标签的方法。
那么,怎么进行群体分析呢?
第一步,要学会分群。可以使用机器学习算法中的分类与聚类等,当然也可以人为地对事物进行分类。
第二步,对分类好的数据进行分析,画出对应的标签。本文将使用人为分类的办法,对学霸与学渣在图书馆借书、图书馆出入情况进行分析,剖析出学霸与学渣借书的区别,用数据说明学渣是不是一定不去图书馆等问题。
一、数据准备
(一)表结构说明
加载已经对每个学生ID进行多维度画像的df表,df表的结构如下:
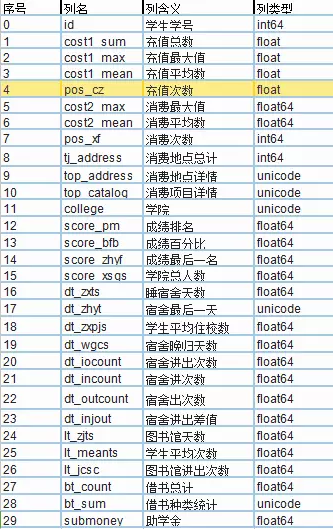
(二)记录条数说明
总共包含29列,总共记录条数为21605条,如下:

![]()
(三)记录内容说明
数据记录如下:
![]()
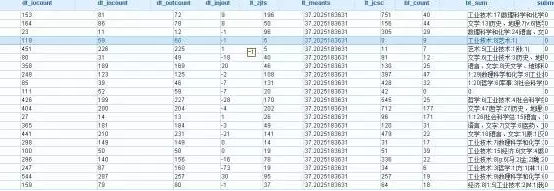
二、数据分类
(一)数据分类思路
根据学院和学生成绩的排名,取不同学院的前50名和后50名,对不同学院前50名的学霸组成一张表a,对不同学院倒数后50名的组合生成一张表b。分别对a、b表做异常数据的剔除,最后获得学霸和学渣数据各969条数。
(二)步骤
1、对导入FEA的df表做排序操作,排序的对象为college列和score_pm列,使用如下语句:
df=order df by (college,score_pm) with (desc,asc)
2、使用foreach循环,分别获取各学院的学霸与学渣记录;
3、组成a表和b表,并处理异常数据;
三、群体分析
(一)群体分析思路
第一种,取消费、住宿等维度的平均值进行比较。
第二种,只取学生成绩、学生图书馆借书、学生进出记录关联分析,抛开住宿、消费维度。
(二)分析过程
第一种我做过,结果如下:
![]()


![]()
比较结果无法区分学霸与学渣之间鲜明的特征,最大的两个特征是学渣获得的助学金多,学霸晚归次数比较多,消费平均数比较大。
去查找了为什么产生这种没有鲜明特征的原因,发现本次数据是经过脱敏处理的,学生成绩排名不分年级,不分专业,只是将所有成绩按学分加权求和,然后除以学分总和,再按照学生所在学院排序。所以,低年级学生怎么可能比高年级学生学分高啊?!
通过第一种思路的分析,说明我们本次数据准备并不完美,或者说本身就是有一定的错误存在。学霸的数据应该是高年级同学中的学霸,而不是学院中各年级各专业的学霸,学渣可能是低年级学渣占多数,而且过几年他们不一定是学渣。所以本次群体分析的立论,应该改为高年级学霸与低年级学渣比较合适。
通过第二种思路,我们只分析图书馆借书维度。先分析学霸和学渣中有多少人没有借过书?
![]()
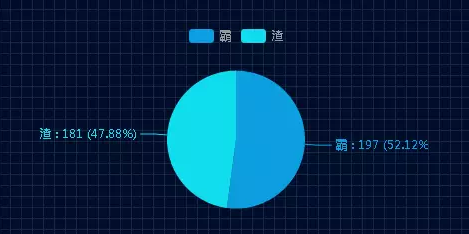
学霸有197人没有借书,学渣有181没有借书。再分析借书总数、平均数、借书人平均数等数据。

![]()
接着,分析学霸与学渣都关注哪种类型的书籍。
![]()
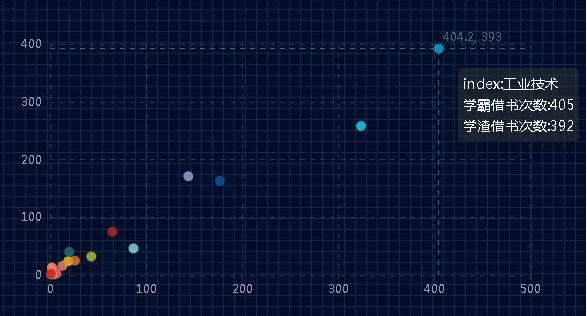
因为本数据来自工科类大学,所以工业技术类书籍占到第一。第二是文学类,第三语言与文字,第四数理化,第五是经济,第六是哲学,第七是政治法律,第八是历史,具体排名见最后图表。
最后,我们看一下借书类型的总次数。
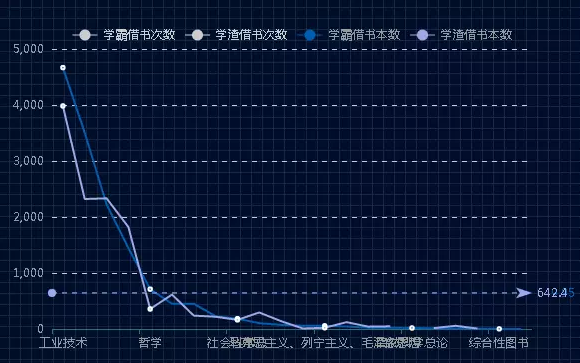
![]()
通过上图发现学渣同学比学霸借的书多,具体排名为:第一是语言、文学,第二是经济,第三是政治、法律。但是学霸与学渣借书的类型、数量上相差不大。
四、群体分析结论
通过上面分析,我们得出以下结论:
第一、学霸、学渣人数各969,但是学霸不借书的人数多于学渣;
第二、学霸借书平均数大于学渣;
第三、被分类到学渣类的同学去图书馆平均次数多于学霸,估计原因为高年级学霸到后期可能忙着找工作;
第四、被分类到学渣类的同学,比学霸更加关注经济、政治、法律、文字、语言类的书籍。
第五、从数据可以看出,学霸与学渣都是很努力学习的。
- 教育 | 学生群体分析
- 北川中学教师群体:一切都是为了学生
- 内容与顾客群体分析
- 博士可能是所有学生群体里被黑最猛烈的
- 黑客/病毒群体行为和产业链分析
- 产品推广的群体队列分析
- 寻找符合学生成长规律的教育
- 寻找符合学生发展规律的教育
- 学生教育与职业教育的思考
- 教育,老师,学生??(education teacher student)
- 数据分析-人群画像和目标群体分析
- Hiptype:分析电子书阅读习惯和读者群体
- 大数据分析下的户外媒体受众群体监测探索
- 信用卡年轻消费群体数据分析和洞察报告
- 教育培训行业现状分析
- 教育培训行业现状分析
- 网友曝西安一大学瞒学生群体盗办信用卡
- 开发者可适当开发适合8-13岁学生群体的app
- ubuntu下的chrome安装遇到的两个问题
- 23种设计模式之——责任链模式(okhttp 拦截器)
- 我的服务端之有限制使用Thread
- 告知你不为人知的UDP-连接性和负载均衡
- Git/综述
- 教育 | 学生群体分析
- LeetCode-22. Generate Parentheses
- java画图中文展示为方框、方块
- 告知你不为人知的UDP-疑难杂症和使用
- php正则表达式(手册)
- 动态开点线段树(Radio stations,762E)
- redis连接被拒绝
- 畸变校正详解
- 图之有权最短路径-迪杰斯特拉


