Spark:Yarn-cluster和Yarn-client区别与联系
来源:互联网 发布:21周胎儿发育标准数据 编辑:程序博客网 时间:2024/05/17 06:55
摘要
我们都知道Spark支持在yarn上运行,但是Spark on yarn有分为两种模式yarn-cluster和yarn-client,它们究竟有什么区别与联系?阅读完本文,你将了解。
问题导读
1.Spark在YARN中有几种模式?
2.Yarn Cluster模式,Driver程序在YARN中运行,应用的运行结果在什么地方可以查看?
3.由client向ResourceManager提交请求,并上传jar到HDFS上包含哪些步骤?
4.传递给app的参数应该通过什么来指定?
5.什么模式下最后将结果输出到terminal中?
Spark插拨式资源管理
Spark支持可插拔的集群管理模式(Standalone、Mesos以及YARN ),集群管理负责启动executor进程,编写Spark application 的人根本不需要知道Spark用的是什么集群管理。Spark支持的三种集群模式,这三种集群模式都由两个组件组成:master和slave。Master服务(YARN ResourceManager,Mesos master和Spark standalone master)决定哪些application可以运行,什么时候运行以及哪里去运行。而slave服务( YARN NodeManager, Mesos slave和Spark standalone slave)实际上运行executor进程。
Spark On Yarn的优势
mapreduce.job.jvm.numtasks。关于这个参数的介绍已经超过本篇文章的介绍。Yarn-cluster VS Yarn-client
从广义上讲,yarn-cluster适用于生产环境;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出。
从深层次的含义讲,yarn-cluster和yarn-client模式的区别其实就是Application Master进程的区别,yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。而yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。
Yarn-cluster:
Spark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况。
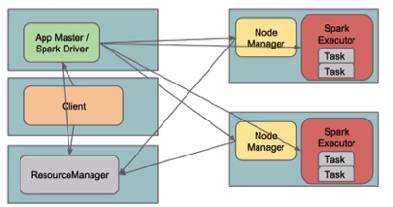
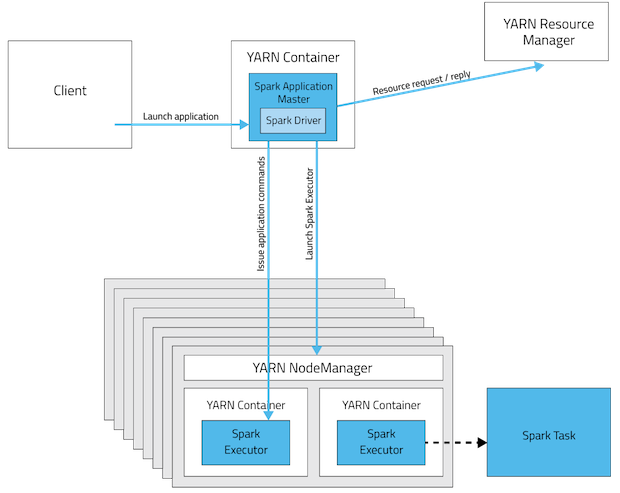

步骤如下:
这期间包括四个步骤:
a). 连接到RM
b). 从RM ASM(ApplicationsManager )中获得metric、queue和resource等信息。
c). upload app jar and spark-assembly jar
d). 设置运行环境和container上下文(launch-container.sh等脚本)
2. ResouceManager向NodeManager申请资源,创建Spark ApplicationMaster(每个SparkContext都有一个ApplicationMaster)
3. NodeManager启动Spark App Master,并向ResourceManager AsM注册
4. Spark ApplicationMaster从HDFS中找到jar文件,启动DAGscheduler和YARN Cluster Scheduler
5. ResourceManager向ResourceManager AsM注册申请container资源(INFO YarnClientImpl: Submitted application)
6. ResourceManager通知NodeManager分配Container,这时可以收到来自ASM关于container的报告。(每个container的对应一个executor)
7. Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。
需要注意的是:
a). Spark中的localdir会被yarn.nodemanager.local-dirs替换
b). 允许失败的节点数(spark.yarn.max.worker.failures)为executor数量的两倍数量,最小为3.
c). SPARK_YARN_USER_ENV传递给spark进程的环境变量
d). 传递给app的参数应该通过–args指定。
在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
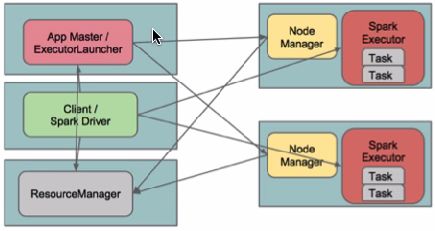

配置YARN-Client模式同样需要HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR变量。
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- spark学习-62-Spark:Yarn-cluster和Yarn-client区别与联系
- spark on yarn中yarn-cluster与yarn-client区别
- Spark-submit模式yarn-cluster和yarn-client的区别
- Spark下Yarn-Cluster和Yarn-Client的区别
- spark中yarn-client和yarn-cluster区别
- Spark Yarn-cluster 与 Yarn-client
- Spark on Yarn-cluster与Yarn-client
- Spark Yarn-cluster与Yarn-client
- ubuntu常用命令
- Android界面布局
- jQuery-Ajax
- 散列-PAT.A1078 Hashing
- 工具类库系列(十)-Object
- Spark:Yarn-cluster和Yarn-client区别与联系
- Java枚举的七种常见用法
- linux中vim的配置
- Makefile通用版
- vertica数据库备份与恢复
- iOS10从app跳转到WiFi设置界面
- Callable和Runnable
- 模板缓冲区
- 发现一个数组中重复的数字,448和287的总结 ---重要


