论XGBOOST科学调参
来源:互联网 发布:阿里云app备案 编辑:程序博客网 时间:2024/05/01 04:45
XGBOOST的威力不用赘述,反正我是离不开它了。
具体XGBOOST的原理可以参见之前的文章《比XGBOOST更快--LightGBM介绍》
今天说下如何调参。
bias-variance trade-off
xgboost一共有几十个参数:
http://xgboost.readthedocs.io/en/latest/parameter.html
中文版解释:
http://blog.csdn.net/zc02051126/article/details/46711047
文艺青年的调参一般这样的:
1. 设定参数{parm},评判指标{metrics};
2. 根据{metrics}在验证集上的大小,确定树的棵树n_estimators;
3. 采用参数{parm}、n_estimators,训练模型,并应用到测试集
一个字:糙!(kuai)
数据挖掘师的调参一般这样的:
设定基础参数{parm0},基础评判指标{metrics0};
在训练集上做cross-validation,做训练集/交叉验证集上偏差/方差与树棵树的关系图;
判断模型是过拟合 or 欠拟合,更新相应参数{parm1};
重复2、3步,确定树的棵树n_estimators;
采用参数{parm1}、n_estimators,训练模型,并应用到测试集;

数据集大小:70000*100,随机准确率 0.17%
在设置了基础参数,设定了树的范围后,可以看到模型在训练集和交叉验证集上的效果是这样子滴:
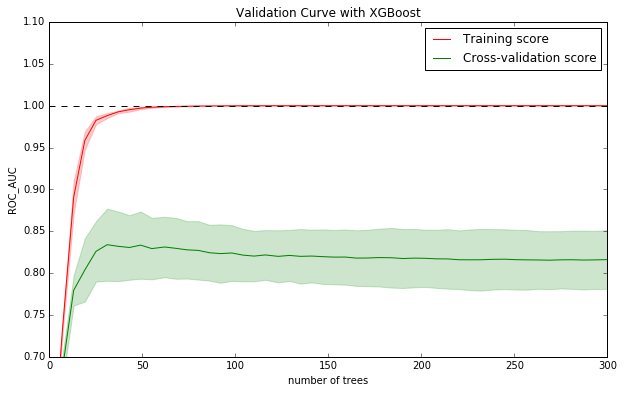
阴影部分,表示的是模型的方差
从上图,可以得出以下几个结论:
- 验证集上偏差最小&方差最小:n_estimators=66
- 训练集和验证集误差较大:过拟合-----模型过于复杂
- 方差较大----模型过于复杂
这符合下面这个图
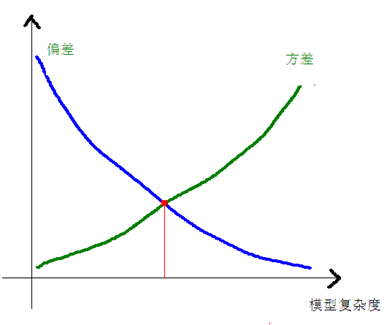
以上特征,都表明我们需要降低模型复杂程度,有哪些参数可以调整呢:
- 直接降低模型复杂度
max_depth、min_child_weight、gamma
- 随机化
subsample、colsample_bytree
- 正则化
lambda、alpha
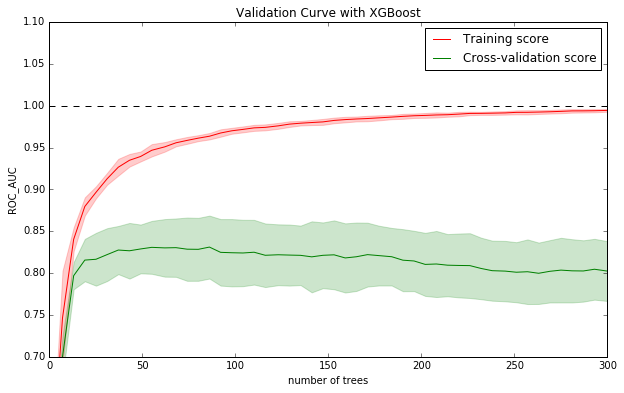
通过,grid-search,再调整了以上的参数后,如下图。最佳trade-off点的variance从0.361降低到0.316,auc_mean从0.8312降低到0.8308。
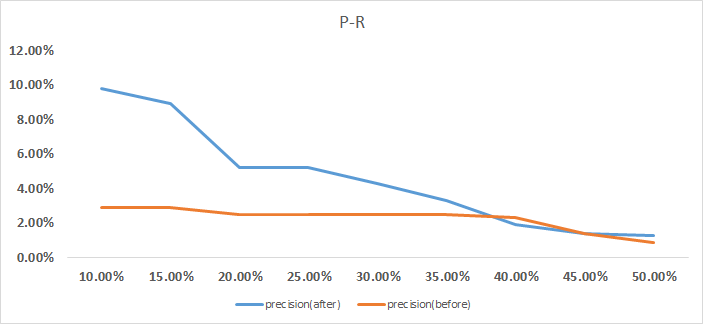
P-R的提升还是比较明显的:
还有,先粗调,再微调
-- 降低learning_rate,当然同时,提高n_estimators
2. 非平衡数据集怎么办
-- 想办法弄到更多的数据
-- 想办法把数据弄平衡
-- 利用smote等算法来过采样/欠采样
-- 设置weight(初始化DMatrix时)
-- 使用更好的metrics:auc、f1
-- min_child_weight 设的小一点
-- scale_pos_weight = 0值的样本数量/1值的样本数量
-- max_delta_step
-- 自定义评价函数
xgb.train(params, dtrain, num_rounds, watchlist, feval=misclassified, maximize=False)
def misclassified(pred_probs, dtrain): labels = dtrain.get_label() # obtain true labels preds = pred_probs > 0.5 # obtain predicted values return 'misclassified', np.sum(labels != preds)对数据感兴趣的小伙伴,欢迎交流,微信公共号:一白侃数
- 论XGBOOST科学调参
- xgboost 调参经验
- xgboost使用调参
- xgboost 调参经验
- xgboost 调参经验
- XGBoost简易调参指南
- python-xgboost调参经验
- XGBoost python调参指南
- XGBoost python调参示例
- 数据科学入门,使用 xgboost 初试 kaggle
- python 科学计算环境安装(xgboost)
- XGboost 调参指南+CV调参
- RF,GBDT,xgboost调参方法整理
- gbdt和xgboost的调参模板
- XGBoost算法原理简介及调参
- XGBoost模型调优
- XGBoost参数调优
- XGBoost参数调优
- ## 2017.02.18队内胡策(三) 斗地主 ##暴力模拟
- Android Studio versionCode 自增 打包命名
- 数据分析利器之hive优化十大原则
- 比XGBOOST更快--LightGBM介绍
- 210. Course Schedule II
- 论XGBOOST科学调参
- Android面试(1)
- HDU2083 简易版之最短路径
- 开源PLM软件Aras详解七 在Aras的Method中如何引用外部DLL
- 【Codeforces Round #398 (Div. 2)】Codeforces 767E Change-free
- Java日期相关随手笔记
- 深度学习论文笔记:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- AtCoder Beginner Contest 055
- Object的notify(),wait()


