How Apache Zeppelin runs a paragraph
来源:互联网 发布:c语言中二维数组在内存 编辑:程序博客网 时间:2024/06/07 11:42
转发一篇zeppelin的主力committer Jongyoul Lee的讲解zeppelin的paragraph的运行机制的文章,原文地址:https://medium.com/apache-zeppelin-stories/how-apache-zeppelin-runs-a-paragraph-783a0a612ba9#.a85u5nlh4
Apache Zeppelin is one of the most popular open source projects. It helps users create their own notebooks easily and share some of reports simply. Most of users appreciate Apache Zeppelin’s functionality and extensibility. Most of contributors and administrators, however, shared their experience of having difficulties while debugging Apache Zeppelin because of its complicated structure. This post will describe how Apache Zeppelin handles users’ requests to run paragraphs from server module to interpreters.
Before diving into details, I’ll clarify some terms that would help you in understanding of this article. The first term is paragraph. It is a minimum unit to be executed. The second one is note which is a set of paragraphs, and also a member of notebook. Thus one instance has only one notebook which has many notes. You can see a notebook in a home page. 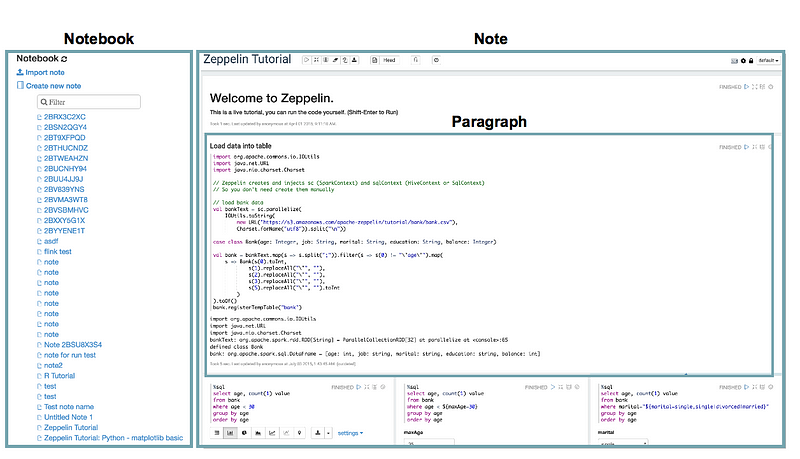
We also need to know what an interpreter is. Interpreter of Apache Zeppelin is the gateway to connect specific framework to run actual code. For instance, SparkInterpreter is a gateway to run Apache Spark, and JDBCInterpreter supports to handle JDBC drivers. Apache Zeppelin has 19 interpreters on a master branch.
The server module of Apache Zeppelin consists of three parts: handling rest/websocket, storing and loading data, and managing interpreters. This post will focus on the last one of managing interpreters. But it will help you understand whole path for running a paragraph. There’re two entry points for running paragraphs.
/** * Run asynchronously paragraph job REST API * * @param message - JSON with params if user wants to update dynamic form's value * null, empty string, empty json if user doesn't want to update * @return JSON with status.OK * @throws IOException, IllegalArgumentException */ @POST @Path("job/{notebookId}/{paragraphId}") @ZeppelinApi public Response runParagraph(@PathParam("notebookId") String notebookId, @PathParam("paragraphId") String paragraphId, String message) throws IOException, IllegalArgumentException { LOG.info("run paragraph job asynchronously {} {} {}", notebookId, paragraphId, message); Note note = notebook.getNote(notebookId); if (note == null) { return new JsonResponse<>(Status.NOT_FOUND, "note not found.").build(); } Paragraph paragraph = note.getParagraph(paragraphId); if (paragraph == null) { return new JsonResponse<>(Status.NOT_FOUND, "paragraph not found.").build(); } // handle params if presented handleParagraphParams(message, note, paragraph); note.run(paragraph.getId()); return new JsonResponse<>(Status.OK).build(); }NotebookRestApi.java on github
private void runParagraph(NotebookSocket conn, HashSet<String> userAndRoles, Notebook notebook, Message fromMessage) throws IOException { final String paragraphId = (String) fromMessage.get("id"); if (paragraphId == null) { return; } String noteId = getOpenNoteId(conn); final Note note = notebook.getNote(noteId); NotebookAuthorization notebookAuthorization = notebook.getNotebookAuthorization(); if (!notebookAuthorization.isWriter(noteId, userAndRoles)) { permissionError(conn, "write", fromMessage.principal, userAndRoles, notebookAuthorization.getWriters(noteId)); return; } Paragraph p = note.getParagraph(paragraphId); String text = (String) fromMessage.get("paragraph"); p.setText(text); p.setTitle((String) fromMessage.get("title")); if (!fromMessage.principal.equals("anonymous")) { AuthenticationInfo authenticationInfo = new AuthenticationInfo(fromMessage.principal, fromMessage.ticket); p.setAuthenticationInfo(authenticationInfo); } else { p.setAuthenticationInfo(new AuthenticationInfo()); } Map<String, Object> params = (Map<String, Object>) fromMessage .get("params"); p.settings.setParams(params); Map<String, Object> config = (Map<String, Object>) fromMessage .get("config"); p.setConfig(config); // if it's the last paragraph, let's add a new one boolean isTheLastParagraph = note.isLastParagraph(p.getId()); if (!(text.trim().equals(p.getMagic()) || Strings.isNullOrEmpty(text)) && isTheLastParagraph) { note.addParagraph(); } AuthenticationInfo subject = new AuthenticationInfo(fromMessage.principal); note.persist(subject); try { note.run(paragraphId); } catch (Exception ex) { LOG.error("Exception from run", ex); if (p != null) { p.setReturn( new InterpreterResult(InterpreterResult.Code.ERROR, ex.getMessage()), ex); p.setStatus(Status.ERROR); broadcast(note.getId(), new Message(OP.PARAGRAPH).put("paragraph", p)); } } }NotebookServer.java on github
In the two above methods, those call note.run(id) at the end of the methods, that method finds an actual paragraph from id and submits the paragraph into the scheduler of an interpreter parsed by paragraph and note. This is the flow of the front-side.
/** * Run a single paragraph. * * @param paragraphId ID of paragraph */ public void run(String paragraphId) { Paragraph p = getParagraph(paragraphId); p.setListener(jobListenerFactory.getParagraphJobListener(this)); String requiredReplName = p.getRequiredReplName(); Interpreter intp = factory.getInterpreter(getId(), requiredReplName); if (intp == null) { String intpExceptionMsg = p.getJobName() + "'s Interpreter " + requiredReplName + " not found"; InterpreterException intpException = new InterpreterException(intpExceptionMsg); InterpreterResult intpResult = new InterpreterResult(InterpreterResult.Code.ERROR, intpException.getMessage()); p.setReturn(intpResult, intpException); p.setStatus(Job.Status.ERROR); throw intpException; } if (p.getConfig().get("enabled") == null || (Boolean) p.getConfig().get("enabled")) { intp.getScheduler().submit(p); } }Note.java on github
Through the code above, you can guess the relationship between a note and interpreters in a code level. Every note has its own interpreters’ mapping and stores it into interpreterFactory, every interpreter has its own scheduler and runs a paragraph from the scheduler, and the status of paragraph is managed by jobListenerFactory. Concerning jobListenerFactory, I’ll write another post for the lifecycle of paragraph.
For the first step to understand interpreter, we should know how to initialize interpreters when Apache Zeppelin starts up. InterpreterFactory manages the lifecycle of interpreters. When you start up the server, InterpreterFactory initializes with two major steps. The first is to read the directory of ${ZEPPELIN_HOME}/interpreter which has many sub directories that have all of jars including third party’s frameworks. InterpreterFactory makes the list of available interpreters with default configuration, and which is used to make a new interpreter setting. Secondly, InterpreterFactory reads ${ZEPPELIN_HOME}/conf/interpreter.json which stores actual configurations of interpreters and includes mapping between notes and interpreters. This is same information in an interpreter tab of UI. It finishes with preparation on running a paragraph by interpreterFactory. Here is the link of the code:
Before proceeding into the next step, you should know how Apache Zeppelin launches an interpreter. The main purpose of supporting different modes is to manage memory usage and overload of CPUs efficiently. No one wants to run MarkdownInterpreter per note, but most of users would like to run SparkInterpreter with their own instances. Apache Zeppelin supports three modes for managing interpreters. Shared mode is a traditional model. this mode shares all of resources. If you use SparkInterpreter with this mode, all running paragraph use one Spark instance. Scoped mode has different class loader in a same process. This mode will enable note to own separate resources within a same process. In case of using JDBCInterpreter, every note has its own connection. Isolated mode means that all notes can run paragraphs in different processes. There are two main functions to decide a mode.
private String getInterpreterProcessKey(String noteId) { if (getOption().isExistingProcess) { return Constants.EXISTING_PROCESS; } else if (getOption().isPerNoteProcess()) { return noteId; } else { return SHARED_PROCESS; } }InterpreterSetting.java on github
private String getInterpreterInstanceKey(String noteId, InterpreterSetting setting) { if (setting.getOption().isExistingProcess()) { return Constants.EXISTING_PROCESS; } else if (setting.getOption().isPerNoteSession() || setting.getOption().isPerNoteProcess()) { return noteId; } else { return SHARED_SESSION; } }InterpreterFactory.java on github
Now, we will look into the method of getInterpreter. Basically, it returns an interpreter which runs a paragraph. To determine specific interpreter, this function has three steps. You will encounter a new term called replName when you dig into the code. It is sort of alias to call a specific interpreter. According to the type of replName, getInterpreter chooses different values. If it’s null, it returns a default interpreter. If it doesn’t have any comma, getInterpreter treats it as a name of default interpreter group. For example, “%pyspark” means as same as “%spark.pyspark”. At last, it has two words separated by dot, getInterpreter handles it as “%{group_name}.{interpreter_name}” and returns a specific interpreter. Here is the link of the code:
Another function of getInterpreter is to make a RemoteInterpreter. Apache Zeppelin launches different processes for different interpreters and manages them via Apache Thrift. It is to avoid conflicts among different interpreters’ dependencies. If the result interpreter is never called before, getInterpreter will make a RemoteInterpreter for that interpreter. RemoteInterpreter is a wrapper including Thrift client interface and a connector between a server process and interpreter processes.
It’s time to find where a paragraph is executed. Let’s go back to note.run(id). that method calls intp.getScheduler().submit(p) at the end. Paragraph implements Job interface, and scheduler will execute Job one by one. If some paragraphs are submitted into the scheduler of an interpreter, the scheduler will run Paragraph.jobRun().
@Override protected Object jobRun() throws Throwable { String replName = getRequiredReplName(); Interpreter repl = getRepl(replName); logger.info("run paragraph {} using {} " + repl, getId(), replName); if (repl == null) { logger.error("Can not find interpreter name " + repl); throw new RuntimeException("Can not find interpreter for " + getRequiredReplName()); } if (this.noteHasUser() && this.noteHasInterpreters()) { InterpreterSetting intp = getInterpreterSettingById(repl.getInterpreterGroup().getId()); if (intp != null && interpreterHasUser(intp) && isUserAuthorizedToAccessInterpreter(intp.getOption()) == false) { logger.error("{} has no permission for {} ", authenticationInfo.getUser(), repl); return new InterpreterResult(Code.ERROR, authenticationInfo.getUser() + " has no permission for " + getRequiredReplName()); } } String script = getScriptBody(); // inject form if (repl.getFormType() == FormType.NATIVE) { settings.clear(); } else if (repl.getFormType() == FormType.SIMPLE) { String scriptBody = getScriptBody(); Map<String, Input> inputs = Input.extractSimpleQueryParam(scriptBody); // inputs will be built // from script body final AngularObjectRegistry angularRegistry = repl.getInterpreterGroup() .getAngularObjectRegistry(); scriptBody = extractVariablesFromAngularRegistry(scriptBody, inputs, angularRegistry); settings.setForms(inputs); script = Input.getSimpleQuery(settings.getParams(), scriptBody); } logger.debug("RUN : " + script); try { InterpreterContext context = getInterpreterContext(); InterpreterContext.set(context); InterpreterResult ret = repl.interpret(script, context); if (Code.KEEP_PREVIOUS_RESULT == ret.code()) { return getReturn(); } String message = ""; context.out.flush(); InterpreterResult.Type outputType = context.out.getType(); byte[] interpreterOutput = context.out.toByteArray(); if (interpreterOutput != null && interpreterOutput.length > 0) { message = new String(interpreterOutput); } if (message.isEmpty()) { return ret; } else { String interpreterResultMessage = ret.message(); if (interpreterResultMessage != null && !interpreterResultMessage.isEmpty()) { message += interpreterResultMessage; return new InterpreterResult(ret.code(), ret.type(), message); } else { return new InterpreterResult(ret.code(), outputType, message); } } } finally { InterpreterContext.remove(); } }Paragraph.java on github
It looks complicated but we focus on repl.interpret(script, context) only. Paragraph gets repl by calling getInterpreter and run the method of interpret. Then RemoteInterpreter will pass the script and context into Interpreter on a different process and obtain the result from another process.
It’s very basic flow about running paragraph and this article skipped some steps for your understanding. through this article, I tried to describe how Apache Zeppelin selects correct interpreter and how an interpreter gets a script and executes it. there are also many new concepts that I didn’t explain. I’ll explain them with another article. Apache Zeppelin is emerging project and changes so fast. I, however, hope this article helps you understand Apache Zeppelin more, and contribute to Apache Zeppelin easily.
- How Apache Zeppelin runs a paragraph
- $watch How the $apply Runs a $digest
- $watch How the $apply Runs a $digest
- How-to: Install Apache Zeppelin on CDH
- Zeppelin源码阅读之更新notebook的paragraph部分
- Apache Zeppelin简介
- centos apache zeppelin install
- Apache Zeppelin简介
- 什么是Apache Zeppelin?
- Apache Zeppelin安装
- Apache Zeppelin配置
- keylogger, runs as a Service
- Learning Python(1) How python program runs
- 「zeppelin」: java.lang.NoSuchMethodError: org.apache.hadoop.tracing.SpanReceiverHost.get(Lorg/a
- Apache Zeppelin安装及介绍
- Apache Zeppelin安装及介绍
- Apache Zeppelin设置访问登录
- Apache Zeppelin安装及使用
- html之marquee详解
- windows环境下java本地连接aws开发
- CentOS 7 安装教程、硬盘分区、LVM、网络配置、软件源配
- 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
- 操作系统实验及代码(全)
- How Apache Zeppelin runs a paragraph
- Android开发——UI_活动
- linux下更新GTK+到3.x60
- HDU 1978 How many ways,动态规划
- 如何用git将项目代码上传到github
- jsp与html+velocity
- Java回调机制
- WindowsForm窗体位置
- java调用wsdl(jdk自带、axis2)


