深度学习基础之:理解卷积学习笔记 (一):卷积
来源:互联网 发布:mac怎么打中文 编辑:程序博客网 时间:2024/06/06 19:58
目的:
为更深入的研究和探索卷积神经网络,以便实现结构和理论上的创新。 为了做到这一点,我们需要非常深刻地理解卷积。
1.colah's blog: Understanding Convolutions
Lessons from a Dropped Ball
Imagine we drop a ball from some height onto the ground, where it only has one dimension of motion. How likely is it that a ball will go a distance
Let’s break this down. After the first drop, it will land
Now after this first drop, we pick the ball up and drop it from another height above the point where it first landed. The probability of the ball rolling
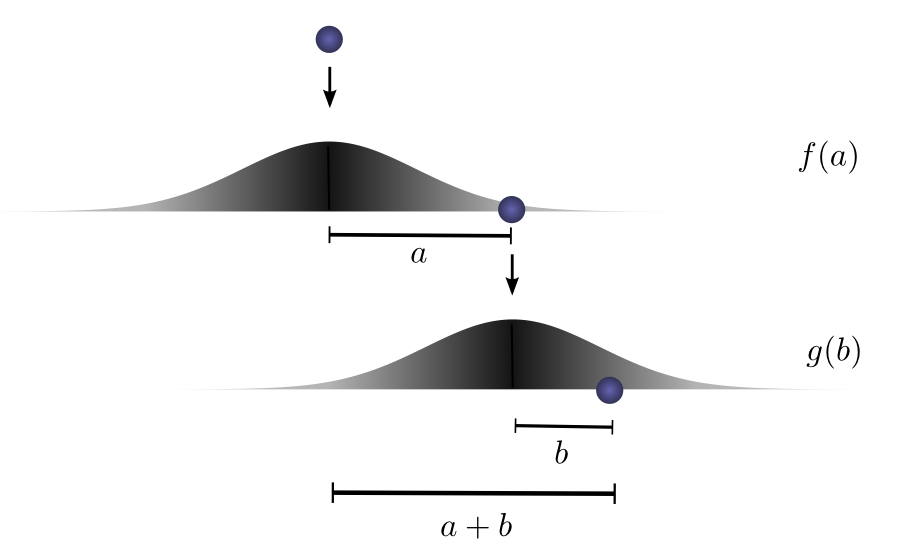
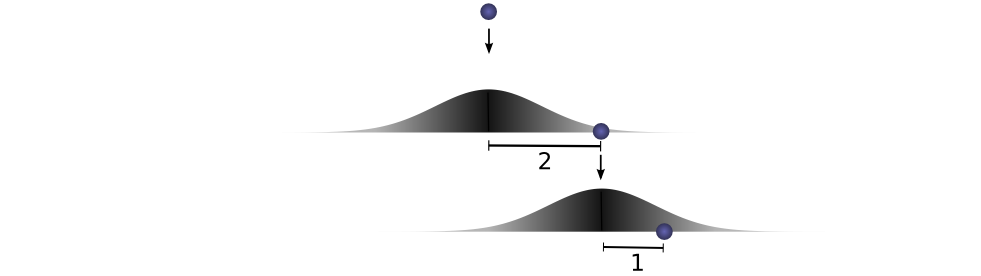
If we fix the result of the first drop so we know the ball went distance
Let’s think about this with a specific discrete example. We want the total distance
However, this isn’t the only way we could get to a total distance of 3. The ball could roll 1 units the first time, and 2 the second. Or 0 units the first time and all 3 the second. It could go any
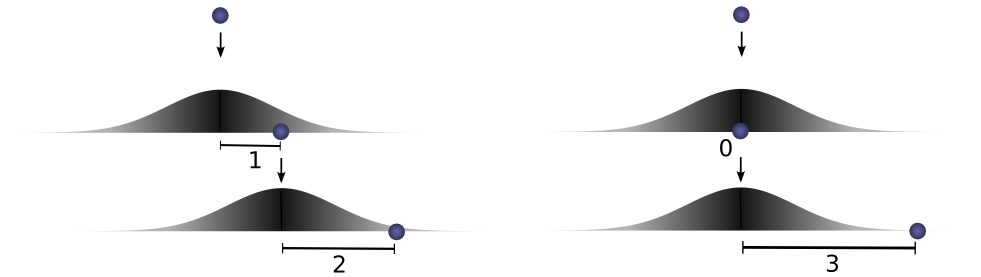
The probabilities are
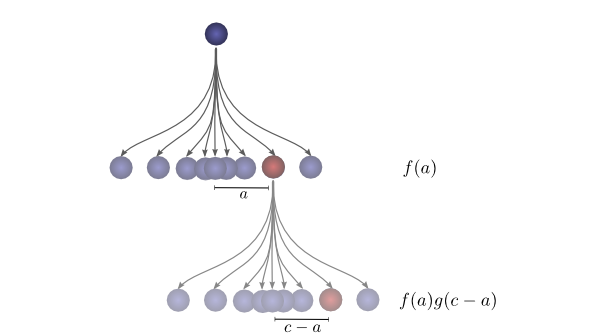
In order to find the total likelihood of the ball reaching a total distance of
We already know that the probability for each case of
Turns out, we’re doing a convolution! In particular, the convolution of
If we substitute
This is the standard definition2 of convolution.
To make this a bit more concrete, we can think about this in terms of positions the ball might land. After the first drop, it will land at an intermediate position
To get the convolution, we consider all intermediate positions.
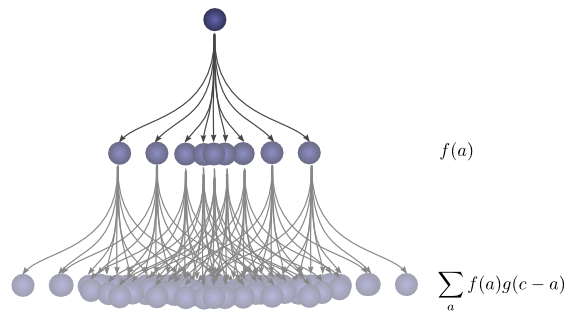
Visualizing Convolutions
There’s a very nice trick that helps one think about convolutions more easily.
First, an observation. Suppose the probability that a ball lands a certain distance
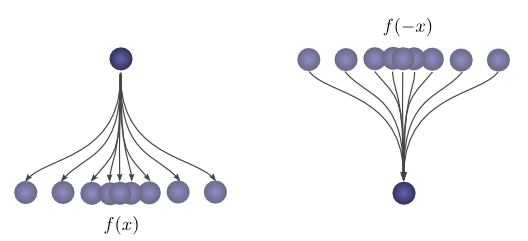
If we know the ball lands at a position
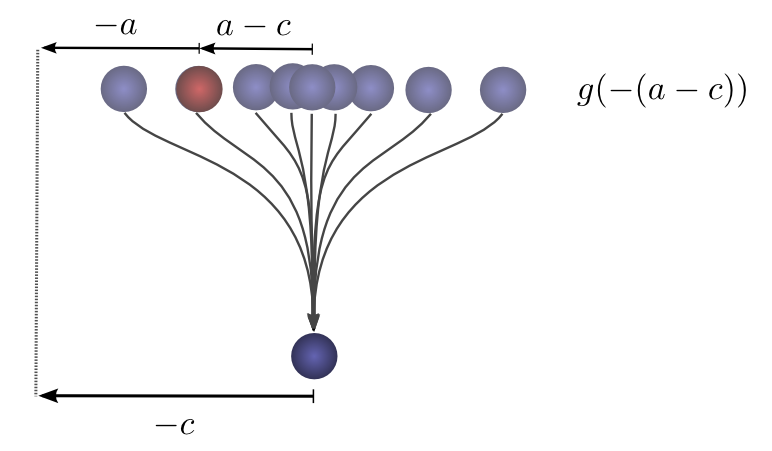
So the probability that the previous position was
Now, consider the probability each intermediate position contributes to the ball finally landing at
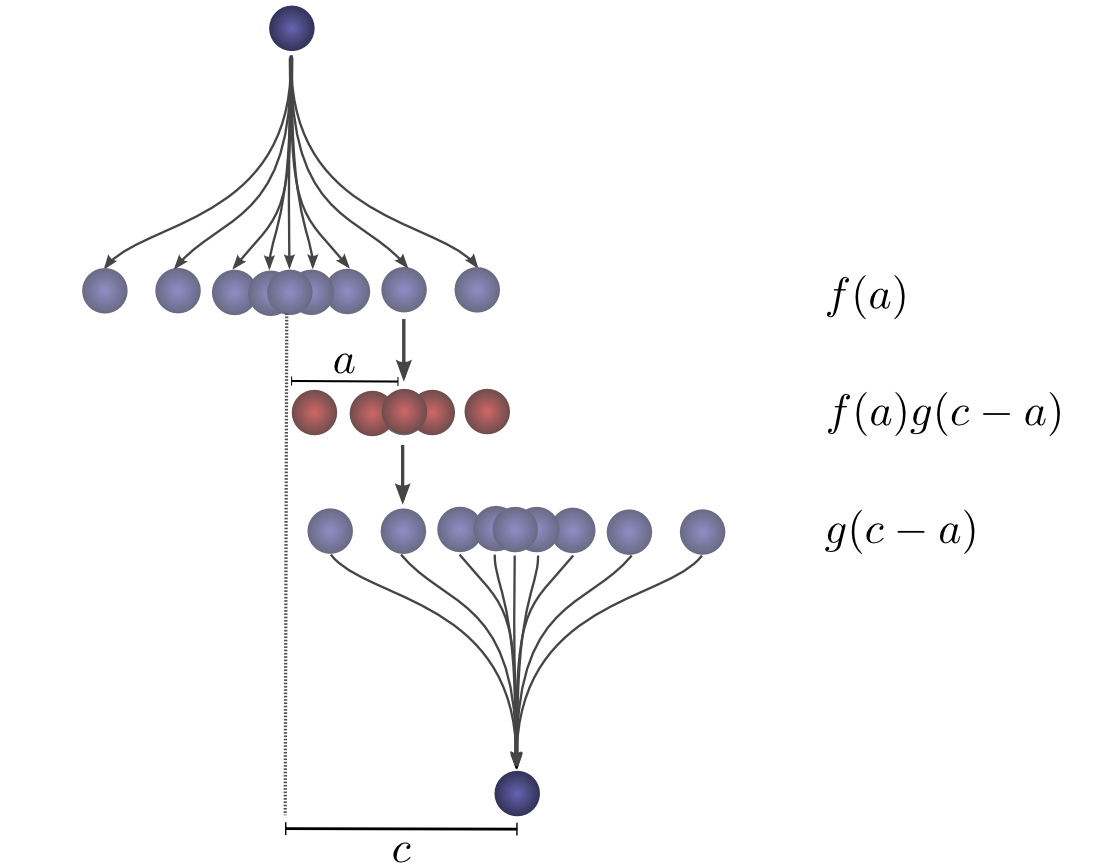
Summing over the
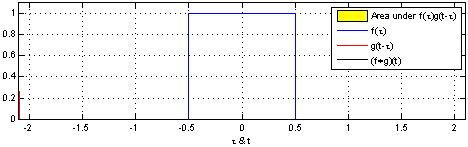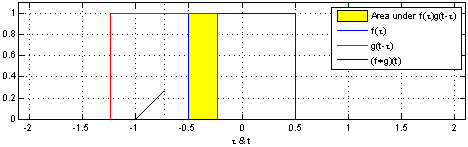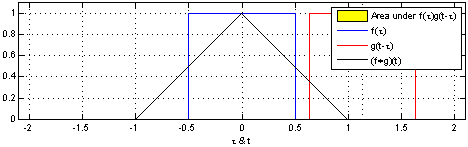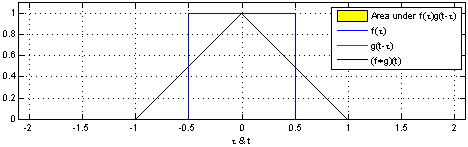
The advantage of this approach is that it allows us to visualize the evaluation of a convolution at a value
For example, we can see that it peaks when the distributions align.
And shrinks as the intersection between the distributions gets smaller.
By using this trick in an animation, it really becomes possible to visually understand convolutions.
Below, we’re able to visualize the convolution of two box functions:
Armed with this perspective, a lot of things become more intuitive.
Let’s consider a non-probabilistic example. Convolutions are sometimes used in audio manipulation. For example, one might use a function with two spikes in it, but zero everywhere else, to create an echo. As our double-spiked function slides, one spike hits a point in time first, adding that signal to the output sound, and later, another spike follows, adding a second, delayed copy.
2.CNN:笔记通俗理解卷积神经网络
sigmoid的函数表达式如下

其中z是一个线性组合,比如z可以等于:b + 



因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):

也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常大的负数时,则g(z)会趋近于0。
压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
举个例子,如下图(图引自Stanford机器学习公开课)

z = b +
- 如果
- 如果
- 如果
换言之,只有
CNN之卷积计算层
4.1 什么是卷积

对应位置上是数字先相乘后相加
=

4.2 图像上的卷积
如下图所示

4.3 GIF动态卷积图
a. 深度depth:神经元个数,决定输出的depth厚度。
b. 步长stride:决定滑动多少步可以到边缘
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。

- 两个神经元,即depth=2
- 数据窗口每次移动两个步长取3*3的局部数据,即stride=2
- zero-padding=1

随着左边数据窗口的平移滑动,滤波器Filter w0 / Filter w1对不同的局部数据进行卷积计算。
值得一提的是:
- 左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
- 与此同时,数据窗口滑动,但中间滤波器Filter w0的权重(即每个神经元连接数据窗口的权重)是固定不变的,这个权重不变即所谓的CNN中的参数(权重)共享机制。
我第一次看到上面这个动态图的时候,只觉得很炫,另外就是据说计算过程是“相乘后相加”,但到底具体是个怎么相乘后相加的计算过程 则无法一眼看出,网上也没有一目了然的计算过程。本文来细究下。
首先,我们来分解下上述动图,如下图

接着,我们细究下上图的具体计算过程。即上图中的输出结果-1具体是怎么计算得到的呢?其实,类似wx + b,w对应滤波器Filter w0,x对应不同的数据窗口,b对应Bias b0,相当于滤波器Filter w0与一个个数据窗口相乘再求和后,最后加上Bias b0得到输出结果-1,如下过程所示:
1* 0 + 1*0 + -1*0
+
-1*0 + 0*0 + 1*1
+
-1*0 + -1*0 + 0*1
+
-1*0 + 0*0 + -1*0
+
0*0 + 0*1 + -1*1
+
1*0 + -1*0 + 0*2
+
0*0 + 1*0 + 0*0
+
1*0 + 0*2 + 1*0
+
0*0 + -1*0 + 1*0
+
![]()
1
=
1






然后滤波器Filter w0固定不变,数据窗口向右移动2步,继续做内积计算,得到0的输出结果

最后,换做另外一个不同的滤波器Filter w1、不同的偏置Bias b1,再跟图中最左边的数据窗口做卷积,可得到另外一个不同的输出。

CS231n课程笔记翻译:卷积神经网络笔记
作一个合理的假设:如果一个特征在计算某个空间位置(x,y)的时候有用,那么它在计算另一个不同位置(x2,y2)的时候也有用。基于这个假设,可以显著地减少参数数量。换言之,就是将深度维度上一个单独的2维切片看做深度切片(depth slice),比如一个数据体尺寸为[55x55x96]的就有96个深度切片,每个尺寸为[55x55]。在每个深度切片上的神经元都使用同样的权重和偏差。在这样的参数共享下,例子中的第一个卷积层就只有96个不同的权重集了,一个权重集对应一个深度切片,共有96x11x11x3=34,848个不同的权重,或34,944个参数(+96个偏差)。在每个深度切片中的55x55个权重使用的都是同样的参数。在反向传播的时候,都要计算每个神经元对它的权重的梯度,但是需要把同一个深度切片上的所有神经元对权重的梯度累加,这样就得到了对共享权重的梯度。这样,每个切片只更新一个权重集。
注意,如果在一个深度切片中的所有权重都使用同一个权重向量,那么卷积层的前向传播在每个深度切片中可以看做是在计算神经元权重和输入数据体的卷积(这就是“卷积层”名字由来)。这也是为什么总是将这些权重集合称为滤波器(filter)(或卷积核(kernel)),因为它们和输入进行了卷积。
形象理解权值共享就是说:对输入图像,采用一个滤波核去扫这张图,在滑动卷积的时候,这个滤波器的参数是不变的,权重是一样的,即整幅图像共享一组权值。
- 深度学习基础之:理解卷积学习笔记 (一):卷积
- 深度学习-卷积理解
- 深度学习之卷积
- 吴恩达深度学习笔记之卷积神经网络(卷积网络)
- 深度学习之卷积神经网络学习摘录(一)
- Deep Learning(深度学习)学习笔记整理系列之LeNet-5卷积参数个人理解
- Deep Learning(深度学习)学习笔记整理系列之LeNet-5卷积参数个人理解
- Deep Learning(深度学习)学习笔记整理系列之LeNet-5卷积参数个人理解
- Deep Learning(深度学习)学习笔记整理系列之LeNet-5卷积参数个人理解
- Deep Learning(深度学习)学习笔记整理系列之LeNet-5卷积参数个人理解
- 小象学院深度学习笔记2(卷积神经网络-基础)
- 理解深度学习中的卷积
- 理解深度学习中的卷积
- 理解深度学习中的卷积
- 深度学习UFLDL教程翻译之卷积神经网络(一)
- 深度学习入门之(一)卷积神经网络
- 深度学习:卷积神经网络基础
- 深度学习阅读笔记(四)之卷积网络CNN
- C++Primer第五版 第九章习题答案(31~40)
- DecimalFormat format 方法
- 欢迎使用CSDN-markdown编辑器
- poj 1236 Network of School (加边成强连通分量)
- 什么是event handlers ?
- 深度学习基础之:理解卷积学习笔记 (一):卷积
- linux平时常用的软件
- hdu1281(二分图匹配)
- Apache Ambari 2.4.2 安装指南
- Android自定义View(十二)_ Matrix详解
- PhotoView单击事件
- 数据结构---------插入排序和希尔排序
- JMM 理解java内存模型
- 前端小知识集合


