用深度学习方法做topic modeling
来源:互联网 发布:php 查找字符串的位置 编辑:程序博客网 时间:2024/06/05 00:25
深度学习也可以做topic modeling
4个月前想好好学学LDA的求解原理,发现还是很困难,用Gibbs Sampling以及一些variant方法解决问题的过程是知道了,但是依然不能很好的明白会什么这么做会有效,以及为什么会想到要那么做。
之后就去研究深度学习了,现在回过头来,发现其实用深度学习,也可以做topic modeling,而且从实验结果来说,要比LDA的效果,好太多了。
LDA产生的结果,是bag-of-words数据的软聚类,同时生成文档对主题的稀疏表示。
事实上,我们同样可以用autoencoder产生好的效果。
autoencoder结构非常简单, 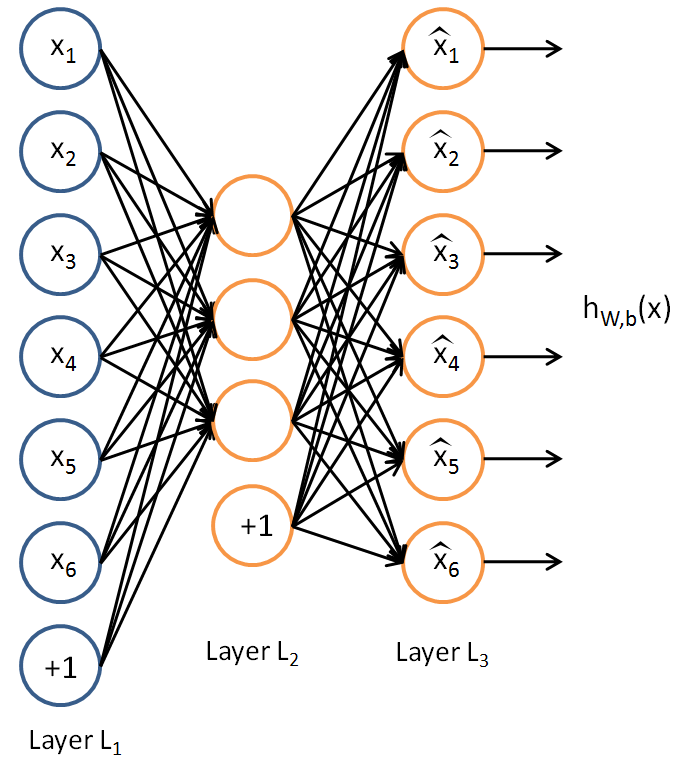
输入的是bag-of-words的稀疏向量,输出的也是一个稀疏向量,误差就是这两个向量之间的差距,即损失函数。
对训练之后得到的latent vector,进行聚类,就可以得到我们想要的topic modeling。
用news20group数据集,评测生成的topic结果,metric用的是Homogeneity and completeness scores 



n是总样本数,
用scikit-learn中的LDA跑出来的结果,大概是0.18左右。
用keras实现的autoencoder跑出来的结果,大概是0.15,效果比LDA还要差。
仔细分析一下模型,可以发现一个问题。
autoencoder的损失函数,用的是图像中常用的的损失函数,
事实上,文档中的词语假设为200的话,总单词表的数目为20000的话,那么稀疏程度就是0.01。相当于mnist中,20*20的图片里面,只有4个点是非零的。但是autoencoder认为每个输入单元的重要性是一致的,但是对于bag-of-words来说,重要的是那些非零输入单元。
因此我们需要想办法把提高非零输入单元的权重。
也许加入sample weights是一个办法,但是操作起来很麻烦。
另一种很实用的方法,实际上是更换损失函数。
KL Divergence衡量的是两个概率分布之间的相似度,我们可以把文档中的词权重,看作是一种分布。 
换成KL Divergence有什么好处呢,注意到上式有一个P(i),一篇文档内,大部分的词出现的概率恰恰为零,因此这些输入单元不对损失函数产生影响,损失函数只考虑不为零的输入单元。这就很好的起到了,加权的作用。
当然我们同时要把输出层的activation进行更换为softmax,才能保证输出的是一个概率分布。
更换之后,评测结果就直接变成了0.73,一个跨度很大的提升。
因为autoencoder训练得到的是一个dense的latent vector,所以我们还可以拿这个latent vector做其他事情,比如text retrieval。
还有一个有趣的点是,我们能不能学习binary latent vector,因为binary是很吸引人的,可以极大的减少存储空间,同时提高计算相似度时的效率(用hamming distance)。
答案是肯定的,将latent vector层的激活函数换成修改过的sigmoid,
评测结果会降到0.68,但是存储和计算都可以得到很大的提高。
不过即使得到binary的latent vector,我也没有找到对binary vector进行优化过的聚类库,C++没有,python也没有。
看来需要自己实现一个了。
- 用深度学习方法做topic modeling
- 用GibbsLDA做Topic Modeling
- Topic modeling LDA by Blei
- LTM(Lifelong Topic Modeling)介绍
- Topic modeling made just simple enough
- Introduction to Topic Modeling learning(链)
- Stanford Topic Modeling Toolbox0.4.0翻译
- 做AI必须要知道的十种深度学习方法
- 做AI必须要知道的十种深度学习方法
- 做AI必须要知道的十种深度学习方法
- 做AI必须要知道的十种深度学习方法
- 【深度学习】做AI必须要知道的十种深度学习方法
- KDD 2011的关于topic modeling的Tutorial
- Topic Modeling 学习——基本概念的理解
- #Paper Reading# Lifelong Machine Learning for Topic Modeling and Beyond
- #Paper Reading# Fast Online EM for Big Topic Modeling
- Targeted Topic Modeling for Focused Analysis(TTM的理解)
- 阅读文章:Incorporating Knowledge Graph Embeddings into Topic Modeling
- python 线性表的链式存储
- atoi 字串转换为数字
- 用Python模拟键盘输入
- 微信小程序瀑布流的实现
- 简单的RBAC用户角色权限控制
- 用深度学习方法做topic modeling
- 自定义协议封装包头、包体
- Oracle导入dmp文件,Oracle创建数据库
- geth的使用入门
- Jenkins:slave启动方式
- 私货
- Git命令
- [IOS APP]伪装者-GPS位置自定义,修改以及分享
- c/c++判断字符串是否为回文


