hadoop第二次作业
来源:互联网 发布:pdf批量转换jpg mac 编辑:程序博客网 时间:2024/05/29 15:12
- 文件读取
客户端通过调用 FileSystem 对象的 open() 方法来打开想读取的文件,对于 HDFS 来说,这个对象是分布式文件系统(DistributedFileSystem)的一个实例,如上图步骤1。
DistributedFileSystem 通过使用 RPC 来调用 namenode ,获取文件的存储位置,以确定文件起始块的位置,如上图步骤2。namenode 返回文件所有组成块的副本的 datanode 地址。并且这些 datanode 地址信息是已经排过序的。
DistributedFileSystem 的 open() 方法返回一个 FSDataInputStream 对象给客户端读取数据。FSDataInputStream 类封装了DFSInputStream 对象,该对象管理着 datanode 和 namenode 的 I/O。
接着,客户端对 FSDataInputStream 对象调用 read() 方法。 - 文件写入
客户端通过对 DistributedFileSystem 对象调用 create() 函数来新建文件。如图步骤1;
DistributedFileSystem 对 namenode 创建一个 RPC 调用,在文件系统的命名空间中新建一个文件,此时还没有对应的数据块,如图步骤2;
namenode 执行各种不同的检查以确保这个文件不存在以及客户端有新建该文件的权限。如果检查通过,namenode 就会为创建新文件记录一条记录;否则,文件创建失败并向客户端抛出一个 IOException 异常。
DistributedFileSystem 向客户端返回一个 FSDataOutputStream 对象,由此客户端可以开始写数据。
DFSOutputStream 将它分成一个个数据包,并写入到内部队列,称为“数据队列”(data queue)。DataStreamer 处理数据队列,它的责任是根据 datanode 队列表来要求 namenode 分配适合的新块来存储数据复本。这一组 datanode 构成一个管线–假设复本数为3。DataStreamer 将数据包流式传送到管线中第1个 datanode ,该 datanode 存储数据并发送到管线中的第 2 个 datanode ,第 2 个 datanode 存储数据包并发送到管线中的第 3 个datanode。
DFSOutputStream 也维护一个内部数据包队列来等待 datanode 的收到确认回执,称为“确认队列”。
客户端完成数据写入后,对数据流调用 close() 方法。

3.HDFS中的NameNode和DataNode
HDFS集群中以Master-Slave模式运行,主要有两类节点:一个Namenode节点(即master)和多个Datanode节点。Namenode管理文件系统的Namespace.他维护着文件系统树以及文件树中所有的文件和文件夹的元数据。
hdfs架构图: 
Namenode:
Namenode管理文件系统的Namespace。它维护着文件系统树以及文件树中所有的文件和文件夹的元数据(Metadata).管理这些信息的文件有两个,分别是Namespace镜像文件(Namespace image)和操作日志文件(edit log), 这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地磁盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是它并不持久化存储这些信息,因为这些信息会在系统重启时从数据及节点重建。
Namenode结构抽象图: 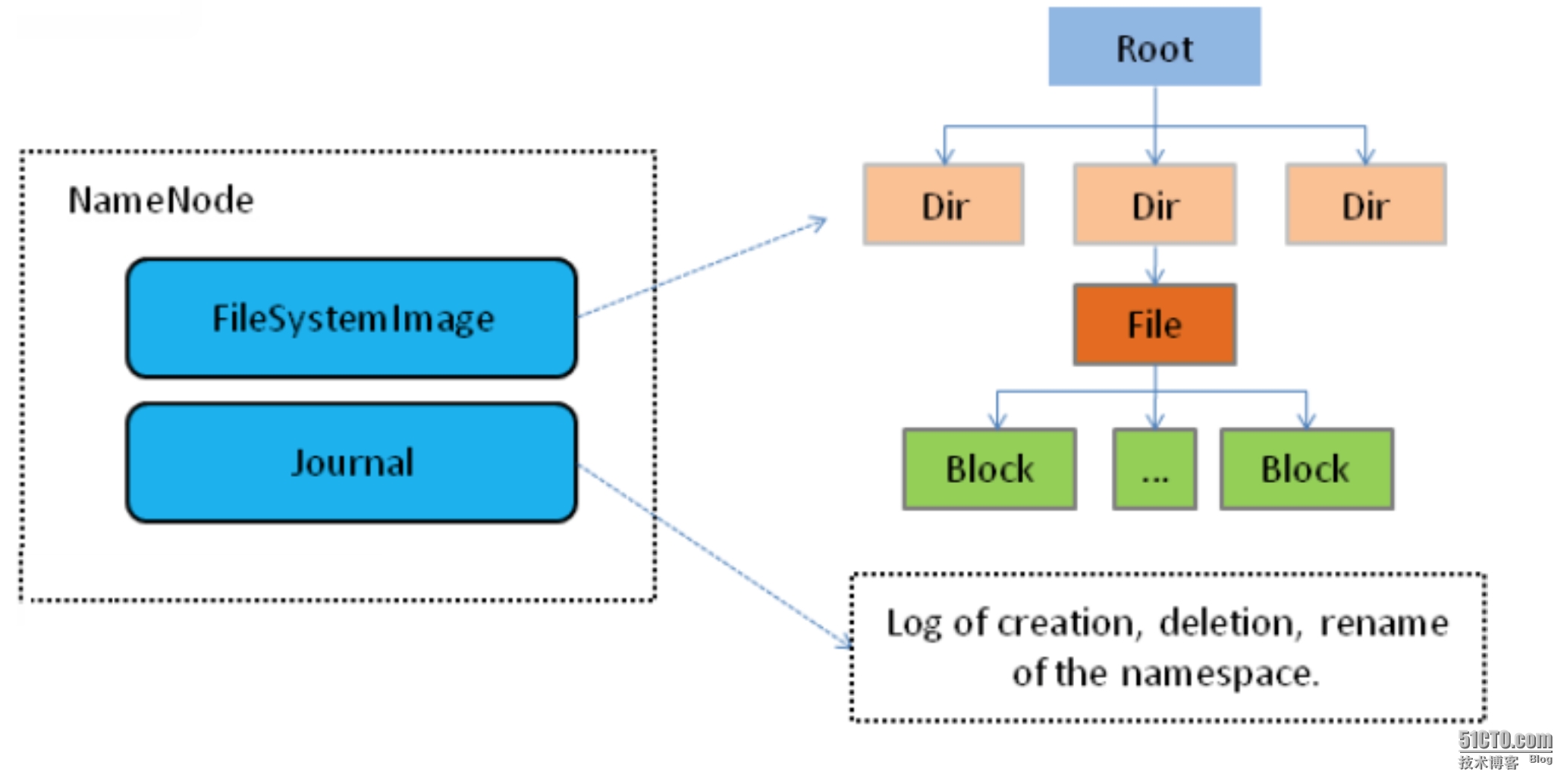
客户端代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一系列的文件系统接口,因此我们在编程时,几乎无需知道datanode和namenode,即可完成我们所需要的功能。
Datanode:
Datanode是文件系统的工作节点,他们根据客户端或者namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表.
Namenode容错机制:
没有了Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种容错机制。
第一种方式:将持久化存储在本地磁盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将它的持久化状态写道不同的文件系统中。这种写操作时同步并且是原子化的。比较常见的配置是在将持久化状态写道本地磁盘的同时,也写到远端挂载的网络文件系统。
第二种方式:是运行一个辅助的Namenode(Secondary Namenode).实时上Secondary Namenode并不能被用作Namenode它的主要作用是定期将namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变的过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并nameSpace镜像的一个备份,如果namenode宕机了,这个备份就可以用上。但是辅助namenode总是落后于namenode,所以在namenode宕机时,数据丢失时不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的namenode 的元数据文件来使用,把nfs中的namenode元数据文件,拷贝到辅助namenode并把辅助namenode作为namenode来运行。
本文转载自:
http://davidbj.blog.51cto.com/4159484/1662449
http://blog.csdn.net/andrewgb/article/details/50603737
- hadoop第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业~~~~~
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- 第二次作业
- Mac下AS快捷键
- MySQL基础
- getRequestDispatcher()与sendRedirect()的区别
- Codeforces 778A String Game(二分)
- 【转】html5学习--js创建与追加元素
- hadoop第二次作业
- VB源程序总是提示加载错误,或者不能加载OCX控件解决方法
- 查看SQL语句信息(脚本sqlstat.sql)
- c++第二次作业
- java第一课数据类型
- Acient Cipher 古老的密码 快速排序法
- POJ 2084 大数+卡特兰数
- 发送激活邮件工具
- Maven系列--pom.xml 配置详解


