使用SVD++进行协同过滤(算法原理部分主要引用自他人)
来源:互联网 发布:windows7优化开机速度 编辑:程序博客网 时间:2024/04/30 16:53
参考:http://www.cnblogs.com/Xnice/p/4522671.html
SVD++是基于SVD(Singular Value Decomposition)的一种改进算法。SVD是一种常用的矩阵分解技术,是一种有效的代数特征提取方法。SVD在协同过滤中的主要思路是根据已有的评分情况,分析出评分者对各个因子的喜好程度以及电影包含各个因子的程度,最后再反过来分析数据得出预测结果。
其在协同过滤中的具体应用方法是先对user_movie的rating矩阵的缺失值用随机数据予以填充,然后将预处理之后的矩阵作为SVD算法的输入,进行迭代求解。
为了更好的说明SVD算法,需要首先对matrix factorization model和Baseline Predictors进行简单的介绍。
matrix factorization model:
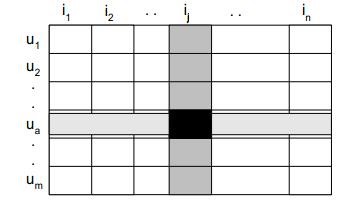
图表 1评分矩阵形式(引用)
评分矩阵U(形式如上图)可被分解为两个矩阵相乘
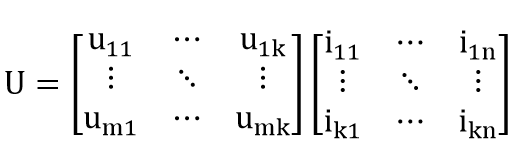
将这种分解方式体现协同过滤中,即有:
![]() (matrix factorization model )
(matrix factorization model )
在这样的分解模型中,Pu代表用户隐因子矩阵(表示用户u对因子k的喜好程度),Qi表示电影隐因子矩阵(表示电影i在因子k上的程度)。
Baseline Predictors:
Baseline Predictors使用向量bi表示电影i的评分相对于平均评分的偏差,向量bu表示用户u做出的评分相对于平均评分的偏差,将平均评分记做μ。
![]() (Baseline Predictors)
(Baseline Predictors)
SVD:
SVD就是一种加入Baseline Predictors优化的matrix factorization model。
SVD公式如下:
![]()
加入防止过拟合的 λ 参数,可以得到下面的优化函数:
![]()
对上述公式求导,我们可以得到最终的求解函数:
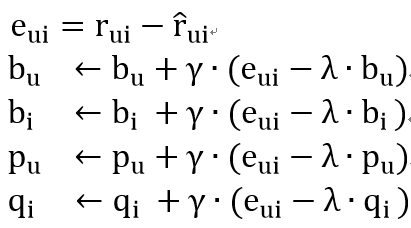
SVD++:
SVD算法是指在SVD的基础上引入隐式反馈,使用用户的历史浏览数据、用户历史评分数据、电影的历史浏览数据、电影的历史评分数据等作为新的参数。
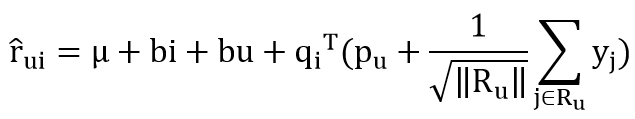
求解公式如下:
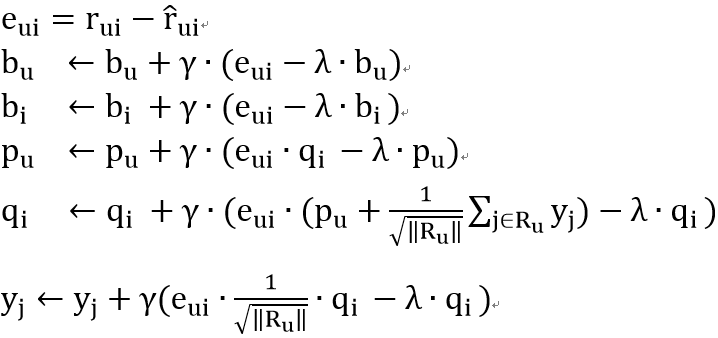
使用用户的历史评价数据作为隐式反馈,算法流程图如下:

【Reference】
【1】从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现http://blog.csdn.net/dark_scope/article/details/17228643
- 使用SVD++进行协同过滤(算法原理部分主要引用自他人)
- 协同过滤相关算法(1):SVD
- 【推荐系统】协同过滤(CF)算法详解,item-base,user-based,SVD,SVD++
- 协同过滤算法的几篇文章PFM/svd/ svd++
- SVD++协同过滤
- 协同过滤算法原理介绍
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 【推荐精读】从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
- 推荐算法:协同过滤原理介绍
- 协同过滤算法(1)
- 利用SVD分解做协同过滤推荐
- 奇异值分解SVD简介及其在推荐系统中的简单应用
- Javascript new发生了什么?
- 使用pip 安装numpy
- windows中.msc文件详解
- Android SlidingMenu 开源项目 侧拉菜单的使用(详细配置)
- 使用SVD++进行协同过滤(算法原理部分主要引用自他人)
- next_permutaion() (Java版)
- 大数据的解决方案--------策略分析
- 关于UITableView的性能优化
- java 打印对象时时如何调用对象toString()方法的
- 为什么要重写equals方法和hashcode方法?
- JAVA方法中数组作为形参,传的是引用
- ubuntu 的回收站的目录
- LeetCode 20. Valid Parentheses


