MXNet学习5——Data Parallelism with Multi-devices
来源:互联网 发布:淘宝自动提取卡密 编辑:程序博客网 时间:2024/04/28 21:01
概要
上一篇文章讲到Mixed Programing,主要描述了混合Symbol和NDArray从头搭建网络并训练,这一篇紧接上文介绍MXNet中如何设计程序并行训练。官方代码请看这里
正文
MXNet是可以自动将计算并行化的,如果有多个设备可用。这使得在MXNet上开发并行程序与跟串行程序一样简单。
下面我们展示如何使用多个设备(比如CPU,GPU)开发一个数据并行的训练程序。这里一个设备(device)表示一个包含自身内存的计算资源。可以是一个GPU也可以是所有CPUs,需要注意的是即使机器有多个CPU,但是使用mx.cpu()可以将所有CPU的资源看成一个整体,对上层是透明的。
下面nvidia的一张图,展示设备的内存结构以及数据如何在设备之间通信 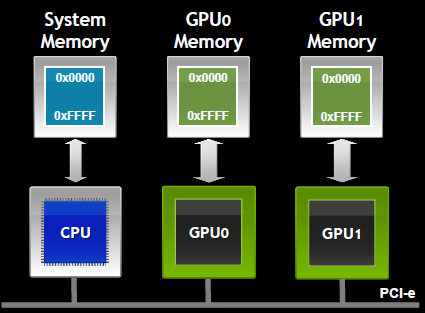
假设每一次迭代我们训练一个总量为
我们将上一篇里的代码扩展下,可以再多个设备下训练。新函数的参数包括一个网络,数据迭代生成器,一系列设备以及对应的性能值。
"""train方法训练网络参数,最后返回的是准确率data是lambda函数 参数从dev[0]复制到其他dev不同设备计算得到的梯度在dev[0]处求和data_shape=[batch_size,num_features]devs是存储设备的list,devs_power是对应的性能workloads是不同设备分配的数据,总和就是batch_sizeround是四舍五入函数zip将两个list构建成一个dict,前一个参数是key,后一个是value"""def train(network, data_shape, data, devs, devs_power): # partition the batch into each device batch_size = float(data_shape[0]) workloads = [int(round(batch_size/sum(devs_power)*p)) for p in devs_power] print('workload partition: ', zip(devs, workloads)) # create an executor for each device ### [p]+data_shape[1:]=[p, num_features] ### data是定义数据的shape,每个设备的训练数据个数(总共batch_size) exs = [network.simple_bind(ctx=d, data=tuple([p]+data_shape[1:])) for d, p in zip(devs, workloads)] args = [dict(zip(network.list_arguments(), ex.arg_arrays)) for ex in exs] # initialize weight on dev 0 for name in args[0]: arr = args[0][name] if 'weight' in name: arr[:] = mx.random.uniform(-0.1, 0.1, arr.shape) if 'bias' in name: arr[:] = 0 # run 50 iterations learning_rate = 0.1 acc = 0 for i in range(50): # broadcast weight from dev 0 to all devices for j in range(1, len(devs)): for name, src, dst in zip(network.list_arguments(), exs[0].arg_arrays, exs[j].arg_arrays): if 'weight' in name or 'bias' in name: src.copyto(dst) # get data ### data是lambda函数 x, y = data() for j in range(len(devs)): # partition and assign data ### idx是一个range, 如果sum(workloads[:1])=12,sum(workloads[:1])=15,则值为range(12,15),该设备计算的数据是第12,13,14个数据(总共是batch_size数)。注意list(range(12,15))的意思 idx = range(sum(workloads[:j]), sum(workloads[:j+1])) ### x是一个batch中所有的数据,x[idx,:]与args[j]['data']的shape相同 ### 此处是根据每个设备装载的数据量填充数据 args[j]['data'][:] = x[idx,:].reshape(args[j]['data'].shape) args[j]['out_label'][:] = y[idx].reshape(args[j]['out_label'].shape) # forward and backward exs[j].forward(is_train=True) exs[j].backward() # sum over gradient on dev 0 if j > 0: for name, src, dst in zip(network.list_arguments(), exs[j].grad_arrays, exs[0].grad_arrays): if 'weight' in name or 'bias' in name: ### as_in_context(context),是在不同设备上传递参数使用的,将自身的参数复制一份到context上 dst += src.as_in_context(dst.context) # update weight on dev 0 for weight, grad in zip(exs[0].arg_arrays, exs[0].grad_arrays): weight[:] -= learning_rate * (grad / batch_size) # monitor if i % 10 == 0: ### np.concatenate 将两个数组拼接 pred = np.concatenate([mx.nd.argmax_channel(ex.outputs[0]).asnumpy() for ex in exs]) acc = (pred == y).sum() / batch_size print('iteration %d, accuracy %f' % (i, acc)) return accbatch_size = 100acc = train(net, [batch_size, num_features], lambda : toy_data.get(batch_size), [mx.cpu(), mx.gpu()], [1, 5])assert acc > 0.95, "Low training accuracy."(‘workload partition: ‘, [(cpu(0), 17), (gpu(0), 83)])
iteration 0, accuracy 0.170000
iteration 10, accuracy 1.000000
iteration 20, accuracy 1.000000
iteration 30, accuracy 1.000000
iteration 40, accuracy 1.000000
Note that the previous network is too small to see any performance benefits moving to multiple devices on such a network. Now we consider use a slightly more complex network: LeNet-5 for hands digits recognition. We first define the network.
上述的例子网络比较小所以体现不出数据并行的优势,接下来考虑一个稍微复杂的网络:LeNet-5手写数字识别。下面首先来定义网络
需要注意的是以下代码我没有跑成功,无法获取MNIST的数据,另外Centos7 python3.5死活装不上sklearn,还没有解决
def lenet(): data = mx.sym.Variable('data') # first conv conv1 = mx.sym.Convolution(data=data, kernel=(5,5), num_filter=20) tanh1 = mx.sym.Activation(data=conv1, act_type="tanh") pool1 = mx.sym.Pooling(data=tanh1, pool_type="max", kernel=(2,2), stride=(2,2)) # second conv conv2 = mx.sym.Convolution(data=pool1, kernel=(5,5), num_filter=50) tanh2 = mx.sym.Activation(data=conv2, act_type="tanh") pool2 = mx.sym.Pooling(data=tanh2, pool_type="max", kernel=(2,2), stride=(2,2)) # first fullc flatten = mx.sym.Flatten(data=pool2) fc1 = mx.sym.FullyConnected(data=flatten, num_hidden=500) tanh3 = mx.sym.Activation(data=fc1, act_type="tanh") # second fullc fc2 = mx.sym.FullyConnected(data=tanh3, num_hidden=10) # loss lenet = mx.sym.SoftmaxOutput(data=fc2, name='out') return lenetmx.viz.plot_network(lenet(), shape={'data':(128,1,28,28)}).view()
from sklearn.datasets import fetch_mldataimport numpy as np import matplotlib.pyplot as pltclass MNIST: def __init__(self): mnist = fetch_mldata('MNIST original') ### np.random.permutation将数组中的数据按照shape随机交换位置 p = np.random.permutation(mnist.data.shape[0]) self.X = mnist.data[p] self.Y = mnist.target[p] self.pos = 0 def get(self, batch_size): p = self.pos self.pos += batch_size return self.X[p:p+batch_size,:], self.Y[p:p+batch_size] def reset(self): self.pos = 0 def plot(self): for i in range(10): plt.subplot(1,10,i+1) plt.imshow(self.X[i].reshape((28,28)), cmap='Greys_r') plt.axis('off') plt.show()mnist = MNIST()mnist.plot()
接下来在单个GPU下训练lenet
# @@@ AUTOTEST_OUTPUT_IGNORED_CELLimport timebatch_size = 1024shape = [batch_size, 1, 28, 28]mnist.reset()tic = time.time()acc = train(lenet(), shape, lambda:mnist.get(batch_size), [mx.gpu(),], [1,])assert acc > 0.8, "Low training accuracy."print('time for train lenent on cpu %f sec' % (time.time() - tic))('workload partition: ', [(gpu(0), 1024)])iteration 0, accuracy 0.071289
iteration 10, accuracy 0.815430
iteration 20, accuracy 0.896484
iteration 30, accuracy 0.912109
iteration 40, accuracy 0.932617
time for train lenent on cpu 2.708110 sec
接下来尝试多个GPU训练,最多需要4个GPU
# @@@ AUTOTEST_OUTPUT_IGNORED_CELLfor ndev in (2, 4): mnist.reset() tic = time.time() acc = train(lenet(), shape, lambda:mnist.get(batch_size), [mx.gpu(i) for i in range(ndev)], [1]*ndev) assert acc > 0.9, "Low training accuracy." print('time for train lenent on %d GPU %f sec' % ( ndev, time.time() - tic))(‘workload partition: ‘, [(gpu(0), 512), (gpu(1), 512)])
iteration 0, accuracy 0.104492
iteration 10, accuracy 0.741211
iteration 20, accuracy 0.876953
iteration 30, accuracy 0.914062
iteration 40, accuracy 0.924805
time for train lenent on 2 GPU 1.623732 sec
(‘workload partition: ‘, [(gpu(0), 256), (gpu(1), 256), (gpu(2), 256), (gpu(3), 256)])
iteration 0, accuracy 0.092773
iteration 10, accuracy 0.777344
iteration 20, accuracy 0.887695
iteration 30, accuracy 0.908203
iteration 40, accuracy 0.916992
time for train lenent on 4 GPU 1.086430 sec
可以看到,使用多个GPU能加快速度。加速的效果并不好,这是因为网络仍然是很简单,GPU之间数据通信的花费相对比较大。我们使用state-of-the-art的网络中看到了更好的结果。下面的图展示了加速的效果 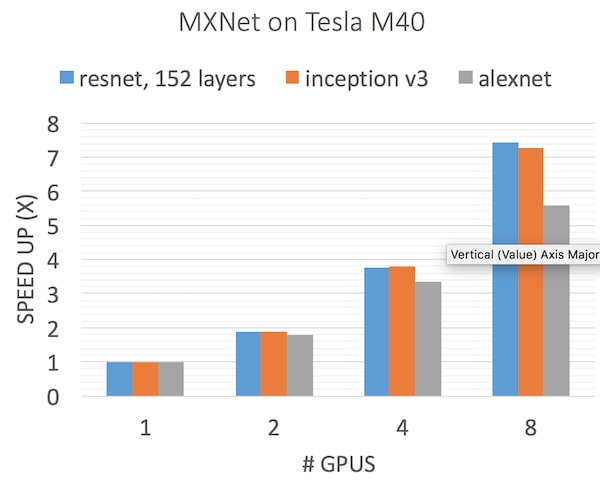
再次注明,本篇文章最后部分代码没有实践,欢迎讨论
- MXNet学习5——Data Parallelism with Multi-devices
- MXNet学习1——数据模拟
- MXNet学习2——Module
- MXNet学习3——Symbol
- MXNet学习4——Mixed Programing
- MXNet学习6——Linear Regression
- MXNet学习7——Logistic Regression
- C++ AMP: .Massive Data Parallelism on the GPU with Microsoft's C++ AMP (Accelerated Massive Parallel
- Serializing data on mobile devices with protobuf on C#
- 数据并行(Data Parallelism)
- MXNet 的学习(一)—— MXNet Dependency Engine(依赖引擎)
- ICME2014-MULTI-VIEW GAIT RECOGNITION WITH INCOMPLETE TRAINING DATA
- MXNet Data IO
- MXNet学习
- mxnet学习
- Improving Multi-frame Data Association with Sparse Representations for Robust Near-online Multi-ob
- MxNet系列——Windows上安装MxNet
- MxNet系列——Windows上安装MxNet
- listview+popupwindow实践:日志列表
- 【php手册】PHP 标记
- Java开发工具IntelliJ IDEA单元测试和代码覆盖率图解
- M
- 面试知识点总结
- MXNet学习5——Data Parallelism with Multi-devices
- A+B(位运算)
- 转载echo print() print_r() var_dump() 的区别
- ubuntu下安装、卸载软件命令
- 通信方式——NFC概述(一)
- 给出文本框一 和二 自动计算文本框三的值
- lmbench基本的部署与使用
- 29.进程的管理
- Swift3.0中如何完成不同View Controller之间的切换


