Pandas入门(上)
来源:互联网 发布:搜索引擎客户数据分析 编辑:程序博客网 时间:2024/05/24 11:14
Pandas入门(上)
Martin
- Pandas入门上
- pandas数据结构介绍
- 基本功能
- 算数运算和数据对齐
pandas数据结构介绍
要使用pandas首先得熟悉它的两个数据结构:Series和DataFrame。
- Series
Series是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即标签)组成。仅由一组数据即可产生最简单的Series:
>>> obj = Series([4,7,-5,3])>>> obj0 41 72 -53 3dtype: int64Series的字符串表现形式为:索引在左边,值在右边。由于我们没有为数据指定索引,于是会自动创建一个0到N-1(N为数据长度)的整数型索引。你可以通过Series的values和index属性获取其数组形式和索引对象:
>>> obj.valuesarray([ 4, 7, -5, 3])>>> obj.indexRangeIndex(start=0, stop=4, step=1) # 开始索引下标为0,结束为4,步长为1但是一般情况下,我们希望创建一个可以各个数据点进行标记的索引:
>>> obj2 = Series([4,7,-5,3],index=['d','b','a','c'])>>> obj2d 4b 7a -5c 3dtype: int64与普通数组相比,你可以通过索引的方式选取Series中的单个或一组值:
>>> obj2['a']-5>>> obj2['b']7>>> obj2[['b','a','d']]b 7a -5d 4dtype: int64如果数据被存放在一个python字典中,也可以直接通过这个字典来创建Series,并且如果只传入一个字典,则结果Series中的索引就是原字典的键(有序字典排序)。
>>> sdata = {'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}>>> obj3 = Series(sdata)>>> obj3Ohio 35000Oregon 16000Texas 71000Utah 5000dtype: int64再来下面这个例子:
>>> sdata = {'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}>>> states = ['California','Ohio','Oregon','Texas']>>> obj4 = Series(sdata,index=states)>>> obj4California NaNOhio 35000.0Oregon 16000.0Texas 71000.0dtype: float64在这个例子中,sdata中跟states索引相匹配的那3个值会被找出来并放到相应位置上,但由于California所对应的sdata值找不到,所以结果就是NaN(即“非数字”not a number),在pandas中它用于表示缺失或NA值,以后将会使用NA表示数据缺失。pandas的isnull和notnull函数可用于检测缺失数据:
>>> pd.isnull(obj4) # 顶层函数调用California TrueOhio FalseOregon FalseTexas Falsedtype: bool>>> obj4.isnull() # 实例方法调用California TrueOhio FalseOregon FalseTexas Falsedtype: bool>>> pd.notnull(obj4)California FalseOhio TrueOregon TrueTexas Truedtype: boolSeries最重要的一个功能就是:在算数运算中能自动对齐不同索引的数据。
>>> obj3Ohio 35000Oregon 16000Texas 71000Utah 5000dtype: int64>>> obj4California NaNOhio 35000.0Oregon 16000.0Texas 71000.0dtype: float64>>> obj3+obj4California NaN # obj3中没有此项,自动变为NA值Ohio 70000.0 Oregon 32000.0 # 自动对齐数据并运算Texas 142000.0Utah NaN # obj4中没有此项,自动变为NA值dtype: float64Series对象本身及其索引都有一个name属性,该属性跟pandas其他的关键功能关系非常密切:
>>> obj4.name = 'population'>>> obj4.index.name = 'state'>>> obj4stateCalifornia NaNOhio 35000.0Oregon 16000.0Texas 71000.0Name: population, dtype: float64Series的索引可以通过赋值的方式就地修改:
>>> obj.index = ['Bob','Steve','Jeff','Ryan']>>> objBob 4Steve 7Jeff -5Ryan 3dtype: int64- DataFrame
DataFrame是一个表格型的数据结构。它含有一组有序的的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看成是有Series组成的字典(共用一个索引)。
构建DataFrame的办法有很多,常用的有两种方式:
- 一种是直接传入一个由等长列表或
Numpy数组构成的字典 - 另一种是嵌套字典(也就是字典的字典)
下面来看一下第一种常用方式:
>>> data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],'year':[2000,2001,2002,2001,2002],'pop':[1.5,1.7,3.6,2.4,2.9]}>>> frame = DataFrame(data)>>> frame pop state year # 字典排序0 1.5 Ohio 20001 1.7 Ohio 20012 3.6 Ohio 20023 2.4 Nevada 20014 2.9 Nevada 2002上面得出的DataFrame结果会自动加上索引(跟Series一样),且全部列会被有序排列。
如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列,指定列顺序用参数columns完成:
>>> DataFrame(data,columns=['year','state','pop']) year state pop0 2000 Ohio 1.51 2001 Ohio 1.72 2002 Ohio 3.63 2001 Nevada 2.44 2002 Nevada 2.9跟Series一样,如果传入的列在数据中找不到,就会产生NA值:
>>> frame2 = DataFrame(data,columns=['year','state','pop','debt'],index=['one','two','three','four','five'])>>> frame2 year state pop debt # debt列在data数据中找不到,故标记为NAone 2000 Ohio 1.5 NaNtwo 2001 Ohio 1.7 NaNthree 2002 Ohio 3.6 NaNfour 2001 Nevada 2.4 NaNfive 2002 Nevada 2.9 NaN通过类似字典获取value的方式,对DataFrame列也可以使用,返回为一个Series对象:
>>> frame2['year'] # 选取列数据one 2000two 2001three 2002four 2001five 2002Name: year, dtype: int64>>> frame2.year # 这种方式跟上面的效果一样one 2000two 2001three 2002four 2001five 2002Name: year, dtype: int64注意:返回的Series拥有原DataFrame相同的索引,且其name属性已经被设置好。但是这种获取方式仅适用于列,对于行也就是axis=0来说,就要用相应的特殊方法.ix。
>>> frame2.ix['three'] # 获取`three`行的数据year 2002state Ohiopop 3.6debt NaNName: three, dtype: object列可以通过赋值方式进行修改,例如,可以给那个空列debt赋值:
>>> frame2['debt'] = 1>>> frame2 year state pop debtone 2000 Ohio 1.5 1two 2001 Ohio 1.7 1three 2002 Ohio 3.6 1four 2001 Nevada 2.4 1five 2002 Nevada 2.9 1修改行数据就要采用刚才说的那个特殊方法ix:
>>> frame2.ix['one'] = [1999,'Califorina',1.7,0]>>> frame2 year state pop debtone 1999 Califorina 1.7 0two 2001 Ohio 1.7 1three 2002 Ohio 3.6 1four 2001 Nevada 2.4 1five 2002 Nevada 2.9 1如果进行某一特定值的修改而不是某整行或某整列时规则跟修改Numpy数组一样,定位行列即可,但是要注意的是DataFrame选取行列定位的顺序是先列后行,与Numpy先行后列不同,一定要注意,如果非要先选行后选列就要用ix。下面来看例子
>>> frame3 = DataFrame(np.arange(15).reshape(5,3),index=['one','two','three','four','five'],columns=['year','state','pop'])>>> frame3 year state popone 0 1 2two 3 4 5three 6 7 8four 9 10 11five 12 13 14如果我想要修改某一项具体值,可以这样做:
>>> frame3['year']['one'] = 99 # 记住要先列后行>>> frame3 year state popone 99 1 2two 3 4 5three 6 7 8four 9 10 11five 12 13 14如果没有遵守先列后行的原则的话,则会报错:
>>> frame3['one']['year'] = 99 # 未遵循先列后行Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/martin/anaconda2/lib/python2.7/site-packages/pandas/core/frame.py", line 1997, in __getitem__如一定要先行后列就要采用ix方法:
>>> frame3.ix['one','year'] = 0>>> frame3 year state popone 0 1 2two 3 4 5three 6 7 8four 9 10 11five 12 13 14但是,重点来了:这里给出的frame3里面的数据都是Numpy数组类型,所以这个先列后行的原则是适用的,但是如果DataFrame里面的数据是别的类型,比如字典类型的话就需要特别处理了,下面来看例子:
>>> frame2 year state popone 1999 Ohio 1.5two 2001 Ohio 1.7three 2002 Ohio 3.6four 2001 Nevada 2.4five 2002 Nevada 2.9应该还记得,frame2是之前给的例子,它里面的的数据是dict字典类型的,我本来也以为它会和Numpy的数组类型是一样的数据赋值,但是通过测试并查找文档发现,这里面还是有猫腻的,来看例子:
# 为了确保会出现警告提示,可以在试验例子之前加一句这个>>>pd.set_option('mode.chained_assignment','raise')>>> frame['year']['one'] = 2000 # 继续使用先列后行,但是奇怪的是报了错Traceback (most recent call last): File "<stdin>", line 1, in <module>...raise SettingWithCopyError(t)pandas.core.common.SettingWithCopyError: A value is trying to be set on a copy of a slice from a DataFrame后来我查了文档,发现文档中有这样一句话,给大家截了官方文档的图片并附上文档地址:
http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
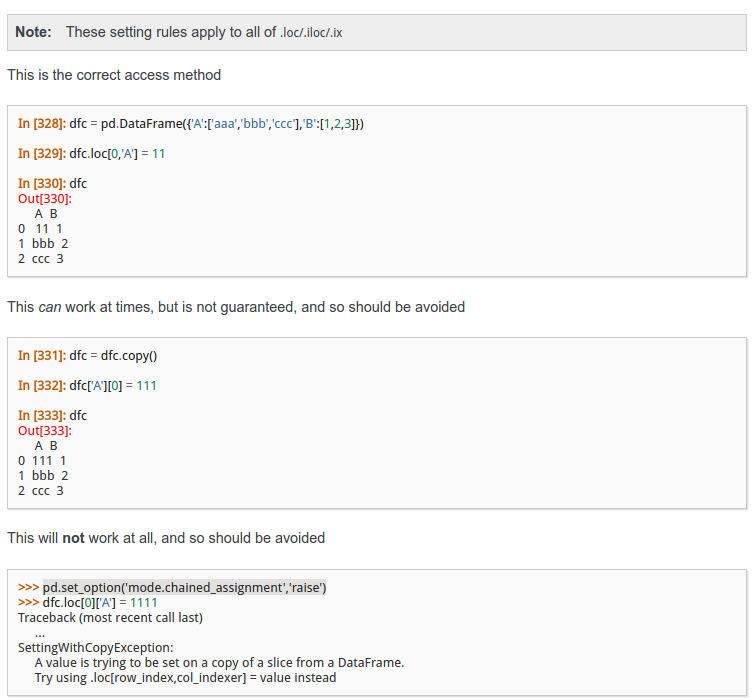
发现“This can work at times,but is not guaranteed,and so should be avoided”这句话了吧,然后再看看它下面的例子,是不是也是跟我讲的是一样的运用方式呢。这句话意思是:这么做有时可以生效,但不总能保证有效,所以请避免这样使用它。那么对于dict字典数据的DataFrame我该怎么修改具体的某个值呢?
往上看,就会找到这样一句话“This is the correct access method”,告诉了我们它下面的使用方式是正确的,也就是使用local函数或者ix函数,遵从先行后列原则。所以我们按照官方文档的方式试试我们的例子:
>>> frame2.loc['one','year'] = 2000 # 一定要先行后列>>> frame2 year state popone 2000 Ohio 1.5 # 用loc函数将1999改成了2000two 2001 Ohio 1.7three 2002 Ohio 3.6four 2001 Nevada 2.4five 2002 Nevada 2.9>>> frame2.ix['one','year'] = 1999 >>> frame2 year state popone 1999 Ohio 1.5 # 用ix函数将2000又改回1999two 2001 Ohio 1.7three 2002 Ohio 3.6four 2001 Nevada 2.4five 2002 Nevada 2.9可能看到这大家不由自主的会有一个疑问,为什么DataFrame类型的数据结构对于数据的操作会这样,把行的处理要单独给于一个函数来处理,但对于列的处理就容易的多了,这比Numpy数组难用多了。我有幸看到了设计Pandas作者的一些想法:
在设计pandas时,我觉得得必须输入frame[:,col]才能选取列实在啰嗦(而且还很容易出错),因为列的选取在报表中是一种常用的操作。于是,我就把所有的标签索引功能都放到了
ix或者loc中了。
为不存在的列赋值会创建出一个新列。关键字del用于删除列且仅适用于列:
>>> frame2['eastern'] = frame2.state == 'Ohio'>>> frame2 year state pop eastern # eastern本不存在,赋值后自动生成one 1999 Ohio 1.5 Truetwo 2001 Ohio 1.7 Truethree 2002 Ohio 3.6 Truefour 2001 Nevada 2.4 Falsefive 2002 Nevada 2.9 False>>> del frame2['eastern']>>> frame2 year state popone 1999 Ohio 1.5two 2001 Ohio 1.7three 2002 Ohio 3.6four 2001 Nevada 2.4five 2002 Nevada 2.9上面的内容就是构造DataFrame时一个比较常用的构造方式:利用由Numpy数组构成的字典。下面来讲下第二种常用构造方式:嵌套字典(字典的字典)。先给举个栗子 :)
>>> pop = {'Nevada':{2001:2.4,2002:2.9},'Ohio':{2000:1.5,2002:3.6}}如果将pop传入DataFrame,它会被解释为:外层字典的键作为列,内层字典的键作为行索引:
>>> frame3 = DataFrame(pop)>>> frame3 Nevada Ohio2000 NaN 1.52001 2.4 NaN2002 2.9 3.6内层字典的键会被合并、排序以形成最终的索引。如果显式指定了索引,则不会这样:
>>> DataFrame(pop,index=[2001,2002,2003]) Nevada Ohio2001 2.4 NaN2002 2.9 3.62003 NaN NaN由Series组成的字典差不多也是一样的用法:(DataFrame每列提取出来都是一个Series类型的数据)
>>> pdata = {'Ohio':frame3['Ohio'][:-1],'Nevada':frame3['Nevada'][:2]}>>> DataFrame(pdata) Nevada Ohio2000 NaN 1.52001 2.4 NaN上面介绍了最常用的构造DataFrame的两种方式,下表给出了可以输入给DataFrame构造器的数据。
如果设置了DataFrame的index和columns的name属性,则这些信息也会被显示出来:
>>> frame3 Nevada Ohio2000 NaN 1.52001 2.4 NaN2002 2.9 3.6>>> frame3.index.name = 'year' # 设置索引name属性>>> frame3.columns.name = 'state' # 设置列name属性>>> frame3state Nevada Ohioyear 2000 NaN 1.52001 2.4 NaN2002 2.9 3.6跟Series一样,values属性也会以二维ndarray的形式返回DataFrame中的数据:
>>> frame3.valuesarray([[ nan, 1.5], [ 2.4, nan], [ 2.9, 3.6]])基本功能
这一节中将介绍操作Series和DataFrame中的数据的基本手段。
- 重新索引
pandas对象的一个重要方法是reindex,其作用是创建一个适应新索引的新对象。还是给个例子
>>> obj = Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c'])>>> objd 4.5b 7.2a -5.3c 3.6dtype: float64调用该Series的reindex将会根据新索引进行重排。如果某个索引值当前不存在,就引入缺失值:
>>> obj2 = obj.reindex(['a','b','c','d','e'])>>> obj2a -5.3b 7.2c 3.6d 4.5e NaN # 引入NA值dtype: float64>>> obj2 = obj.reindex(['a','b','c','d','e'],fill_value=0) # 填充缺失值为0>>> obj2a -5.3b 7.2c 3.6d 4.5e 0.0dtype: float64注意:其实上面的reindx函数可以这样替代:
>>> obj2 = obj[['a','b','c','d']]>>> obj2a -5.3b 7.2c 3.6d 4.5dtype: float64但仅仅就局限于Series对象,对于DataFrame对象使用此方法会报错。
对于DataFrame,reindex可以修改(行)索引、列或者两个都修改。如果想重新索引列,必须传入columns关键字,因为默认没有关键字是只重新排列索引的(即axis=0)。
>>> frame2.reindex(['five','four','three','two','one']) year state popfive 2002 Nevada 2.9four 2001 Nevada 2.4three 2002 Ohio 3.6two 2001 Ohio 1.7one 1999 Ohio 1.5同时修改索引和列必须要传入关键字index和columns:
>>> frame2.reindex(index=['five','four','three','two','one'],columns=['pop','state','year']) pop state yearfive 2.9 Nevada 2002four 2.4 Nevada 2001three 3.6 Ohio 2002two 1.7 Ohio 2001one 1.5 Ohio 1999那么替代DataFrame对象的reindex`方法该这么做:
>>> frame2 year state popone 1999 Ohio 1.5two 2001 Ohio 1.7three 2002 Ohio 3.6four 2001 Nevada 2.4five 2002 Nevada 2.9>>> frame_test = DataFrame(frame2,index=['five','four','three','two','one'])>>> frame_test year state popfive 2002 Nevada 2.9four 2001 Nevada 2.4three 2002 Ohio 3.6two 2001 Ohio 1.7one 1999 Ohio 1.5下表列出了reindex函数的参数:
- 丢弃指定轴上的项
丢弃某轴上的一个或者多个项很简单,只要有一个索引数组或列表即可。由于需要执行一些数据整理和集合逻辑,所以drop方法返回的是一个在指定轴上删除了指定值的新对象。
>>> obj = Series(np.arange(5),index=['a','b','c','d','e'])>>> obja 0b 1c 2d 3e 4dtype: int64>>> new_obj = obj.drop('c')>>> new_obja 0b 1 d 3e 4dtype: int64对于DataFrame,可以删除任意轴上的索引值:
>>> data = DataFrame(np.arange(16).reshape((4,4)),index=['Ohio','Colorado','Utah','New York'],columns=['one','two','three','four'])>>> data one two three fourOhio 0 1 2 3Colorado 4 5 6 7Utah 8 9 10 11New York 12 13 14 15>>> data.drop(['Colorado','Ohio']) one two three fourUtah 8 9 10 11New York 12 13 14 15如果不写axis=1,默认是删除行,如果想删除列,必须加上axis=1。
>>> data.drop('two',axis=1) one three fourOhio 0 2 3Colorado 4 6 7Utah 8 10 11New York 12 14 15>>> data.drop(['two','four'],axis=1) # 传入的是序列 one threeOhio 0 2Colorado 4 6Utah 8 10New York 12 14- 索引、选取和过滤
Series索引的工作方式类似于Numpy数组的索引,只不过Series的索引值不只是整数,下面是几个例子:
>>> obja 0b 1c 2d 3e 4dtype: int64>>> obj['b']1>>> obj[1]1>>> obj[2:4]c 2d 3dtype: int64>>> obj[['b','a','d']]b 1a 0d 3dtype: int64利用标签的切片运算与普通的python切片运算不同,期末端是包含的。
>>> obj['b':'c']b 1c 2dtype: int64设置值的方式也很简单:
>>> obj['b':'c'] = 5>>> obja 0b 5c 5d 3e 4dtype: int64你可能猜到了,对DataFrame进行索引其实就是获取一个或多个列。
>>> data one two three fourOhio 0 1 2 3Colorado 4 5 6 7Utah 8 9 10 11New York 12 13 14 15>>> data['two']Ohio 1Colorado 5Utah 9New York 13Name: two, dtype: int64>>> data[['three','one']] three oneOhio 2 0Colorado 6 4Utah 10 8New York 14 12>>> data['Utah':'New York'] # DataFrame依然可以标签索引,但是对象是行标签 one two three fourUtah 8 9 10 11New York 12 13 14 15为了在DataFrame上能进行行标签索引,引入了ix,但是不能进行标签切片,只能进行普通切片。
>>> data.ix[['Utah','New York'],['one','two']] one twoUtah 8 9New York 12 13>>> data.ix[1:3,0:2] one twoColorado 4 5Utah 8 9下表给出DataFrame的索引选项。
算数运算和数据对齐
Pandas最重要的一个功能是,他可以对不同索引的对象进行算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。看一个例子:
>>> s1 = Series([7.3,-2.5,3.4,1.5],index=['a','c','d','e'])>>> s2 = Series([-2.1,3.6,-1.5,4,3.1],index=['a','c','e','f','g'])>>> s1a 7.3c -2.5d 3.4e 1.5dtype: float64>>> s2a -2.1c 3.6e -1.5f 4.0g 3.1dtype: float64将它们相加就会产生:
>>> s1 + s2a 5.2c 1.1d NaNe 0.0f NaNg NaNdtype: float64自动的数据对其操作在不重叠的索引处引入了NA值。缺失值会在算数运算过程中传播。
对于DataFrame,对齐操作会同时发生在行和列:
>>> df1 = DataFrame(np.arange(9).reshape((3,3)),columns=list('bcd'),index=['Ohio','Texas','Colorado'])>>> df2 = DataFrame(np.arange(12).reshape((4,3)),columns=list('bde'),index=['Utah','Ohio','Texas','Oregon'])>>> df1 b c dOhio 0 1 2Texas 3 4 5Colorado 6 7 8>>> df2 b d eUtah 0 1 2Ohio 3 4 5Texas 6 7 8Oregon 9 10 11把他们相加后将会返回一个新的DataFrame,其索引和列为原来那两个DataFrame的并集:
>>> df1 + df2 b c d eColorado NaN NaN NaN NaNOhio 3.0 NaN 6.0 NaNOregon NaN NaN NaN NaNTexas 9.0 NaN 12.0 NaNUtah NaN NaN NaN NaN- 在算数运算中填充值
在对不同索引对象进行算数运算是,你可能希望当一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值(比如0):
>>> df1 = DataFrame(np.arange(12).reshape((3,4)),columns=list('abcd'))>>> df2 = DataFrame(np.arange(20).reshape((4,5)),columns=list('abcde'))>>> df1 a b c d0 0 1 2 31 4 5 6 72 8 9 10 11>>> df2 a b c d e0 0 1 2 3 41 5 6 7 8 92 10 11 12 13 143 15 16 17 18 19将它们相加时,没有重叠的位置就会产生NA值:
>>> df1 + df2 a b c d e0 0.0 2.0 4.0 6.0 NaN1 9.0 11.0 13.0 15.0 NaN2 18.0 20.0 22.0 24.0 NaN3 NaN NaN NaN NaN NaN使用df1的add方法,传入df2以及一个fill_value参数:
>>> df1.add(df2,fill_value=0) a b c d e0 0.0 2.0 4.0 6.0 4.0 # look,NA值变成了01 9.0 11.0 13.0 15.0 9.02 18.0 20.0 22.0 24.0 14.03 15.0 16.0 17.0 18.0 19.0还记得之前讲的reindex吗,在对Series和DataFrame重新索引是,也可以指定一个填充值:
>>> df1.reindex(columns=df2.columns,fill_value=0) a b c d e0 0 1 2 3 01 4 5 6 7 02 8 9 10 11 0下面给出基本的算数运算函数:
- DataFrame和Series之间的运算
跟Numpy数组一样,DataFrame和Series之间的运算也是有明确规定的。先上一个例子:
>>> arr = np.arange(12).reshape((3,4))>>> arrarray([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]])>>> arr[0]array([0, 1, 2, 3])>>> arr - arr[0]array([[0, 0, 0, 0], [4, 4, 4, 4], [8, 8, 8, 8]])这种运算叫做广播,意思就是可以把某一数据扩散传播并参与运算到整个数组。DataFrame和Series之间的运算也差不多是这样:
>>> frame = DataFrame(np.arange(12).reshape((4,3)),columns=list('bde'),index=['Utah','Ohio','Texas','Orgegon'])>>> series = frame.ix[0]>>> frame b d eUtah 0 1 2Ohio 3 4 5Texas 6 7 8Orgegon 9 10 11>>> seriesb 0d 1e 2Name: Utah, dtype: int64默认情况下,DataFrame和Series之间的运算会将Series的索引匹配到DataFrame的所有列,然后沿着行方向一直向下传播:
>>> frame - series b d eUtah 0 0 0Ohio 3 3 3Texas 6 6 6Orgegon 9 9 9如果希望匹配行且在列上广播,则必须使用算数运算方法:
>>> series2 = frame['d']>>> frame b d eUtah 0 1 2Ohio 3 4 5Texas 6 7 8Orgegon 9 10 11>>> series2Utah 1Ohio 4Texas 7Orgegon 10Name: d, dtype: int64>>> frame.sub(series2,axis=0) b d eUtah -1 0 1Ohio -1 0 1Texas -1 0 1Orgegon -1 0 1传入的轴号就是希望匹配的轴,如果不写轴号默认是axis=1,会出错。
- 函数应用和映射
Numpy的ufunc(元素级数组方法),也可用与操作Pandas对象:
>>> frame = DataFrame(np.random.randn(4,3),columns=list('bde'),index=['Utah','Ohio','Texas','Oregon'])>>> frame b d eUtah 0.228682 0.256469 -1.233977Ohio -1.021476 0.796296 1.715231Texas 0.205654 -0.371884 -2.273169Oregon 0.390541 -0.310140 1.070018>>> np.abs(frame) b d eUtah 0.228682 0.256469 1.233977Ohio 1.021476 0.796296 1.715231Texas 0.205654 0.371884 2.273169Oregon 0.390541 0.310140 1.070018另一个常见的操作是将函数应用到由各列或各行所形成的一维数组上。DataFrame的apply方法即可实现此功能。
>>> f = lambda x:x.max()-x.min() # lambda表达式>>> frame.apply(f) b 1.412017d 1.168180e 3.988401dtype: float64apply方法默认是应用在axis=0上面的,所以如果想要应用在axis=1上得显式指定。
>>> frame.apply(f,axis=1)Utah 1.490445Ohio 2.736707Texas 2.478823Oregon 1.380158dtype: float64除标量值外,传递给apply的函数还可以返回由多个值组成的Series:
>>> def f(x):... return Series([x.max()-x.min()],index=['min','max'])... >>> frame.apply(f) b d emin 1.412017 1.16818 3.988401max 1.412017 1.16818 3.988401函数f可以用lambda表达式替换:
>>> f = lambda x:Series([x.max()-x.min()],index=['min','max'])>>> frame.apply(f) b d emin 1.412017 1.16818 3.988401max 1.412017 1.16818 3.988401- 排序和排名
根据条件对数据进行排序也是一种重要的内置运算。要对行或者列索引进行排序(按字典排序),可使用sort_index方法,它将返回一个已排序的新对象:
>>> obj = Series(range(4),index=['d','a','b','c'])>>> objd 0a 1b 2c 3dtype: int64>>> obj.sort_index()a 1b 2c 3d 0dtype: int64面对DataFrame,则可以根据任意一个轴上的索引进行排序:
>>> frame = DataFrame(np.arange(8).reshape((2,4)),index=['three','one'],columns=['d','a','b','c'])>>> frame.sort_index() # axis=0 d a b cone 4 5 6 7three 0 1 2 3>>> frame.sort_index(axis=1) # axis=1 a b c dthree 1 2 3 0one 5 6 7 4数据默认是按升序排列的,但也可以降序排列,只需改一个参数:
>>> frame.sort_index(axis=1,ascending=False) d c b athree 0 3 2 1one 4 7 6 5以上是对Series或者DataFrame的索引或者列进行排序,还有一种排序是针对里面的数据值来进行排序的,这里用到的就是sort_values方法(2.7.12以前版本使用的是order,虽然可以产生作用,但会弹出警告):
>>> obj.sort_values()2 -33 20 41 7dtype: int64在排序时,任何缺失值默认都会被放到Series的末尾:
>>> obj = Series([4,np.nan,7,np.nan,-3,2])>>> obj.sort_values()4 -3.05 2.00 4.02 7.01 NaN3 NaNdtype: float64在DataFrame上,你可能希望根据一个或多个列中的值进行排序。将一个或多个列的名字传递给by选项即可达到该目的,使用的还是sort_values函数(2.7.12版本以前用的是sort_index,会产生效果,但会弹警告):
>>> frame = DataFrame({'b':[4,7,-3,2],'a':[0,1,0,1]}) >>> frame a b0 0 41 1 72 0 -33 1 2>>> frame.sort_values(by='b') a b2 0 -33 1 20 0 41 1 7- Pandas入门(上)
- pandas入门(上)
- pandas入门
- pandas入门
- Pandas入门
- Pandas入门
- pandas入门
- pandas入门
- Pandas 入门
- pandas入门
- Pandas入门
- pandas 数据分析入门
- pandas入门(持续更新)
- 10分钟入门pandas
- pandas入门-数据结构(1)
- pandas入门-数据结构(2)
- Python pandas 入门
- Pandas入门(中)
- hibernate常见错误总结
- 堆排序
- 2.Calling Extraterrestrial Intelligence Again
- L2-002. 链表去重
- Swift: ImplicitlyUnwrappedOptional,Optional
- Pandas入门(上)
- Retrofit2学习记录
- 如何阅读文献(三)
- StringBuffer和StringBuilder
- 随记1——FramLayout先放置Button,再放置TextView,Button会覆盖TextView
- leetcode【第三周】:输出圆括号
- GitHub使用教程
- 超越spark性能300倍的性能测试
- Maximum Subarray


