【机器学习】k-fold cross validation(k-折叠交叉验证)
来源:互联网 发布:python实现神经网络 编辑:程序博客网 时间:2024/04/30 06:37
另一篇博客http://blog.csdn.net/evillist/article/details/76009632
交叉验证的目的:在实际训练中,模型通常对训练数据好,但是对训练数据之外的数据拟合程度差。用于评价模型的泛化能力,从而进行模型选择。
交叉验证的基本思想:把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对模型进行训练,再利用验证集来测试模型的泛化误差。另外,现实中数据总是有限的,为了对数据形成重用,从而提出k-折叠交叉验证。
对于个分类或回归问题,假设可选的模型为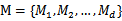 。k-折叠交叉验证就是将训练集的1/k作为测试集,每个模型训练k次,测试k次,错误率为k次的平均,最终选择平均率最小的模型Mi。
。k-折叠交叉验证就是将训练集的1/k作为测试集,每个模型训练k次,测试k次,错误率为k次的平均,最终选择平均率最小的模型Mi。
1、 将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作{![]() }。
}。
2、 每次从模型集合M中拿出来一个![]() ,然后在训练子集中选择出k-1个
,然后在训练子集中选择出k-1个
{![]() }(也就是每次只留下一个
}(也就是每次只留下一个![]() ),使用这k-1个子集训练
),使用这k-1个子集训练![]() 后,得到假设函数
后,得到假设函数![]() 。最后使用剩下的一份
。最后使用剩下的一份![]() 作测试,得到经验错误
作测试,得到经验错误![]() 。
。
3、 由于我们每次留下一个![]() (j从1到k),因此会得到k个经验错误,那么对于一个
(j从1到k),因此会得到k个经验错误,那么对于一个![]() ,它的经验错误是这k个经验错误的平均。
,它的经验错误是这k个经验错误的平均。
4、 选出平均经验错误率最小的![]() ,然后使用全部的S再做一次训练,得到最后的
,然后使用全部的S再做一次训练,得到最后的![]() 。
。
参考
0 0
- 【机器学习】k-fold cross validation(k-折叠交叉验证)
- 【机器学习】交叉验证和K-折交叉验证cross-validation and k-fold cross-validation
- k折交叉验证;k-fold交叉验证;k-fold cross-validation
- K-Fold Cross Validation(K倍交叉检验)
- 什么是交叉检验(K-fold cross-validation)
- k fold cross validation
- K-Fold Cross Validation
- 机器学习--k-折交叉验证(k-fold crossValidation)
- 【机器学习】交叉验证(cross-validation)
- K-fold 交叉验证
- Bias(偏差),Error(误差),Variance(方差),和K-fold Cross Validation的关系(机器学习核心)
- k-fold cross validation中的小问题
- cross-validation:从 holdout validation 到 k-fold validation
- cross-validation:从 holdout validation 到 k-fold validation
- 斯坦福大学机器学习——交叉验证(Cross Validation)
- 机器学习中的交叉验证(cross-validation)
- 机器学习中的交叉验证(cross-validation)
- 机器学习----交叉验证(Cross Validation)简介
- GreenDao文档和简单使用
- AndroidFramework -- Binder中的Bn与Bp
- Docker工具介绍
- iPhone隐藏指令
- Android Http
- 【机器学习】k-fold cross validation(k-折叠交叉验证)
- 使用Ecplise git commit时出现"There are no stages files"
- NOIP 2002 提高组 复赛 字串变换
- BZOJ P2751:[HAOI2012]容易题
- 389.Find the Difference
- navicat for mysql乱码解决方法
- Win7安装及设置Jmeter
- 移动硬盘不能识别的解决办法
- 删除多余的空格


