【数据挖掘】用户画像
来源:互联网 发布:杨氏模量实验数据图 编辑:程序博客网 时间:2024/05/16 11:01
概念区分
Persona和Profile,经常都翻译为用户画像,二者的概念有相关的部分,但是也有区别。
- Persona,也叫做用户角色,是描绘抽象一个自然人的属性,用于产品和用户调研。
- Profile,是和数据挖掘、大数据息息相关的应用。通过数据建立描绘用户的标签。
本文讨论的是Profile。 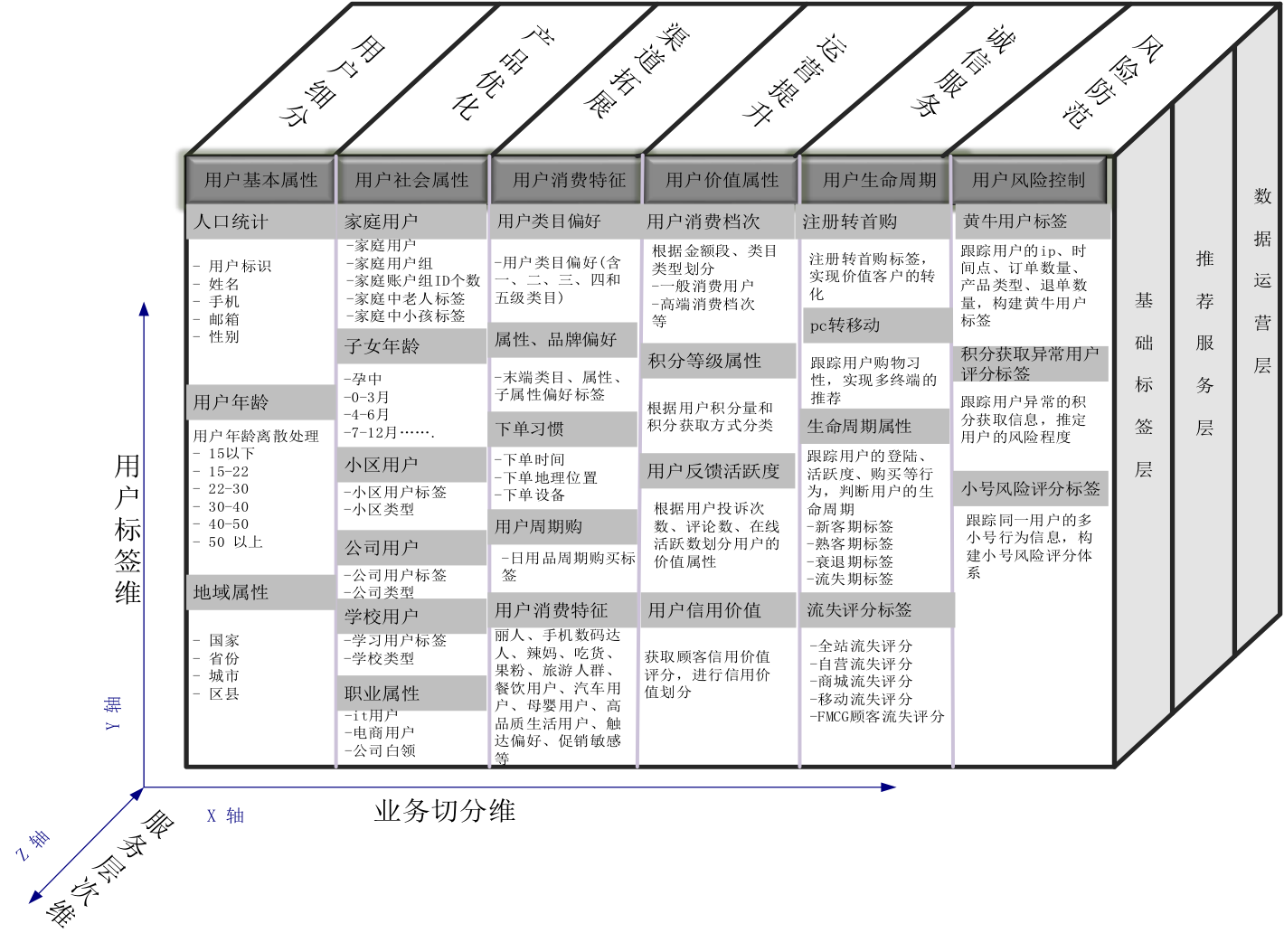
作用
- 精准营销,分析产品潜在用户,针对特定群体利用短信邮件等方式进行营销;
- 用户统计,比如中国大学购买书籍人数 TOP10,全国分城市奶爸指数;
- 数据挖掘,构建智能推荐系统,利用关联规则计算,喜欢红酒的人通常喜欢什么运动品牌,利用聚类算法分析,喜欢红酒的人年龄段分布情况;
- 效果评估,完善产品运营,提升服务质量,其实这也就相当于市场调研
- 用户调研,迅速下定位服务群体,提供高水平的服务;
- 对服务或产品进行私人定制,即个性化的服务某类群体甚至每一位用户(个人认为这是目前的发展趋势,未来的消费主流)。
- 业务经营分析以及竞争分析,影响企业发展战略
构建流程
数据收集
数据收集大致分为网络行为数据、服务内行为数据、用户内容偏好数据、用户交易数据这四类。
- 网络行为数据:活跃人数、页面浏览量、访问时长、激活率、外部触点、社交数据等
- 服务内行为数据:浏览路径、页面停留时间、访问深度、唯一页面浏览次数等
- 用户内容便好数据:浏览/收藏内容、评论内容、互动内容、生活形态偏好、品牌偏好等
- 用户交易数据(交易类服务):贡献率、客单价、连带率、回头率、流失率等
当然,收集到的数据不会是100%准确的,都具有不确定性,这就需要在后面的阶段中建模来再判断,比如某用户在性别一栏填的男,但通过其行为偏好可判断其性别为“女”的概率为80%。
还得一提的是,储存用户行为数据时最好同时储存下发生该行为的场景,以便更好地进行数据分析。
行为建模
该阶段是对上阶段收集到数据的处理,进行行为建模,以抽象出用户的标签,这个阶段注重的应是大概率事件,通过数学算法模型尽可能地排除用户的偶然行为。
这时也要用到机器学习,对用户的行为、偏好进行猜测,好比一个 y=kx+b 的算法,X 代表已知信息,Y 是用户偏好,通过不断的精确k和b来精确Y。
在这个阶段,需要用到很多模型来给用户贴标签。
- 用户汽车模型
根据用户对“汽车”话题的关注或购买相关产品的情况来判断用户是否有车、是否准备买车 - 用户忠诚度模型
通过判断+聚类算法判断用户的忠诚度 - 身高体型模型
根据用户购买服装鞋帽等用品判断 - 文艺青年模型
根据用户发言、评论等行为判断用户是否为文艺青年 - 用户价值模型
判断用户对于网站的价值,对于提高用户留存率非常有用(电商网站一般使用RFM 实现)
还有消费能力、违约概率、流失概率等等诸多模型。
用户画像基本成型
该阶段可以说是二阶段的一个深入,要把用户的基本属性(年龄、性别、地域)、购买能力、行为特征、兴趣爱好、心理特征、社交网络大致地标签化。
为什么说是基本成型?因为用户画像永远也无法100%地描述一个人,只能做到不断地去逼近一个人,因此,用户画像既应根据变化的基础数据不断修正,又要根据已知数据来抽象出新的标签使用户画像越来越立体。
关于“标签化”,一般采用多级标签、多级分类,比如第一级标签是基本信息(姓名、性别),第二级是消费习惯、用户行为;第一级分类有人口属性,人口属性又有基本信息、地理位置等二级分类,地理位置又分工作地址和家庭地址的三级分类。
数据可视化分析
这是把用户画像真正利用起来的一步,在此步骤中一般是针对群体的分析,比如可以根据用户价值来细分出核心用户、评估某一群体的潜在价值空间,以作出针对性的运营。
参照思维导图:用户画像
内容整理自知乎,如侵删。
0 0
- 数据挖掘-用户画像
- 数据挖掘-用户画像
- 【数据挖掘】用户画像
- 杨步涛:基于用户画像的大数据挖掘实践
- 受众画像数据只是看看?——基于朴素贝叶斯的用户数据挖掘
- 基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘
- <转>基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘
- <转>基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘
- <转> 基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘
- <转> 基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘
- 基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘
- 用户画像数据建模方法
- 用户画像数据建模方法
- 用户画像数据建模方法
- 用户画像数据建模方法
- 用户画像数据建模方法
- 用户画像数据建模方法
- 用户画像数据建模方法
- 斯坦福机器学习视频笔记 Week6 关于机器学习的建议 Advice for Applying Machine Learning
- Linux内核内存管理中伙伴查找和检查
- Presentation 常用的承接句——技术分享、学术报告串联全场不尴尬
- mysql数据库中文乱码问题总结及解决手段
- Android复习-Acitivity的生命周期(一、正常情况下的各种回调)
- 【数据挖掘】用户画像
- JVM进阶(九)——JAVA 年轻代收集器
- ArcEngine属性条件查询和空间条件查询
- 身份证,手机号正则表达式
- csdnMarkdown
- 设计模式---外观模式(C++实现)
- 忘记mysql初始密码
- ifconfig: command not found(CentOS专版,其他的可以参考)
- 带你玩转Visual Studio——带你理解多字节编码与Unicode码


